做一个软件需要哪些技术win优化大师
一、简介
K最近邻(K-Nearest Neighbors, KNN) 是一种简单且直观的监督学习算法,适用于分类和回归任务。其核心思想是:相似的数据点在特征空间中彼此接近。KNN通过计算新样本与训练数据中各个样本的距离,找到最近的K个邻居,并根据这些邻居的标签进行预测。
对于分类任务:新样本的类别由K个最近邻居中多数决定
对于回归任务:新样本的输出值由K个最近邻居的平均值决定
二、算法步骤
1.计算距离:
比如传入一个点,先计算这个点于所有样本的距离
2.选择K值
选取距离这个点最近的K个点
3.投票或者加权平均
如果是分类任务,那么就统计K个邻居中的类别数量,拥有最多点的类别就是这个点的类别。如果是回归任务:计算K个邻居的的平均值,这个值就是这个点的值
三、距离计算公式
1.欧式距离:
适用于连接特征
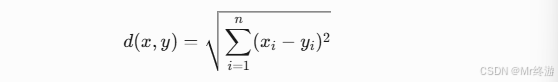
2.曼哈顿距离:
适用于高维数据或稀疏数据,因为那样计算简单

四、K值的选择
1.如果k过小,模型对噪声敏感,容易过拟合。
2. 如果k过大,模型过于平滑,可能欠拟合。
3.最好的办法是通过交叉验证来选择最优的k值
五、KNN代码
import numpy as np
from collections import Counter
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScalerclass KNN:def __init__(self, k=5, distance_metric='euclidean'):self.k = kself.distance_metric = distance_metricdef fit(self, X, y):self.X_train = Xself.y_train = ydef predict(self, X_test):predictions = []for x in X_test:# 计算距离if self.distance_metric == 'euclidean':distances = np.sqrt(np.sum((self.X_train - x) ** 2, axis=1))elif self.distance_metric == 'manhattan':distances = np.sum(np.abs(self.X_train - x), axis=1)else:raise ValueError("Unsupported distance metric")# 获取最近的k个样本的索引k_indices = np.argsort(distances)[:self.k]# 获取这些样本的标签k_labels = self.y_train[k_indices]# 多数投票,如果是回归任务则代码是:predictions.append(np.mean(k_labels))most_common = Counter(k_labels).most_common(1)predictions.append(most_common[0][0])return np.array(predictions)# 测试代码
if __name__ == "__main__":# 加载数据iris = load_iris()X, y = iris.data, iris.target# 数据预处理scaler = StandardScaler()X = scaler.fit_transform(X)# 划分数据集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 训练模型knn = KNN(k=5, distance_metric='euclidean')knn.fit(X_train, y_train)# 预测y_pred = knn.predict(X_test)# 计算准确率accuracy = np.sum(y_pred == y_test) / len(y_test)print(f"准确率: {accuracy:.4f}") # 准确率:0.9778