贵阳手机网站制作抖音营销
1.并查集
(1)基础理论
并查集是一种树形的数据结构,用于处理一些不相交集合的 合并 及 查询 问题。比如,可以用并查集判断一个森林中有几棵树、某个节点是否属于某棵树。
并查集由一个整形数组 pre[] 和两个函数 find() 、 join() 构成。
- 数组 pre[] 记录了每个点的前驱结点
- find(x) 函数用于查找指定节点x属于哪个集合
- join(x,y) 函数用于合并两个节点x、y
# find函数,寻找最上层节点(代表元)
def find(x): # 查找 x 最上层节点while(pre[x] != x): # 如果x的上层不是自己(则说明找到的人不是最上层节点)x = pre[x] # x 继续找上层节点,直到找到最上层节点为止return x # 返回最上层节点# join函数,将两个节点合并到一棵树中
dfs join(x, y) # 将两个节点 x 和 y 合并到一棵树中fx, fy = find(x), find(y) # 寻找 x, y 的代表元if(fx != fy) # 如果 x 和 y 的代表元不相等pre[fx]=fy # 则将 x 的代表元设置为 y路径压缩算法 :将x到根节点路径上的所有点的pre(上级)都设为根节点。
def find(x): # 查找结点 x 的根结点 if pre[x] == x:return x # 递归出口:x 的代表元为 x 本身,即 x 为根结点pre[x] = find(pre[x]) # 找到 x 的上层节点,并将其上层节点更改为根节点return x # 将 x 到根节点路径上的所有节点的前驱结点更改为根节点 路径压缩算法(加权标记法) :用权值大小决定谁做前驱结点
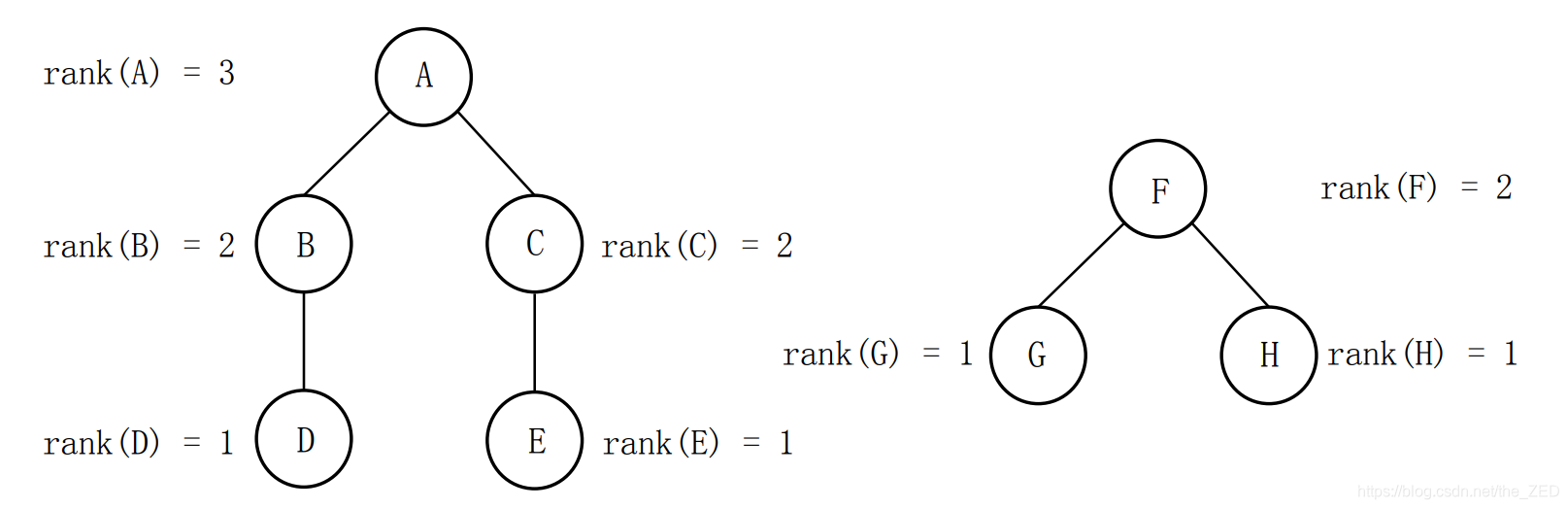
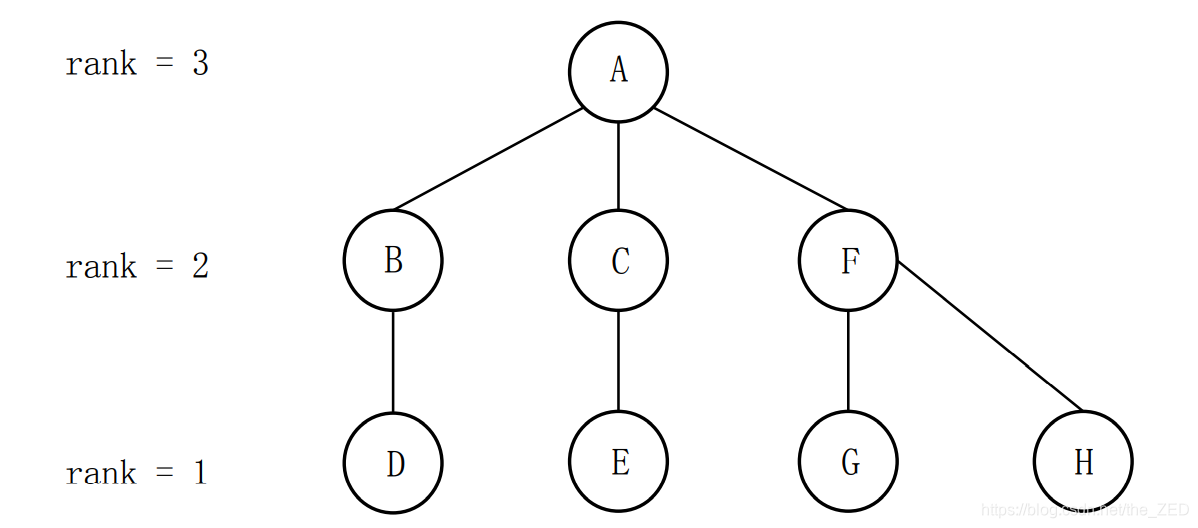
def union(x, y)x, y = find(x), find(y) # 寻找 x,y 的代表元if x==y:return # 如果 x,y 的代表元一致,不需要合并,直接返回if rank[x]>rank[y]: # 如果 x 的高度大于 y,则令 y 的上级为 xpre[y]=x else: # 否则if rank[x]==rank[y]:rank[y]++ # 如果 x 的高度和 y 的高度相同,则令 y 的高度加1pre[x]=y # 让 x 的上级为 y(2)字符串化繁为简
题目说明
给定一个输入字符串,字符串只可能由英文字母 ('a'~'z'、'A'~'Z' )和左右小括号 ('('、')')组成。当字符里存在小括号时,小括号是成对的,可以有一个或多个小括号对,小括号对不会嵌套,小括号对内可以包含1个或多个英文字母,也可以不包含英文字母。当小括号对内包含多个英文字母时,这些字母之间是相互等效的关系,而且等效关系可以在不同的小括号对之间传递,即当存在'a'和'b'等效和存在'b'和'c' 等效时,'a' 和 'c' 也等效,另外,同一个英文字母的大写字母和小写字母也相互等效 (即使它们分布在不同的括号对里)。
需要对这个输入字符串做简化,输出一个新的字符串,输出字符串里只需保留输入字符串里的没有被小括号对包含的字符(按照输入字符串里的字符顺序) ,并将每个字符替换为在小括号对里包含且字典序最小的等效字符。
如果简化后的字符串为空,请输出为"0"。
示例:
输入字符串为"never(dont)give(run)up(f)()",初始等效字符集合为('d','o','n','t')、('r','u','n'),由于等效关系可以传递,因此最终等效字符集合为('d','o','n','t','r','u'),将输入字符串里的剩余部分按字典序最小的等效字符替换后得到"devedgivedp"。
输入描述
input_string
输入为 1 行,代表输入字符串。
输出描述
output_string
输出为 1 行,代表输出字符串。
补充说明
输入字符串的长度在 1 ~ 100000 之间。
示例
示例1
输入 ()abd
输出 abd
说明 输入字符串里没有被小括号包含的子字符串为"abd",其中每个字符没有等效字符,输出为"abd"。
示例2
输入 (abd)demand(fb)for
输出 aemanaaor
说明 等效字符集为('a','b','d','f'),输入字符串里没有被小括号包含的子字符串集合为 "demandfor",将其中字符替换为字典序最小的等效字符后输出为:"aemanaaor"。
示例3
输入 ()happy(xyz)new(wxy)year(t)
输出 happwnewwear
说明 等效字符集为('x','y','z','w'),输入字符串里没有被小括号包含的子字符串集合为"happynewyear",将其中字符替换为字典序最小的等效字符后输出为:"happwnewwear"。
示例4
输入 ()abcdefgAC(a)(Ab)(C)
输出 AAcdefgAC
说明 等效字符集为('a','A','b'),输入字符里没有被小括号包含的子字符串集合为"abcdefgAC",将其中字符替换为字典序最小的等效字符后输出为:"AAcdefgAC"。
# 这道题给我的启示就是虽然看错了题但是也能AC 75%
# 想开点吧孩子s = input()# 并查集实现
class UnionFindSet:def __init__(self, n):self.pre = [i for i in range(n)]def find(self, x):if x != self.pre[x]:self.pre[x] = self.find(self.pre[x])return self.pre[x]return xdef join(self, x, y):x_root = self.find(x)y_root = self.find(y)# 保证字典序小的字符优先为根if x_root < y_root:self.pre[y_root] = x_rootelse:self.pre[x_root] = y_rootdef solve():new_s = [] # 主体字符容器equal = [] # 等效字符容器ufs = UnionFindSet(128) # 使用并查集记录等效传递关系, 数组索引对应 0~127 ASCII码值的字符letters = set() # set记录已被加入到ufs的字母isOpen = False # isOpen标志,表示有没有遇到 '(' 字符for c in s:if c == '(':isOpen = True # 接下来将开始收集等效字符elif c == ')':isOpen = False # 某个()内的等效字符收集完成if len(equal) == 0:continue# 括号间等效传递for letter in equal:# 不同括号间的大小写字母可以形成等效传递upper = letter - 32lower = letter + 32# set记录的是之前括号里面出现过的字母if lower in letters:ufs.join(letter, lower)if upper in letters:ufs.join(letter, upper)# 括号内等效传递cur_root = equal[0]for letter in equal:ufs.join(letter, cur_root)letters.add(letter) # 将当前()内字符加入set# 清空eq, 用于收集下个()内的字母equal.clear()elif isOpen:equal.append(ord(c)) # 等效字符容器else:new_s.append(ord(c)) # 