企业网站备案要关站吗google安卓手机下载
1. 概述
1.1 主从复制概述
在生产环境中,随着业务量增长,数据库的读写压力会不断加大。为了提升系统的可用性、扩展性与数据安全性,主从复制(Replication) 成为一种常见的数据库架构方案。通过主从复制:
- 读写分离:主库处理写操作,从库处理读操作,提升整体性能。
- 高可用性:主库故障后可快速切换到从库,提高系统稳定性。
- 数据备份:从库作为热备份,提升数据安全。
- 数据分析:从库可用于数据分析、报表查询等业务,减少对主库影响。
1.2 主从复制类型
MySQL 提供多种主从复制模式:
| 类型 | 简介 | 特点 |
|---|---|---|
| 基于语句(Statement-Based Replication, SBR) | 复制 SQL 语句 | 简单、可能因非确定性函数出错 |
| 基于行(Row-Based Replication, RBR) | 复制变更的数据行 | 精确、安全但数据量大 |
| 混合模式(Mixed-Based Replication, MBR) | 自动在 SBR 与 RBR 之间切换 | 综合两者优点 |
当前多数生产环境推荐使用 Row-Based(RBR)。
2. 主从复制原理
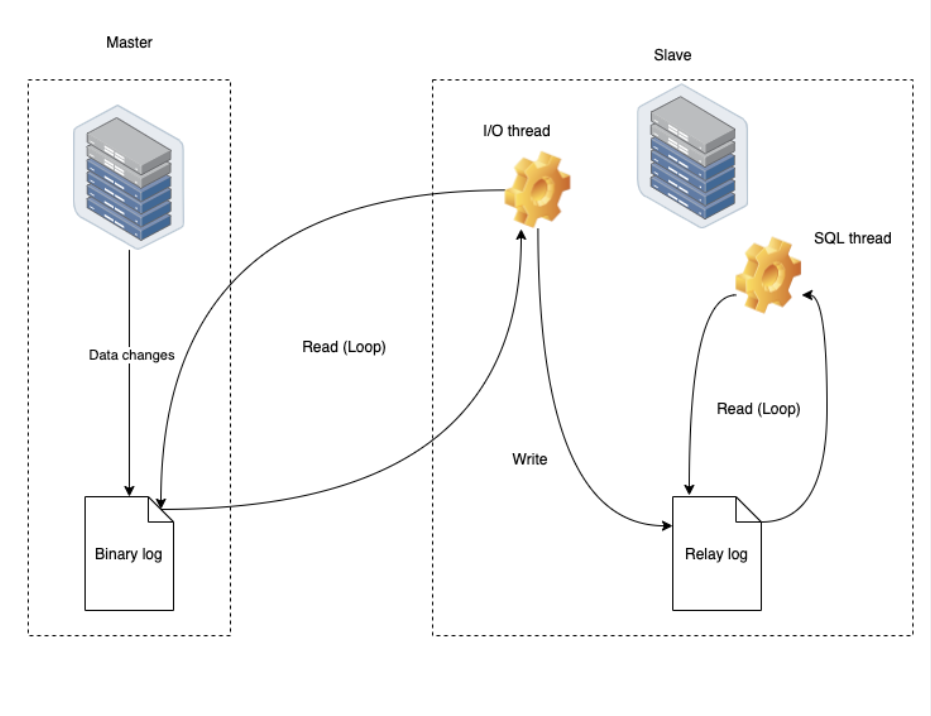
MySQL 主从复制(Replication)是通过**复制主库上的二进制日志(binlog)**来实现从库数据同步的过程。整个过程可以分为 五个步骤 和 三个关键线程,分别在主库与从库之间协作完成。
2.1 主从复制的关键线程
| 线程 | 所在节点 | 作用 |
|---|---|---|
| Binlog Dump Thread | 主库 | 监听并推送 binlog 变更给从库 |
| I/O Thread | 从库 | 向主库请求 binlog,并写入本地中继日志(relay log) |
| SQL Thread | 从库 | 读取 relay log,并按顺序执行日志中的 SQL 操作 |
2.2 主从复制的具体步骤
-
主库记录 binlog 日志
当主库执行INSERT、UPDATE、DELETE等 DML 操作时,会将这些更改以事件(event)的形式按顺序写入到 binlog(二进制日志)中。这个日志记录的是数据变化的“描述”。 -
从库发起连接请求(I/O Thread)
从库通过 I/O 线程连接主库,并向主库请求从某个位置(指定的 binlog 文件和偏移量)开始读取 binlog 数据。 -
主库启动 Binlog Dump Thread 发送日志
主库接收到从库连接请求后,会启动一个专用的 Binlog Dump 线程,实时监听 binlog 的变化,并将新生成的 binlog 内容发送给对应的从库。 -
从库接收并写入 relay log(中继日志)
从库的 I/O Thread 接收到主库发送的 binlog 数据后,会将这些日志写入到本地的 relay log(中继日志)文件中,作为一个临时的日志缓冲。 -
从库重放 relay log 执行 SQL(SQL Thread)
从库的 SQL Thread 会不断读取 relay log 中的日志内容,并解析并按顺序执行日志中的操作,从而在从库上“重放”主库的数据更改,实现数据同步。
3. 搭建主从复制环境
这里以一主一从为例,假设两台服务器,主库 IP 为
192.168.10.10,从库 IP 为192.168.10.20,MySQL 版本为 8.0。
3.1 主库配置
(1)修改配置文件 my.cnf(或 my.ini)
[mysqld]
server-id=1
log-bin=mysql-bin
binlog_format=row
server-id:每个节点必须唯一。log-bin:启用 binlog 日志。binlog_format=row:推荐使用 RBR。
重启 MySQL 服务:
sudo systemctl restart mysqld
mysqld是 MySQL 数据库服务器的核心进程,负责处理所有客户端请求、SQL 执行和数据管理等核心功能。
(2)创建复制用户
CREATE USER 'repl'@'192.168.10.%' IDENTIFIED BY 'repl_pass';
GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO 'repl'@'192.168.10.%';
FLUSH PRIVILEGES;
(3)查看主库状态
SHOW MASTER STATUS;
记录下 File 和 Position,后续配置从库时使用。
3.2 从库配置
(1)修改配置文件 my.cnf
[mysqld]
server-id=2
relay-log=relay-log
read_only=1
server-id必须与主库不同。relay-log指定中继日志名。read_only=1可防止从库被误写(非 root 用户)。
重启服务:
sudo systemctl restart mysqld
(2)连接主库配置复制信息
CHANGE MASTER TOMASTER_HOST='192.168.10.10',MASTER_USER='repl',MASTER_PASSWORD='repl_pass',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=120;
注意:MASTER_LOG_FILE 和 MASTER_LOG_POS 使用主库 SHOW MASTER STATUS 的结果。
(3)启动复制进程
START SLAVE;
(4)查看复制状态
SHOW SLAVE STATUS\G
重点关注:
Slave_IO_Running: YesSlave_SQL_Running: Yes
如果两项均为 Yes,表示复制正常。
4. 验证主从复制是否成功
你可以通过以下方式验证主从复制是否成功并生效:
4.1 在主库插入数据,在从库查询
主库:
USE test;
CREATE TABLE test_rep (id INT PRIMARY KEY, val VARCHAR(100));
INSERT INTO test_rep VALUES (1, 'hello replication');
从库:
SELECT * FROM test.test_rep;
如果看到相同数据,说明复制成功。
4.2 观察从库 Seconds_Behind_Master
SHOW SLAVE STATUS\G
字段 Seconds_Behind_Master 为 0 表示从库基本无延迟。
