java怎么做直播网站网站推广软件有哪些
上文主要是对于 LoRA 的原理和一些常见问题进行了讲解,该篇主要是讲解一些常见的 LoRA 变体。本笔记供个人学习总结使用。
QLoRA
QLoRA 是在 LoRA 的基础上进行的改进,旨在进一步减少微调大语言模型时的内存占用,同时保持或仅轻微牺牲性能。主要改进点如下:
- 4-bit NormalFloat(NF4):QLoRA 引入了一种新的数据类型,即 4-bit NormalFloat,这是一种理论上最优的数据类型,适用于正态分布的权重。这种数据类型通过确保每个量化箱有相同数量的值来避免量化误差,对于异常值的处理有好处。
- 双重量化(Double Quantization):QLoRA 采用了双重量化技术,即对量化常数进行量化,以进一步减少内存占用。这种方法通过量化第一层量化的常数作为输入,进行二次量化,从而减少了量化常数本身的内存占用。
- 分页优化器(Paged Optimizers):QLoRA 使用 NVDIA 的统一内存特性,通过自动在 CPU 和 GPU 之间进行页面到页面的传输,来管理梯度更新时可能出现的内存峰值。这种方法允许在 GPU 内存不足时,将优化器状态自动转移到 CPU RAM ,然后在需要时再将其转回 GPU 内存。
- 内存使用效率:QLoRA 通过上述技术显著降低了微调 65 B 参数模型所需的平均内存需求,从需要超过 780 GB 的 GPU 内存降低到小于 48 GB,而不会降低运行时间或预测性能。
- 性能保持:QLoRA 在减少内存需求的同时,能够保持与 fp16 微调基线相当的性能。这使得最大的公开可用模型能够在单个 GPU 上进行微调,大大提高了 LLM 微调的可访问性。
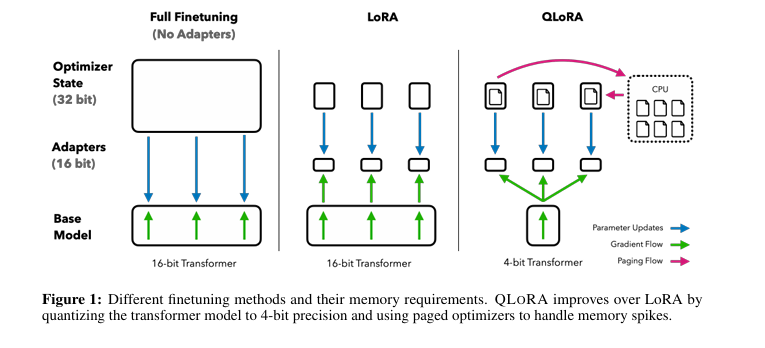
总的来说,QLoRA 通过结合量化技术和 LoRA 的低秩适配器权重,实现了在保持性能的同时显著降低内存占用,使得在资源有限的硬件上微调大型模型成为可能。
LoRA-FA
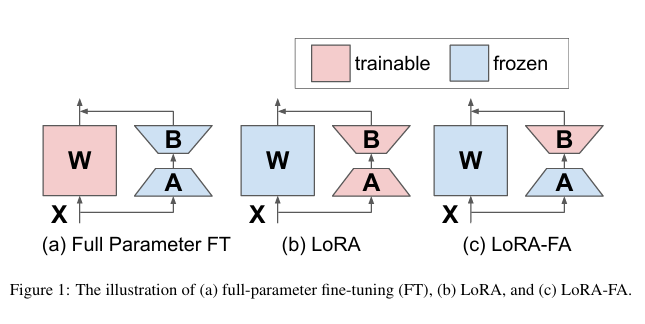
LoRA-FA 的原理是在 LoRA 的基础上,冻结矩阵 A ,矩阵 B 不是添加新的向量,而是在用零初始化之后进行训练,减少了一半的训练参数。
AdaLoRA
AdaLoRA 是对 LoRA 的一种改进,它根据重要性评分动态分配参数预算给权重矩阵,将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将不重要的矩阵的秩降低,以防止过拟合并节省计算预算。
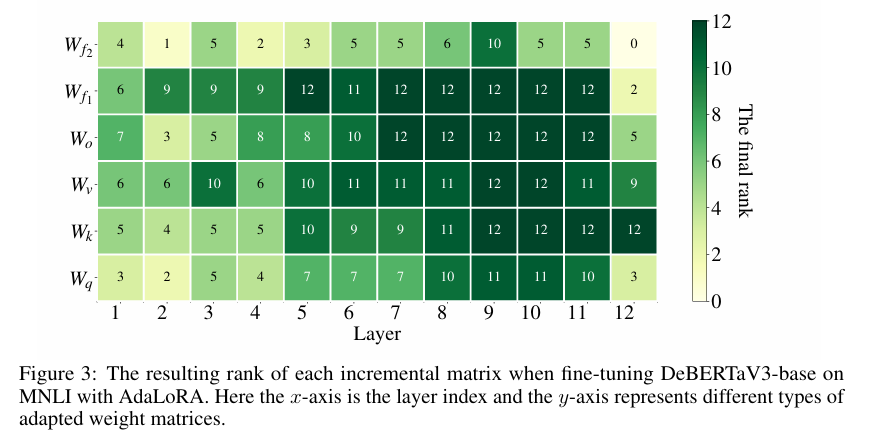
LoRA 每个 Adapter 的秩都是一样的, AdaLoRA 对于不同层、类型参数根据下游任务动态分配秩,基于 SVD 的形式参数化增量更新,这种基于 SVD 的参数化形式可用在规避 SVD 复杂的计算的同时高效裁剪不重要的奇异值,从而降低计算量。
LongLoRA
