西宁市网站建设价格网站推广的方式
归一化 Normalization 技术概述、优化思路
- 归一化模型是啥
- 在归一化时,为什么要在 批量 Batch (N)、通道 ( C )、空间 (H,W)、序列长度 (T)、特征维 (D) 这些维度上做均值/方差?每个维度的归一化影响什么?它好在哪儿,又有什么局限?
- 归一化问答
- 归一化模型的优化思路
- 1 | 规范化这一族的共同核心
- 2 | 主流激活归一化方法一览
- 3 | 当我们选择某种 Norm 时,真正在意的四件事
- 4 | 如何把它们看成同一家族的一员
- 5 | 实践小贴士
归一化模型是啥
核心目的:先把数据的分布统一到一个合适的尺度(移除过大或过小的差异),再通过额外的可学习参数保留/修正网络的个性表达。
目标是 把激活值拉回到合理区间,同时保留足够的表达能力。
这就引申到后面两个关键问题:
-
在哪些维度上做“均值 / 方差”统计?
激活值是多维张量,包括批(batch)、通道(channel)、特征/序列长度(feature dimension)以及空间位置(height × width)等。
-
做完归一化后,是否要再加可学习参数修正(𝛾 和 β、g 和 b)?
特殊极简场景:如果你希望网络参数极少(比如只有一个全局缩放),那就可以只保留 𝛾,省去 𝛽。或像 ScaleNorm 只用一个标量。
绝大部分情况下,“带可学习参数”有助于收敛和精度,不建议完全去除。
在归一化时,为什么要在 批量 Batch (N)、通道 ( C )、空间 (H,W)、序列长度 (T)、特征维 (D) 这些维度上做均值/方差?每个维度的归一化影响什么?它好在哪儿,又有什么局限?
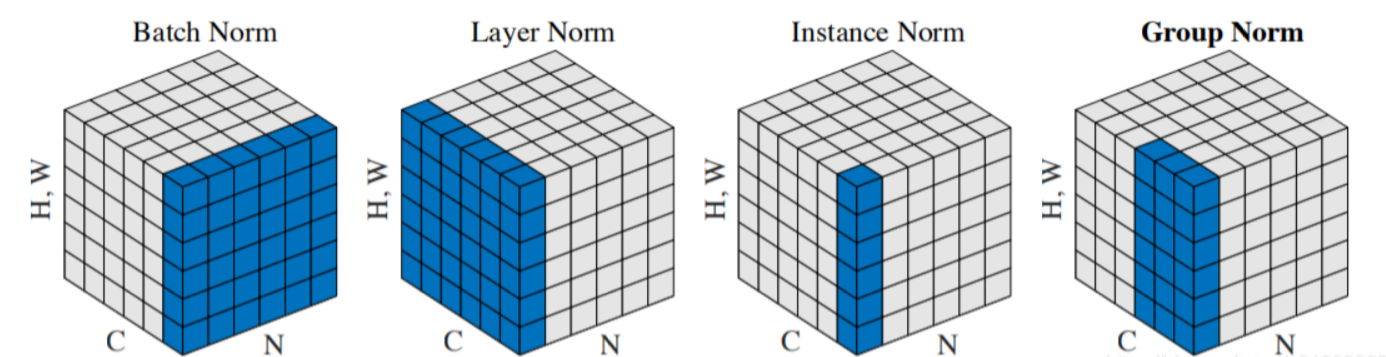
Batch 维度 (N):把“所有顾客的胸围”合并计算一个平均值和标准差,就能快速抓到整体市场的主流尺寸。
如果你只有 2~3 个顾客数据,就很难准确估计“大家的平均胸围”。
在神经网络里:BatchNorm (BN) 就是对同一通道、所有样本 + 像素点做均值/方差,让该通道的激活分布在全局上“对齐”。
大批量时,统计量准确,收敛更快。
小批量时,BN 统计量抖动严重,导致不稳定。对序列模型或小 batch 视觉任务不适用。
全通道合并有时会过度抹平;分组后能保持一定细粒度,又不像 BN 那样依赖大 batch。
如果你把通道跟其他通道的值全混起来做统计,可能破坏了每个通道自带的功能分化(比如“垂直边缘检测”通道 vs “水平边缘检测”通道)。
通道 维度 ( C ):把顾客分成“男性 / 女性 / 儿童 / 成年人”几类,各自算均值/方差,就能让每一类都有更合适的服装尺寸。