明白了!以下是你博客的第五部分内容,基于 ShardingSphere-JDBC 实现 Spring Boot 中的 MySQL 主从读写分离,避开了繁琐的手动路由切换,采用官方推荐的配置方式实现自动读写分离,更贴合真实项目场景,步骤完整,开箱即用。
5. 应用层读写分离
在主从复制搭建完成后,我们可以借助 Apache ShardingSphere-JDBC 快速实现 读写分离,让应用层自动将写操作路由到主库,将读操作路由到从库,简化开发,提升系统性能。
相比手动多数据源和注解控制的方式,ShardingSphere-JDBC 更加灵活、配置集中,且支持负载均衡、读写一致性策略、分库分表等高级功能。
5.1 实现原理
ShardingSphere-JDBC 在应用层以 JDBC Driver 的形式接入,通过解析 SQL 并结合配置的读写策略,自动将:
- 写请求(INSERT/UPDATE/DELETE) 路由到主库;
- 读请求(SELECT) 路由到从库(可设置负载均衡策略);
整个过程对业务代码透明,无需更改 Mapper 接口或注解。
5.2 实现步骤
5.2.1 添加依赖
<dependencies><!-- Spring Boot Starter Web --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>3.1.5</version></dependency><!-- MyBatis Starter --><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>3.0.3</version></dependency><!-- ShardingSphere JDBC --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.4.1</version></dependency><!-- Druid --><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.16</version></dependency><!-- MySQL Connector --><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>8.0.33</version><scope>runtime</scope></dependency><!-- Lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.30</version><scope>provided</scope></dependency></dependencies>
5.2.2 配置 application.yml
spring:shardingsphere:datasource:names: master, slave1, slave2 # 定义数据源名称master:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/master_db?useSSL=false&serverTimezone=UTCusername: rootpassword: password# Druid连接池配置druid:initial-size: 5min-idle: 5max-active: 20max-wait: 60000time-between-eviction-runs-millis: 60000min-evictable-idle-time-millis: 300000test-while-idle: truetest-on-borrow: falsetest-on-return: falsefilters: stat,wall # 监控统计和SQL防火墙slave1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3307/slave_db1?useSSL=false&serverTimezone=UTCusername: rootpassword: passworddruid:initial-size: 5min-idle: 5max-active: 20slave2:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3308/slave_db2?useSSL=false&serverTimezone=UTCusername: rootpassword: passworddruid:initial-size: 5min-idle: 5max-active: 20masterslave:name: ms_ds # 主从数据源名称master-data-source-name: master # 主库数据源slave-data-source-names: slave1, slave2 # 从库数据源列表load-balance-algorithm-type: round_robin # 从库负载均衡策略props:sql-show: true # 打印SQL日志(调试用)
注意:这里如果不配置masterslave也可以实现数据的读取,但是往数据库里面写入数据会报错,因为shardingsphere无法确定哪一个是主节点,默认情况下都是从节点。
5.2.3 Mapper 和 Service代码
@Mapper
public interface UserMapper {@Insert("INSERT INTO user (name, email) VALUES (#{name}, #{email})")void insert(User user);@Select("SELECT * FROM user WHERE id = #{id}")User findById(Long id);
}
@Service
public class UserService {public void create(User user) {userMapper.insert(user); // 自动走主库}public User query(Long id) {return userMapper.findById(id); // 自动走从库}
}
5.2.4 验证读写分离
- 启动应用后执行读写操作;
- 查看控制台打印 SQL,对应的数据库连接地址即为执行的库(主/从);
- 也可开启数据库日志或通过慢查询日志判断实际访问库。
示例日志片段:
Logic SQL: SELECT * FROM user WHERE id = ?
Actual SQL: slave ::: SELECT * FROM user WHERE id = ?