学网页设计工资多少成都高新seo
什么是LLM代理?
LLM代理可以被定义为能够对环境采取行动的大型语言模型。代理的主要组成部分包括:记忆、规划、提示、知识和工具。大型语言模型可以被视为这个架构的大脑,而其他所有组件则是代理正常工作的基础模块。
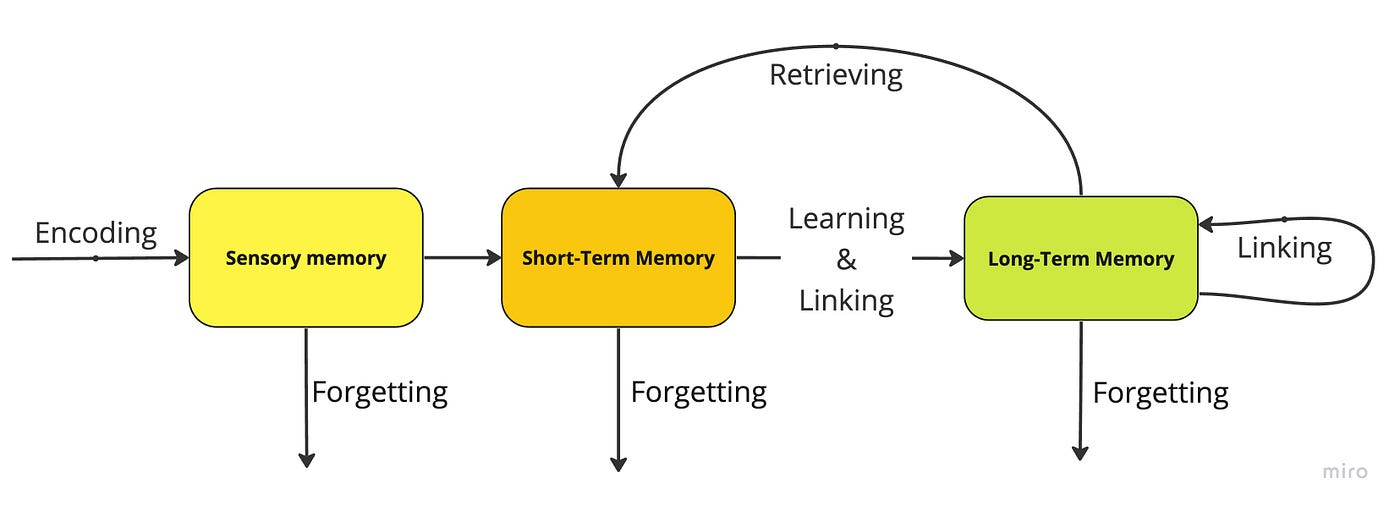
代理的组成部分
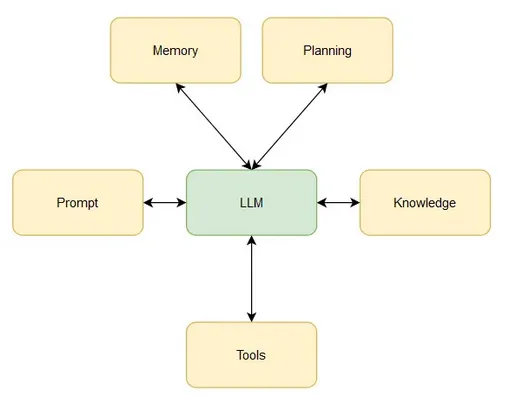
1. 提示
提示是向LLM提供其目标、行为和计划信息的指令。
2. 规划
复杂问题通常需要链式思考的方法。因此,代理必须通过其推理能力制定计划。
3. 工具
可执行的函数、API或其他服务,让代理能够完成任务并与环境交互。
4. 知识
没有领域知识,代理就无法解决甚至理解任务。所以要么对LLM进行微调以获取知识,要么创建工具从数据库中提取知识。
5. 记忆
众所周知,代理通过先将复杂任务分解为子任务,然后执行工具来完成子任务。为此,模型需要记住之前的步骤。这也是本文将重点关注的方面。
记忆分类
简单来说,记忆就是一个能记住之前互动内容的系统。这对于打造良好的代理体验至关重要。想象一下,如果你有个同事记不住过去的指示,很快就会变得无法继续工作。由于代理主要用于多阶段任务,记忆就变得尤为重要。
据《语言代理的认知架构》一文所述,语言代理使用几种类型的记忆来存储和维护与世界互动的信息:
1. 短期记忆
工作记忆维持活跃信息,作为连接语言代理各个组件的中央枢纽。它保存感知输入、来自推理或检索的活跃知识以及从前几个周期带来的其他信息。工作记忆与长期记忆和基础接口交互,并在多次LLM调用过程中持续存在。
短期记忆主要用于存储当前任务或对话的上下文信息,例如多轮对话中的用户查询和系统响应。
实现方式通常依赖大语言模型(LLM)的上下文窗口(Context Window),其容量受限于Transformer模型的架构。 例如,一些模型的上下文长度可能达到4096个令牌,但具体数值因模型而异。
短期记忆的特点是临时性,任务完成后通常会被清除,以释放资源并避免信息过载。 例如,Ali的SuperAGI通过生成交互的简洁摘要(如agent_summary.txt)来维护短期记忆,确保摘要长度不超过设定的字符限制。
三种常见的形式为:
-
上下文窗口:最基础的形式,将之前的对话历史保留在输入窗口中,但受限于模型的上下文长度限制。
-
滑动窗口:当对话超出上下文限制时,保留最近的N条交互,丢弃较早的内容。
-
消息压缩/总结:将过去的对话历史压缩或总结,以节省上下文空间。
2. 长期记忆
长期记忆用于存储需要持久保留的信息,例如用户的偏好、过去的任务经验或外部知识。
