中小企业网络设计论文seo是什么学校
url=古诗文网-古诗文经典传承
进入登陆界面的网址:前提是你已经注册了账号
登录古诗文网
一、代码功能以及知识点的解释。
1. 准备工作
-
导入必要的库:
-
requests:用于发送HTTP请求 -
pytesseract:用于OCR识别验证码图片 -
PIL.Image:用于处理图片 -
lxml.etree:用于解析HTML
-
2. 设置请求头
-
定义了一个
header字典,包含User-Agent信息,模拟浏览器访问
3. 创建会话
-
使用
requests.session()创建一个会话对象,可以保持cookie等信息
4. 第一次请求(获取登录页面)
-
发送GET请求到登录页面URL
-
使用lxml解析HTML响应,提取两个隐藏表单字段:
-
__VIEWSTATE -
__VIEWSTATEGENERATOR
这些是ASP.NET网站常用的隐藏字段,用于维持页面状态
-
5. 获取验证码图片
-
从HTML中解析出验证码图片的URL
-
拼接完整的验证码URL
-
再次发送GET请求下载验证码图片
-
将图片保存为本地文件"code.png"
6. 识别验证码
-
使用PIL打开验证码图片
-
设置Tesseract OCR的路径
-
使用pytesseract识别图片中的文字,并去除前后空格
7. 模拟登录
-
检查识别出的验证码是否为4位(假设验证码长度为4)
-
如果是,构造POST数据,包括:
-
之前获取的VIEWSTATE和VIEWSTATEGENERATOR
-
用户名(email)
-
密码(pwd)
-
识别出的验证码(code)
-
登录按钮的值(denglu)
-
-
发送POST请求进行登录
-
打印响应文本(通常是登录后的页面)
