网站优怎么做百度推广官方投诉电话
理解 "文件"
狭义理解
文件在磁盘里
磁盘是永久性存储介质,因此文件在磁盘上的存储是永久性的
磁盘是外设(即是输出设备也是输入设备)
磁盘上的文件 本质是对文件的所有操作,都是对外设的输入和输出 简称 IO
广义理解
Linux 下一切皆文件(键盘、显示器、网卡、磁盘…… 这些都是抽象化的过程)
文件操作的归类认知
对于 0KB 的空文件是占用磁盘空间的
文件是文件属性(元数据)和文件内容的集合(文件 = 属性(元数据)+ 内容)
所有的文件操作本质是文件内容操作和文件属性操作
系统角度
对文件的操作本质是进程对文件的操作
磁盘的管理者是操作系统
文件的读写本质不是通过 C 语言 / C++ 的库函数来操作的(这些库函数只是为用户提供方便),而是通过文件相关的系统调用接口来实现的
C语言的fopen,fwrite,fread是库函数并不是系统调用,这三个接口都是封装了操作系统底层的系统调用
回顾C文件接口
打开文件
#include <stdio.h>
int main()
{FILE *fp = fopen("myfile", "w");if(!fp){printf("fopen error!\n");}while(1);fclose(fp);return 0;
}
写文件
#include <stdio.h>
#include <string.h>
int main()
{FILE *fp = fopen("myfile", "w");if(!fp){printf("fopen error!\n");}const char *msg = "hello bit!\n";int count = 5;while(count--){fwrite(msg, strlen(msg), 1, fp);}fclose(fp);return 0;
}
读文件
#include <stdio.h>
#include <string.h>
int main()
{FILE *fp = fopen("myfile", "r");if(!fp){printf("fopen error!\n");return 1;}char buf[1024];const char *msg = "hello bit!\n";while(1){//注意返回值和参数,此处有坑,仔细查看man⼿册关于该函数的说明 ssize_t s = fread(buf, 1, strlen(msg), fp);if(s > 0){buf[s] = 0;printf("%s", buf);}if(feof(fp)){break;}}fclose(fp);return 0;
}
管理文件
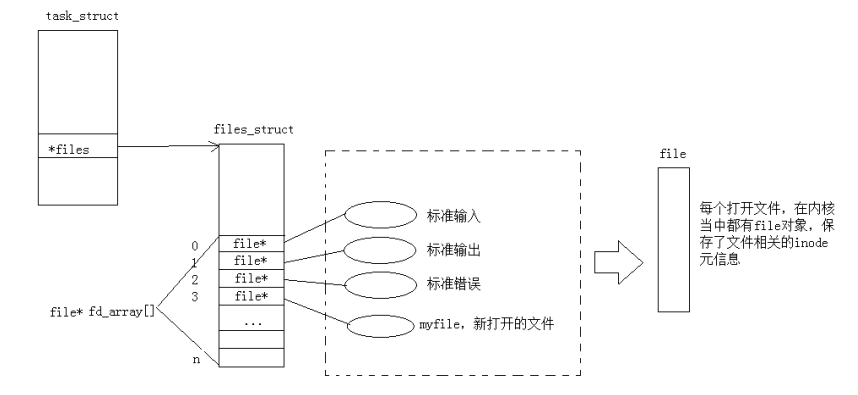
一个进程可以打开多个文件,所以系统中存在大量被打开或正要关闭的文件,所以操作系统需要管理文件,先描述,再组织!!!
