合肥知名网站推广企业网站建设流程

<------最重要的是订阅“鲁班模锤”------>
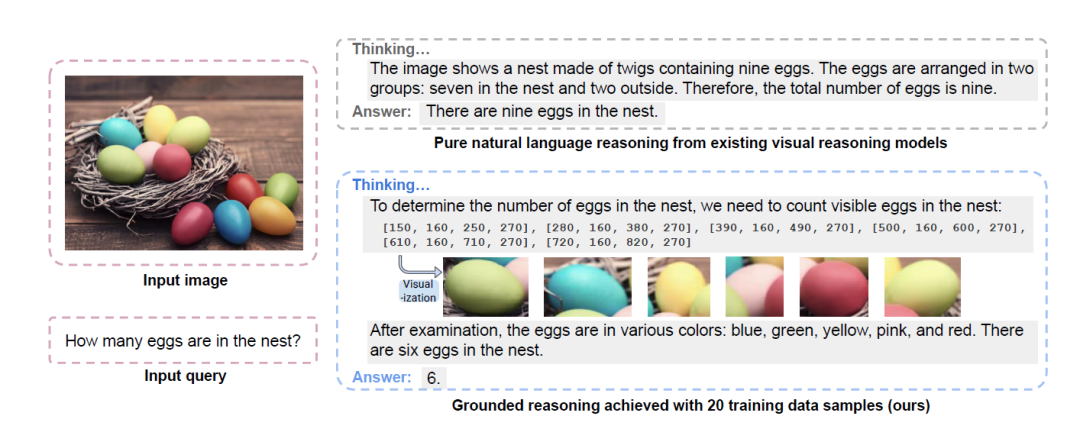
GRIT从本质上而言是一种改良过的强化学习,它针对输出进行了魔改,用一个生活例子来理解。想象一下,你在和朋友看一张照片,朋友问你:"这张照片里有几只猫?"普通人会怎么回答?"我看看,这里有一只白猫(用手指着左上角),那里还有一只黑猫(指着右下角),所以一共有2只猫。"
传统AI是怎么回答的?"我需要仔细观察这张图片,分析其中的动物特征,通过形状、颜色等特征识别,最终得出结论:图片中有2只猫。"
看出区别了吗?人类会指着具体位置来说明自己的推理过程,而传统AI只会给出文字描述,却不会告诉你它在看图片的哪个部分。
1)传统AI的问题在于看图推理时"指鹿为马",分析图片时就像睁眼瞎,也许它可能说"我看到了一只狗",但实际上图片里根本没有狗。它无法告诉你它在看图片的哪个位置。打个比方: 就像一个学生在考试时写答案,却不显示计算过程。老师无法知道他是真的会做,还是瞎猜的。
2)要训练一个能"指着图说话"的AI,传统方法需要数万张图片,每张图片都要人工标注详细信息(这只猫在哪里、那只狗在哪里),还要写出详细的推理步骤。
这就像: 要教一个孩子认识动物,不仅要给他看图片,还要在每张图片上画出每只动物的位置,写出详细的识别过程。工作量巨大。
GRIT进行了微创新,教AI"用坐标指路",GRIT教会AI在推理时不只说话,还要"指路":
-
传统AI的回答:"我看到图片中有车辆,通过分析可以确定有2辆车。"
-
GRIT训练的AI回答:
<think>我需要数一数图片中的车辆。左上角有一辆红色汽车 [123,456,234,567],右下角还有一辆蓝色卡车 [321,432,654,543]</think><rethink>让我再仔细确认一下这两个位置:第一个位置[123,456,234,567]确实是红色汽车,第二个位置[321,432,654,543]确实是蓝色卡车。</rethink><answer>图片中有2辆车。</answer>
这里的数字[123,456,234,567]就是坐标,就像GPS定位一样,告诉你AI在看图片的哪个具体区域!

GRIT的神奇之处:只需要20张图片就能训练成功。GRIT只在答对时给糖果,答错时不给奖励。
-
奖励1 - 格式奖励(教规矩)
-
奖励2 - 计数奖励(教准确)
-
奖励3 - 答案奖励(教正确)
用GPT-4o当"老师"来判断答案对不对,答对了 → 给大奖励,反之答错了 → 给小奖励或不给奖励。
-
如果需要数3只猫,AI指出了3个位置 → 给奖励
-
如果指出了2个或4个位置 → 不给奖励。就像教孩子数数要准确一样
-
如果AI按照 <think>...坐标...</think> 的格式回答 → 给奖励
-
如果AI乱说话不按格式 → 不给奖励,就像教孩子说话要有礼貌一样
传统方法可能需要请100个老师,准备1万本教材,教3个月。而GRIT则是请1个老师,准备20本教材,教1天。而且GRIT让AI变得"诚实":
-
以前用户:"为什么你说这里有只猫?"。AI:"我就是觉得有"(无法解释)
-
现在用户:"为什么你说这里有只猫?",AI:"因为我在坐标[100,200,300,400]这个位置看到了猫的特征"。用户可以立即验证这个位置是否真的有猫

