网站后台超链接怎么做小程序生成平台系统
在当今数字化时代,社交媒体平台已成为人们日常生活中不可或缺的一部分。作为中国最受欢迎的社交平台之一,微博不仅为用户提供了一个分享信息、表达观点的空间,还通过其丰富的功能如签到服务,让用户能够记录自己生活中的点点滴滴。这些由用户生成的数据蕴含着巨大的价值,无论是对于学术研究、市场营销还是个人兴趣探索而言。然而,获取并分析这些数据并非易事。微博签到数据的收集通常需要面对诸如数据量庞大、结构复杂以及访问权限等挑战。随着Python编程语言及其相关库(如Requests、BeautifulSoup、Selenium等)的发展,开发者现在拥有了一系列强大的工具来构建网络爬虫,从而自动抓取网页内容,从中提取所需的信息。
本文将探讨如何利用GET请求从微博API或网页上获取用户的签到数据,并展示使用Python的requests库发送GET请求的方法,以提取详细的用户签到位置信息。关键词地点的签到记录,并通过解析JSON格式的数据或HTML页面来处理响应数据。我们关注的是微博平台上用户的活动足迹及其地理分布情况。这种做法有助于我们更深入地了解微博用户的社交行为模式、偏好变化趋势以及在不同地区的活跃度和消费趋势。通过对微博签到数据的分析,我们可以揭示出更多有价值的市场洞察和社会现象。
微博手机版网页:微博
我们第一步先找到微博签到数据的存储位置,先检索"上海",然后点击地点,选择上海,选择其他的地点或者关键词都可,这里仅做演示;
接下来,通过检索用户微博内容可以进一步发现,具体数据套了很多层级,最后发现在card_type为9的mblog里面才是用户发布的微博;
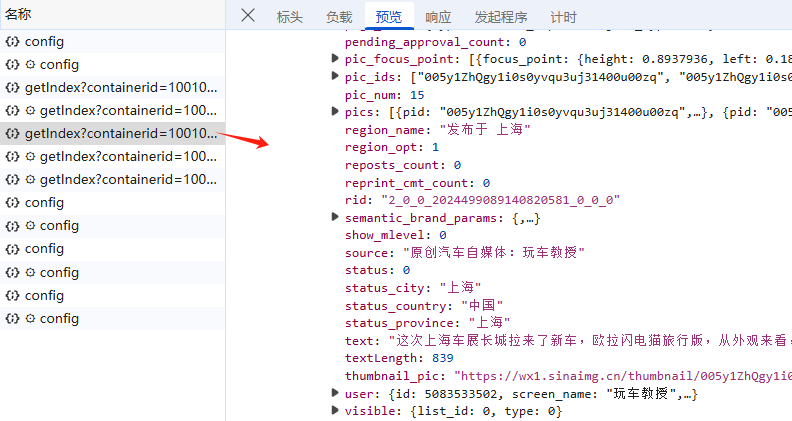
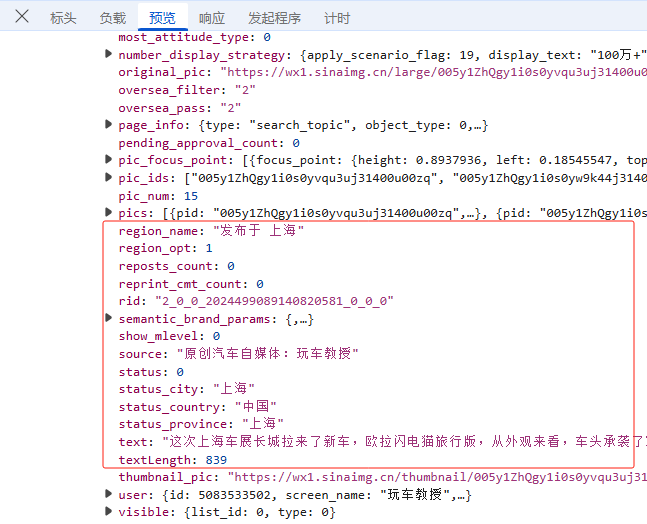
然后,看3个关键部分标头、负载、 预览;
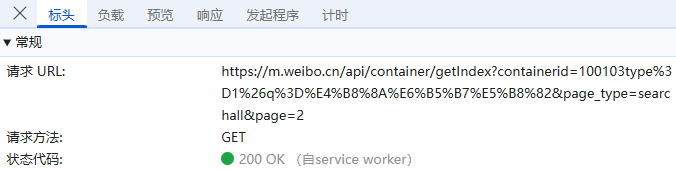
标头:通常包括URL的连接,也就是目标资源的位置;
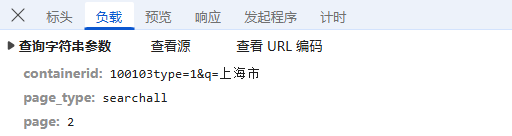
负载:对于GET请求:负载通常包含了传递的参数,这里我们可以看到它的传参包括,位置关键词、页码,还是明文,没有进行加密;
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应数据存储位置,获取所有打卡地点的相关微博发布内容;
- 通过修改MAX PAGES来调整获取页数;
- 坐标汇总并可视化,数据导入ArcGIS进行可视化;
第一步:我们先找到对应数据存储位置,这里可以通过修改页码进行遍历所有页面,"MAX PAGES= 你需要获取的页面最大值";
完整代码#运行环境 Python 3.11
# -*- coding: utf-8 -*-
import requests
import html
import re
import time
import random
import pandas as pd
from datetime import datetimeCONTAINER_ID = "100808e94e8bd35fc8144f38fd1ebc1f81ab36_-_lbs" # 填入你要爬取的地点对应的 containerid