分太多组也会让数据样本更少(没法好好估计该组的平均尺寸),或者太少组又会把不同人群混在一起。
在神经网络里:每个通道对应一种特征(例如“垂直边缘检测”或“水平边缘检测”),各自有独立分布,能更灵活地保留不同的特征信息。
如果通道数很大、batch 又小,BN 也不行,需要改用 GN(把通道分组)或 LN(干脆把通道都当成一个整体)。
通道数越多,网络越需要小心选择归一化方式。
因为大通道数会带来更丰富的特征表达,但也意味着更高维的统计。
在图像里,一个通道对应的特征图有 H×W 像素
为什么把同一个通道的“所有像素 (H×W)”放一起算均值/方差?
对于 CNN 来说,一个通道往往是同一种“卷积滤波响应”,这些像素在某种程度上是“一类特征”的空间分布,把它们对齐能减少不必要的局部波动。
因为图像中的局部结构差异不一定是我们想要的“全局偏置”,对训练来说更希望通道内的激活值具有可控的整体分布。
空间 维度 (H,W):你要量一个人的“各个身体部位”(腹部、背部、腿…),但在某种程度上,你把这些部位都当作相似的“躯干特征”,用一个均值/方差一起归一化。可以“抹去”很多局部噪声。
如果你想要非常精细地做衣服,比如要给每个部位精准量身,那就不能把身体各部位都混在一起做一个平均值。
在神经网络里:对同一通道下的 (H,W) 做聚合,能让网络更容易学到整体特征,减少局部差异造成的不稳定。
在神经网络里:若空间特征对任务很重要,过度“抹平”会丢失局部信息。某些任务可能更需要局部响应归一化或别的方法来保留局部差异。
为什么对序列维度也要考虑归一化?
序列模型中,随着时间步增加,激活分布可能漂移,不做归一化的话训练会不稳定、可能出现梯度爆炸/消失。
序列长度 (T):想量一个人不同时期(童年、青年…)的体重,如果你把所有时段的数据都汇总,就能大致知道他的一生体重分布。但有时也可以“各阶段分开看”。
把童年、青年、中年体重都混在一起做一个平均,可能不符合真实需求;每个年龄段的平均才更精准。
在神经网络里:对 RNN/Transformer 来说,时间步 (T) 可能很长。如果想让“同一批数据里各时间步”都归一化,可以获得一定的统一性,减少训练不稳定。
BN 对时间维度往往失效,因为序列数据差异大;LN 通常只对每个时刻的特征维度做统计,不跨 T 合并。
D 通常就是隐藏层大小或向量维度
在 MLP / Transformer 中,特征维 (D) 是最主要的归一化对象。
因为这些网络里,输入/输出是向量(多层感知机)或嵌入向量(Transformer),对向量的均值/方差做统一归一化是很直接的做法。
为什么对同一个样本在其“所有特征”上做统计可以稳定训练?
答:把 D 维度的激活值零均值、单位方差后,能让反向梯度在各种特征维度上传播更平滑,不易爆炸或消失。
为什么要保留可学习参数 (γ, β)?