第一步:接收任务输入,例如一张客厅照片 + "房间里有几把椅子?"
第二步:开始思考(<think>阶段)
AI开始扫描图片:
<think>我需要在这张客厅图片中找到所有的椅子。让我仔细看看...第三步:指出位置并分析,AI找到可疑区域并标记坐标:我在左边看到一把木椅 [50,100,150,200],中间有一把沙发椅 [200,150,350,250],右边角落还有一把小椅子 [400,300,500,400]第四步:再次确认(<rethink>阶段)AI重新检查自己找到的位置:<rethink>让我再次确认这些位置:位置[50,100,150,200]:确实是一把木质餐椅位置[200,150,350,250]:这是一把单人沙发椅位置[400,300,500,400]:这是一把小凳子,也算椅子所以总共有3把椅子。</rethink>
第五步:给出最终答案
<answer>房间里有3把椅子。</answer>
以下为强化学习的过程,这个过程很像训练宠物:
第一轮尝试:
AI生成答案:"房间里有椅子[乱七八糟的数字],所以有2把"
系统判断:格式乱、位置错、答案也错奖励:0分(什么都不给)
第二轮尝试:
AI生成答案:"<think>有椅子[100,200,300,400]</think> <answer>1把</answer>"
系统判断:格式对、位置对、但答案错了奖励:1分(格式奖励+位置奖励)
第三轮尝试:
AI生成完整的推理过程,格式正确,位置准确,答案正确奖励:满分!
经过多次训练: AI学会了同时做好三件事:按正确格式回答,准确指出位置,给出正确答案
从视觉定位(grounding)和逻辑推理(reasoning)两个角度评估了使用 GRIT 方法训练的多模态模型在“定位式推理”(grounded reasoning)任务中的表现。接着,从定性与定量两个方面进一步分析了模型生成的边界框与其推理内容之间的相互作用。最后还研究了训练数据规模扩大对模型性能的影响。
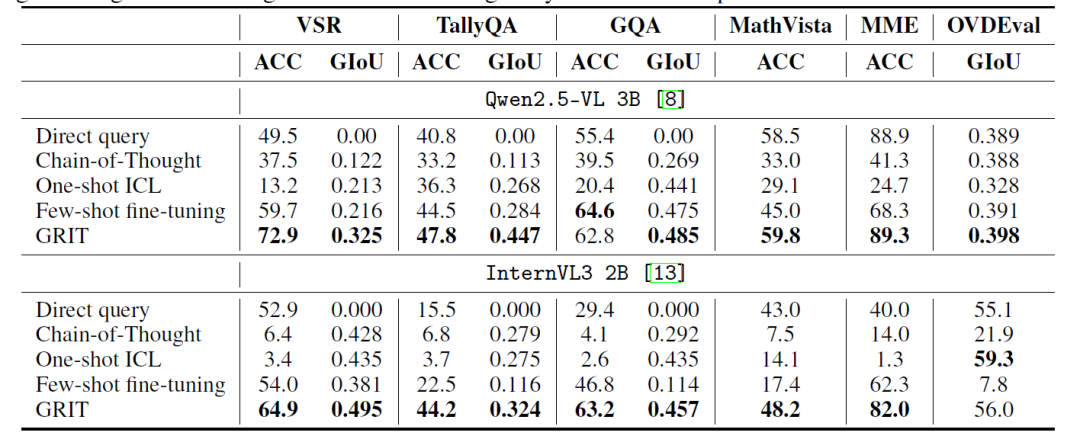
在实验设置方面,选取了六个公共数据集(VSR、TallyQA、GQA、MME、MathVista-mini 和 OVDEval 的位置子集)作为评测集,涵盖空间关系验证、目标计数、组合式空间问答、多样化视觉任务及开放词表定位等任务类型。
训练数据方面,展示了GRIT在小样本场景下的强大能力,仅使用来自VSR和TallyQA的20个图像-问题-答案三元组进行训练。训练使用 Qwen2.5-VL-3B 和 InternVL3-2B 两个主流多模态模型,在 GRPO-GR 策略下采用强化学习进行优化,训练步骤为 200,使用 Deepspeed Zero2 在 8 张 A100 显卡上完成,训练耗时约 12 小时。
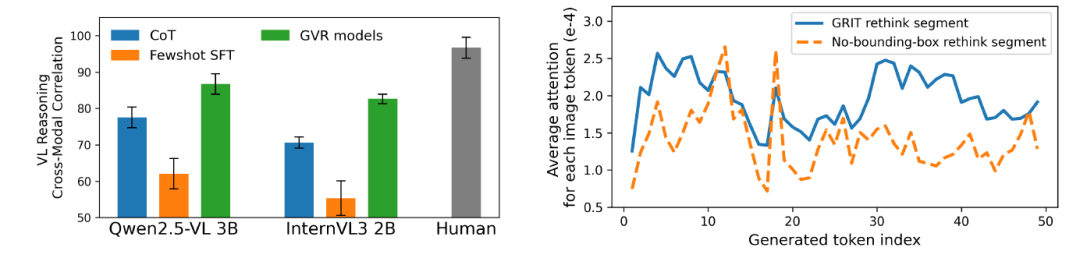
实验结果表明,GRIT 训练出的模型在 GPT-答案准确率和 Grounding IoU 两个指标上均优于所有基线方法,体现了其在统一视觉定位与多步推理能力上的显著优势。

更多专栏请看:
-
LLM背后的基础模型
-
如何优雅的谈论大模型
-
体系化的通识大模型