邢台网站制作哪家好站长之家seo概况查询
DQN on MountainCar
引言
在本次实验里,我构建了DQN和Dueling DQN,并在Gymnasium库的MountainCar环境中对它们展开测试。我通过调整训练任务的超参数,同时设计不同的奖励函数及其对应参数,致力于获取更优的训练效果。最后,将训练结果进行可视化处理并加以比较。
DQN实现流程
实现方法
- 实现了DQN类。
- 实现了经验回放缓冲区(Buffer)类。
- 编写了训练流程。
- 将所有超参数集中配置在一处。
- 设计了程序运行参数,具体如下:
--train:训练模式。--test:测试模式。--resume:断点续训模式。--checkpoint:指定用于断点续训或测试模式加载的模型。--task_name:确定任务名称,该名称与保存日志的路径相关。--visualize_train:开启Gym环境的可视化功能。--dueling:使用Dueling DQN网络。--stop_threshold:早停阈值。
遇到的难题
难题一
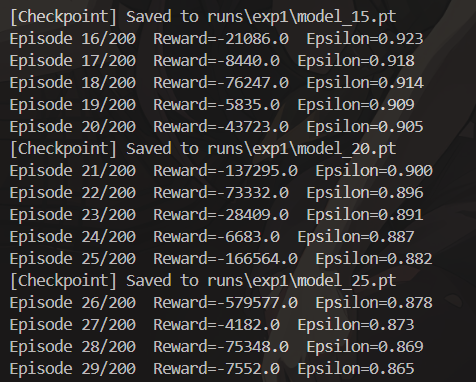
在进行DQN训练时,进程常常在第20多轮(episode)时卡住。起初,我考虑可能是超参数设计的问题,但后来怀疑并非是训练超参数设置不当所致。我了解到Gym环境设定了停止条件,要么是完成任务,要么是达到最大步数。鉴于进程一直卡在第29轮不动,按常理应该早就达到了200步的上限,触发停止条件。然而,我在本地保存的日志文件,其TensorBoard日志文件大小却持续变化,似乎训练仍在进行。由此推测,可能是DQN算法中的经验回放缓冲区部分存在问题,导致缓冲区占用内存过大。
经过更为细致的分析,我发现编写循环终止条件时,仅设置了到达终点这一条件,而未考虑步数达到上限的情况。这就使得每次奖励值都为负几万。因此,应判定每个回合在步数达到上限时也停止。
修改终止条件后,训练能够以正常速度推进。
难题二
由于Gym中封装的MountainCar环境每走一步奖励值为 -1,小车很难学会先向左再向右冲刺的策略。
我先后尝试了多种奖励设计方法:
- 提取状态( s t a t e state state)中的位置信息( p o s i t i o n position position),在该环境中, p o s i t i o n position position 取值范围为 [ − 1.2 , 0.6 ] [-1.2, 0.6] [−1.2,0.6]。若 p o s i t i o n ≥ 0.4 position \geq 0.4 position≥0.4,则 r e w a r d reward reward 加 1,以此奖励小车到达更靠右的位置。
- 为奖励小车尽可能到达更靠右的位置,直接设计一个关于 p o s i t i o n position position 的一次多项式,即 r e w a r d + = α ( p o s i t i o n + 0.5 ) reward += \alpha(position + 0.5) reward+=α(position+0.5),加 0.5 是因为小车初始位置约为 -0.5。
- 奖励小车向右的速度,公式为 r e w a r d + = α ( p o s i t i o n + 0.5 ) + β v e l o c i t y reward += \alpha(position + 0.5) + \beta velocity reward+=α(position+0.5)+βvelocity。
- 为激励小车更多地探索先向左再向右的路径,设计了一个势能奖励函数,采用二次多项式形式,即 r e w a r d + = α 2 ( p o s i t i o n + 0.5 ) 2 + α 1 ( p o s i t i o n + 0.5 ) + β v e l o c i t y reward += \alpha_2(position + 0.5)^2 + \alpha_1(position + 0.5) + \beta velocity reward+=α2(position+0.5)2+α1(position+0.5)+βvelocity。
经过逐步设计与尝试,最终发现第四种方案最为完善。经过参数调整后,成功训练小车到达山顶。
Dueling DQN实现流程
使用DQN的改进版本Dueling DQN,只需在DQN网络基础上拆分为两个子网络,并进行优势函数的计算。
遇到的难题
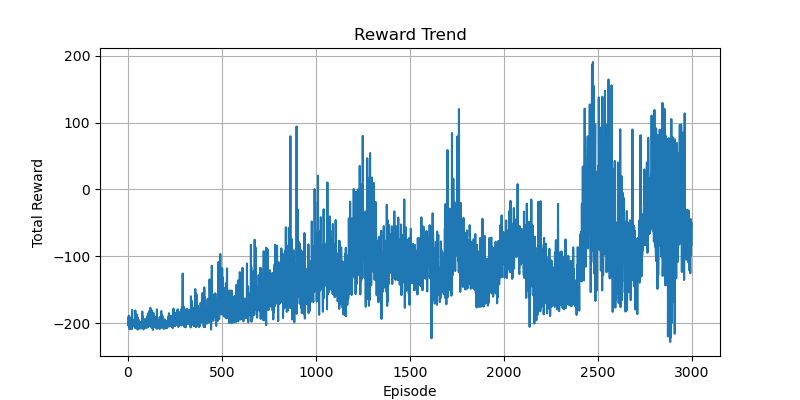
最初,网络结构设定为 2->128->128->128->3,训练结果难以收敛。我推测可能是网络结构过于复杂,导致权重参数极为稀疏。于是,我去掉了两个隐藏层,将网络结构改为 2->128->3,训练效果得到显著提升。

两种方法训练结果对比
训练曲线比较
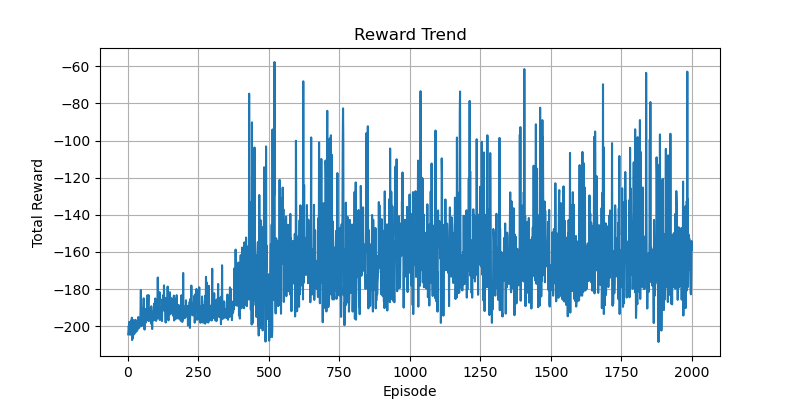
我在代码中添加了保存TensorBoard日志的功能,这样可以通过TensorBoard查看不同训练任务的曲线变化。
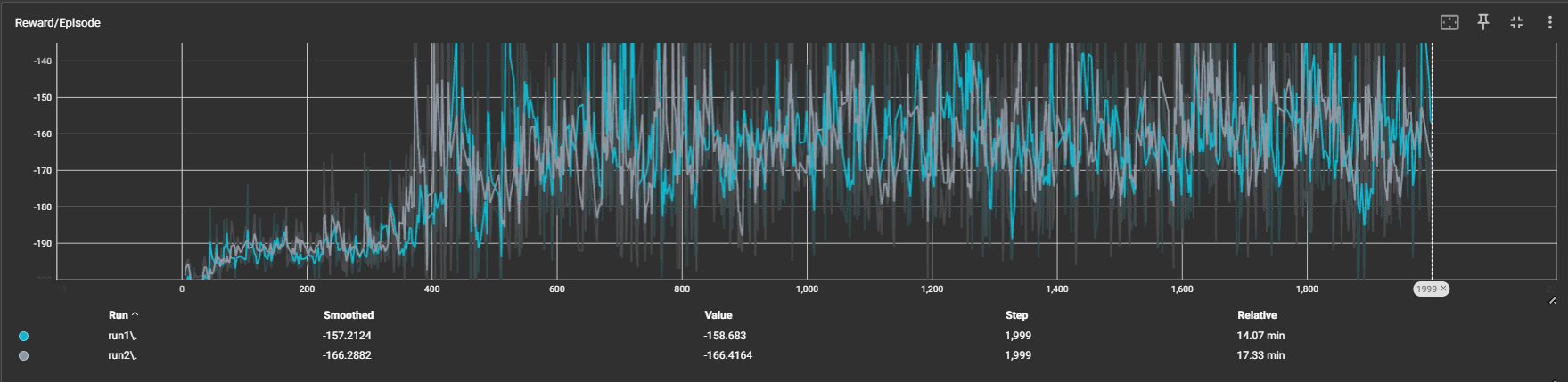