# 最多抓取多少页
MAX_PAGES = 20
# 每次请求后随机 sleep,降低封禁风险
SLEEP_RANGE = (1, 3)def get_headers():"""构造请求头,包含随机 User-Agent 和 Referer"""ua_list = ["Mozilla/5.0 (iPhone; CPU iPhone OS 14_0 like Mac OS X) ""AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 ""Mobile/15E148 Safari/604.1","Mozilla/5.0 (Linux; Android 10; Pixel 4 XL Build/QQ3A.200805.001) ""AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.127 Mobile Safari/537.36",]return {"User-Agent": random.choice(ua_list),"Referer": "https://m.weibo.cn",}def fetch_page(session, containerid, since_id=None):url = "https://m.weibo.cn/api/container/getIndex"params = {"containerid": containerid,"lcardid": "frompoi","extparam": "frompoi","luicode": "10000011","lfid": "231583"}if since_id:params["since_id"] = since_idresp = session.get(url, params=params, headers=get_headers(), timeout=10)resp.raise_for_status()return resp.json()def clean_text(raw_html: str) -> str:"""HTML 解码并去除所有标签,返回纯文本"""text = html.unescape(raw_html)return re.sub(r'<.*?>', '', text).strip()def trans_format(time_string: str) -> str:"""将微博 API 返回的时间字符串转换为 'YYYY-MM-DD HH:MM:SS' 格式。原始示例:Tue Apr 18 08:13:28 +0800 2023"""from_format = '%a %b %d %H:%M:%S +0800 %Y'to_format = '%Y-%m-%d %H:%M:%S'try:dt = datetime.strptime(time_string, from_format)return dt.strftime(to_format)except Exception:return time_stringdef parse_cards(json_data: dict) -> list:"""从一页 JSON 中提取所有 card_type==9 的用户微博(签到贴)。