残疾人服务平台seo网站推广经理
问题 1: 为什么使用消息队列?
消息队列的作用:
削峰填谷
解耦
异步
具体的使用场景:
问题 1: 实际没有用过
比如: IM 系统; 秒杀/抢票的削峰填谷
服务搭建
Kafka
- 写一个 docker-compose.yml
version: '3'name: kafka-groupservices:zookeeper-test:image: zookeeperports:- "2181:2181"volumes:- zookeeper_vol:/data- zookeeper_vol:/datalog- zookeeper_vol:/logscontainer_name: zookeeper-testkafka-test:image: wurstmeister/kafkaports:- "9092:9092"environment:KAFKA_ADVERTISED_HOST_NAME: "localhost"KAFKA_ZOOKEEPER_CONNECT: "zookeeper-test:2181"KAFKA_LOG_DIRS: "/kafka/logs"volumes:- kafka_vol:/kafkadepends_on:- zookeeper-testcontainer_name: kafka-testvolumes:zookeeper_vol: {}kafka_vol: {}
- 运行docker compose
docker compose -f <yml 的文件路径> up -d
- 运行 sdk(go-Kafka)功能测试
const (topic = "test-topic"brokerAddress = "localhost:9092"
)func TestKafka() {ctx := context.Background()// 1. 发送消息produceMessage(ctx)// 2. 启动消费者go consumeMessages()// 3. 等待10秒time.Sleep(10 * time.Second)fmt.Println("测试完成,退出程序")
}func produceMessage(ctx context.Context) {writer := &kafka.Writer{Addr: kafka.TCP(brokerAddress),Topic: topic,Balancer: &kafka.LeastBytes{},}defer writer.Close()msg := kafka.Message{Key: []byte("test-key"),Value: []byte(fmt.Sprintf("测试消息 - %s", time.Now().Format(time.RFC3339))),}if err := writer.WriteMessages(ctx, msg); err != nil {log.Fatalf("发送消息失败: %v", err)}fmt.Printf("已发送消息: %s\n", msg.Value)
}func consumeMessages() {reader := kafka.NewReader(kafka.ReaderConfig{Brokers: []string{brokerAddress},Topic: topic,GroupID: "test-group",MinBytes: 10e3,MaxBytes: 10e6,})defer reader.Close()fmt.Println("消费者已启动...")for {msg, err := reader.ReadMessage(context.Background())if err != nil {log.Printf("消费错误: %v", err)continue}fmt.Printf("消费到消息: %s\n", msg.Value)}
}
RocketMQ
编写 docker-compose.yml
version: '3.8'
services:namesrv:image: sha256:a1f797e48d967647d4c61b67130891c7ef4763fd33bddc6c2eba3067330305e8container_name: rmqnamesrvports:- 9876:9876networks:- rocketmqcommand: sh mqnamesrvbroker:image: sha256:a1f797e48d967647d4c61b67130891c7ef4763fd33bddc6c2eba3067330305e8container_name: rmqbrokerports:- 10909:10909- 10911:10911- 10912:10912volumes:- ./broker.conf:/home/rocketmq/rocketmq-5.3.2/conf/broker.confenvironment:- NAMESRV_ADDR=rmqnamesrv:9876depends_on:- namesrvnetworks:- rocketmqcommand: sh mqbroker -c /home/rocketmq/rocketmq-5.3.2/conf/broker.confproxy:image: sha256:a1f797e48d967647d4c61b67130891c7ef4763fd33bddc6c2eba3067330305e8container_name: rmqproxynetworks:- rocketmqdepends_on:- broker- namesrvports:- 8080:8080- 8081:8081restart: on-failureenvironment:- NAMESRV_ADDR=rmqnamesrv:9876command: sh mqproxy