从图中可以看出,在同一套奖励函数和参数设置下,两种方法的训练速度和收敛速度相近。
最终策略比较
通过测试功能,可以观察到两种方法训练出的策略。两种方法都能让小车成功到达山顶,但奖励表现存在些许差异。可以发现,Dueling DQN的训练结果得分更高,策略变化的波动更小。
[检查点] 从 runs/Dueling_exp6/model_final.pt 加载模型:回合数 = 2000,探索率(epsilon) = 0.600
进行 10 个回合的测试...测试 #1:奖励值 = -113.00测试 #2:奖励值 = -113.00测试 #3:奖励值 = -113.00测试 #4:奖励值 = -113.00测试 #5:奖励值 = -113.00测试 #6:奖励值 = -112.00测试 #7:奖励值 = -113.00测试 #8:奖励值 = -113.00测试 #9:奖励值 = -92.00测试 #10:奖励值 = -115.00
10 个回合的平均奖励值:-111.00 ± 6.37[检查点] 从 runs/exp6/model_final.pt 加载模型:回合数 = 2000,探索率(epsilon) = 0.600
进行 10 个回合的测试...测试 #1:奖励值 = -119.00测试 #2:奖励值 = -121.00测试 #3:奖励值 = -186.00测试 #4:奖励值 = -160.00测试 #5:奖励值 = -158.00测试 #6:奖励值 = -115.00测试 #7:奖励值 = -160.00测试 #8:奖励值 = -158.00测试 #9:奖励值 = -89.00测试 #10:奖励值 = -119.00
10 个回合的平均奖励值:-138.50 ± 28.30
最后提供代码:
import os
import time
import argparse
import random
import numpy as np
import gymnasium as gym
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from collections import deque
import matplotlib.pyplot as plt# ---------- 参数配置区域 ----------
EPISODES = 2000 # 最大训练轮数
BATCH_SIZE = 64 # 批次大小
GAMMA = 0.99 # 折扣因子
LR = 1e-3 # 学习率
EPS_START, EPS_END = 1.0, 0.6 # ε-greedy 起始/最小
EPS_DECAY = 0.995 # ε 衰减
TARGET_UPDATE = 10 # (已废弃,按步数更新)
TARGET_UPDATE_STEPS = 500 # 梯度更新步数间隔更新目标网络
REPLAY_BUFFER_SIZE = 10000 # Replay Buffer 容量
SAVE_INTERVAL = 50 # Checkpoint 保存间隔 (episodes)
RENDER_DELAY = 0.01 # 渲染延迟(秒)
ALPHA = 6 # reward 参数(未用)
ALPHA2 = 2
ALPHA1 = 1
BETA = 1
# ----------------------------device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# ---------- 标准 DQN ----------
class DQN(nn.Module):def __init__(self, obs_dim, action_dim):super().__init__()self.net = nn.Sequential(nn.Linear(obs_dim, 128), nn.ReLU(),# nn.Linear(128, 128), nn.ReLU(),nn.Linear(128, action_dim))def forward(self, x):return self.net(x)# ---------- Dueling DQN ----------
class DuelingDQN(nn.Module):def __init__(self, obs_dim, action_dim):super().__init__()# 共享特征层self.feature = nn.Sequential(nn.Linear(obs_dim, 128), nn.ReLU(),# nn.Linear(128, 128), nn.ReLU())# Advantage 分支self.advantage = nn.Sequential(# nn.Linear(128, 128), nn.ReLU(),nn.Linear(128, action_dim))# Value 分支self.value = nn.Sequential(# nn.Linear(128, 128), nn.ReLU(),nn.Linear(128, 1))def forward(self, x):x = self.feature(x)adv = self.advantage(x) # [B, A]val = self.value(x) # [B, 1]# Q(s,a) = V(s) + (A(s,a) - mean_a A(s,a))q = val + adv - adv.mean(dim=1, keepdim=True)return qclass ReplayBuffer:def __init__(self, capacity):self.buffer = deque(maxlen=capacity)def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, batch_size):batch = random.sample(self.buffer, batch_size)state, action, reward, next_state, done = map(np.array, zip(*batch))return state, action, reward, next_state, donedef __len__(self):return len(self.buffer)def save_checkpoint(path, policy_net, target_net, optimizer, episode, epsilon, rewards):os.makedirs(os.path.dirname(path), exist_ok=True)torch.save({'episode': episode,'epsilon': epsilon,'policy_state': policy_net.state_dict(),'target_state': target_net.state_dict(),'optim_state': optimizer.state_dict(),'episode_rewards': rewards,}, path)print(f"[Checkpoint] Saved to {path}")def load_checkpoint(path, policy_net, target_net, optimizer):data = torch.load(path, map_location=device)policy_net.load_state_dict(data['policy_state'])target_net.load_state_dict(data['target_state'])optimizer.load_state_dict(data['optim_state'])print(f"[Checkpoint] Loaded from {path}: episode={data['episode']}, epsilon={data['epsilon']:.3f}")return data['episode'], data['epsilon'], data['episode_rewards']def train(args):base_dir = os.path.join('runs', args.task_name)env = gym.make("MountainCar-v0", render_mode="human") if args.visualize_train else gym.make("MountainCar-v0")obs_dim = env.observation_space.shape[0]action_dim = env.action_space.n# 根据命令行参数选择网络net_cls = DuelingDQN if args.dueling else DQNpolicy_net = net_cls(obs_dim, action_dim).to(device)target_net = net_cls(obs_dim, action_dim).to(device)target_net.load_state_dict(policy_net.state_dict())target_net.eval()optimizer = optim.Adam(policy_net.parameters(), lr=LR)buffer = ReplayBuffer(REPLAY_BUFFER_SIZE)writer = SummaryWriter(base_dir)episode_rewards = []epsilon = EPS_STARTstart_ep = 0update_steps = 0if args.resume and args.checkpoint and os.path.isfile(args.checkpoint):start_ep, epsilon, episode_rewards = load_checkpoint(args.checkpoint, policy_net, target_net, optimizer)print("Start training...")for episode in range(start_ep, EPISODES):state, _ = env.reset()state = np.array(state, dtype=np.float32)total_r = 0.0done = Falsewhile not done:if args.visualize_train:env.render()time.sleep(RENDER_DELAY)# ε-greedyif random.random() < epsilon:action = env.action_space.sample()else:with torch.no_grad():qv = policy_net(torch.from_numpy(state).unsqueeze(0).to(device))action = qv.argmax(dim=1).item()next_s, r, terminated, truncated, _ = env.step(action)done = terminated or truncatednext_s = np.array(next_s, dtype=np.float32)position, velocity = next_sshaped_r = rshaped_r += (ALPHA2 * (position + 0.5)**2 + ALPHA1 * (position + 0.5)) + BETA * velocity# if (position >= 0.4):# shaped_r += 1buffer.push(state, action, shaped_r, next_s, done)state = next_stotal_r += shaped_r# 学习更新if len(buffer) >= BATCH_SIZE:s, a, r_b, s2, d = buffer.sample(BATCH_SIZE)s_t = torch.from_numpy(s).to(device)a_t = torch.from_numpy(a).long().unsqueeze(1).to(device)r_t = torch.from_numpy(r_b).float().unsqueeze(1).to(device)s2_t = torch.from_numpy(s2).to(device)d_t = torch.from_numpy(d.astype(np.float32)).unsqueeze(1).to(device)q_curr = policy_net(s_t).gather(1, a_t)with torch.no_grad():q_next = target_net(s2_t).max(1)[0].unsqueeze(1)q_target = r_t + GAMMA * q_next * (1 - d_t)loss = nn.functional.mse_loss(q_curr, q_target)optimizer.zero_grad()loss.backward()optimizer.step()writer.add_scalar("Loss/Train", loss.item(), episode)# 按步数更新目标网络update_steps += 1if update_steps % TARGET_UPDATE_STEPS == 0:target_net.load_state_dict(policy_net.state_dict())# 每集结束后的记录epsilon = max(EPS_END, epsilon * EPS_DECAY)episode_rewards.append(total_r)writer.add_scalar("Reward/Episode", total_r, episode)writer.add_scalar("Epsilon", epsilon, episode)print(f"Episode {episode+1}/{EPISODES} Reward={total_r:.2f} Epsilon={epsilon:.3f}")# 早停检查if args.stop_threshold is not None and len(episode_rewards) >= 10:last10_avg = np.mean(episode_rewards[-10:])if last10_avg > args.stop_threshold:print(f"[Early Stop] Last 10 episodes avg reward = {last10_avg:.2f} > threshold {args.stop_threshold}")break# 定期保存if (episode+1) % SAVE_INTERVAL == 0:ckpt = os.path.join(base_dir, f"model_{episode+1}.pt")save_checkpoint(ckpt, policy_net, target_net, optimizer,episode+1, epsilon, episode_rewards)# 保存最后一版模型final_ckpt = os.path.join(base_dir, "model_final.pt")save_checkpoint(final_ckpt, policy_net, target_net, optimizer,episode+1, epsilon, episode_rewards)env.close()writer.close()# 画训练曲线plt.figure(figsize=(8,4))plt.plot(range(1, len(episode_rewards)+1), episode_rewards)plt.xlabel("Episode")plt.ylabel("Total Reward")plt.title("Reward Trend")plt.grid(True)plt.savefig(os.path.join(base_dir, "training_rewards.png"))plt.show()return policy_netdef test(policy_net, episodes=10):env = gym.make("MountainCar-v0", render_mode="human")rewards = []print(f"Testing over {episodes} episodes...")for i in range(episodes):state, _ = env.reset()state = np.array(state, dtype=np.float32)done = Falsetotal_r = 0.0while not done:env.render()with torch.no_grad():action = policy_net(torch.from_numpy(state).unsqueeze(0).to(device)).argmax(1).item()state, r, terminated, truncated, _ = env.step(action)done = terminated or truncatedstate = np.array(state, dtype=np.float32)total_r += rtime.sleep(0.02)rewards.append(total_r)print(f" Test #{i+1}: Reward = {total_r:.2f}")env.close()mean_r = np.mean(rewards)std_r = np.std(rewards)print(f"Average Reward over {episodes} episodes: {mean_r:.2f} ± {std_r:.2f}")if __name__ == "__main__":parser = argparse.ArgumentParser(description="DQN / DuelingDQN MountainCar with Early Stop & Step-wise Target Update")parser.add_argument("--train", action="store_true")parser.add_argument("--test", action="store_true")parser.add_argument("--resume", action="store_true")parser.add_argument("--checkpoint", type=str, default=None)parser.add_argument("--task_name", type=str, default="default")parser.add_argument("--visualize_train",action="store_true")parser.add_argument("--dueling", action="store_true", help="Use Dueling DQN instead of standard DQN")parser.add_argument("--stop_threshold", type=float, default=None,help="Early stop if avg reward over last 10 eps > this")args = parser.parse_args()model = Noneif args.train:model = train(args)if args.test:net_cls = DuelingDQN if args.dueling else DQNif not model:dummy = net_cls(2, 3).to(device)opt = optim.Adam(dummy.parameters(), lr=LR)ckpt = args.checkpoint or os.path.join('runs', args.task_name, "model_final.pt")if os.path.isfile(ckpt):_, _, _ = load_checkpoint(ckpt, dummy, dummy, opt)model = dummyif model:test(model)