兼容首页(card_group)和后续页(直接 mblog)两种结构。返回列表,每项包含:用户名(user)、内容(content)、发布时间(created_at)、签到地点(location)、客户端来源(source)、地点标签(page_title) 和 地址标签(content1)"""results = []data = json_data.get("data", {}) or {}cards = data.get("cards", []) or []for card in cards:# 后续页直接 mblog;首页在 card_groupcandidates = []if card.get("mblog"):candidates.append(card)candidates.extend(card.get("card_group") or [])for entry in candidates:m = entry.get("mblog")if not m or entry.get("card_type") != 9:continue# 原始字段user_raw = m.get("user", {}).get("screen_name", "")text_html = m.get("text", "")created_raw = m.get("created_at", "")source_html = m.get("source", "")page_info = m.get("page_info", {}) or {}# 清洗与转换user = user_rawcontent = clean_text(text_html)created_at = trans_format(created_raw)source = clean_text(source_html)page_title = page_info.get("page_title", "")content1 = page_info.get("content1", "")# 提取“城市·区域”形式的签到地点loc_match = re.search(r'([\u4e00-\u9fa5]+·[\u4e00-\u9fa5]+)', content)location = loc_match.group(1) if loc_match else ""results.append({"user": user,"content": content,"created_at": created_at,"location": location,"source": source,"page_title": page_title,"content1": content1})return resultsdef main():session = requests.Session()since_id = Noneall_items = []for page in range(1, MAX_PAGES + 1):print(f"正在抓取 第 {page} 页 … since_id={since_id}")try:js = fetch_page(session, CONTAINER_ID, since_id)except Exception as e:print("请求失败,跳过:", e)breakitems = parse_cards(js)if not items:print("未获取到更多数据,结束。")