实现方式通常依赖外部存储系统,如向量数据库(Vector Database),通过将信息嵌入向量空间,支持基于相似性搜索的快速检索。
例如,千问AI agent使用一个Memory类来管理长期记忆,支持多种文件类型(如.pdf、.docx、.xlsx等),并配置参数如max_ref_token(默认4000)、parser_page_size(默认500)等,通过检索增强生成(Retrieval-Augmented Generation, RAG)技术进行高效检索。
长期记忆的另一个例子是MemoryBank,它存储完整的交互记录,以确保对话的一致性和连贯性。
总结来说两种主要形式为:
-
向量数据库存储:
- 将对话内容转换为向量嵌入
- 存储在向量数据库中(如Pinecone、Faiss、Milvus等)
- 通过相似性搜索快速检索相关信息
-
结构化知识库:
- 将信息以键值对、图结构或三元组形式存储
- 常用Neo4j、Postgres等数据库
2.1 情景记忆
情景记忆存储以前决策周期的经验。 这包括训练的输入-输出对、事件流、游戏轨迹和其他表示过去经验的内容。这些存储的内容可以在规划阶段被检索到工作记忆中以支持推理。

2.2 语义记忆
语义记忆存储代理关于世界和自身的知识。这可以从外部数据库初始化,也可以随着时间的推移通过学习积累。 语义记忆可以存储事实或通过推理获得的知识。
2.3 程序记忆:

程序记忆很有意思,比如骑车。
程序记忆存储关于如何执行操作的知识,有两种形式:
- 存储在LLM权重中通过交互学习到的隐式知识
- 写在代理代码中的显式知识。程序记忆由设计者初始化,虽然可以更新,但比更新其他类型的记忆风险更大,比如开发者为防止产品被滥用而设定的护栏。
这些不同的记忆模块让语言代理能够存储、检索和从经验中学习,并使用这些信息做出明智的决策。
简言之,程序记忆可以被定义为应用于工作记忆以确定代理行为的一套规则。
记忆的实现过程
证据倾向于支持记忆的实现包括三个主要步骤,类似于认知心理学中的记忆模型:
-
写入(Writing):
- 此步骤涉及捕获并存储新信息。例如,在对话场景中,Agent可能会提取用户输入的关键点(如饮食偏好、用餐时间)并存储到记忆中。
- 写入过程可能涉及信息提取和格式化,例如将对话记录转换为自然语言描述或向量表示。
-
管理(Management):
- 管理阶段包括更新、整合和可能遗忘信息,以保持记忆的相关性和效率。
- 一些系统使用衰减因子(如0.99)来减少旧信息的重要性,或通过抽象和合并减少冗余。例如,系统可能将多次提及的相同偏好合并为单一记录。