答:因为把特征全部拉到同一个分布,容易“抹平个性”,需要 γ, β 在训练中恢复/调节一些有用差异。
特征维度 (D):如果你给某个人量了几十个身体指标(腿长、脚长、肩宽…),想统一“归一到同一量级”,就要对全部指标做一个统计,让它们都落在合适区间。
如果你的指标分属于截然不同的类别,可能不该全部混在一起做平均,比如把“血压、体脂率”跟“身高、肩宽”统统合并统计,有时会失去差异。
在神经网络里:对特征维 (D) 做均值/方差(如 LN 或 RMSNorm)能稳定梯度,对 MLP/Transformer 中的“向量输出”尤其自然。
不一定所有特征都应该统一到一个分布,尤其通道多时,或与序列/空间维度强耦合时,需要更灵活的方法(GN、IN)。
总结,不同维度归一化的关键“联想”:
-
Batch (N)
-
类比:全市场人群的大数据拿来做均值。
-
好处:大批量效果好。
当批量 (batch size) 足够大时,不同样本之间的差异能彼此抵消,求得的均值/方差对整个通道的分布有较好的估计。
加速收敛:BatchNorm 的确是被广泛验证过的,能让卷积网络(CNN)在大批量下收敛更快、效果更好。
-
局限:小数据(小批量)不行;对时序不友好。
-
实测效果好:在图像分类、检测等主流任务(如 ImageNet 训练)中,大量实验都证明 BN 能带来明显的加速和精度提升(前提是 batch 不小)
-
-
Channel ( C )
-
类比:分类人群再做均值,每类有独立分布。每组的分布都更贴近该组特征。
-
好处:每个通道特征独立,灵活度高,利于提取多种特征。
每个通道独立:在 CNN 中,每个通道往往对应不同卷积滤波器(提取不同特征),让它们各有各的统计量,有利于保留“通道多样性”。
灵活度高:如果通道数多,可以用不同策略:要么像 BN 那样“通道独立 + 合并 batch & 空间”,要么 GN 把通道分成若干组,适应小批量场景。
-
局限:通道数大,batch 小时可能分布估计不稳。
通道划分需要调参:如 GN 要设定分组数 G,分多了或分少了都影响效果,需要实验调优。
-
-
空间 (H,W)
-
类比:把同一个人的身体部位当作一个整体做均值。这样做会把局部的差异抹掉一些,让整体更统一。
-
好处:减少局部噪声,统一特征图。
减少局部噪声:把同一通道下的 (H,W) 像素点合并,可以抹平局部过大或过小的激活值,减轻训练中不必要的局部抖动。
提高整体一致性:尤其在 BN、GN、IN 中,都会把 (H,W) 维度放进统计。如风格迁移抹平通道内局部差异,当我们不关心精确的空间分布,而更关心通道维度的“全局响应”时,这种方法效果好。
-
局限:会丢失一定的局部差异,对精细任务要谨慎。。
可能丢失局部细节:如果任务对位置非常敏感(如某些精细分割、姿态估计),把 (H,W) 过度统一,可能损失重要的差异信息。
需要特定任务匹配:风格迁移喜欢这种操作,因为它想抹掉原图的统计特征(InstanceNorm 就单通道对 (H,W) 归一化),但有些视觉任务不一定希望过度抹平。
-
-
序列 (T)
-
类比:同一个人的不同年龄段数据,要不要合并?
