网易云播放器做网站播放seo推广教程seo推广技巧
优化理论
梯度下降(Gradient Descent)
数学原理与可视化
梯度下降是优化领域的基石算法,其核心思想是沿负梯度方向迭代更新参数。数学表达式为:
θ t + 1 = θ t − α ∇ θ J ( θ t ) \theta_{t+1} = \theta_t - \alpha \nabla_\theta J(\theta_t) θt+1=θt−α∇θJ(θt)
其中:
- α \alpha α:学习率,控制步长
- ∇ θ J \nabla_\theta J ∇θJ:损失函数关于参数的梯度
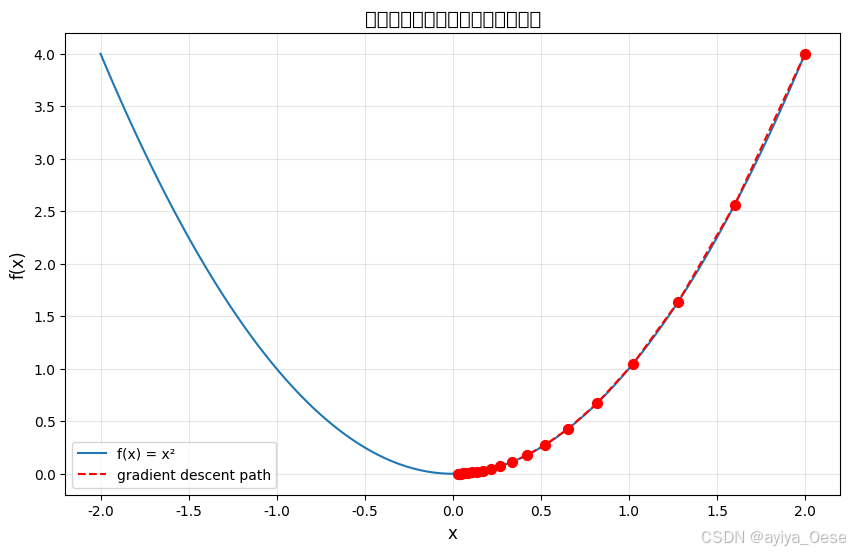
几何解释:在三维空间中,梯度下降如同沿着最陡下降方向下山。二维可视化展示参数更新路径:
import matplotlib.pyplot as plt
import numpy as np# 定义二次函数及其梯度
def f(x): return x**2
def grad(x): return 2*x# 梯度下降轨迹可视化
x_path = []
x = 2.0
lr = 0.1
for _ in range(20):x_path.append(x)x -= lr * grad(x)# 绘制函数曲线和更新路径
xs = np.linspace(-2, 2, 100)
plt.figure(figsize=(10,6))
plt.plot(xs, f(xs), label="f(x) = x²")
plt.scatter(x_path, [f(x) for x in x_path], c='red', s=50, zorder=3)
plt.plot(x_path, [f(x) for x in x_path], 'r--', label="gradient descent path")
plt.title("梯度下降在二次函数上的优化轨迹", fontsize=14)
plt.xlabel("x", fontsize=12)
plt.ylabel("f(x)", fontsize=12)
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
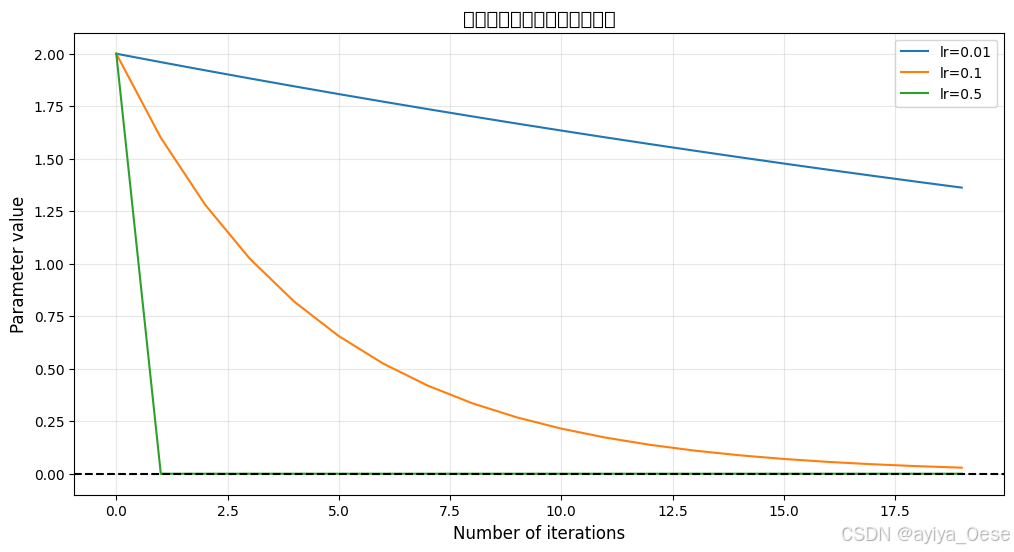
学习率对比实验
lrs = [0.01, 0.1, 0.5] # 不同学习率plt.figure(figsize=(12,6))
for lr in lrs:x = 2.0path = []for _ in range(20):path.append(x)x -= lr * grad(x)plt.plot(path, label=f"lr={lr}")plt.title("不同学习率对收敛速度的影响", fontsize=14)
plt.xlabel("Number of iterations", fontsize=12)
plt.ylabel("Parameter value", fontsize=12)
plt.axhline(0, color='black', linestyle='--')
plt.legend()