- 管理还可能涉及反射(Reflection)机制,将过去的经验整合为更高层次的知识。
-
读取(Reading):
- 读取阶段根据当前任务或查询检索相关信息。例如,在餐厅预订任务中,Agent可能会从长期记忆中检索用户的饮食偏好、用餐人数和时间,以确定合适的餐厅。
- 读取通常基于相似性搜索,通过将查询转换为向量并与存储的记忆向量进行比较,快速找到相关信息。
其中读取我们可以理解为记忆检索
记忆检索
-
语义搜索:基于当前查询与存储信息的语义相关性检索
-
时间衰减检索:优先考虑最近的记忆,较早的记忆权重降低
-
重要性过滤:基于预设规则或重要性评分筛选信息
其中管理我们可以理解为记忆更新,以下为记忆更新关键动作
记忆更新
-
主动总结:定期总结对话内容生成新的记忆条目
-
记忆合并与删除:合并重复信息,删除不相关或过时信息
-
分层记忆管理:
- 工作记忆:当前活跃的信息
- 短期记忆:近期但非立即需要的信息
- 长期记忆:重要但不常用的信息
以下是记忆在实际应用中的具体案例,展示了其重要性:
- 餐厅预订Agent:在“Agent 预定餐厅”案例中,记忆在第二步用于检索用户的饮食偏好、用餐人数和时间,以匹配合适的餐厅。这体现了短期记忆用于对话上下文,长期记忆用于存储用户特征。
- 对话系统:如MemoryBank,用于保存对话记录,确保多轮对话的一致性和连贯性,增强用户体验。
- 个人助理:长期记忆存储用户习惯和偏好,支持个性化推荐。
- 开放世界游戏:如Voyager,存储技能和经验,支持探索和任务执行。
如何在代理中设置记忆
现在,我们了解了各种类型的记忆以及大致实现过程,但如何在代理中设置记忆呢?
1. 暴力记忆法
我们可以将之前的消息放在一个列表中,每次运行代理时都加载这个消息列表。如果不需要长期记忆且交互不会占用太多token,这种方法是可行的。
messages = [ { "role" : "user" , "content" : "法国的首都是哪里?"}, { "role" : "assistant" , "content" : "法国的首都是巴黎。"}, { "role" : "user" , "content" : "总结这段文字:‘敏捷的棕色狐狸跳过了懒狗。’"}, { "role" : "assistant" , "content" : "这段文字描述了一只敏捷的棕色狐狸跳过了一只懒狗。"}, { "role" : "user" , "content" : "生成 Python 代码来计算数字的阶乘。"