-
好处:可统一序列分布,时序网络可获得更稳定激活分布。
统一序列分布:如果在序列网络里能够做时序归一化(如对每个时间步进行 LN),可以缓解激活漂移,让训练更稳定。
有时可跨时间统计:部分场景下可能对全序列做一次性统计(相对少见),但能捕捉到整个序列的平均激活水平。
-
局限:序列长且差异大,BN 难做;常用 LN (只对特征维)。
长序列/差异大:如果把所有时间步合并做统计,差异过大会冲掉特征信息,或者统计混乱。
-
-
特征 (D)
-
类比:几十个身体指标一起归一化。
-
好处:在 MLP / Transformer 上简单有效。
输入就是 (N, D) 或 (N, T, D)。把 D 维度做 LayerNorm/RMSNorm,立刻能把激活值拉回一个合适范围,减少梯度问题。
梯度更平滑:特征维度内若有过大的偏差,会破坏训练稳定性;LN 或 RMSNorm 就很好地抹平这种偏差。
-
局限:可能抹平过度异质的特征,需要可学习参数 (γ, β) 来找回差异。
可能抹平异质特征:如果特征向量里包含不同类别的信息(比如视觉 + 文本的混合 embedding),完全混在一起做均值/方差可能会过度平滑。
-
归一化问答
| 问 | 答 | 关联/回顾 |
|---|---|---|
| 1. 归一化的目的是什么? | 把每一层输出的 数值分布 拉回到一个统一、可控的范围(通常是零均值、单位方差附近),从而 加快收敛、稳定梯度。 | 想想机器学习里对特征做 z-score 标准化:防止某一列数值特别大主导了训练。 |
| 2. 为什么要“拉回统一分布”? | 如果某层输出忽大忽小,下一层可能“饱和”或“梯度爆炸/消失”,导致训练变慢甚至不收敛。 | 类比:做实验时先把秤归零,才好准确称重。 |
| 3. 归一化到底“动”了哪两个统计量? | 均值 m u mu mu(平移)和 方差 s i g m a 2 sigma^2 sigma2(缩放)。 | 回忆高斯分布位置-尺度变换: ( x − μ ) / σ (x-\mu)/\sigma (x−μ)/σ。 |
| 4. 归一化公式里出现的 a ^ _ i = ( a _ i − μ ) / σ \hat a\_i = (a\_i-\mu)/\sigma a^_i=(a_i−μ)/σ 是什么? | 这是把原激活 a _ i a\_i a_i 调整到 零均值、单位标准差 的“标准化”步骤。 | 正态分布教材里的 z-score 公式。 |
| 5. 公式里后来又乘 γ \gamma γ、加 β \beta β 是干什么? | 这是 仿射恢复:允许网络再学回最适合任务的尺度( γ \gamma γ)和偏移( β \beta β),避免归一化后“千篇一律”削弱表达力。 | 给网络自由度,以得到最适合当前任务的特征分布。相当于先把照片统一调成灰度,再让修图软件加回对比度和亮度。 |
| 6. μ \mu μ、 σ \sigma σ 跟 γ \gamma γ、 β \beta β 的来源一样吗? | 不同: • μ , σ \mu,\sigma μ,σ 是 统计量,在选定的数据集合里实时或滑动计算; • γ , β \gamma,\beta γ,β 是 可训练参数,像普通权重一样反向传播更新。 | 分类模型里的权重 vs 训练时对数据计算的平均准确率。 |
| 7. “选定的数据集合”指什么? | 归一化族的分水岭就在 统计范围 $S$: • BatchNorm:同一通道、整个 mini-batch 的所有像素; • LayerNorm:同一样本内的所有特征维; • Group/InstanceNorm:介于两者之间; • RMSNorm:同 LayerNorm 但只用均方根。 | 回忆方差的统计学“样本数”概念——不同“桶”会算不同均值方差。 |
| 8. 为什么 BatchNorm 对批大小敏感? | 它用 整批 来算 μ , σ \mu,\sigma μ,σ。批越小,统计越不稳定,导致噪声梯度或推理阶段训练-测试分布漂移。 | 小样本统计方差大;抽样误差。 |
| 9. LayerNorm 为什么适合 Transformer/语言模型? | 它在 单个序列样本内部 计算统计量,跟批大小无关,也不会破坏序列长度可变性。 | 类比:对一句话自己做语境归一化,而不和别人的句子一起平均。 |