-
-
如果验证码识别失败(不是4位),打印提示信息
二、代码的XPATH从哪寻找呢?
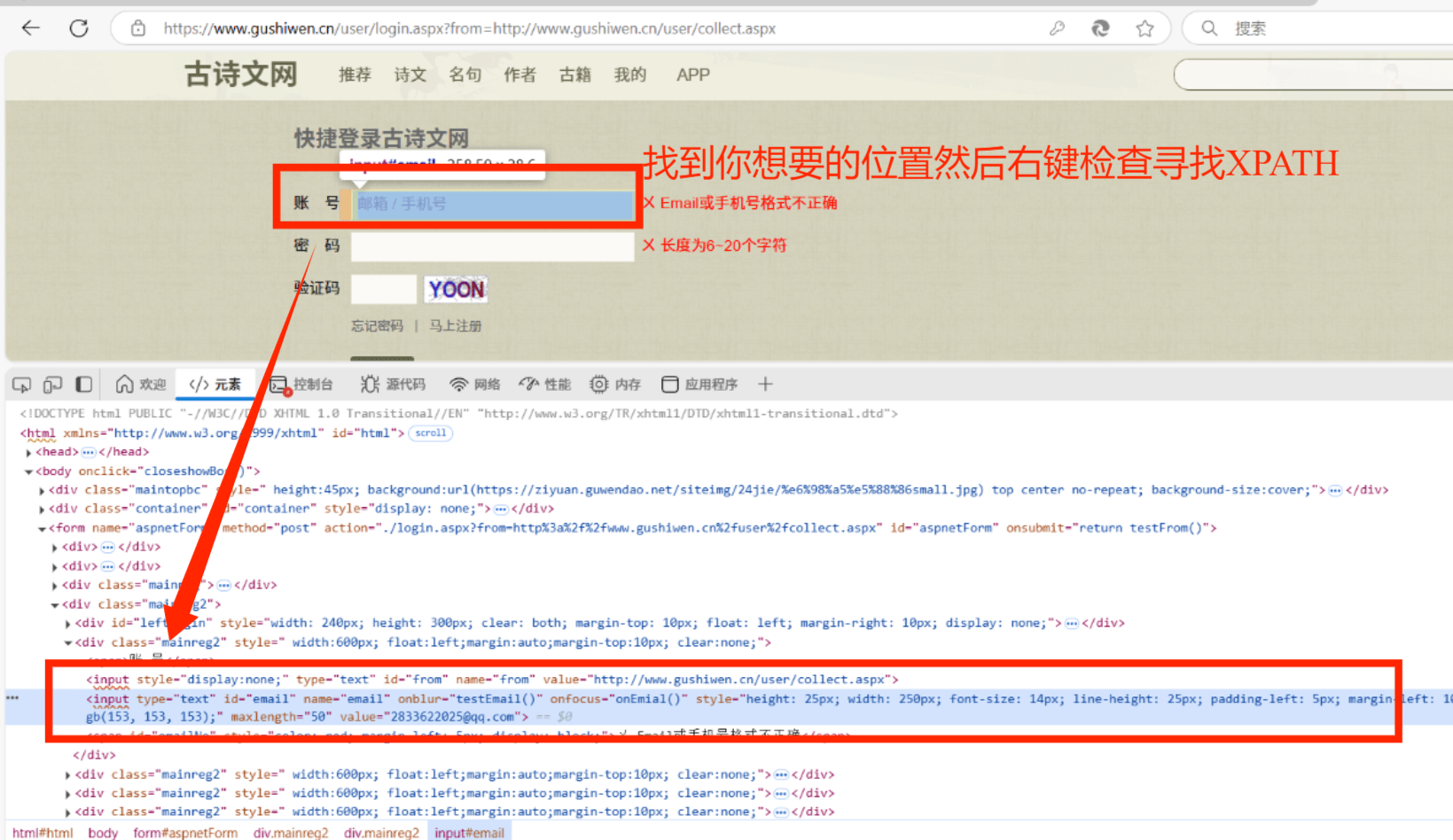
同时你必须有XPATH的扩展程序 具体如何下载在专栏里面有详细步骤
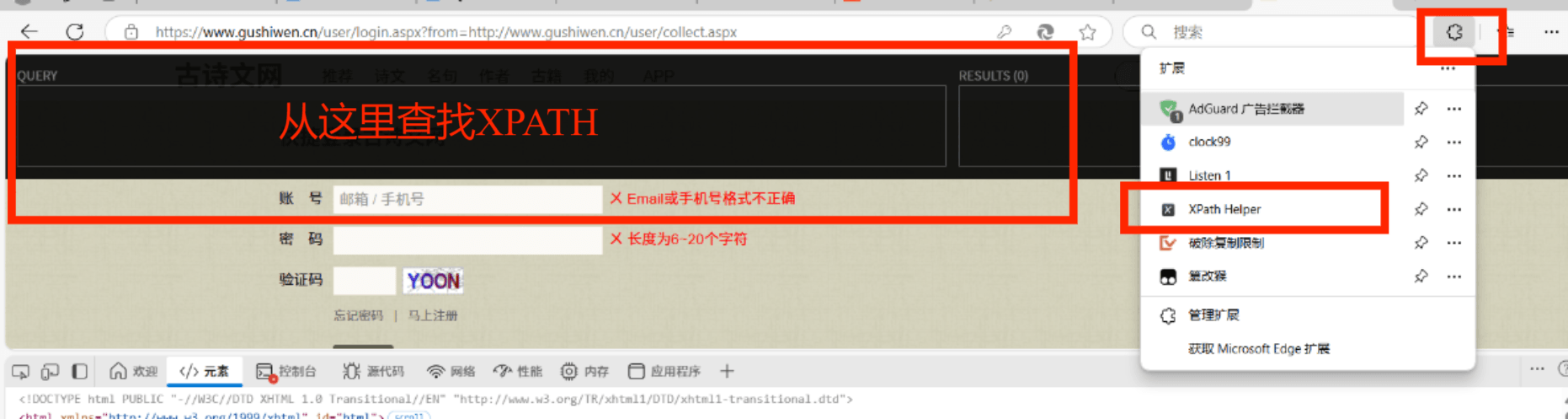
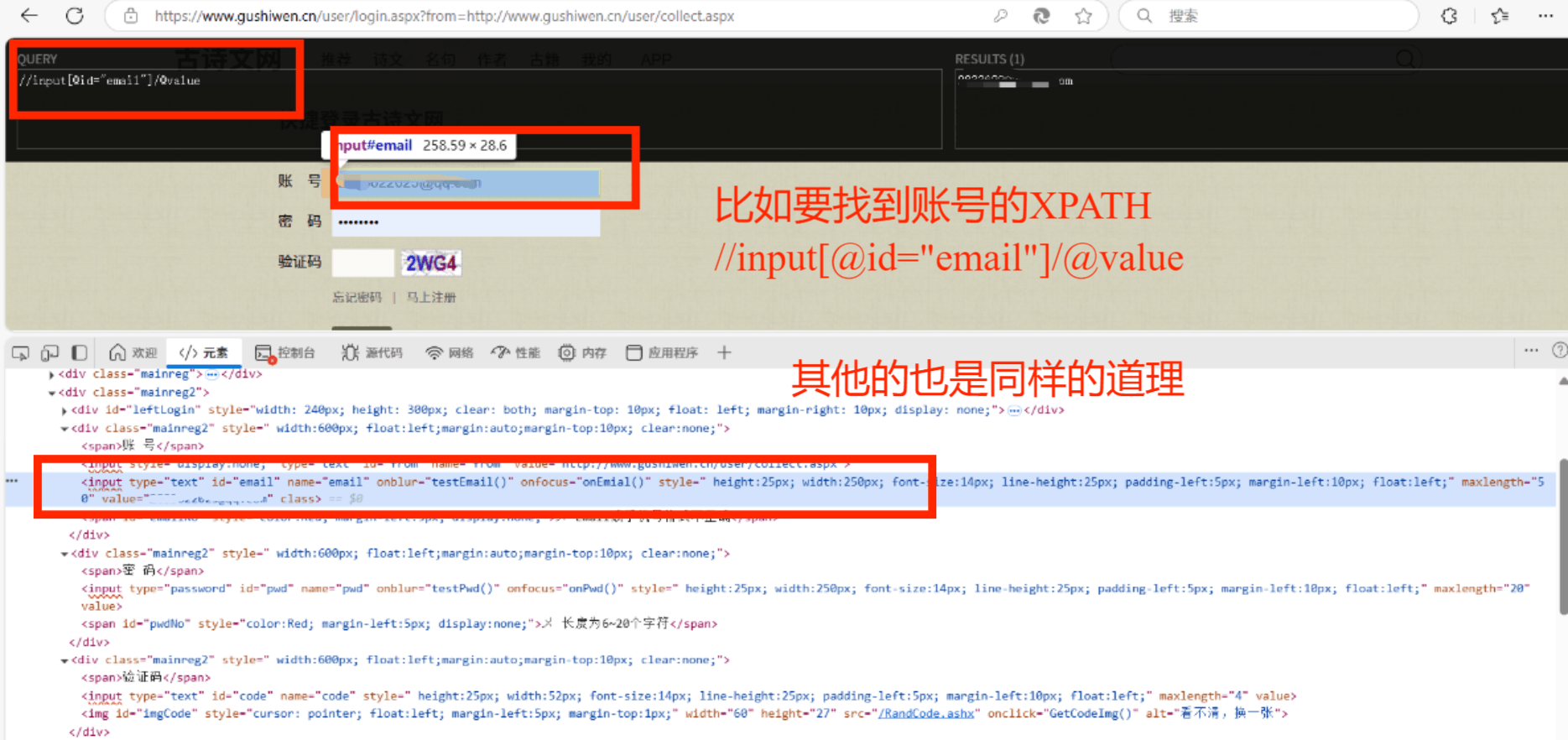
......
三、具体代码展示:
# 导入必要的库
import requests # 用于发送HTTP请求
import pytesseract as te # OCR库,用于识别验证码
from PIL import Image # 图像处理库,用于打开验证码图片
from lxml import etree # HTML解析库,用于提取页面中的元素# 设置请求头,模拟浏览器访问
header = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36"
}# 目标登录页面的URL
url = "https://www.gushiwen.cn/user/login.aspx?from=http://www.gushiwen.cn/user/collect.aspx"# 创建一个会话对象,用于保持cookies和会话状态
session = requests.session()# 第一步:获取登录页面,提取必要的隐藏字段和验证码URL
resp1 = session.get(url, headers=header) # 发送GET请求获取登录页面
html = etree.HTML(resp1.text) # 使用lxml解析HTML# 提取ASP.NET页面中的隐藏字段(用于表单提交)