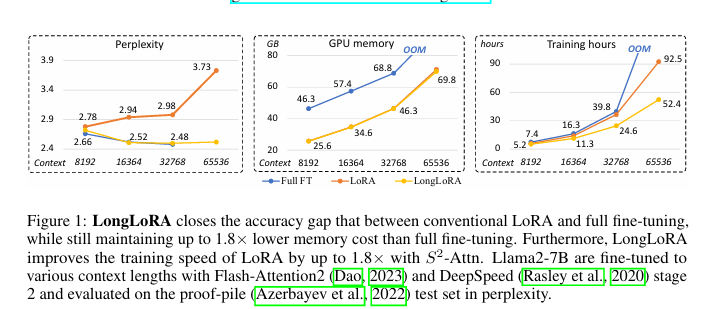
用较长的上下文长度训练 LLM 的计算成本很高,需要大量的训练时间和 GPU 资源。(例如,对上下文长度为 8192 的自注意力层进行训练需要的计算成本是 2048 的 16 倍),LoRA 训练长语境模型既不够有效,也不够高效。
就有效性而言,普通的低秩适应在长语境扩展中会导致较高的复杂度。将等级提高到最高的值,例如 rank = 256 ,并不能缓解这一问题。

在效率方面,无论是否采用 LoRA ,计算成本都会随着上下文规模扩大而急剧增加,这主要是由于标准的 self-attention 机制造成的。如图,即使采用 LoRA ,当上下文窗口扩大时,标准 LLaMA2 模型的训练时间也会大幅增加。
LongLoRA 从以下方面加快了 LLM 的上下文扩展:
shift short attention :虽然在推理过程中需要密集的全局注意力,但通过 sparse local attention 可用有效地对模型进行微调。 LongLoRA 使用 shift short attention 可用有效地实现上下文扩展,从而节省大量的计算量。其性能与使用 vanilla attention 进行微调的效果类似,特别是在训练中只需要少量代码即可实现,而在推理中则是可选的。
以上各别方法的详细讲解(扫盲专区):
Sparse Local Attention 是一种在深度学习模型中用于处理长序列数据的注意力机制。它通过限制每个位置只能关注其局部邻域内的其他位置,从而减少计算复杂度,同时保持对局部信息的敏感性。Sparse Local Attention 的核心思想是只让每个位置关注其附近的几个位置,而不是整个序列。这种方法在处理长序列时特别有效,因为它显著减少了计算量,同时仍然能够捕捉到局部的重要信息。
Vanilla Attention 是一种基础的注意力机制,通常用于序列到序列(Seq2Seq)模型中,如机器翻译、文本生成等任务。它的核心思想是通过计算输入序列中每个元素与当前输出元素的相关性,动态地为每个输出分配不同的权重,从而捕捉输入序列中的重要信息。
Shift Short Attention 是一种在深度学习模型中用于处理序列数据的注意力机制。它通过引入“shift”操作来捕捉局部依赖关系,同时减少计算复杂度。这种机制特别适用于处理长序列数据,因为它能够在保持高效计算的同时,捕捉到序列中的局部模式。具体来说,它通过将输入序列向左或向右移动一定步长,生成新的序列,然后在这些新序列上应用注意力机制。这种方法能够有效地捕捉到序列中的局部依赖关系,同时减少计算复杂度。
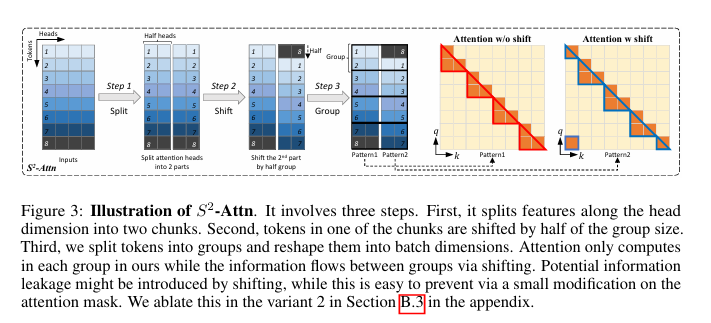
- 首先,它将特征沿头部维度分成两块
- 其次,将其中一个块中的标记移动到组大小的一半
- 然后,我们将标记分成若干组,并将其重塑为批次维度
在 LongLoRA 方法中,注意力只在每个组中进行计算,而标准自我注意力则在所有标记之间进行计算。组与组之间的信息流动通过移位实现的。