}, { "role" : "assistant" , "content" : "这是一个用于计算数字阶乘的 Python 函数:\n\n```python\nimport math\n\ndef factorial(n):\n if n < 0:\n raise ValueError(\"Factorial is not defined for negative numbers.\")\n return 1 if n == 0 else n * factorial(n - 1)\n```"}, { "role" : "user" , "content" : "用简单的术语解释神经网络是如何工作的。"}, { "role" : "assistant" , "content" : "神经网络是模仿人脑的计算机系统。它们由相互连接的节点层(如神经元)组成。数据通过这些连接传递,网络调整其内部参数以学习模式并做出预测或决策。"}, { "role" : "user" , "content" : "在此列表中找出两个最大的数字:[3, 1, 4, 1, 5, 9, 2, 6]。"}, { "role" : "assistant" , "content" : "列表中两个最大的数字是 9 和 6。"}, { "role" : "user" , "content" :"1 除以 0 的结果是多少?"}, { "role" : "assistant" , "content" : "1 除以 0 在数学上是未定义的,并且在大多数编程语言中,它会导致错误。"}, {"role" : "user" , "content" : "如何在 LangChain 中编写提示来总结文本?"}, { "role" : "assistant" , "content" : "这是一个用于总结文本的 LangChain 提示的示例:\n\n```python\nfrom langchain.prompts import PromptTemplate\n\nprompt = PromptTemplate(\n input_variables=['text'],\n template=\"\"\"\n 请总结以下文本:\n {text}\n \"\"\"\n)\n```"}
]
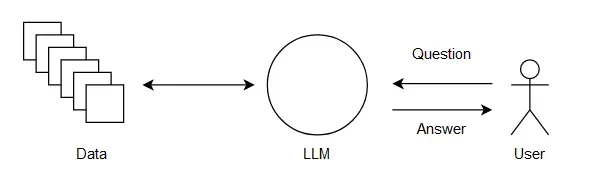
2. RAG或微调
我们可以使用检索增强生成(RAG)来模拟长期记忆。检索增强生成的工作原理如下:
- 首先检索与用户查询相关的内容
- 将检索内容与用户的查询结合
- 然后使用组合后的提示生成答案
这种方法的主要挑战包括开发者需要定期更新系统,这会随着时间推移变得很费力。此外,随着交互在数据库中累积,内存使用量会显著增长,最终导致难以高效管理和检索过去的交互。