viewstate = html.xpath("//input[@id='__VIEWSTATE']/@value")[0] # __VIEWSTATE值
viewstategenerator = html.xpath("//input[@id='__VIEWSTATEGENERATOR']/@value")[0] # __VIEWSTATEGENERATOR值# 构建验证码图片的完整URL(从页面中提取相对路径并拼接基础URL)
baseurl = "https://www.gushiwen.cn"
codeurl = baseurl + html.xpath("//img[@id='imgCode']/@src")[0] # 验证码图片URL# 第二步:下载验证码图片
resp2 = session.get(codeurl, headers=header) # 发送GET请求获取验证码图片
# 将验证码图片保存到本地
with open("code.png", "wb") as fp:fp.write(resp2.content) # 写入图片二进制数据# 第三步:使用OCR识别验证码
image = Image.open("code.png") # 打开验证码图片
# 设置Tesseract OCR的路径(需要根据实际安装路径修改)
te.pytesseract.tesseract_cmd = r"D:\Tesseract-OCR\tesseract.exe" #路径也是自己的
# 识别图片中的文字,并去除前后空格
textcode = te.pytesseract.image_to_string(image).strip()
print("识别出的验证码:", textcode)# 第四步:构造登录数据并提交
# 检查验证码是否识别成功(假设验证码长度为4)
if len(textcode) == 4:# 构造POST请求的表单数据data = {'__VIEWSTATE': viewstate, # ASP.NET页面状态字段'__VIEWSTATEGENERATOR': viewstategenerator, # ASP.NET页面生成器字段'email': '', # 登录邮箱'pwd': '', # 登录密码自己的'code': textcode, # 识别出的验证码'denglu': '登录' # 登录按钮的值}# 发送POST请求进行登录resp = session.post(url, data=data, headers=header)# 打印登录后的响应内容(通常是登录结果页面)print("登录响应内容:", resp.text)
else:print("验证码识别失败,长度不为4")关键注释说明:
-
会话管理:使用
requests.session()保持会话,确保验证码和登录请求在同一个会话中 -
ASP.NET隐藏字段:
__VIEWSTATE和__VIEWSTATEGENERATOR是ASP.NET网站的重要字段,必须随表单一起提交 -
验证码处理流程:
-
从页面解析验证码URL
-
下载并保存验证码图片
-
使用Tesseract OCR识别验证码
-
-
登录提交:构造完整表单数据并发送POST请求
-
错误处理:简单检查验证码长度,实际应用中可能需要更复杂的验证
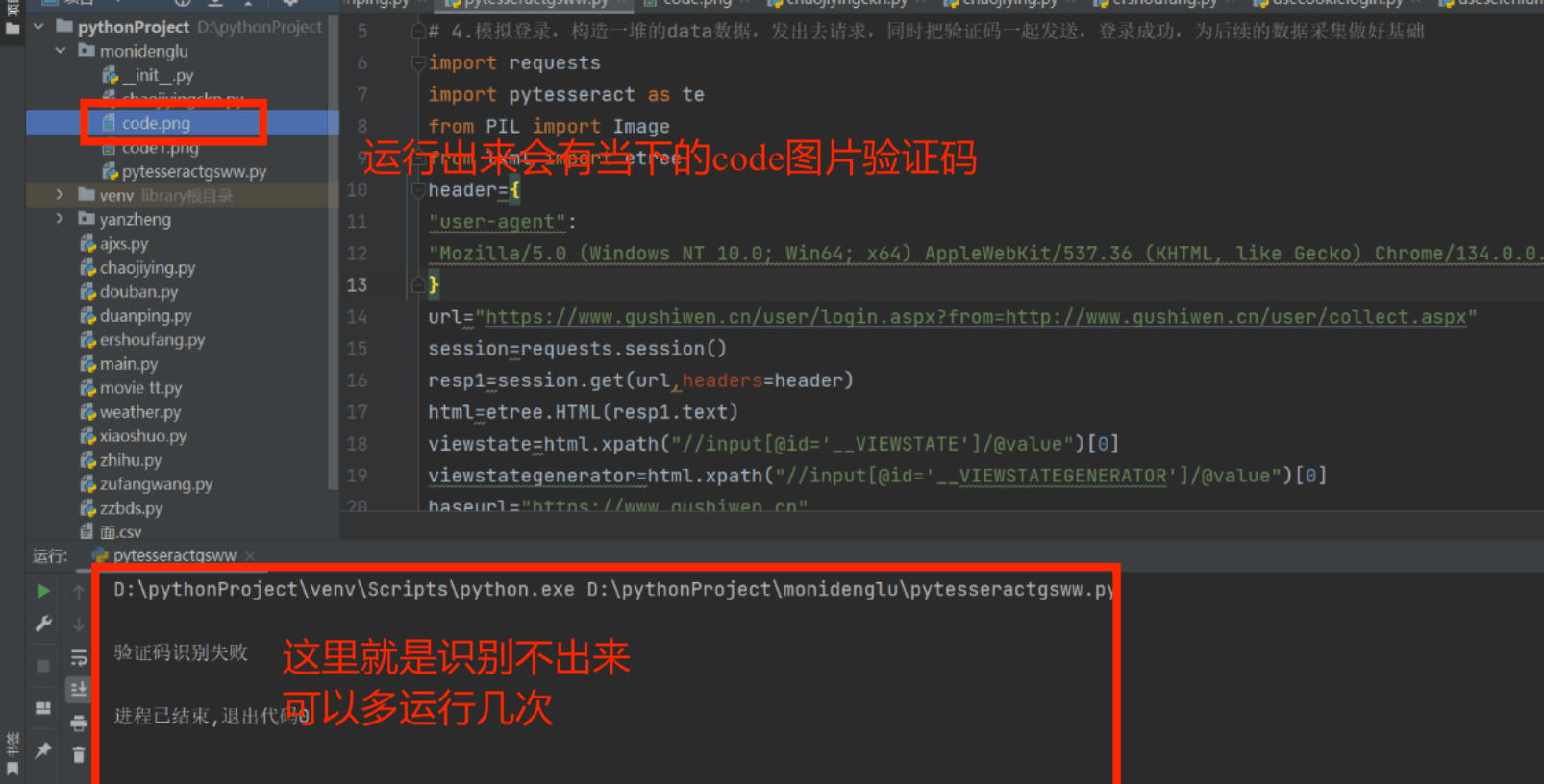
四、运行结果展示
因为这样的话一般是识别不出来验证码的 所以失败的次数很多、
成功案例:
