做微信广告网站有哪些内容seo搜索优化
前言
本文隶属于专栏《机器学习的一百个概念》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见[《机器学习的一百个概念》
ima 知识库
知识库广场搜索:
| 知识库 | 创建人 |
|---|---|
| 机器学习 | @Shockang |
| 机器学习数学基础 | @Shockang |
| 深度学习 | @Shockang |
正文
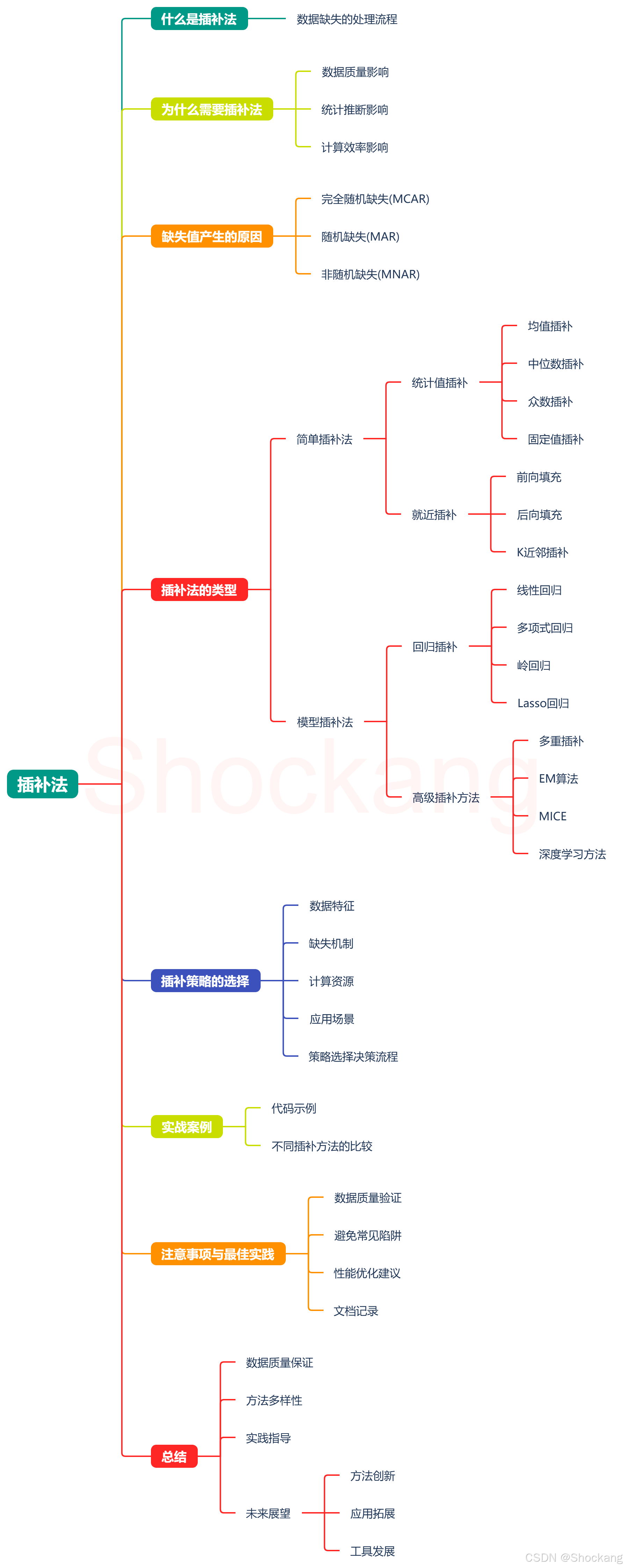
什么是插补法 🤔
插补法(Imputation)是处理缺失数据的一种重要技术方法,其核心思想是通过合理的推断和估计来填补数据集中的缺失值。在机器学习领域,高质量的数据是模型训练的基础,而现实世界中的数据往往存在缺失、异常等问题。插补法作为数据预处理的关键步骤,能够帮助我们维持数据的完整性和可用性。
数据缺失的处理流程
为什么需要插补法 📊
在实际的数据科学项目中,缺失值处理的重要性往往被低估。以下几点说明了为什么我们需要认真对待数据缺失问题:
-
数据质量影响
- 模型训练效果直接依赖于数据质量
- 缺失值可能导致模型偏差
- 影响特征工程的效果
-
统计推断影响
- 样本量减少影响统计显著性
- 可能导致结果偏差
- 降低模型的可解释性
-
计算效率影响
- 某些算法不支持缺失值处理
- 增加数据处理的复杂度
- 影响模型训练速度
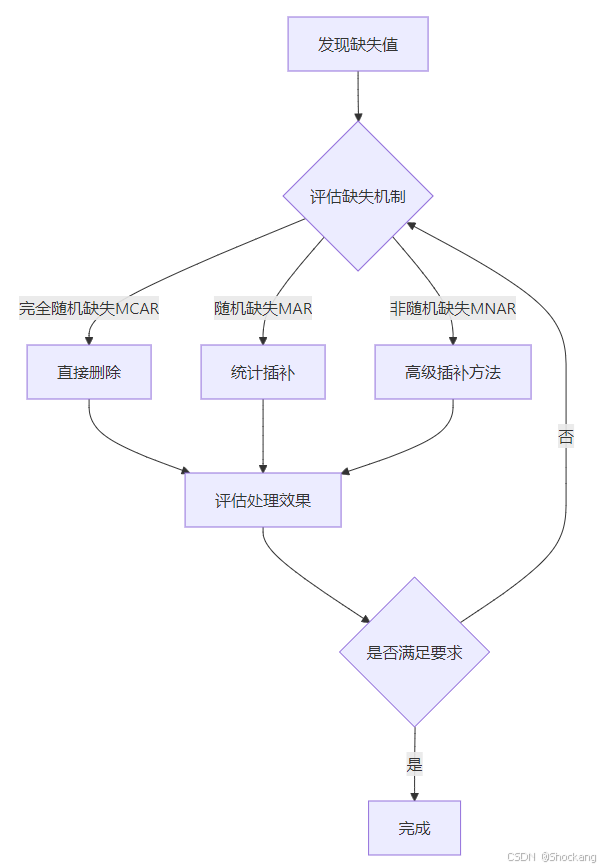
缺失值产生的原因 🔍
理解缺失值产生的原因对选择合适的插补策略至关重要。主要可分为以下三类:
1. 完全随机缺失(MCAR)
- 缺失完全随机发生
- 缺失概率与其他变量无关
- 例如:问卷调查中随机跳过问题
2. 随机缺失(MAR)
- 缺失与其他可观测变量相关
- 条件随机性
- 例如:高收入人群倾向于不填写收入信息
3. 非随机缺失(MNAR)
- 缺失与缺失值本身相关
- 存在系统性偏差
- 例如:成绩差的学生不愿提供成绩信息
插补法的类型 🛠️
1. 简单插补法
统计值插补
- 均值插补
- 中位数插补
- 众数插补
- 固定值插补
就近插补
- 前向填充(Forward Fill)
- 后向填充(Backward Fill)
- K近邻插补(KNN Imputation)
2. 模型插补法

-
回归插补
- 线性回归
- 多项式回归
- 岭回归
- Lasso回归
-
高级插补方法
- 多重插补(Multiple Imputation)
- EM算法(Expectation-Maximization)
- MICE(Multiple Imputation by Chained Equations)
- 深度学习方法
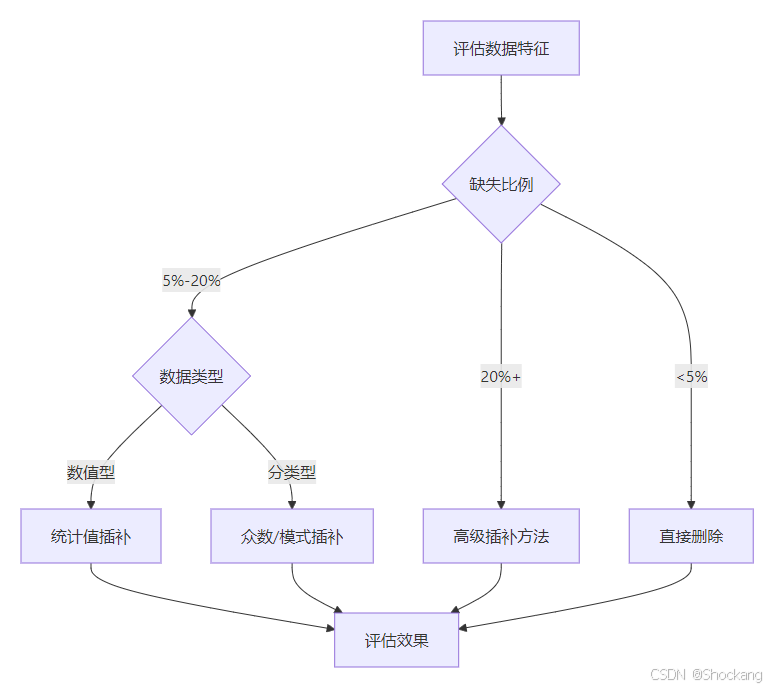
插补策略的选择 📝
选择合适的插补策略需要考虑以下因素:
-
数据特征
- 数据类型(数值/分类)
- 缺失比例
- 数据分布特征
- 变量间相关性
-
缺失机制
- MCAR:可使用简单插补
- MAR:需要考虑条件关系
- MNAR:可能需要收集额外信息
-
计算资源
- 数据量大小
- 时间约束
- 硬件限制
-
应用场景
- 模型要求
- 精度要求
- 实时性要求
策略选择决策流程
实战案例 💻
让我们通过一个具体的例子来说明插补法的应用。假设我们有一个包含用户信息的数据集:
import pandas as pd
import numpy as np
from sklearn.impute import SimpleImputer, KNNImputer
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer# 创建示例数据
data = pd.DataFrame({'age': [25, np.nan, 30, 35, np.nan],'income': [50000, 60000, np.nan, 75000, 80000],'education_years': [16, 14, np.nan, 18, 16]
})# 1. 简单均值插补
imputer = SimpleImputer(strategy='mean')
data_mean = pd.DataFrame(imputer.fit_transform(data), columns=data.columns)# 2. KNN插补
imputer_knn = KNNImputer(n_neighbors=2)
data_knn = pd.DataFrame(imputer_knn.fit_transform(data), columns=data.columns)# 3. 多重插补(MICE)
imputer_mice = IterativeImputer(random_state=0)
data_mice = pd.DataFrame(imputer_mice.fit_transform(data), columns=data.columns)
不同插补方法的比较
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 均值插补 | 简单快速 | 忽略变量关系 | 随机缺失,缺失比例低 |
| KNN插补 | 考虑数据相似性 | 计算开销大 | 数据量适中,强相关性 |
| MICE | 保持变量关系 | 计算复杂 | 多变量关系复杂 |
注意事项与最佳实践 ⚠️
1. 数据质量验证
- 检查缺失值分布
- 验证插补后的数据分布
- 评估插补对下游任务的影响
2. 避免常见陷阱
- 过度依赖简单插补
- 忽视缺失机制
- 未验证插补效果
3. 性能优化建议
- 并行计算处理大规模数据
- 使用增量式插补
- 缓存中间结果
4. 文档记录
- 记录缺失值处理策略
- 保存原始数据副本
- 记录验证结果
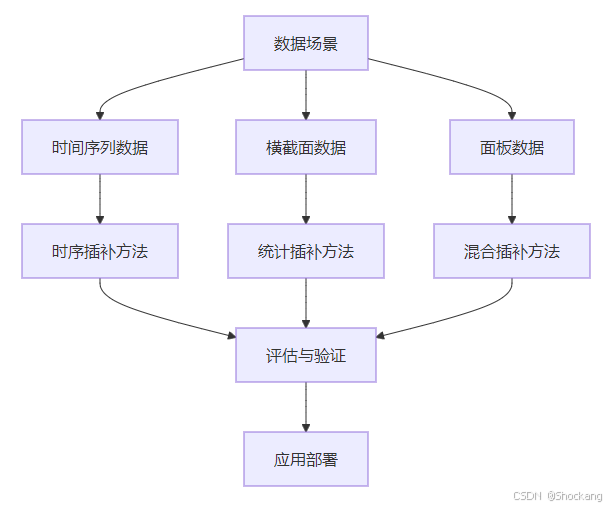
插补法在不同场景下的应用流程
总结 🎯
插补法是机器学习数据预处理中的关键技术,其重要性体现在:
-
数据质量保证
- 维持数据完整性
- 保持数据分布特征
- 提高模型训练效果
-
方法多样性
- 从简单统计到复杂模型
- 适应不同数据特征
- 满足各种应用需求
-
实践指导
- 系统化的选择策略
- 规范的处理流程
- 完善的评估体系
未来展望 🔮
-
方法创新
- 深度学习在插补中的应用
- 自动化插补策略选择
- 实时插补技术发展
-
应用拓展
- 大规模数据处理
- 特定领域定制化方案
- 与其他技术的融合
-
工具发展
- 更智能的插补框架
- 更高效的计算方法
- 更友好的用户界面
通过本文的详细讲解,相信读者已经对插补法有了全面的认识。在实际应用中,需要根据具体情况选择合适的插补策略,并注意验证其效果。随着机器学习技术的发展,插补法也将继续演进,为数据科学实践提供更好的支持。