| 10. 实际训练时归一化让学习率可以调得更大吗? | 通常可以。因为激活被压到可控范围后,梯度分布更稳定,较大的学习率不容易震荡。 | 想起批归一化论文标题里的“Accelerating Deep Network Training”。 |
| 11. 归一化会不会削弱非线性、让网络变成线性模型? | 如果只做 ( a − μ ) / σ (a-\mu)/\sigma (a−μ)/σ 的确会。但 γ , β \gamma,\beta γ,β 把“个性”加回来;同时归一化前后仍会接激活函数 f ( ⋅ ) f(\cdot) f(⋅)(ReLU、GELU 等),保持非线性。 | 在减数分裂示例里“只减同源染色体”但仍保留遗传多样性类似。 |
| 12. “Pre-Norm / Post-Norm”,是什么意思? | 指 归一化放在残差块 之前还是之后: • Pre-Norm(如 GPT-NeoX)更稳深层梯度; • Post-Norm(原 Transformer)易出现梯度消失。 | RNN 时代的“梯度穿透”技巧。 |
| 13. RMSNorm 与 LayerNorm 的唯一区别是什么? | RMSNorm 不减均值,只除以均方根 mean ( a 2 ) \sqrt{\text{mean}(a^2)} mean(a2)。这样少一次减法,数值更稳、显存少一点。 | 数学里常用 均方根 近似标准差。 |
| 14. 如果我要在小批量目标检测里用,首选哪一种?为什么? | GroupNorm:批无关,又能保留些通道结构;经验上在批=2~8 的目标检测和分割模型效果最好。 | PyTorch Detectron2 默认设置。 |
| 15. 什么时候可以完全不用激活归一化? | 若使用 残差、SkipInit、合适初始化或自归一化激活(SELU),在小网络上有时可省。但大规模训练通常还是加一层 Norm 更保险。 | 想到权重标准化和 Dropout:不同正则互补。 |
归一化模型的优化思路
1 | 规范化这一族的共同核心
所有 Normalization 方法都做两件事:
| 步骤 | 目的 | 数学操作 |
|---|---|---|
| 标准化 (standardize) | 把本批/本样本/本通道里的数据移到 零均值、单位方差或其它统一尺度,以消除分布漂移、让梯度落在线性区 | a ^ _ i = a _ i − μ _ S σ _ S \displaystyle \hat a\_i=\frac{a\_i-\mu\_S}{\sigma\_S} a^_i=σ_Sa_i−μ_S |
| 仿射恢复 (re-affine) | 给模型留出“个性”——在统一尺度上再学得一组可训练 γ , β \gamma,\beta γ,β,保证网络在需要时仍能产生非线性和不同幅度 | h _ i ′ = f ( γ a ^ _ i + β ) h\_i' = f(\gamma\hat a\_i+\beta) h_i′=f(γa^_i+β) |
差异几乎全部体现在 “统计集合 S S S 的选取” 和 “所用统计量” 上:

- 改变 S S S → 影响 计算复杂度、对批大小的敏感度、对顺序/空间结构的保留程度
- 改变统计量(均值+方差 / 仅 RMS / 最大值 …)→ 影响 数值稳定性 与 正则化强度
2 | 主流激活归一化方法一览
| 方法 (发表年份) | 统计集合 $S$ | 与批大小关系 | 主要优缺点与典型场景 |
|---|---|---|---|
| BatchNorm (2015) | 整个 mini-batch × 空间位置,每个通道独立 | 依赖批;推理期要用滑动平均 | 卷积/MLP 的事实标准;批小或序列模型效果差 |
| LayerNorm (2016) | 同一样本里的全部特征维 | 与批无关 | RNN/Transformer 标配;图像 CNN 效果略逊 |
| InstanceNorm (2016) | 同一样本、同一通道的空间位置 | 与批无关 | 图像风格迁移:把内容图的统计量擦掉、保留风格 |
| GroupNorm (2018) | 把通道分 G 组,组内像 LayerNorm | 与批无关;G=1≈Layer、G=C≈Instance | 小批量视觉任务(检测、分割) |
| RMSNorm (2019) | 仅除以 RMS,不减均值;$S$ 同 Layer | 批无关,少一次减法 | 大语言模型常用;数值更稳、更省显存 |
