大朗镇仿做网站北京朝阳区疫情最新情况
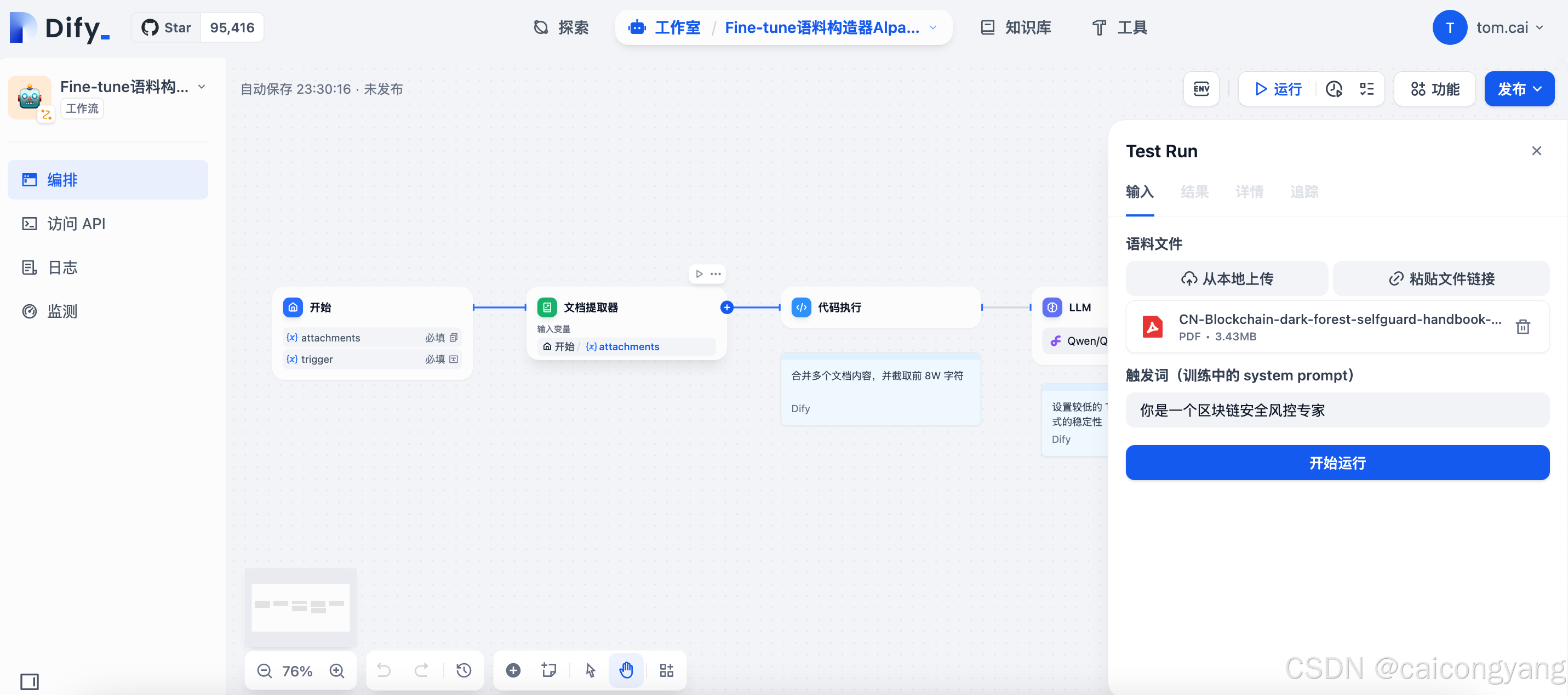
如果你选择llamafactory 格式进行微调,它只是格式是Alpaca格式,dify 的agent dsl 如下,你可以导入本地的dify 或者导入cloud 版本的;测试版本是0.1.5
app:description: '上传文件,基于文件内容,使用 SiliconCloud 128K 上下文的 Qwen2.5 模型,生成日常问答内容,JSONL 格式的语料数据⚠️ 注:- 由于 Dify 限制,超过 80000 字符的文件内容会被截断- 生成内容仅供参考,可能存在幻觉或内容错漏、格式错误,请注意甄别'icon: 🤖icon_background: '#FFEAD5'mode: workflowname: 'Fine-tune语料构造器Alpaca格式 'use_icon_as_answer_icon: false
kind: app
version: 0.1.5
workflow:conversation_variables: []environment_variables: []features:file_upload:allowed_file_extensions:- .JPG- .JPEG- .PNG- .GIF- .WEBP- .SVGallowed_file_types:- imageallowed_file_upload_methods:- local_file- remote_urlenabled: falsefileUploadConfig:audio_file_size_limit: 50batch_count_limit: 5file_size_limit: 15image_file_size_limit: 10video_file_size_limit: 100workflow_file_upload_limit: 10image:enabled: falsenumber_limits: 3transfer_methods:- local_file- remote_urlnumber_limits: 3opening_statement: ''retriever_resource:enabled: truesensitive_word_avoidance:enabled: falsespeech_to_text:enabled: falsesuggested_questions: []suggested_questions_after_answer:enabled: falsetext_to_speech:enabled: falselanguage: ''voice: ''graph:edges:- data:isInIteration: falsesourceType: starttargetType: document-extractorid: 1735807686274-source-1735807758092-targetsource: '1735807686274'sourceHandle: sourcetarget: '1735807758092'targetHandle: targettype: customzIndex: 0- data:isInIteration: falsesourceType: document-extractortargetType: codeid: 1735807758092-source-1735807761855-targetsource: '1735807758092'sourceHandle: sourcetarget: '1735807761855'targetHandle: targettype: customzIndex: 0- data:isInIteration: falsesourceType: codetargetType: llmid: 1735807761855-source-1735807764975-targetsource: '1735807761855'sourceHandle: sourcetarget: '1735807764975'targetHandle: targettype: customzIndex: 0- data:isInIteration: falsesourceType: llmtargetType: endid: 1735807764975-source-1735807769820-targetsource: '1735807764975'sourceHandle: sourcetarget: '1735807769820'targetHandle: targettype: customzIndex: 0nodes:- data:desc: ''selected: falsetitle: 开始type: startvariables:- allowed_file_extensions: []allowed_file_types:- documentallowed_file_upload_methods:- local_file- remote_urllabel: 语料文件max_length: 10options: []required: truetype: file-listvariable: attachments- allowed_file_extensions: []allowed_file_types:- imageallowed_file_upload_methods:- local_file- remote_urllabel: 触发词(训练中的 system prompt)max_length: 