操作系统通过一个结构体struct file来管理文件,在文件被打开的时候就会创建一个struct file,其中存放着文件的各种属性,结构体之间互相链接形成链表,所以操作系统对文件的管理就转换成了对链表的管理
task_struct中不止存在页表,还存在着一个文件描述符表struct files_struct,其中存放着一个 struct file数组,数组的每一个的下标都链接着一个文件的地址,系统就通过数组来管理每一个进程打开的文件。
相对应一个文件也可以被多个进程打开,那么关闭文件是否会对进程造成影响,毕竟进程是具有独立性的,而struct file使用和智能指针类似的做法,就是引用计数,只有计数为0的时候才会真正关闭文件
文件的内容会加载到文件缓冲区,文件的属性会加载到struct file
系统文件 I/O
初识标志位
打开文件的方式不仅仅是 fopen,ifstream 等流式,语言层的方案,其实系统才是打开文件最底层的方案。不过,在学习系统文件 IO 之前,先要了解下如何给函数传递标志位,该方法在系统文件 IO 接口中会使用到:
#include <stdio.h>
#define ONE 0001 //0000 0001
#define TWO 0002 //0000 0010
#define THREE 0004 //0000 0100
void func(int flags) {if (flags & ONE) printf("flags has ONE! ");if (flags & TWO) printf("flags has TWO! ");if (flags & THREE) printf("flags has THREE! ");printf("\n");
}
int main() {func(ONE);func(THREE);func(ONE | TWO);func(ONE | THREE | TWO);return 0;
}
通过这个代码能够了解标志位的作用
状态表示:每个标志位都能独立地表示一种状态。在这个例子中,ONE、TWO 和 THREE 分别代表不同的状态。
状态组合:通过按位或运算符 | 可以把多个标志位组合起来,以此表示多种状态的组合。
状态检查:借助按位与运算符 & 能够检查某个标志位是否被设置,从而依据不同的状态执行不同的操作。
系统调用读文件
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{int fd = open("myfile", O_RDONLY);if(fd < 0){perror("open");return 1;}const char *msg = "hello bit!\n";char buf[1024];while(1){ssize_t s = read(fd, buf, strlen(msg));//类⽐write if(s > 0){printf("%s", buf);}else{break;}}close(fd);return 0;
}
系统调用写文件
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{umask(0);int fd = open("myfile", O_WRONLY|O_CREAT, 0644);if(fd < 0){perror("open");return 1;}int count = 5;const char *msg = "hello bit!\n";int len = strlen(msg);while(count--){write(fd, msg, len);//fd: 后⾯讲, msg:缓冲区⾸地址, len: 本次读取,期望写⼊多少个字节的数据。 返回值:实际写了多少字节数据 }close(fd);return 0;
}
接口认识
open
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);第一个参数是文件,第二个参数是标志位 ,第三个参数表示新创建文件的权限,如果新创建的文件不带mode会造成新创建的文件权限位乱码
通过使用标志位用偶有效减少传参的个数
open标志位介绍
O_RDONLY:以只读模式打开文件。文件只能被读取,不能进行写入操作
O_WRONLY:以只写模式打开文件。文件只能被写入,不能进行读取操作
O_RDWR:以读写模式打开文件。文件既可以被读取,也可以被写入
O_CREAT:如果文件不存在,则创建该文件。使用此标志位时,需要提供第三个参数 mode 来指定新文件的权限。
O_EXCL:和 O_CREAT 一起使用时,如果文件已经存在,则 open 调用会失败并返回 -1,同时将 errno 设置为 EEXIST。这可用于确保文件是新创建的。
O_TRUNC:如果文件存在且以可写模式打开,则将文件长度截断为零,即清空文件内容
O_APPEND:以追加模式打开文件。每次写操作都会将数据追加到文件末尾,而不是覆盖原有内容
O_NONBLOCK:以非阻塞模式打开文件。在进行读写操作时,如果没有数据可读或无法立即写入数据,函数不会阻塞,而是立即返回 -1,同时将 errno 设置为 EAGAIN 或 EWOULDBLOCK。这在处理多个文件描述符或需要异步操作时非常有用
而标志位的组合使用|
write
ssize_t write(int fd, const void *buf, size_t count);第一个参数是文件操作符,第二个参数是写入文件的内容,第三个参数是需要写入的字节数
read
ssize_t read(int fd, void *buf, size_t count);第一个参数是文件操作符,第二个参数是存放读到的数据,第三个参数是读入的字节数
文件操作符
write,read的第一个参数都是fd,fd就是文件操作符
操作系统只认fd,那么fd是什么呢?在文件描述符表中存在struct file数组,fd就是数组的下标。
当我们打开多个文件的时候,查看他们的fd,会发现fd是从3开始的。这是由于数组中默认的0,1,2号下标分别是标准输入,标准输出,标准错误。
fd的数据是从小到大的,只要前面有多余的位置,系统就会将文件分配到靠前的下标
open的时候就会找到进程的文件描述符表中的数组,找到一个未被使用过的位置,将struct file的地址填入其中,fd就是数组的下标
read就是用fd找到数组的下标,访问对应文件的地址,从文件缓冲区中将数据拷贝到buffer,文件缓冲区的数据是由磁盘中文件的内容预加载到缓冲区中。
重定向
Linux中存在函数dup2,用于复制文件描述符
int dup2(int oldfd, int newfd);oldfd:需要被复制的源文件描述符。
newfd:复制到的目标文件描述符。如果newfd已经打开,会先将其关闭。
使用dup2会将newfd位置的文件覆盖到oldfd上
可以通过dup2来替换标准输入,标准输出来实现重定向操作。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<unistd.h>
int main()
{int fd = open("test.txt", O_RDWR);dup2(fd,1);close(fd);printf("fd: %d\n", fd);return 0;
}当我们将文件夹中的test.txt替换掉标准输出,此时使用printf, 则不会将内容输出到显示器上,而是将内容输出到test.txt中
操作系统只认识fd,printf就是为了往stdout中输出内容,但是stdout被关闭,此时fd为1的文件是log.txt,printf输出的内容就会输出到log.txt中
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<unistd.h>
int main()
{int fd = open("test.txt", O_RDWR);dup2(fd,0);close(fd);char s[100];scanf("%s",s);printf("%s\n",s);return 0;
}
将test.txt文件替换标准输入文件,此时scanf一般是从键盘上读取数据,此时就只能从test.txt中读取数据,将test.txt的数据填写到s中。
操作系统只认fd,scanf就是从键盘中读取数据,但是标准输入被关闭,此时fd为0的文件是test.txt,此时scanf就会从 test.txt中读取数据
通过上面两端代码可以大致了解重定向的原理,就是将文件进行替换,从而将一下本该输出到显示屏中的数据输出到其他文件中,将从键盘中读取的数据转换成从其他文件中读取数据
正确的重定向操作方法
例如存在一个文件:log.txt,需要将原本输出到显示屏的数据输出到log.txt中
ls -l 1 > log.txt将原本输出到1号文件的内容输出到log.txt中 ,而1号文件就是stdout
#include<cstdio>
#include<iostream>
using namespace std;
int main()
{cout<<"hellocout"<<endl;cerr<<"hellocerr"<<endl;return 0;
}
当我们使用这段代码重定向到一个文件时,cerr的内容并不会重定向到文件,而是输出在显示屏上,这是由于cerr对应的文件时stderr,它的fd为2,而默认的重定向只有1
所以可以通过将1重定向到log.txt,2追加重定向到log.txt
./a 1 > log.txt 2 >> log.txt此时cout和cerr的内容就都输出到log.txt中了
也可以将标准错入重定向到标准输出的目标位置,&1 表示「当前标准输出的目标位置」
./a 1 > log.txt 2>&1效果与第一种一样
理解“一切皆文件”
首先,在 Windows 中是文件的东西,它们在 Linux 中也是文件;其次一些在 Windows 中不是文件的东西,比如进程、磁盘、显示器、键盘这样硬件设备也被抽象成了文件,你可以使用访问文件的方法访问它们获得信息;甚至管道,也是文件;将来我们要学习网络编程中的 socket(套接字)这样的东西,使用的接口跟文件接口也是一致的。
这样做最明显的好处是,开发者仅需要使用一套 API 和开发工具,即可调取 Linux 系统中绝大部分的资源。举个简单的例子,Linux 中几乎所有读(读文件,读系统状态,读 PIPE)的操作都可以用 read 函数来进行;几乎所有更改(更改文件,更改系统参数,写 PIPE)的操作都可以用 write 函数来进行。
在操作系统中,每个外设都有一套属于自己的读写操作。操作系统中的struct file的内容中存在函数指针,他们会指向对应外设的读写操作,而每个函数指针的命名,参数,都一样
一切皆文件,是进程认为一切皆文件,进程中存储着文件描述符表,文件描述符表指向struct file,从硬件角度上来看,struct file的函数指针指向硬件的读写操作,所以管理好文件也就能管理好硬件,进程无需接触到硬件,只需接触到struct file即可
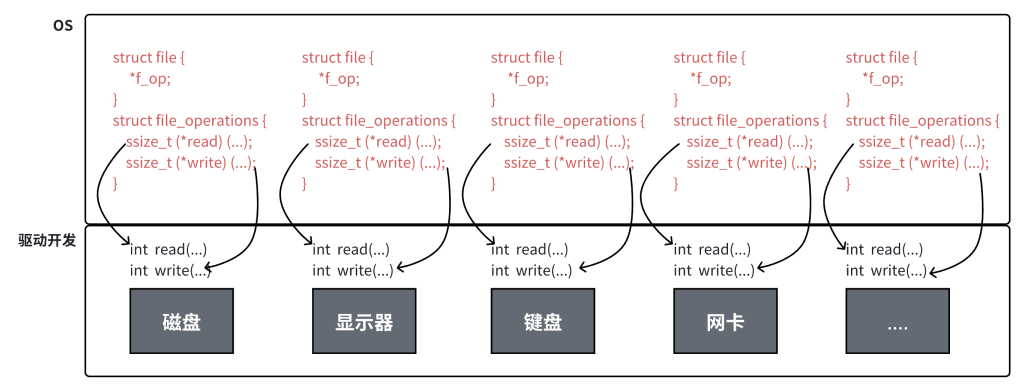
上图中的外设,每个设备都可以有自己的 read、write,但一定是对应着不同的操作方法!!但通过struct file 下 file_operation 中的各种函数回调,让我们开发者只用 file 便可调取 Linux 系统中绝大部分的资源!!这便是 “linux 下一切皆文件” 的核心理解。
缓冲区
什么是缓冲区
缓冲区就如同日常中的快递站,可以帮助我们在空闲时间再去拿快递,而非在快递送到家门口的时候无论在做任何事情都要回去拿快递,这样也严重影响了快递员的效率
缓冲区是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
可以查看Linux中的FILE结构体
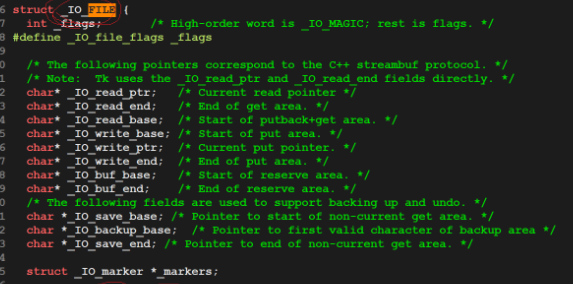
它的指针就指向了缓冲区的位置
为什么要引入缓冲区机制
系统调用也是有成本的,系统调用是需要操作系统进行操作的,而操作系统平时需要进行大量的资源管理,如果没有缓冲区,当我们进行文件写入时,操作系统无论做什么事情都需要停下来进行写入操作
读写文件时,如果不会开辟对文件操作的缓冲区,直接通过系统调用对磁盘进行操作 (读、写等),那么每次对文件进行一次读写操作时,都需要使用读写系统调用处理此操作,即需要执行一次系统调用,执行一次系统调用将涉及到 CPU 状态的切换,即从用户空间切换到内核空间,实现进程上下文的切换,这将损耗一定的 CPU 时间,频繁的磁盘访问对程序的执行效率造成很大的影响。
为了减少使用系统调用的次数,提高效率,我们就可以采用缓冲机制。比如我们从磁盘里取信息,可以在磁盘文件进行操作时,可以一次从文件中读出大量的数据到缓冲区中,以后对这部分的访问就不需要再使用系统调用了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作 快于对磁盘的操作,故应用缓冲区可 大提高计算机的运行速度。
又如,我们使用打印机打印文档,由于打印机的打印速度相对较慢,我们先把文档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的 CPU 可以处理别的事情。可以看出,缓冲区就是一块内存区,它用在输入输出设备和 CPU 之间,用来缓存数据。它使得低速的输入输出设备和高速的 CPU 能够协调工作,避免低速的输入输出设备占用 CPU,解放出 CPU,使其能够高效率工作。
缓冲类型
标准 I/O 提供了 3 种类型的缓冲区。
・全缓冲区:这种缓冲方式要求填满整个缓冲区后才进行 I/O 系统调用操作。对于磁盘文件的操作通常使用全缓冲的方式访问。
・行缓冲区:在行缓冲情况下,当在输入和输出中遇到换行符时,标准 I/O 库函数将会执行系统调用操作。当所操作的流涉及一个终端时(例如标准输入和标准输出),使用行缓冲方式。因为标准 I/O 库每行的缓冲区长度是固定的,所以只要填满了缓冲区,即使还没有遇到换行符,也会执行 I/O 系统调用操作,默认行缓冲区的大小为 1024。
・无缓冲区:无缓冲区是指标准 I/O 库不对字符进行缓存,直接调用系统调用。标准出错流 stderr 通常是不带缓冲区的,这使得出错信息能够尽快地显示出来。
缓冲区的工作
当使用printf/fprintf/fwrite等等的库函数进行文件操作的时候,数据并非直接写入到文件内核缓冲区中,c标准库中存在一个库缓冲区,使用库函数进行操作的时候,数据会先占时写入到库缓冲区中,直到某种条件的触发,会将fopen返回值中的fd找出来,通过fd进行系统调用,将库缓冲区的内容写到文件内核缓冲区中。
刷新缓冲区的条件
1.强制刷新
2.进程退出
3.刷新条件满足->(全缓冲,行缓冲,无缓冲)