盘锦门户网站制作北京网站设计公司
(1)训练部件分割(partseg)模型和检测自己点云并将结果保存txt,请看博主上两篇文章
(2)本文背景是将pipe点云上的缺陷和本体检测出来,即1种语义场景(pipe),2种类别(body和quexian)。请记住这两个数字。
一、标注数据集:
step1:数据集预处理
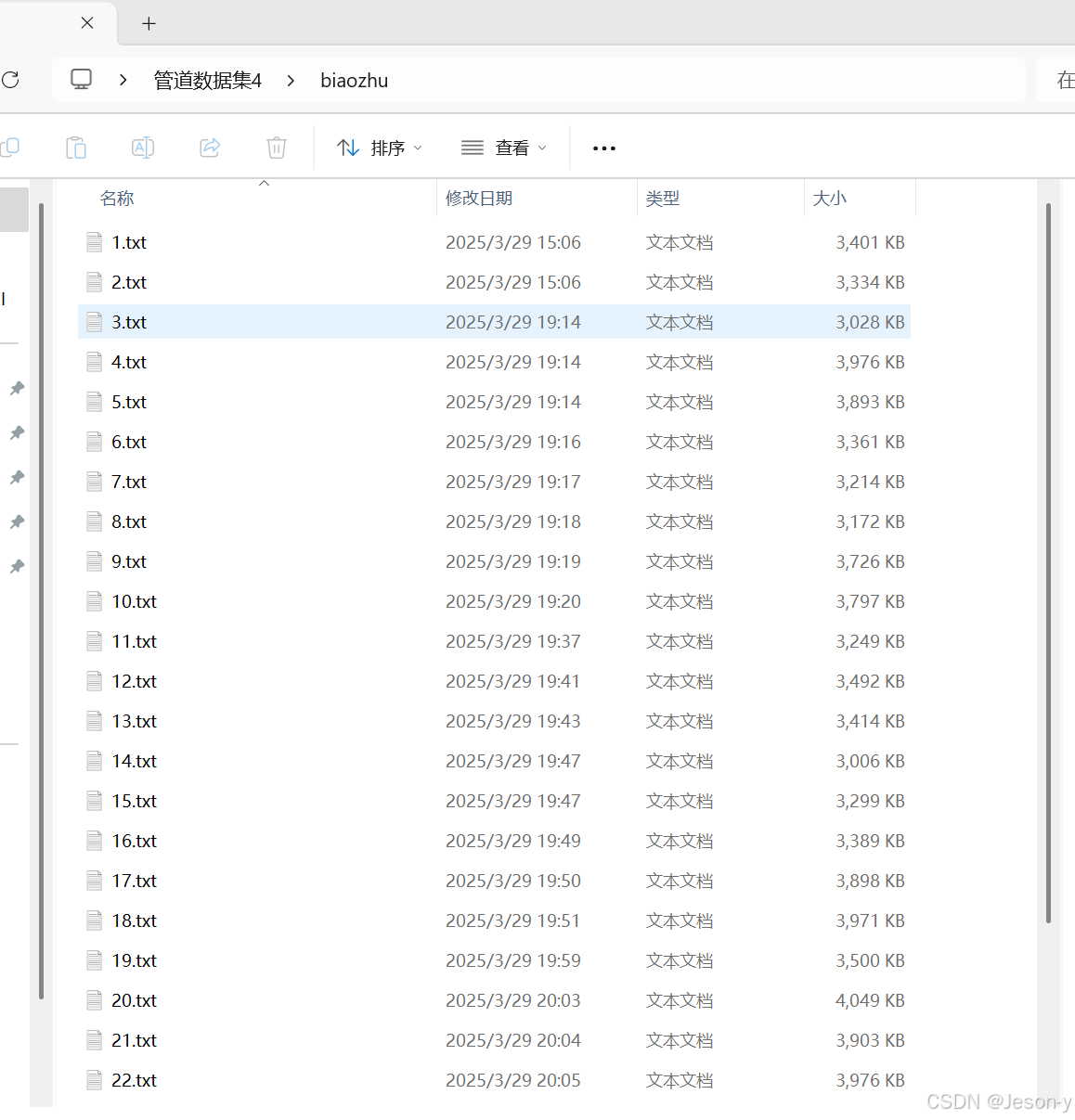
参考:Windows11和Ubuntu用PointNet++训练自己的数据集(部件分割模型)的第一部分即“一、标注数据集”部分即可。得到分类好的n行4列的txt文件。如果是部件分割(partseg)就结束了,但这里是语义分割(semseg)标注很麻烦,还没完成!我这里操作完后得到了m个txt文件,即原本有m个pipe的点云txt文本。
step1结果:

step2:学习语义分割数据集的格式
参考:S3DIS场景点云数据集,仔细阅读
这里用Stanford3dDataset_v1.2_Aligned_Version模式。格式是x y z r g b格式 即n行6列。
step3:制作语义分割txt格式数据集(可以问deepseek,见step3末尾)
思路:用matlab依次遍历step1中每个txt点云文件,在进行操作:将标签为0的点,去掉0并将后三位替换为某个rgb值,再将标签为1的点后三位替换为另外某个rgb值。(因为我只有两个类别,所以我就只有0和1。)。
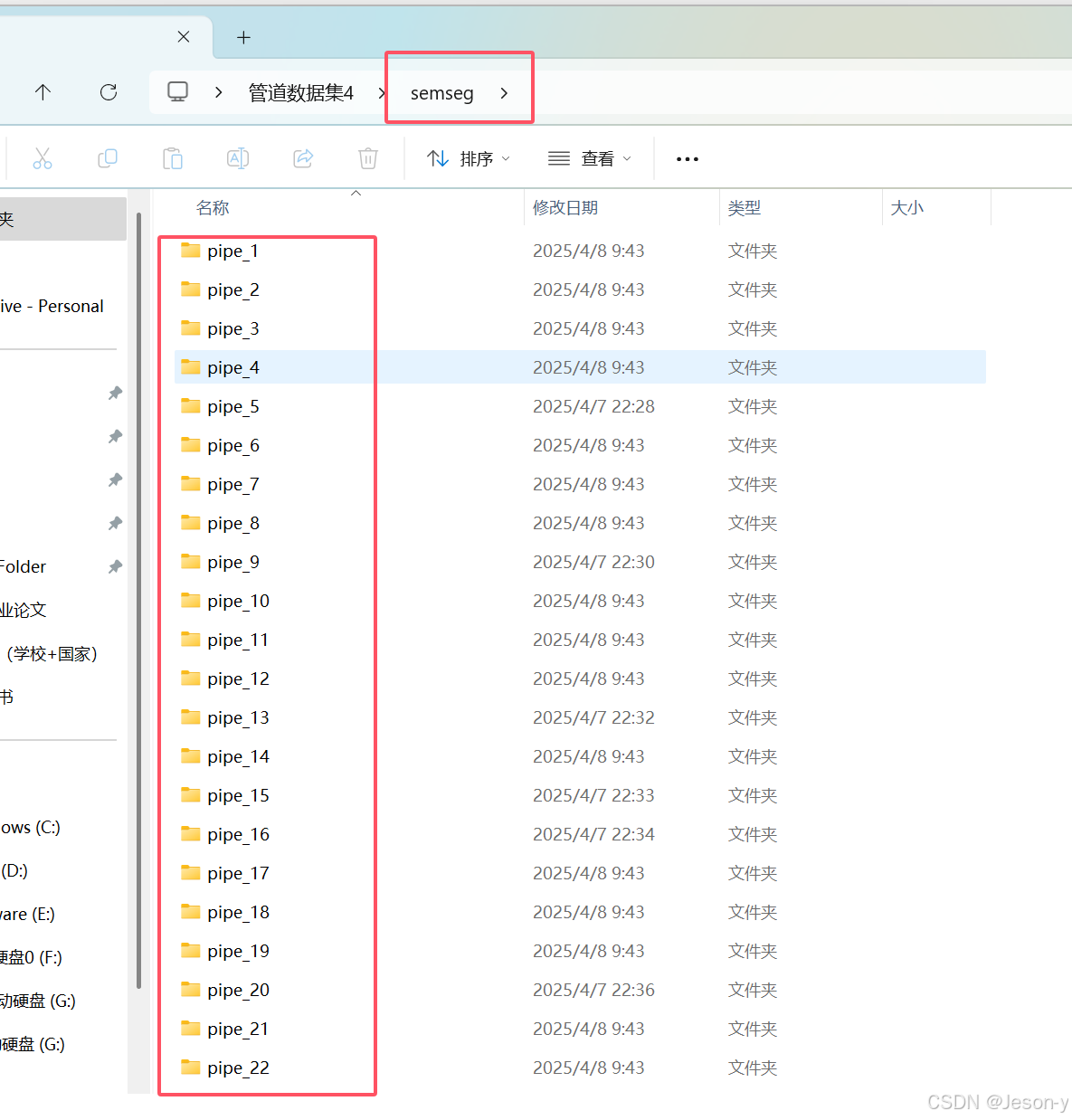
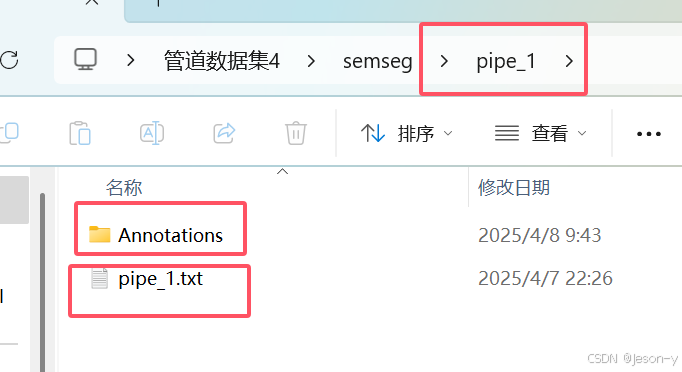
注意:最后要符合语义分割数据集的格式,即每个场景(即step1得到的每个txt文件)单独一个文件夹名字叫做pipe_i(i从1到
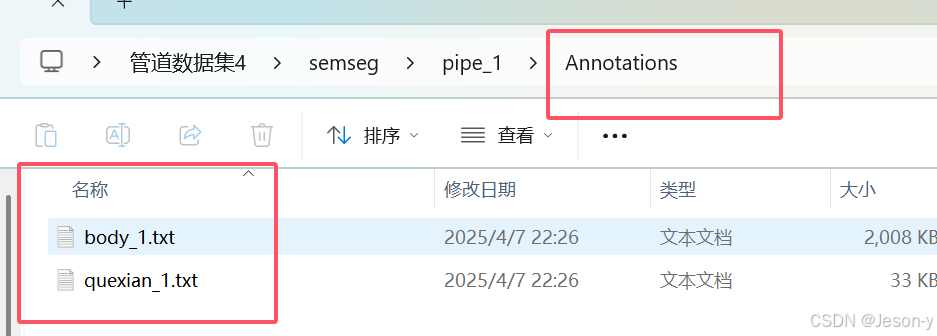
m),文件夹下存着step1结果中第m个点云(n行6列)pipe_i.txt还有一个Annotations文件夹。Annotations文件夹下有2个txt文件(本文的2种类别),分别是body_i.txt和quexian_i.txt,即两种类别的n行6列的文本文件。逻辑是:body_i.txt + quexian_i.txt=pipe_i.txt