breakall_items.extend(items)# 获取下一页的 since_id,不存在则停止page_info = js.get("data", {}).get("pageInfo") or {}since_id = page_info.get("since_id")if not since_id:print("since_id 未找到,结束翻页。")breaktime.sleep(random.uniform(*SLEEP_RANGE))# 保存到 CSV,并去重(含所有字段)if all_items:df = pd.DataFrame(all_items)df.drop_duplicates(subset=['user','content','created_at','location','source','page_title','content1'],inplace=True)df.to_csv("weibo_sign.csv", index=False, encoding="utf-8-sig")print(f"共抓取 {len(df)} 条签到数据(去重后),已保存到 weibo_sign.csv")else:print("未抓取到任何数据。")if __name__ == "__main__":main()获取数据标签如下, user(用户名)、content(分布内容)、location(打卡点)、source(机型)、content1(具体地址),也可以返回内容自行增加一些标签,其他一些非关键标签,这里省略;
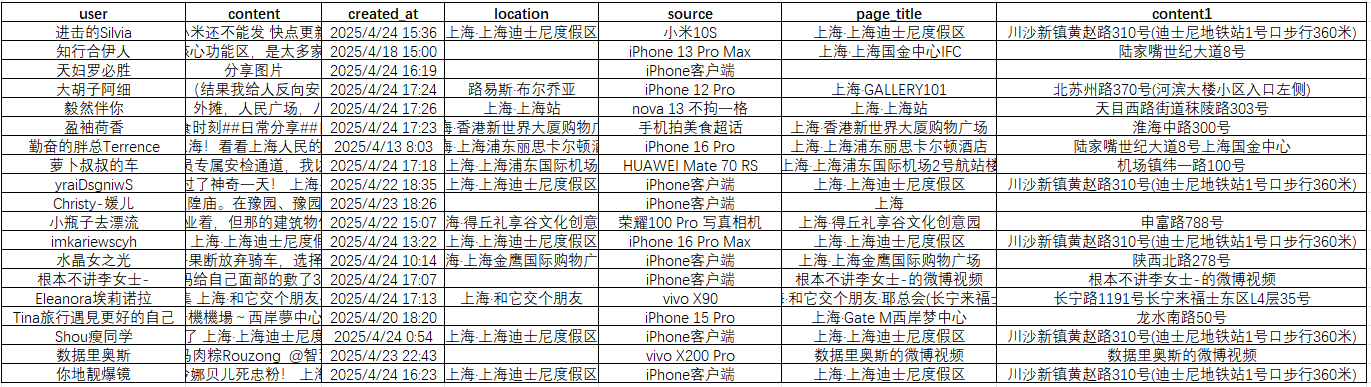
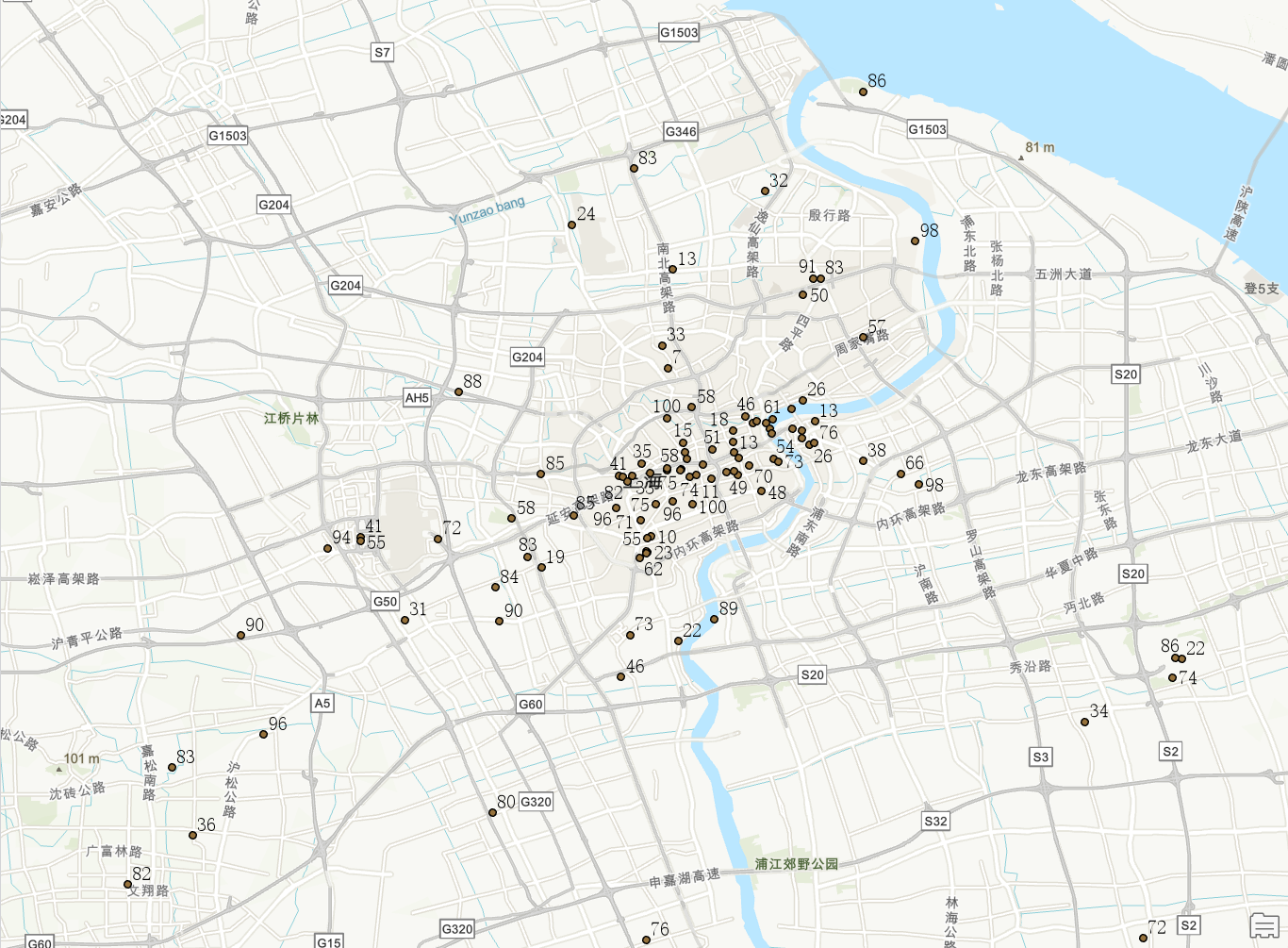
第三步:坐标聚类可视化,因为数据本身是一个个热门打卡点,就可以通过聚类打卡点和详细坐标的地理编码转坐标来进行可视化,和打卡热点位置分析;
这里有个几个小tips,1、如果你输入区域爬不到数据的时候,记得F12看看第二页的分页参数,把since_id改成page就可以正常爬取数据了,就像上海这里分页就是page;
2、首页是不带页码的,后续是需要页码的;
3、参数配置:CONTAINER_ID = "100808e94e8bd35fc8144f38fd1ebc1f81ab36_-_lbs" # 填入你要爬取的地点对应的 containerid,这个参数在负载里面,替换一下即可;
4、经实际测试多次跑下来结果并不一致,可能数据是实时更新的或者其他原因;
参考:Python爬取微博签到数据(2025年3月更)_微博签到打卡数据爬取-CSDN博客
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。