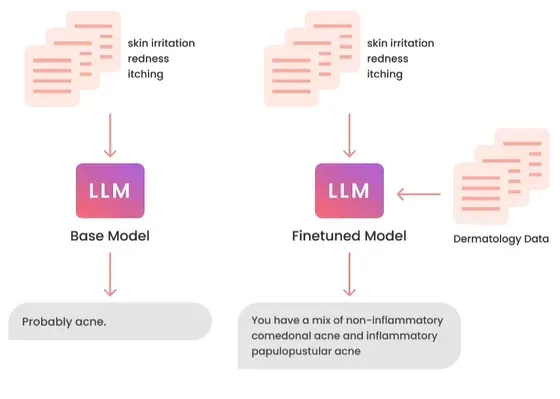
另一种方法可能是将之前的行动作为微调数据用于未来任务。微调让你能够将更多数据输入到模型中,而不仅仅是放入提示。这让模型学习数据而不只是访问数据。但这需要太多计算资源和时间,并非人人都有资源来微调大型语言模型。
3. MemGPT
还有一种完全不同的方法来完成这个任务。如果我们让LLM管理自己的记忆会怎样?论文《Memgpt: Towards llms as operating systems》回答了这个问题。
MemGPT使用受传统操作系统启发的虚拟内存系统来管理大型语言模型(LLM)的有限上下文窗口。
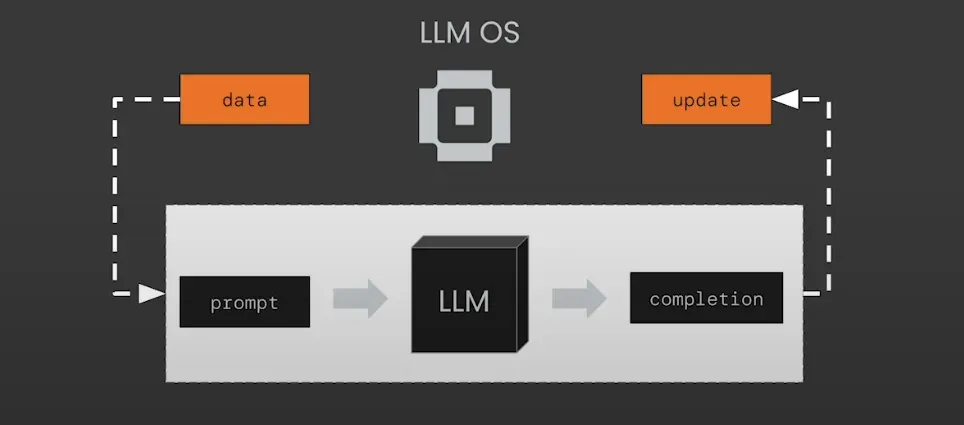
MemGPT是一个执行内存管理的LLM操作系统。在MemGPT中,这个操作系统本身也是一个LLM代理。因此,记忆管理是自动完成的。
但它是如何工作的呢?我们可以用一个类比来理解这个虚拟内存是如何工作的:
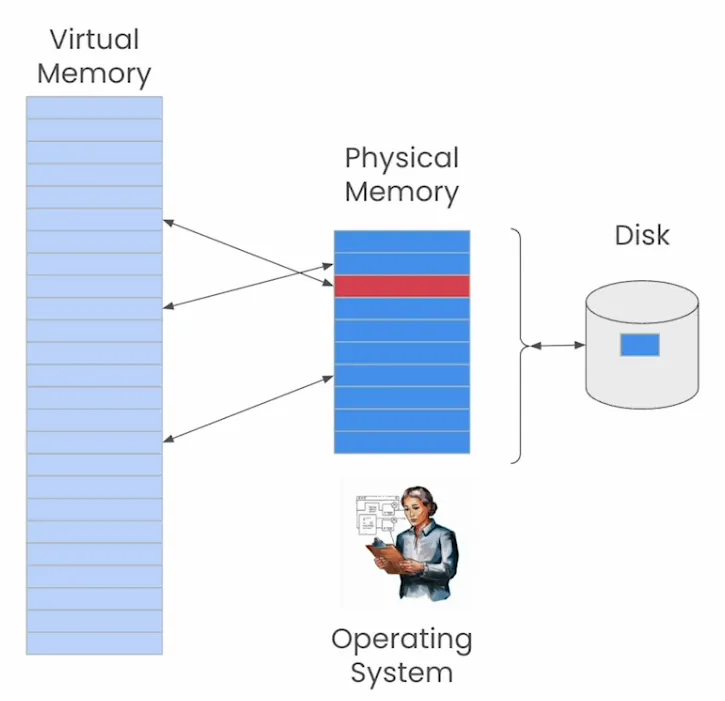
在MemGPT中,上下文窗口可以被视为计算机中的虚拟内存。你的计算机认为它有一个很大的内存,比实际拥有的物理内存大得多。具体来说,它有一个很大的虚拟内存。当它尝试引用一个不在物理内存中的虚拟位置时,操作系统会先通过将物理内存中的一块信息移出到磁盘来腾出空间,保留该块中的任何更改,然后从磁盘获取新的信息块,并将其带回物理内存。
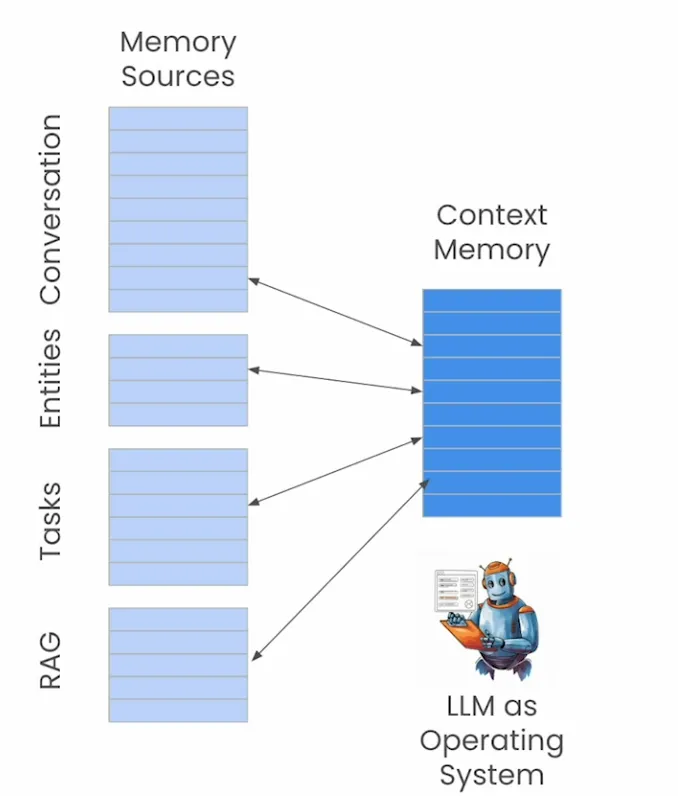
类似地,你可以将LLM的上下文窗口视为类似于物理内存。在MemGPT系统中,LLM代理包括操作系统的角色,并决定上下文窗口中应该包含哪些信息。
MemGPT背后的关键理念
自我编辑记忆:
在MemGPT中,代理可以根据聊天中学到的内容更新自己的指令或个性化信息。它通过使用工具来实现这一点。
内心思考
在MemGPT中,代理总是进行自我思考,而回应用户只是一种工具。因此,代理不会在收到用户问题后立即回答。通常在回答前会有几步内心思考。
每个输出都是一个工具
在MemGPT中,代理总是调用工具。即使是回答用户也是一种工具。唯一不使用工具的步骤是内心思考。
通过心跳循环
在MemGPT中,代理能够通过心跳进行循环。将request_heartbeat设置为True意味着代理必须调用另一个工具。心跳可以被视为内心思考和非回答用户工具的限制器。由于LLM可能会不断创造更多内心思考,我们设置了一个叫做心跳的限制,如果不回答用户的步骤超过了心跳限制,那么LLM必须为用户形成一个答案。