plt.grid(True, alpha=0.3)
随机梯度下降(Stochastic Gradient Descent, SGD)
算法原理
与传统梯度下降的对比:
| 方法 | 梯度计算 | 内存需求 | 收敛性 | 适用场景 |
|---|---|---|---|---|
| 批量梯度下降 | 全数据集 | 高 | 稳定 | 小数据集 |
| SGD | 单样本 | 低 | 震荡 | 在线学习 |
| 小批量SGD | 批量样本 | 中 | 平衡 | 最常见 |
数学表达式:
θ t + 1 = θ t − α ∇ θ J ( θ t ; x ( i ) , y ( i ) ) \theta_{t+1} = \theta_t - \alpha \nabla_\theta J(\theta_t; x^{(i)}, y^{(i)}) θt+1=θt−α∇θJ(θt;x(i),y(i))
实际应用示例(MNIST分类)
import torchvision
from torch.utils.data import DataLoader# 数据准备
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))
])
train_set = torchvision.datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=64, shuffle=True)# 模型定义
model = torch.nn.Sequential(torch.nn.Flatten(),torch.nn.Linear(784, 10)
)# 优化器配置
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 训练循环
losses = []
for epoch in range(5):for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = torch.nn.functional.cross_entropy(output, target)loss.backward()optimizer.step()# 记录损失losses.append(loss.item())# 绘制损失曲线
plt.figure(figsize=(12,6))
plt.plot(losses, alpha=0.6)
plt.title("SGD在MNIST分类任务中的损失曲线", fontsize=14)
plt.xlabel("Number of iterations", fontsize=12)
plt.ylabel("Cross-entropy loss", fontsize=12)
plt.grid(True, alpha=0.3)
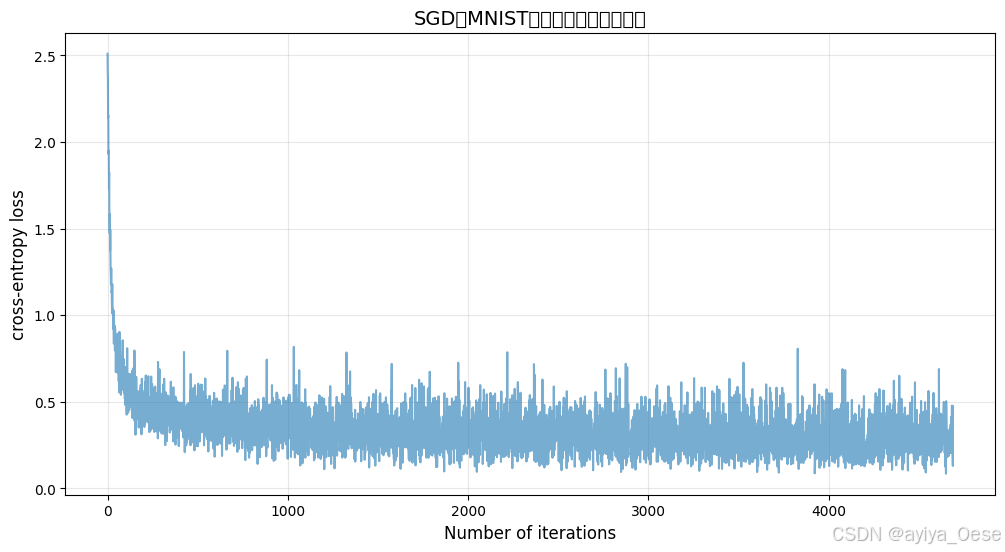
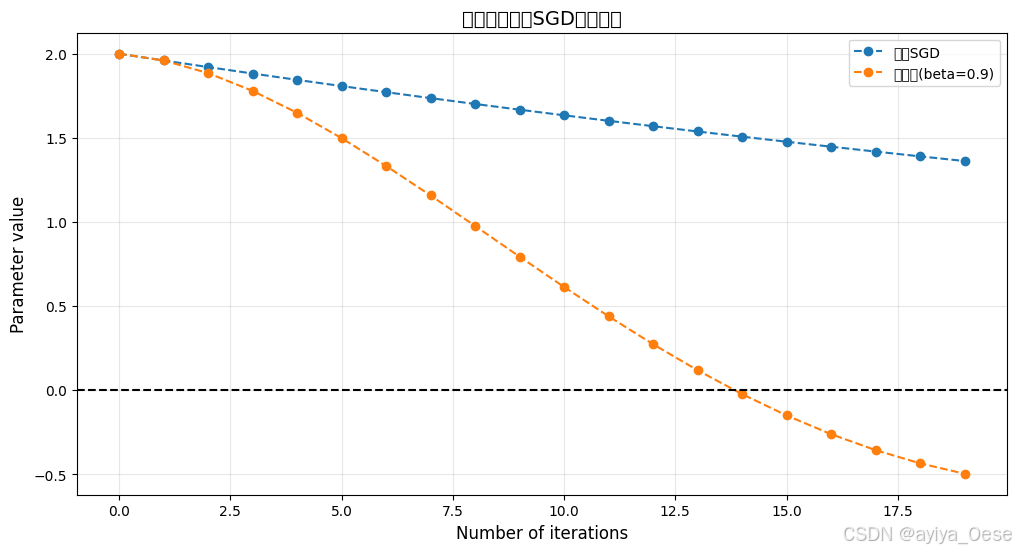
动量法(Momentum)
物理类比与数学表达
动量法引入速度变量 v v v,模拟物体运动惯性:
更新规则:
v t + 1 = β v t − α ∇ θ J ( θ t ) θ t + 1 = θ t + v t + 1 \begin{aligned} v_{t+1} &= \beta v_t - \alpha \nabla_\theta J(\theta_t) \\ \theta_{t+1} &= \theta_t + v_{t+1} \end{aligned} vt+1θt+1=βvt−α∇θJ(θt)=θt+vt+1
其中 β ∈ [ 0 , 1 ) \beta \in [0,1) β∈[0,1)为动量系数,典型值为0.9
对比实验
def optimize_with_momentum(lr=0.01, beta=0.9):x = torch.tensor([2.0], requires_grad=True)velocity = 0path = []for _ in range(20):path.append(x.item())loss = x**2loss.backward()with torch.no_grad():velocity = beta * velocity - lr * x.gradx += velocityx.grad.zero_()return path# 运行对比实验
paths = {'普通SGD': optimize_with_momentum(beta=0),'动量法(beta=0.9)': optimize_with_momentum()
}# 可视化对比
plt.figure(figsize=(12,6))
for label, path in paths.items():plt.plot(path, marker='o', linestyle='--', label=label)plt.title("动量法与普通SGD收敛对比", fontsize=14)
plt.xlabel("Number of iterations", fontsize=12)
plt.ylabel("Parameter value", fontsize=12)
plt.axhline(0, color='black', linestyle='--')
plt.legend()
plt.grid(True, alpha=0.3)
算法选择指南
| 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 梯度下降 | 稳定收敛 | 计算成本高 | 小规模数据集 |
| SGD | 内存需求低 | 收敛路径震荡 | 在线学习、大规模数据 |
| 动量法 | 加速收敛、抑制震荡 | 需调参动量系数 | 高维非凸优化 |
实践建议
- 学习率设置:从3e-4开始尝试,按数量级调整
- 批量大小:通常选择2的幂次(32, 64, 128)
- 动量系数:默认0.9,对RNN可尝试0.99
- 学习率衰减:配合StepLR或CosineAnnealing使用效果更佳
# 最佳实践示例:带学习率衰减的动量SGD
optimizer = torch.optim.SGD(model.parameters(),lr=0.1,momentum=0.9,weight_decay=1e-4 # L2正则化
)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)