主体字符容器# 等效替换for i in range(128):root = ufs.find(i) # 找到i字母的等效的字典序最小的字母root# 将i替换为rootfor j in range(len(new_s)):if new_s[j] == i:new_s[j] = rootres = "".join(map(lambda x: chr(x), new_s))if len(res) == 0:return("0") # 如果简化后的字符串为空,请输出为"0"else:return(res)print(solve())(3)服务器广播
题目描述
服务器连接方式包括直接相连,间接连接。
A和B直接连接,B和C直接连接,则A和C间接连接。
直接连接和间接连接都可以发送广播。
给出一个N*N数组,代表N个服务器,
matrix[i][j] == 1,
则代表i和j直接连接;不等于 1 时,代表i和j不直接连接。
matrix[i][i] == 1,
即自己和自己直接连接。matrix[i][j] == matrix[j][i]。
计算初始需要给几台服务器广播, 才可以使每个服务器都收到广播。
输入描述
输入为N行,每行有N个数字,为0或1,由空格分隔,
构成N*N的数组,N的范围为 1 <= N <= 40
输出描述
输出一个数字,为需要广播的服务器的数量
示例1
# 输入
1 0 0
0 1 0
0 0 1# 输出
3# 说明:3 台服务器互不连接,所以需要分别广播这 3 台服务器
示例2
# 输入
1 1
1 1# 输出
1# 说明:2 台服务器相互连接,所以只需要广播其中一台服务器# 要在ufs的定义函数中做文章,self.pre可以不使用,也可以在init里定义其他需要用到的参数
# 本题中进行一次join操作相当于少了一个需要广播的计算机
# 因此对join函数进行改动matrix = []
while True:try:matrix.append(list(map(int, input().split())))except:breakclass UnionFindSet:def __init__(self, n):self.pre = [i for i in range(n)]self.count = ndef find(self, x):if x != self.pre[x]:self.pre[x] = self.find(self.pre[x])return self.pre[x]return xdef join(self, x, y):x_root = self.find(x)y_root = self.find(y)if x_root != y_root:self.pre[y_root] = x_rootself.count -= 1returndef solve():n = len(matrix)ufs = UnionFindSet(n)for i in range(n):for j in range(i, n):if matrix[i][j] == 1:ufs.join(i, j)return ufs.countprint(solve())(4)走梅花桩
题目描述
少林寺武僧有一项训练科目就是走梅花桩,现在有 m 行 n 列的梅花桩,每个梅花桩都有一个高度,若相邻梅花桩之间的高度相差为 x,则可以走到相邻梅花桩上。
少林武僧可以选择任意起始位置,请你计算出少林武僧最多可以走多少个梅花桩。
输入描述
第一行输入 m 和 n 和 x,以空格分隔。m 和 n 不大于100。高度差 x 不大于10。
之后 m 行,每行 n 个数,分别表示梅花桩的高度。高度不大于100。
输出描述
请输出少林武僧最多可以走的梅花桩数量。
用例
输入
5 5 1
1 2 3 4 5
9 8 7 6 5
9 9 9 9 9
1 2 3 4 5
1 2 3 4 5
输出
15# 竟然会做了!惊喜!