step3结果:
deepseek实现step3
我的某个文件夹里有42个txt文件,名字分别是1.txt~42.txt.每个txt文件有n行4列,中间用空格隔开,即每个文件有n个空间点 前三列是xyz后一列是标签,这42个文件里的每个点只有两个标签即0和1可能是浮点型。你也知道上面这种格式是做pointnet++部件分割的,现在我要改成语义分割,需要把标签变成rgb。所以现在要你遍历每个txt文件(可以用for数字遍历,因为名字有规律),把每个文件里的0标签的点换为rgb为[0 0 1],1标签是换为[1 0 0]即n行6列xyzrgb 每列用空格隔开。但是要求每个txt要单独建立一个文件夹叫做pipe_i,i是和i.txt的i相对应。pipe_i文件夹下有个pipe_i.txt放着i.txt的变换好的文件,pipe_i文件夹下的Annotations文件夹下有单独的按照标签的txt,之前为0标签的点标签变换rgb后就放到命名为body_i.txt,之前为1标签的点标签变换rgb后就放到命名为quexian_i.txt。即完全符合语义分割的数据格式。matlab实现
Matlab代码如下:运行时间会很长!!其中的rgb的值都是0~1可以自己改。

%%
%设置pointnet++语义分割数据集
% 设置输入路径和输出路径
input_path = 'D:\YinParker\Desktop\管道数据集4\biaozhu'; % 输入文件路径
output_root = 'D:\YinParker\Desktop\管道数据集4\semseg'; % 输出根目录% 创建输出根目录(如果不存在)
if ~exist(output_root, 'dir')mkdir(output_root);
end% 遍历1.txt到42.txt
for i = 1:42% 输入文件名input_filename = fullfile(input_path, sprintf('%d.txt', i));% 检查文件是否存在if ~exist(input_filename, 'file')fprintf('文件不存在: %s\n', input_filename);continue;end% 