48options: []required: truetype: text-inputvariable: triggerheight: 116id: '1735807686274'position:x: 30y: 258positionAbsolute:x: 30y: 258selected: falsesourcePosition: righttargetPosition: lefttype: customwidth: 244- data:desc: ''is_array_file: trueselected: falsetitle: 文档提取器type: document-extractorvariable_selector:- '1735807686274'- attachmentsheight: 92id: '1735807758092'position:x: 334y: 258positionAbsolute:x: 334y: 258selected: falsesourcePosition: righttargetPosition: lefttype: customwidth: 244- data:code: "def main(articleSections: list) -> dict:\n try:\n # 将列表项合并为字符串\n\\ combined_text = \"\\n\".join(articleSections)\n \n \\ # 截取前80000个字符\n truncated_text = combined_text[:80000]\n \\ \n return {\n \"result\": truncated_text\n \\ }\n except Exception as e:\n # 错误处理\n return {\n \\ \"result\": \"\"\n }"code_language: python3desc: ''outputs:result:children: nulltype: stringselected: falsetitle: 代码执行type: codevariables:- value_selector:- '1735807758092'- textvariable: articleSectionsheight: 54id: '1735807761855'position:x: 638y: 258positionAbsolute:x: 638y: 258selected: falsesourcePosition: righttargetPosition: lefttype: customwidth: 244- data:context:enabled: falsevariable_selector: []desc: ''model:completion_params:frequency_penalty: 0.5max_tokens: 4096temperature: 0.3mode: chatname: Qwen/Qwen2.5-72B-Instruct-128Kprovider: siliconflowprompt_template:- id: b6913d40-d173-45d8-b012-98240d42a196role: systemtext: "【角色】 \n你是一位 LLM 大语言模型科学家,参考用户提供的「内容」,帮助用户构造符合规范的 Fine‑tune(微调)数据。\\ \n\n【任务】 \n- 针对每次给定的「内容」,生成通俗易懂、贴近现实的「问题」(instruction); \n- 针对每个「问题」,引用「内容」原文并结合合理解释,给出忠实于原文主旨的「解答」(output);\\ \n- 最终所有条目以 Alpaca 格式输出,每条一行 JSON,组成合法的 JSONL 文件。 \n\n【Alpaca 格式说明】\\ \n每条数据必须包含三个字段: \n```json\n{\n \"instruction\": \"问题(贴近现实、通俗白话)\"\,\n \"input\": \"使用用户指定的「触发词」\",\n \"output\": \"解答(忠于原文、合理演绎)\"\n}\n\```\n\n【要求】\n1.“instruction” 中的问题不要直接照搬「内容」原句,需贴近当代生活场景;\n2.问题用语通俗,避免“假、大、空”;\n\3.“output” 必须忠于原文主旨,不得曲解;可在原文基础上合理演绎;\n\n【输出规范】\n1.输出为标准 JSONL 文本,每行一个\\ JSON 对象;\n2.不要在输出中添加多余注释或说明文字;\n3.每行对应一条训练样本;\n4.保证整体文件格式合法,可直接用于微调。\n\【示例】\n```json\n{\"instruction\": \"为什么我们在家里养的绿植会在有阳光的房间里长得更好?