| ScaleNorm (2019) | 对整层向量取 $|a|_2$,再乘全局标量 | 极简,无 β | Transformer 轻量替代品 |
| Filter Response Norm (FRN) (2019) | 每通道均值,再除以 $\sqrt{\text{mean}(a^2)+\epsilon}$ | 批无关 | 图像小批量、去除 mean 可能坏时用 |
| WeightNorm / SpectralNorm | 归一化 权重 而非激活 | 批无关,推理友好 | WeightNorm 加速收敛;SpectralNorm 控 Lipschitz、稳 GAN |
| Recent variants (2022-2024) | “NormFormer” 里的 Pre-Norm + 深度可学习系数、ReRMSNorm 等 | 针对超深/稀疏模型微调 | 改善收敛、稳定梯度或节省显存 |
一句话本质:所有激活归一化都在 “统一尺度 → 保留表达” 的两步之间做权衡,通过改变统计范围或统计量来适应不同网络结构和硬件/数据约束。
3 | 当我们选择某种 Norm 时,真正在意的四件事
| 关注点 | 要问自己的实际问题 | 典型首选 |
|---|---|---|
| 批大小 / 分布稳定性 | 我的任务能维持 >32 的 batch 吗?推理时统计量是否固定? | 批大→BatchNorm;批小或动态长序列→Layer/Group/RMSNorm |
| 结构对称性 | 我想保留空间结构、还是序列位置无关? | 图像 CNN → 通道内统计 (BN, GN);语言模型 → 全层向量统计 (LN, RMSNorm) |
| 计算/显存预算 | 减均值一次够吗?方差再来一次会爆显存吗? | 超大模型 → RMSNorm 或 ScaleNorm |
| 优化/泛化目标 | 我需要严格控制 Lipschitz 以稳 GAN,或需要去掉内容统计? | SpectralNorm、InstanceNorm 等专用方法 |
4 | 如何把它们看成同一家族的一员
-
标准化模板
a ^ i = a i − μ S ( σ S + ϵ ) α \hat a_i = \frac{a_i - \mu_S}{(\sigma_S + \epsilon)^\alpha} a^i=(σS+ϵ)αai−μS
- α = 1 \alpha=1 α=1 → 传统方差归一化
- α = 1 2 \alpha=\tfrac12 α=21 → RMSNorm(只根号、无均值)
-
可学习恢复模板
h i ′ = f ( γ a ^ i + β ) h_i' = f(\gamma \hat a_i + \beta) hi′=f(γa^i+β)
- 可以把 γ , β \gamma,\beta γ,β 简化(ScaleNorm 仅标量 γ;某些变体把 β 去掉)
- 也可以让 γ , β \gamma,\beta γ,β 依赖深度 / 位置(NormFormer)
-
写作规范
- 把 “统计维度” 视为一个开关向量 ( b , c , h , w , … ) (b, c, h, w, \dots) (b,c,h,w,…)
- 调整开关就能从 BN → GN → IN → LN 平滑过渡
5 | 实践小贴士
| 场景 | 推荐策略 |
|---|---|
| Transformer / LLM | RMSNorm(Pre-Norm) ≈ LN,速度省 5-10 %,梯度更稳定;如果出现发散可回退 LN |
| 小批量视觉检测 | GroupNorm (32 通道一组) 大多能替换 BN 而不调 lr |
| 风格迁移 / 图像翻译 | 使用 InstanceNorm;若要保留内容色彩,再加 Adaptive InstanceNorm |
| GAN 判别器 | SpectralNorm 是最稳的 Lipschitz 约束手段 |
| 极深 CNN (>1000 层) | 可考虑 BatchNorm + SkipInit 或 FRN,前者收敛快,后者更稳 |
Normalization 的本质:
用局部统计把激活先“洗成统一身材”,再让可训练参数给它穿回合身衣服。
改变“洗澡的水池”有多大(统计集合 S S S),以及用什么水温(方差 / RMS / 谱范数),就派生出了 BatchNorm、LayerNorm、GroupNorm、RMSNorm 等子类,以适应不同的数据结构、批大小和计算/稳定性需求。