读取数据data = load(input_filename);xyz = data(:, 1:3);labels = data(:, 4);% 创建对应的输出目录结构pipe_dir = fullfile(output_root, sprintf('pipe_%d', i));annotations_dir = fullfile(pipe_dir, 'Annotations');if ~exist(pipe_dir, 'dir')mkdir(pipe_dir);endif ~exist(annotations_dir, 'dir')mkdir(annotations_dir);end% 准备转换后的数据(xyzrgb)rgb_data = zeros(size(data, 1), 6);rgb_data(:, 1:3) = xyz;% 分离不同标签的点(带RGB)body_points = [];quexian_points = [];for j = 1:size(data, 1)if abs(labels(j)) < 0.5 % 处理浮点型标签% 标签0 -> 蓝色 [0 0 1]rgb_data(j, 4:6) = [0 0 1];body_points = [body_points; xyz(j, :), 0, 0, 1]; % 添加RGBelse% 标签1 -> 红色 [1 0 0]rgb_data(j, 4:6) = [1 0 0];quexian_points = [quexian_points; xyz(j, :), 1, 0, 0]; % 添加RGBendend% 保存转换后的主文件(pipe_i.txt)output_main_file = fullfile(pipe_dir, sprintf('pipe_%d.txt', i));dlmwrite(output_main_file, rgb_data, 'delimiter', ' ');% 保存带RGB的标签文件(Annotations/body_i.txt和quexian_i.txt)if ~isempty(body_points)body_file = fullfile(annotations_dir, sprintf('body_%d.txt', i));dlmwrite(body_file, body_points, 'delimiter', ' ');endif ~isempty(quexian_points)quexian_file = fullfile(annotations_dir, sprintf('quexian_%d.txt', i));dlmwrite(quexian_file, quexian_points, 'delimiter', ' ');endfprintf('已处理文件: %s\n', input_filename);
endfprintf('所有文件处理完成!结果保存在: %s\n', output_root);
step4:txt格式数据集变为npy
语义分割需要.npy格式的数据集,这也是麻烦的地方。
在PointNet++工程文件夹下的data文件夹建立s3dis文件夹,再在s3dis里面建立Stanford3dDataset_v1.2_Aligned_Version文件夹,里面有Area_1和Area_2两个文件夹。后面会在程序参数设置中让Area_2里的数据为测试集。再从step3中的pipe_i文件夹里找点文件复制进去,当做训练集(Area1)和测试集(Area2)。结构图如下:
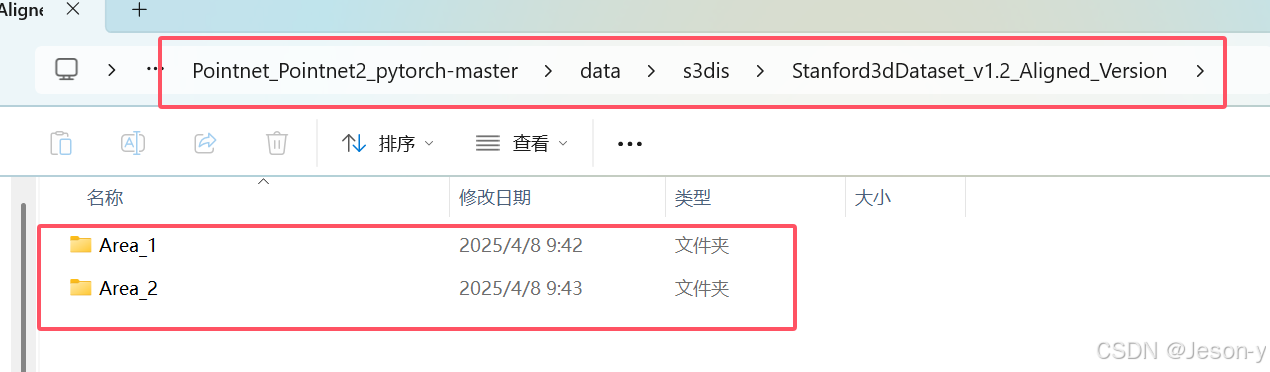
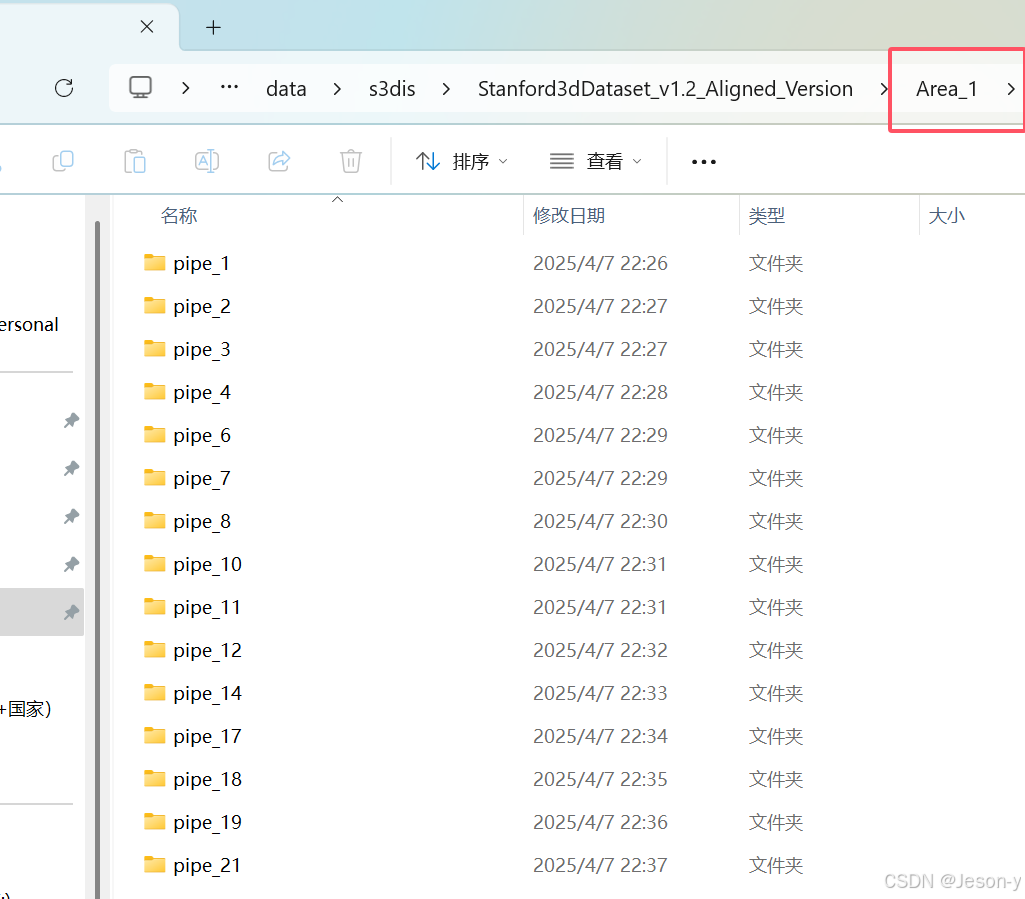
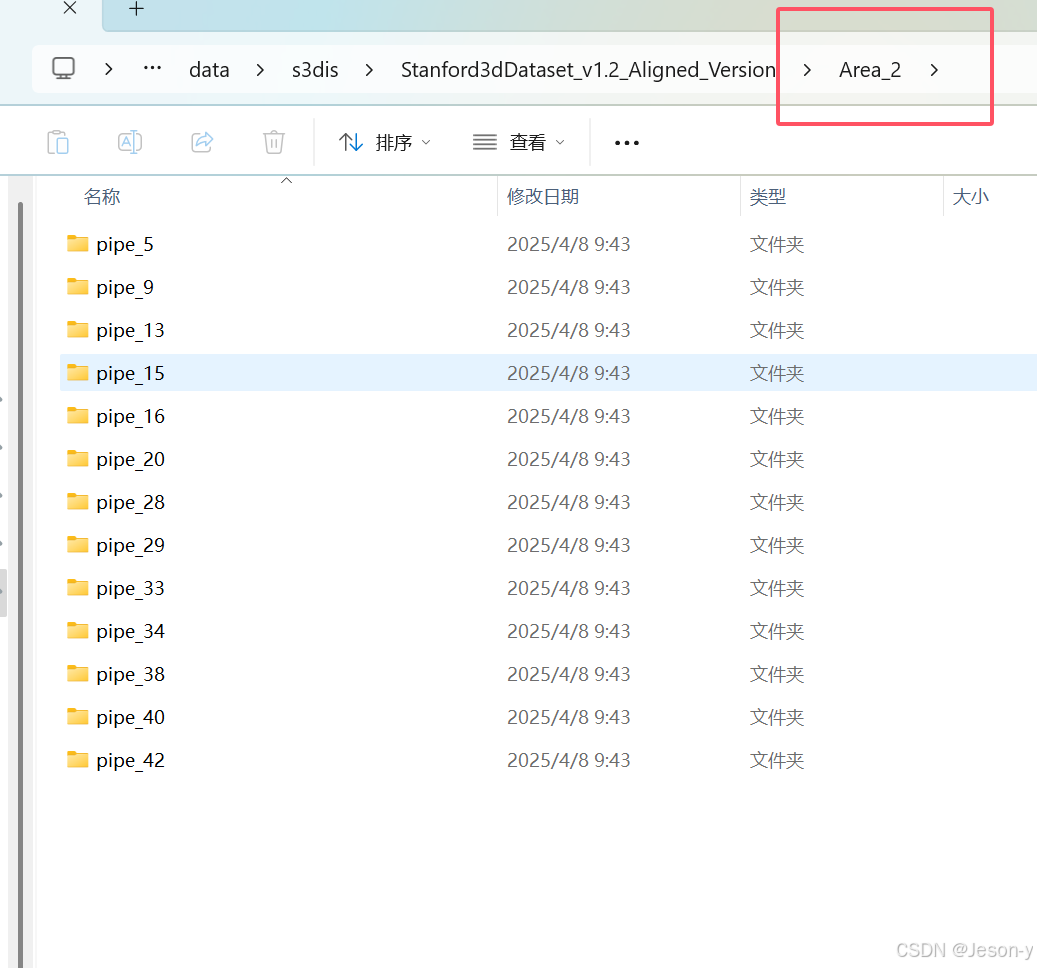
再在data文件夹下建立stanford_indoor3d用于存储npy格式的文件。
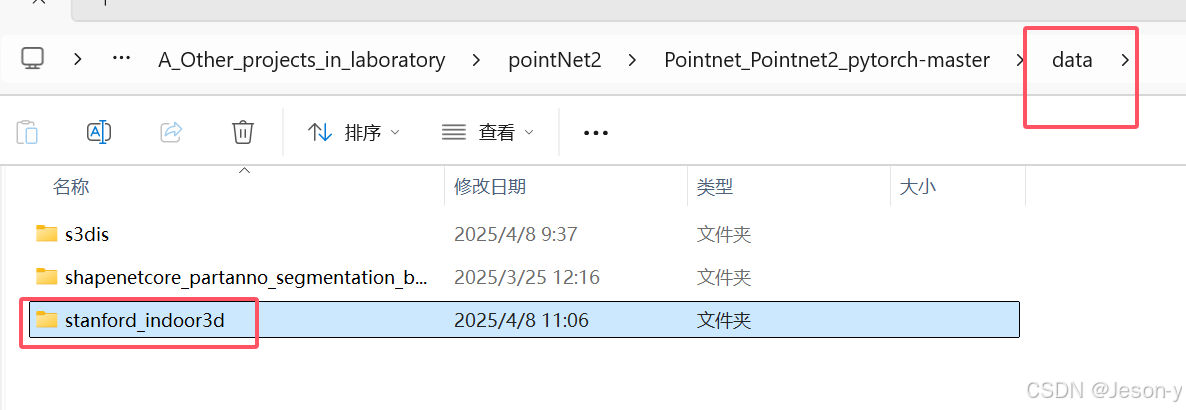
再修改anno_paths.txt和class_names.txt ,anno_paths.txt写所有Area的Annotations的路径,class_names.txt写类别,和之前的step3中得到的Annotions里的相对应。
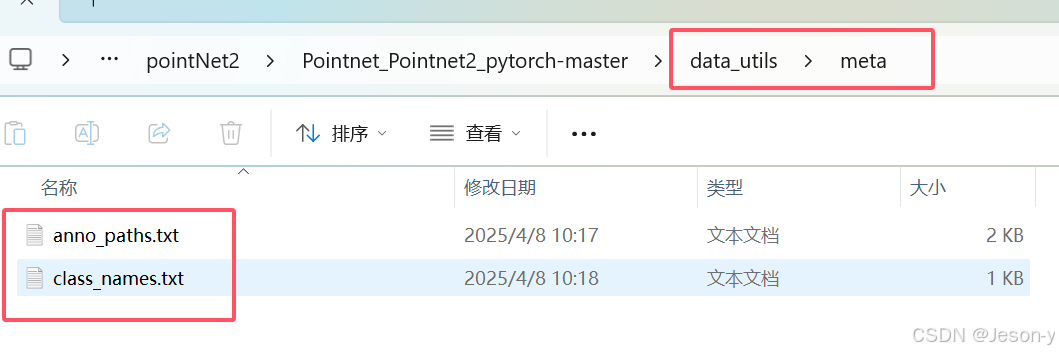
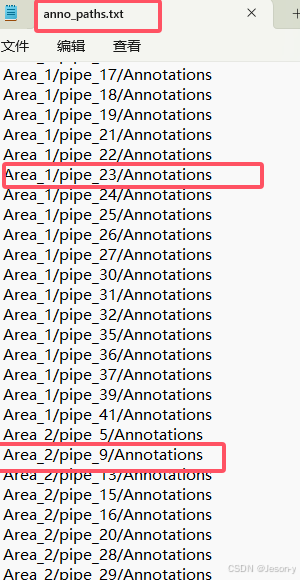
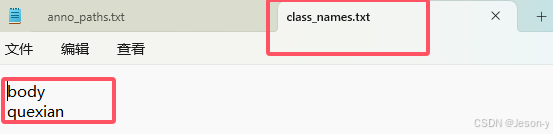
用collect_indoor3d_data.py和indoor3d_util.py将txt样本变为npy样本 。参考:【PointNet++】基于自建数据训练PointNet++场景语义分割网络
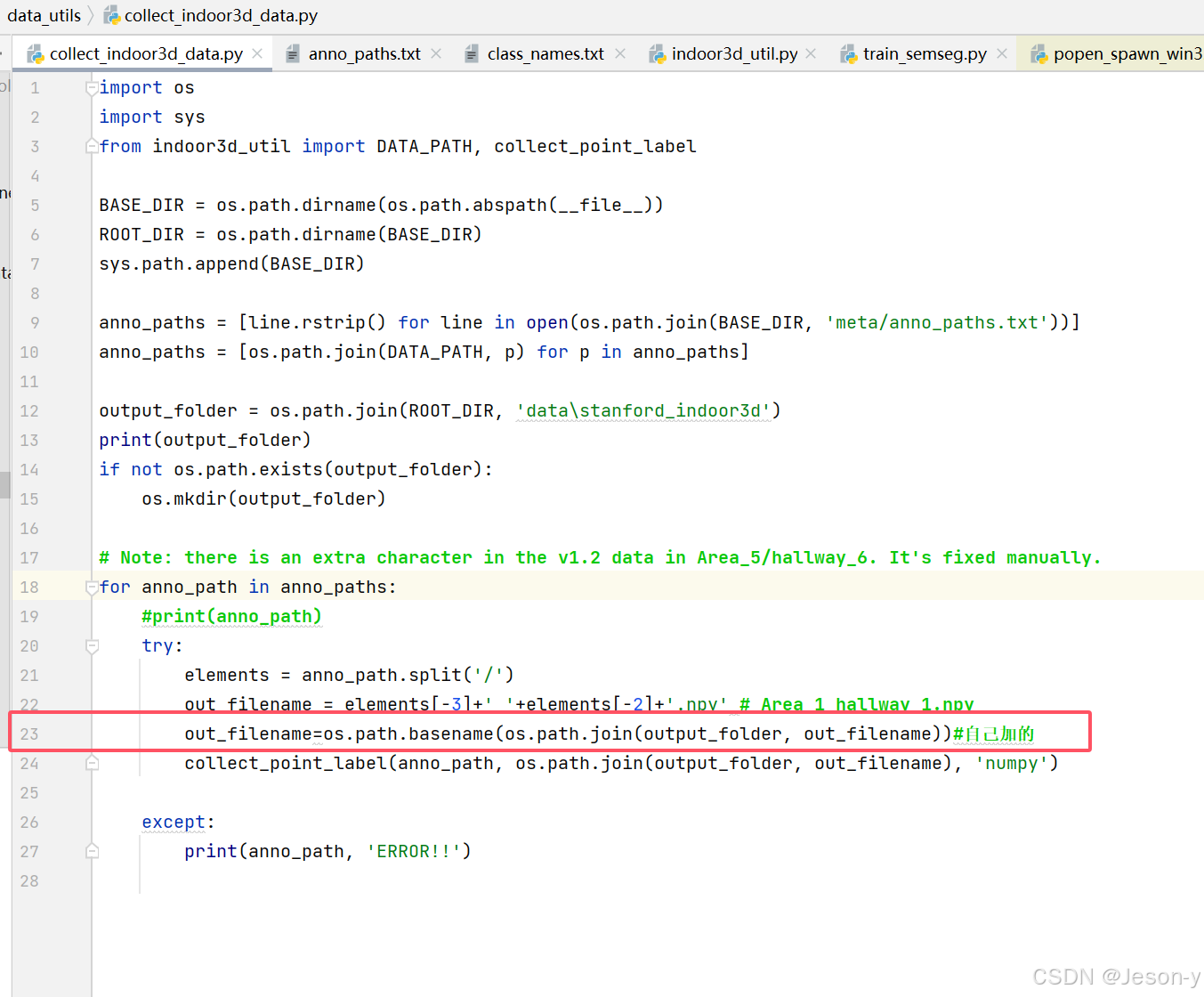
(1)collect_indoor3d_data.py修改:1/1 加一行代码:out_filename=os.path.basename(os.path.join(output_folder, out_filename)),不然生成的npy文件路径不对,还得自己复制到data/stanford_indoor3d文件夹下
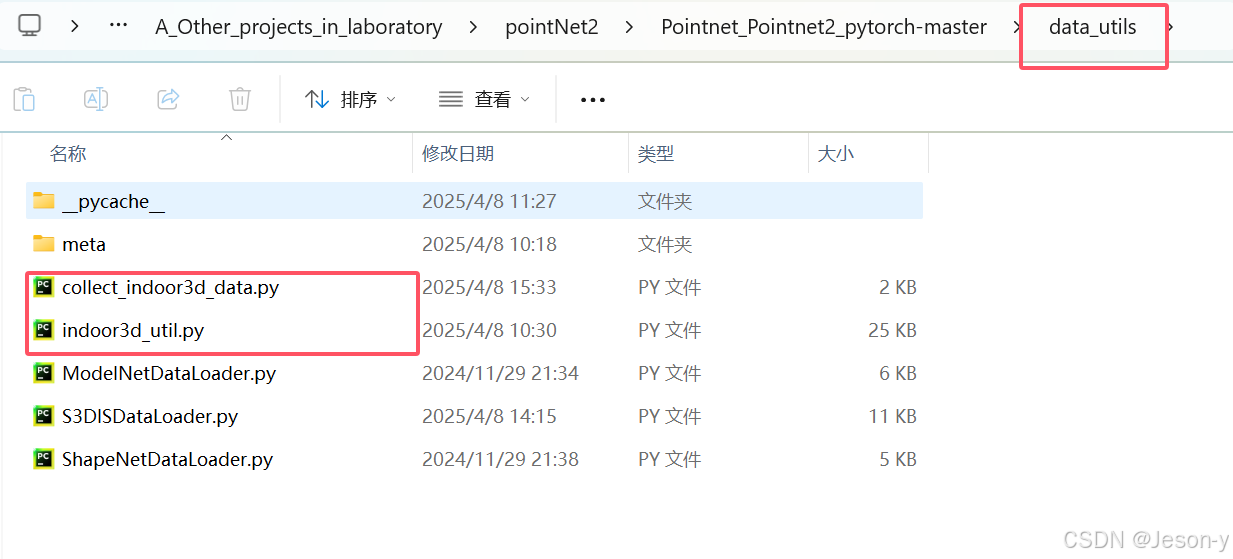
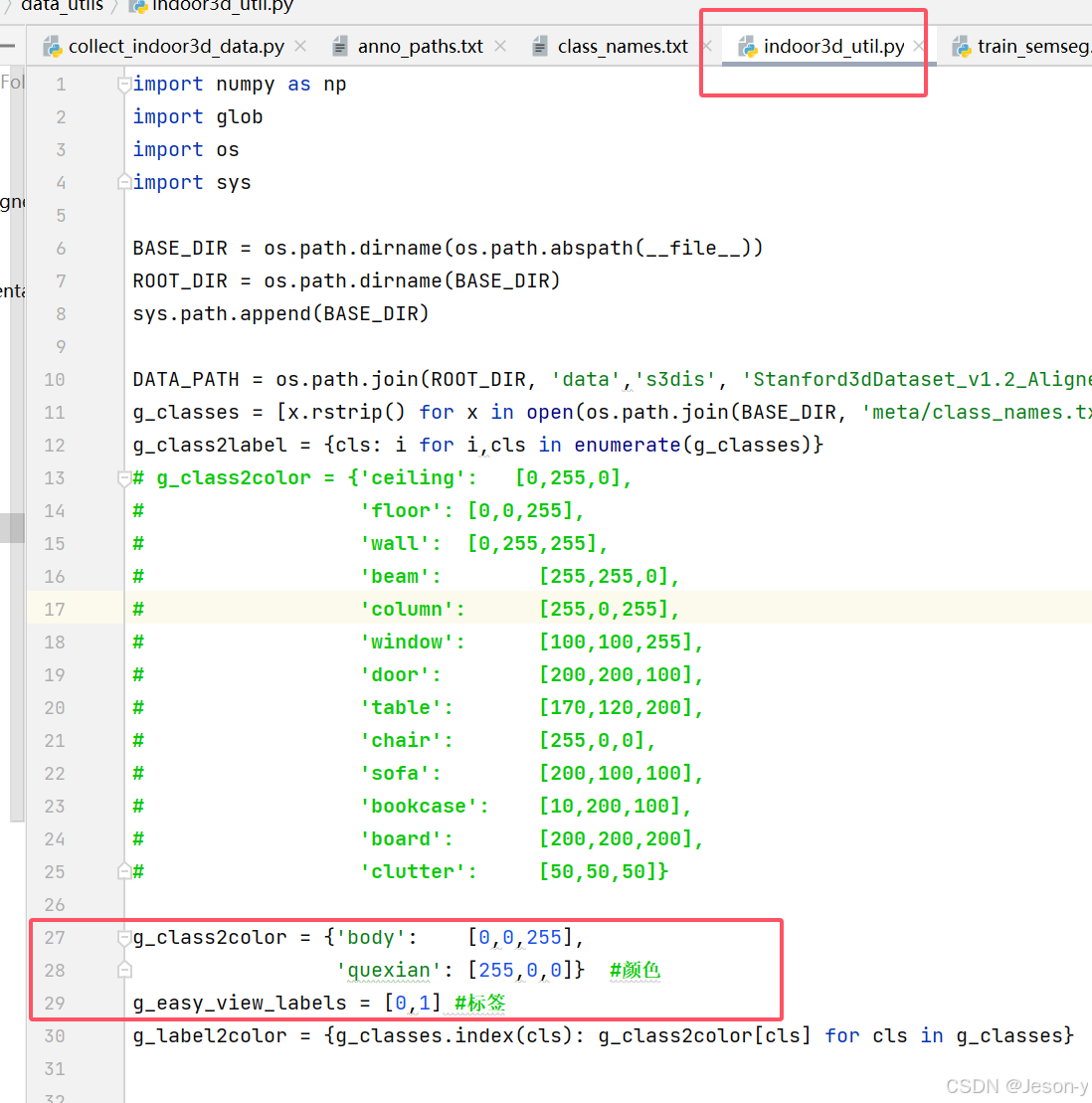
(2)indoor3d_util.py修改: 改方框的两处地方:
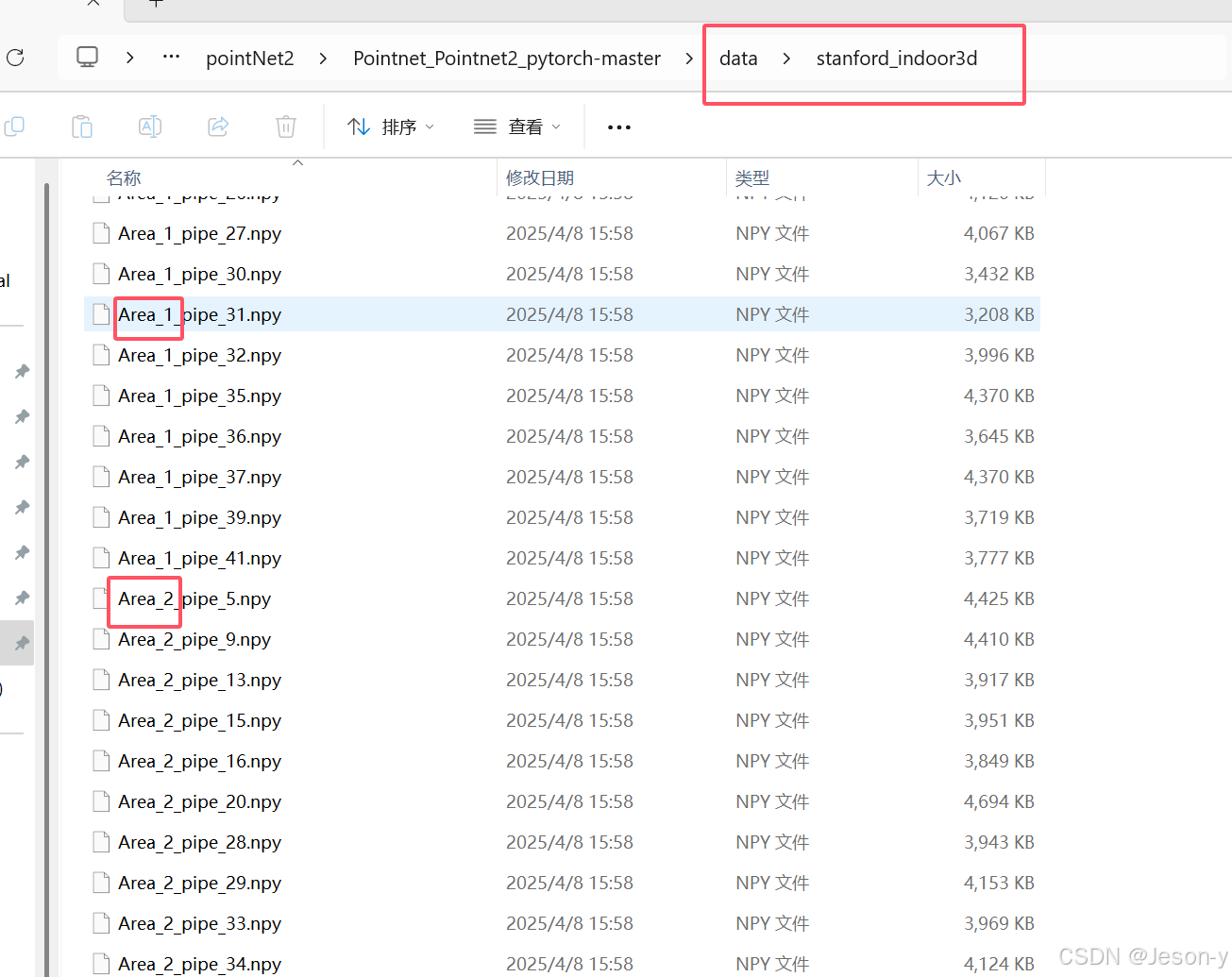
运行
collect_indoor3d_data.py在 data/stanford_indoor3d文件夹下生成npy文件,且前面有Area_1和2的前缀。
二、修改训练和测试代码以及S3DISDataLoader.py
参考:
【PointNet++】基于自建数据训练PointNet++场景语义分割网络
【PointNet++】PointNet++复现(PyTorch版本)
1、训练代码修改:train_semseg.py
(1)类别:

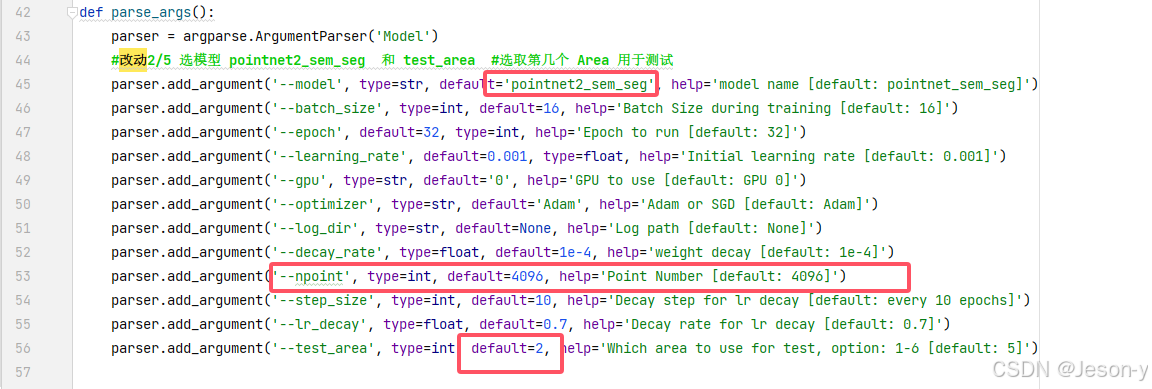
(2)改参数:其中最后一个参数指定哪个Area是测试集,剩下参数都根据实际调整
(3)类别数:

(4)(5)numpy版本问题

2、测试代码修改:test_semseg.py
测试的参数batch_size、num_point等参数根据自己实际调整
(1)类别:

(2)类别数量:
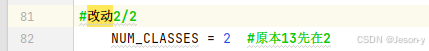
3、S3DISDataLoader.py修改
参考文献中老哥少改了一个
(1)数字:

(2)数字:得+1

(3)数字:

训练以及训练中报错:
运行train_semseg.py即可开启训练。
报错1:
Traceback (most recent call last):File "D:\YinParker\Desktop\AllFileFolder\A_Other_projects_in_laboratory\pointNet2\Pointnet_Pointnet2_pytorch-master\train_semseg.py", line 302, in <module>main(args)File "D:\YinParker\Desktop\AllFileFolder\A_Other_projects_in_laboratory\pointNet2\Pointnet_Pointnet2_pytorch-master\train_semseg.py", line 186, in mainfor i, (points, target) in tqdm(enumerate(trainDataLoader), total=len(trainDataLoader), smoothing=0.9):File "E:\ProfessionSoftware2\anaconda\anaconda3202303\envs\yolov8Python310\lib\site-packages\torch\utils\data\dataloader.py", line 438, in __iter__return self._get_iterator()File "E:\ProfessionSoftware2\anaconda\anaconda3202303\envs\yolov8Python310\lib\site-packages\torch\utils\data\dataloader.py", line 386, in _get_iteratorreturn _MultiProcessingDataLoaderIter(self)File "E:\ProfessionSoftware2\anaconda\anaconda3202303\envs\yolov8Python310\lib\site-packages\torch\utils\data\dataloader.py", line 1039, in __init__w.start()File "E:\ProfessionSoftware2\anaconda\anaconda3202303\envs\yolov8Python310\lib\multiprocessing\process.py", line 121, in startself._popen = self._Popen(self)File "E:\ProfessionSoftware2\anaconda\anaconda3202303\envs\yolov8Python310\lib\multiprocessing\context.py", line 224, in _Popenreturn _default_context.get_context().Process._Popen(process_obj)File "E:\ProfessionSoftware2\anaconda\anaconda3202303\envs\yolov8Python310\lib\multiprocessing\context.py", line 336, in _Popenreturn Popen(process_obj)File "E:\ProfessionSoftware2\anaconda\anaconda3202303\envs\yolov8Python310\lib\multiprocessing\popen_spawn_win32.py", line 93, in __init__reduction.dump(process_obj, to_child)File "E:\ProfessionSoftware2\anaconda\anaconda3202303\envs\yolov8Python310\lib\multiprocessing\reduction.py", line 60, in dumpForkingPickler(file, protocol).dump(obj)