基于向量数据库的记忆实现示例
# 简化的基于向量数据库的记忆实现示例
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings# 初始化嵌入模型和向量存储
embeddings = OpenAIEmbeddings()
memory_db = Chroma(embedding_function=embeddings)# 存储记忆
def store_memory(text, metadata=None):memory_db.add_texts([text], metadatas=[metadata] if metadata else None)# 检索相关记忆
def retrieve_memories(query, k=5):results = memory_db.similarity_search(query, k=k)return [doc.page_content for doc in results]# 在Agent中使用
def agent_response(user_query):# 1. 检索相关记忆relevant_memories = retrieve_memories(user_query)# 2. 构建包含记忆的提示prompt = f"""记忆:{' '.join(relevant_memories)}用户问题: {user_query}请考虑上述记忆回答问题。"""# 3. 调用LLM获取回答response = llm(prompt)# 4. 存储新记忆store_memory(f"用户: {user_query}\n助手: {response}")return response
结论
记忆是AI Agent能够学习和适应的关键:
- 学习与进化:通过积累经验,Agent可以从过去的任务中学习,支持跨任务信息的整合。
- 一致性与自然性:在对话系统中,记忆确保多轮对话的连贯性和用户参与度。
- 扩展能力:通过外部知识(如API或数据库),Agent可以超越内部知识的限制。
然而,当前研究仍面临挑战:
- 主要集中在文本形式的记忆上,而参数化记忆(Parametric Memory)研究不足。
- 多Agent记忆、终身学习(Lifelong Learning)以及模拟人类记忆的机制(如遗忘曲线)仍需进一步探索。
大模型智能体Agent的记忆通过短期记忆和长期记忆实现,前者处理临时对话信息,后者存储持久化数据。记忆的实现包括写入、管理和读取三个步骤,支持Agent在复杂任务中的学习和决策。尽管当前技术已取得进展,但仍存在挑战,未来研究将进一步提升记忆系统的效率和智能化。