\", \"input\"\: \"光合作用是植物将光能转化为化学能的过程……\", \"output\": \"因为光合"- id: 61530521-14cf-4eaf-8f06-a4bc89db3cb1role: usertext: '「内容」{{#1735807761855.result#}}「触发词」{{#1735807686274.trigger#}}'selected: falsetitle: LLMtype: llmvariables: []vision:enabled: falseheight: 98id: '1735807764975'position:x: 937.9650491140262y: 258positionAbsolute:x: 937.9650491140262y: 258selected: truesourcePosition: righttargetPosition: lefttype: customwidth: 244- data:desc: ''outputs:- value_selector:- '1735807764975'- textvariable: textselected: falsetitle: 结束type: endheight: 90id: '1735807769820'position:x: 1246y: 258positionAbsolute:x: 1246y: 258selected: falsesourcePosition: righttargetPosition: lefttype: customwidth: 244- data:author: Difydesc: ''height: 88selected: falseshowAuthor: truetext: '{"root":{"children":[{"children":[{"detail":0,"format":0,"mode":"normal","style":"","text":"设置较低的Temperature,提高输出格式的稳定性","type":"text","version":1}],"direction":"ltr","format":"","indent":0,"type":"paragraph","version":1,"textFormat":0}],"direction":"ltr","format":"","indent":0,"type":"root","version":1}}'theme: bluetitle: ''type: ''width: 240height: 88id: '1735808753316'position:x: 951.4285714285714y: 375.7142857142857positionAbsolute:x: 951.4285714285714y: 375.7142857142857selected: falsesourcePosition: righttargetPosition: lefttype: custom-notewidth: 240- data:author: Difydesc: ''height: 88selected: falseshowAuthor: truetext: '{"root":{"children":[{"children":[{"detail":0,"format":0,"mode":"normal","style":"","text":"合并多个文档内容,并截取前8W 字符","type":"text","version":1}],"direction":"ltr","format":"","indent":0,"type":"paragraph","version":1,"textFormat":0}],"direction":"ltr","format":"","indent":0,"type":"root","version":1}}'theme: bluetitle: ''type: ''width: 240height: 88id: '1735808799815'position:x: 640y: 338.5714285714286positionAbsolute:x: 640y: 338.5714285714286selected: falsesourcePosition: righttargetPosition: lefttype: custom-notewidth: 240viewport:x: 16.889594857123143y: 9.872527989539648zoom: 0.7632446373312666
如果你想生产openai 支持的JSONL格式,只需要稍微调整下其中LLM 的提示词
【角色】
你是一位 LLM 大语言模型科学家,参考用户提供的内容,帮助用户构造符合规范的 Fine-tune(微调)数据【任务】
- 对于给定的「内容」,你每次回列出尽可能多的通俗「问题」;
- 针对每个「问题」,引用「内容」原文及对内容的合理解释和演绎,做出「解答」;
- 并将「问题」「解答」整理为规范的 JSONL 格式【要求】
1. 问题 **不要** 直接引用「内容」,应该贴近当代现实生活;
2. 问题应该是通俗白话,避免“假、大、空“;
3. 答案应忠于原文,对于原文的解释不能脱离原文的主旨、思想;【输出规范】
* 输出规范的 JSONL,每行一条数据
* 每条数据应包含一个 message 数组,每个数组都应该包含 role 分别为 system、user 和 assistant 的三条记录
* 其中 role 为 system 的数据,作为训练中的 system prompt 格外重要,其 content 使用用户指定的「触发词」
* role 为 user 的数据对应列出的「问题」
* role 为 assistant 的数据则对应针对「问题」的「解答」
* 示例如下:
```
{"messages": [{"role": "system", "content": "你是当代大儒"}, {"role": "user", "content": "应该怎么学习?"}, {"role": "assistant", "content": "贤贤易色;事父母,能竭其力;事君,能致其身;与朋友交,言而有信。虽曰未学,吾必谓之学矣。"}]}
```Java 码农转型AI 关于微调的更多内容可以查看我的github : https://github.com/caicongyang/ML2LLM/tree/main/LLM/lora