networks:rocketmq:driver: bridge运行docker compose
cd 到存放 docker-compose.yml 的文件夹或者docker compose up 指定文件
- up 指定文件
docker compose -f < compose.yml文件路径> up -d
修改配置文件(解决网络问题)
- 进入容器
docker exec -it rmqbroker bash
- 修改配置
echo "brokerIP1 = 127.0.0.1" >> ../conf/broker.conf
- 重新运行
docker-compose restart
或者使用命令强行设置 IP
docker exec rmqbroker sh mqadmin updateBrokerConfig -b broker-name -k brokerIP1 -v 127.0.0.1 -n 127.0.0.1:9876
- 检查IP 是否设置好
docker exec rmqnamesrv sh mqadmin clusterList -n 127.0.0.1:9876
创建一个 topic
sh ./mqadmin updateTopic -n localhost:9876 -t test-topic -c DefaultCluster -a +message.type=NORMAL
运行skd尝试发送与接收功能
发送
// 测试 1: 单元测试:生产者发消息
func TestProducer(t *testing.T) {// 创建生产者实例p, err := rocketmq.NewProducer(// 设置 NameServer 地址producer.WithNameServer([]string{"127.0.0.1:9876"}),// 设置生产者组名producer.WithGroupName("test_producer_group"),// 设置重试次数producer.WithRetry(2),)if err != nil {fmt.Printf("create producer error: %s\n", err.Error())return}// 启动生产者err = p.Start()if err != nil {fmt.Printf("start producer error: %s\n", err.Error())return}defer p.Shutdown()// 准备发送的消息msg := &primitive.Message{Topic: TestTopic,Body: []byte("Hello RocketMQ From Go Client"),}// 设置消息标签msg.WithTag("TestTag")// 设置消息键msg.WithKeys([]string{"TestKey"})// 发送消息ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)defer cancel()res, err := p.SendSync(ctx, msg)if err != nil {fmt.Printf("send message error: %s\n", err.Error())} else {fmt.Printf("send message success: result=%s\n", res.String())}// 等待中断信号优雅关闭sig := make(chan os.Signal, 1)signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM)<-sig
}
接收
func TestConsumer(t *testing.T) {// 创建消费者实例c := NewConsumer(//消费组consumer.WithGroupName("testGroup"),// namesrv地址consumer.WithNameServer([]string{"127.0.0.1:9876"}),//消费模式consumer.WithConsumeFromWhere(consumer.ConsumeFromFirstOffset),)defer c.Shutdown()// 订阅主题c.Subscribe(TestTopic, Handler1)// 创建生产者p := NewProducer(// 设置 NameServer 地址producer.WithNameServer([]string{"127.0.0.1:9876"}),// 设置生产者组名producer.WithGroupName("test_producer_group"),// 设置重试次数producer.WithRetry(2),)// 启动生产者err := p.Producer.Start()if err != nil {fmt.Printf("start producer error: %s\n", err.Error())return}defer p.Producer.Shutdown()for i := 0; i < 10; i++ {err = p.SendMsg(TestTopic, []byte(fmt.Sprintf("Hello RocketMQ From Go Client %d", i)))if err != nil {fmt.Printf("send message error: %s\n", err.Error())return}}// 等待 5s 后退出time.Sleep(5 * time.Second)