AttributeError: Can't pickle local object 'main.<locals>.<lambda>'
Traceback (most recent call last):File "<string>", line 1, in <module>File "E:\ProfessionSoftware2\anaconda\anaconda3202303\envs\yolov8Python310\lib\multiprocessing\spawn.py", line 116, in spawn_mainexitcode = _main(fd, parent_sentinel)File "E:\ProfessionSoftware2\anaconda\anaconda3202303\envs\yolov8Python310\lib\multiprocessing\spawn.py", line 126, in _mainself = reduction.pickle.load(from_parent)
EOFError: Ran out of input


原因:gpt说是train_semseg.py有两处lambda表达式在window不行
法一:改lanbda表达式(推荐法二)
(1)改:参考行号
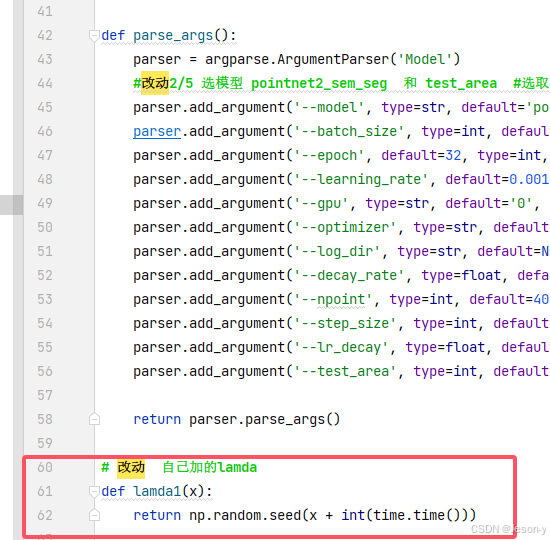

(2)得import functools
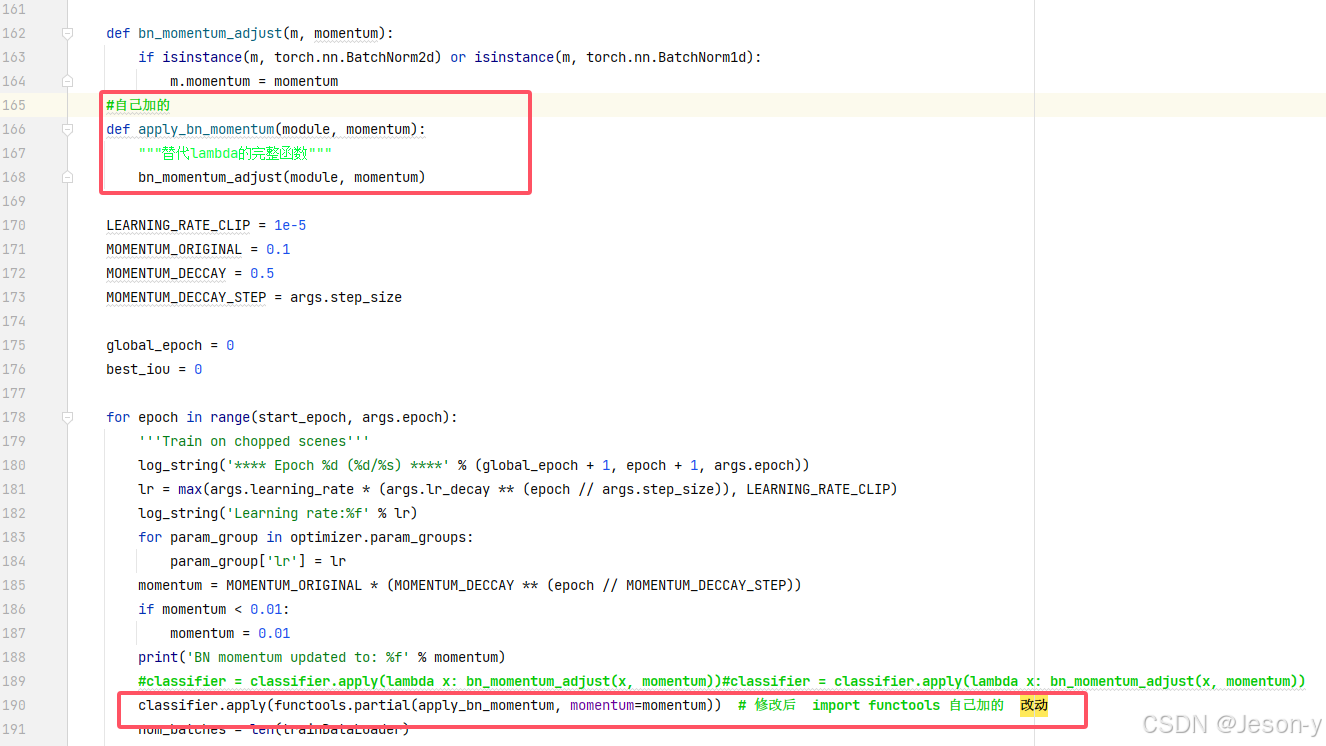
法二:
如何使用PointNet++复现自己的点云语义分割数据集?
如果你是windows系统,那你应该还要注意num_workers设置为0,否则会报错的。 仅需改两处

报错2:
也不是报错,就是训练代码运行后一直卡住,
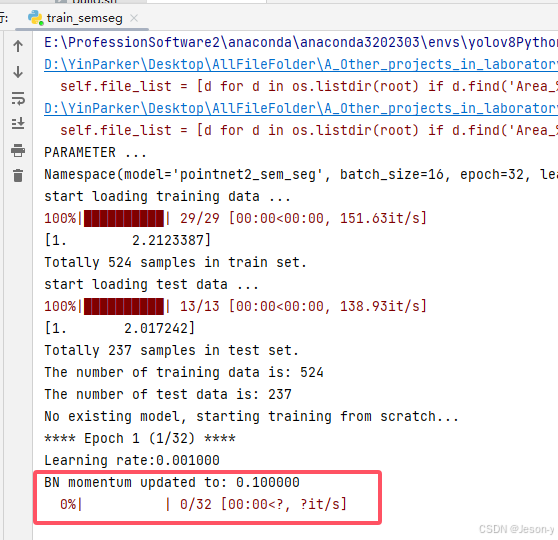
原因:S3DISDataLoader.py里有个一直循环,点数没有达到1024个

因为1*1平方米内自己点太少了,达不到训练时设置的参数--npoint(超参数)
解决方法:train_semseg.py里把参数1调大也行 或者 将上图S3DISDataLoader.py里把1024调小

如果对你有帮助,可以点赞、收藏支持一波