m, n, x = list(map(int, input().split()))
matrix = []
for _ in range(m):matrix.append(list(map(int, input().split())))
# print(matrix)class UnionFindSet:def __init__(self, m, n):self.pre = [i for i in range(m*n)]def find(self, x):if x != self.pre[x]:self.pre[x] = self.find(self.pre[x])return self.pre[x]return xdef join(self, x, y):x_root = self.find(x)y_root = self.find(y)if x_root != y_root:self.pre[y_root] = x_rootdef solve():ufs = UnionFindSet(m, n)dir = ((-1, 0), (0, -1), (1, 0), (0, 1))for i in range(m):for j in range(n):for d in dir:newi = i + d[0]newj = j + d[1]if 0 <= newi < m and 0 <= newj < n and abs(matrix[i][j] - matrix[newi][newj]) <= x:ufs.join(n*i+j, n*newi+newj)else:continueans = [0 for _ in range(m*n)]for index in range(m*n):ans[ufs.find(index)] += 1return max(ans)print(solve())
(5)Linux 发行版的数量
题目描述
Linux操作系统有多个发行版,distrowatch.com提供了各个发行版的资料。这些发行版互相存在关联,例如Ubuntu基于Debian开发,而Mint又基于Ubuntu开发,那么我们认为Mint同Debian也存在关联。
发行版集是一个或多个相关存在关联的操作系统发行版,集合内不包含没有关联的发行版。
给你一个 n * n 的矩阵 isConnected,其中 isConnected[i][j] = 1 表示第 i 个发行版和第 j 个发行版直接关联,而 isConnected[i][j] = 0 表示二者不直接相连。
返回最大的发行版集中发行版的数量。
输入描述
第一行输入发行版的总数量N,
之后每行表示各发行版间是否直接相关
输出描述
输出最大的发行版集中发行版的数量
备注
1 ≤ N ≤ 200
用例
# 输入
4
1 1 0 0
1 1 1 0
0 1 1 0
0 0 0 1# 输出
3# 说明
Debian(1)和Unbuntu(2)相关
Mint(3)和Ubuntu(2)相关,
EeulerOS(4)和另外三个都不相关,
所以存在两个发行版集,发行版集中发行版的数量分别是3和1,所以输出3。n = int(input())
matrix = []
for _ in range(n):matrix.append(list(map(int, input().split())))class UnionFindSet:def __init__(self, n):self.pre = [i for i in range(n)]def find(self, x):if x != self.pre[x]:self.pre[x] = self.find(self.pre[x])return self.pre[x]return xdef join(self, x, y):x_root = self.find(x)y_root = self.find(y)if x_root != y_root:self.pre[y_root] = x_rootdef solve():ufs = UnionFindSet(n)for i in range(n):for j in range(i+1, n):if matrix[i][j] == 1:ufs.join(i, j)ans = [0 for _ in range(n)]for i in range(n):ans[ufs.find(i)] += 1return max(ans)print(solve())(6)精准核酸检测
题目描述
为了达到新冠疫情精准防控的需要,为了避免全员核酸检测带来的浪费,需要精准圈定可能被感染的人群。
现在根据传染病流调以及大数据分析,得到了每个人之间在时间、空间上是否存在轨迹的交叉。
现在给定一组确诊人员编号(X1,X2,X3...Xn) 在所有人当中,找出哪些人需要进行核酸检测,输出需要进行核酸检测的人数。(注意:确诊病例自身不需要再做核酸检测)
需要进行核酸检测的人,是病毒传播链条上的所有人员,即有可能通过确诊病例所能传播到的所有人。
例如:A是确诊病例,A和B有接触、B和C有接触 C和D有接触,D和E有接触。那么B、C、D、E都是需要进行核酸检测的
输入描述
第一行为总人数N
第二行为确诊病例人员编号 (确证病例人员数量 < N) ,用逗号隔开
接下来N行,每一行有N个数字,用逗号隔开,其中第i行的第个j数字表名编号i是否与编号j接触过。0表示没有接触,1表示有接触
输出描述
输出需要做核酸检测的人数
补充说明
- 人员编号从0开始
- 0 < N < 100
示例1
输入:
5
1,2
1,1,0,1,0
1,1,0,0,0
0,0,1,0,1
1,0,0,1,0
0,0,1,0,1输出
3说明:
编号为1、2号的人员为确诊病例1号与0号有接触,0号与3号有接触,2号54号有接触。
所以,需要做核酸检测的人是0号、3号、4号,总计3人要进行核酸检测。N = int(input())
people = list(map(int, input().split(",")))
matrix = []
for _ in range(N):matrix.append(list(map(int, input().split(","))))class UnionFindSet:def __init__(self, n):self.pre = [i for i in range(n)]def find(self, x):if x != self.pre[x]:self.pre[x] = self.find(self.pre[x])return self.pre[x]return xdef join(self, x, y, flag):x_root = self.find(x)y_root = self.find(y)if flag[y_ro