}
event-bus 多消费者
func TestConsumer2(t *testing.T) {// 创建消费者实例1c1 := NewConsumer(//消费组consumer.WithGroupName("testGroup1"),// namesrv地址consumer.WithNameServer([]string{"127.0.0.1:9876"}),//消费模式consumer.WithConsumeFromWhere(consumer.ConsumeFromFirstOffset),)defer c1.Shutdown()// 订阅主题c1.Subscribe(TestTopic, Handler1)// 创建消费者实例2c2 := NewConsumer(//消费组consumer.WithGroupName("testGroup2"),// namesrv地址// namesrv地址consumer.WithNameServer([]string{"127.0.0.1:9876"}),//消费模式consumer.WithConsumeFromWhere(consumer.ConsumeFromFirstOffset),)defer c2.Shutdown()// 订阅主题c2.Subscribe(TestTopic, Handler2)// 创建生产者producerSend()// 等待 5s 后退出time.Sleep(5 * time.Second)
}
压力测试:
Kafka
batch-size(批量大小)
- 批量传输是提升吞吐量的关键参数,主要是提高传输效率(减少发送的次数)
条件: 发送线程数:1; topic 分区数 15 ; 数据大小:79 字节
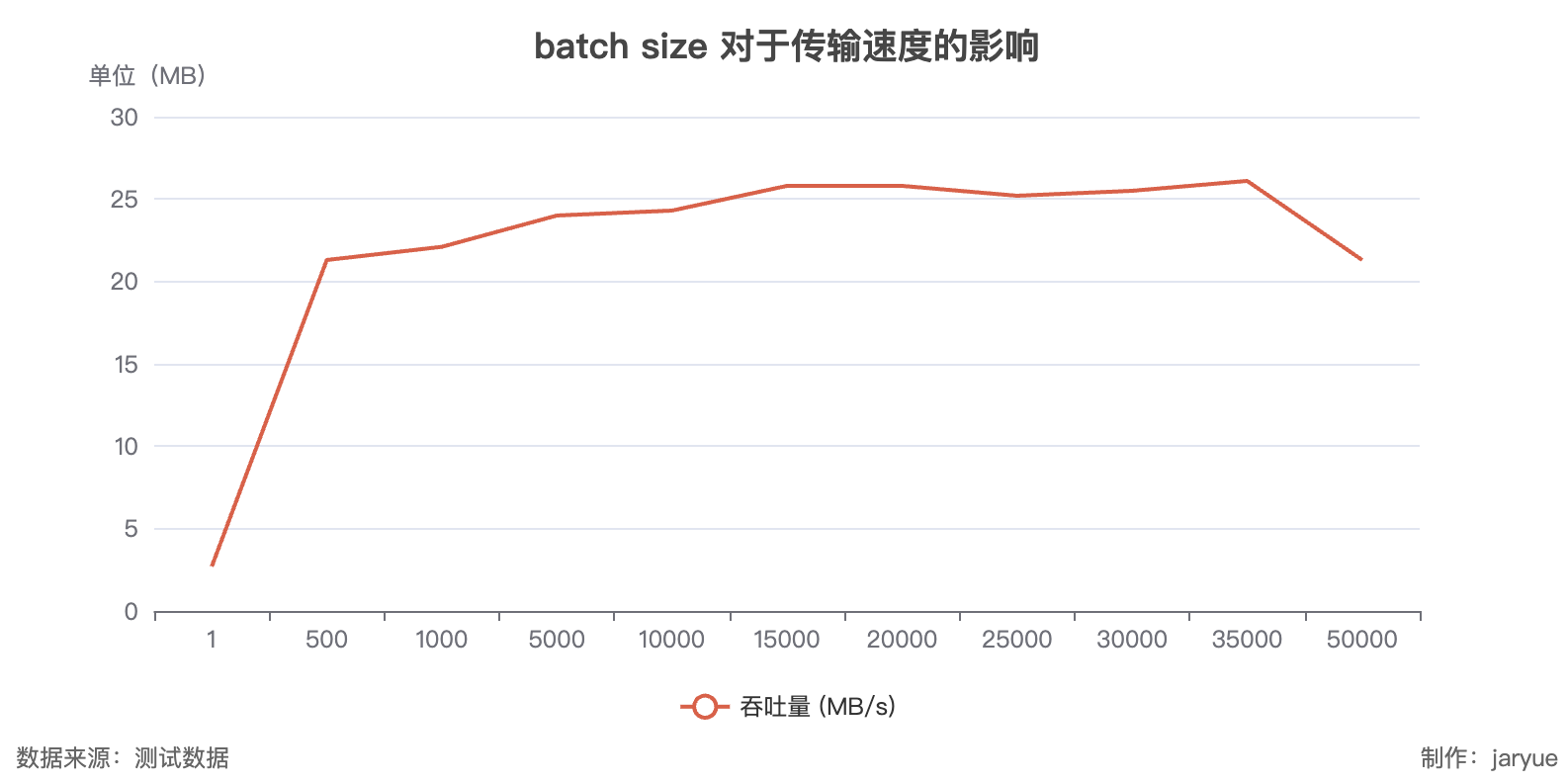
go-kafka sdk测试结果
| Batch-Size | 吞吐量 (MB/s) | 发送数据 (条/s) |
|---|---|---|
| 1 | 2.7 | 34,177 |
| 500 | 21.3 | 269,620 |
| 1000 | 22.1 | 279,746 |
| 5000 | 24 | 303,797 |
| 10000 | 24.3 | 307,595 |
| 15000 | 25.8 | 326,582 |
| 20000 | 25.8 | 326,582 |
| 25000 | 25.2 | 318,987 |
| 30000 | 25.5 | 322,785 |
| 35000 | 26.1 | 330,380 |
| 50000 | 21.3 | 269,620 |
Kafka 自带的压测脚本 测试结果
| batch.size | 记录发送速率 (records/sec) | 吞吐量 (MB/sec) | 平均延迟 (ms) | 最大延迟 (ms) | 50th 百分位延迟 (ms) | 95th 百分位延迟 (ms) | 99th 百分位延迟 (ms) | 99.9th 百分位延迟 (ms) | 备注 |
|---|---|---|---|---|---|---|---|---|---|
| 无设置 | 214,334.71 | 140.43 | 213.22 | 500.00 | 200 | 310 | 413 | 480 | 默认配置 |
| 5,000 | 70,993.48 | 46.51 | 658.11 | 2,310.00 | 633 | 747 | 1,142 | 2,058 | 服务器负载较低,性能较差 |
| 10,000 | 134,605.81 | 88.19 | 345.87 | 637.00 | 335 | 428 | 533 | 631 | 性能显著提升 |
| 15,000 | 199,399.20 | 130.64 | 234.3 | 378.0 | 233 | 343 | 496 | 872 | 服务器接近负载上限 |
| 15,000 (二次) | 186,382.87 | 122.11 | 247.37 | 948.00 | 233 | 343 | 496 | 872 | 略有下降,服务器负载较高 |
| 20,000 | 250,269.04 | 163.97 | 177.39 | 514.00 | 168 | 264 | 390 | 504 | 性能进一步提升 |
| 25,000 | 297,300.51 | 194.78 | 119.14 | 420.00 | 127 | 194 | 371 | 413 | 最佳性能 |
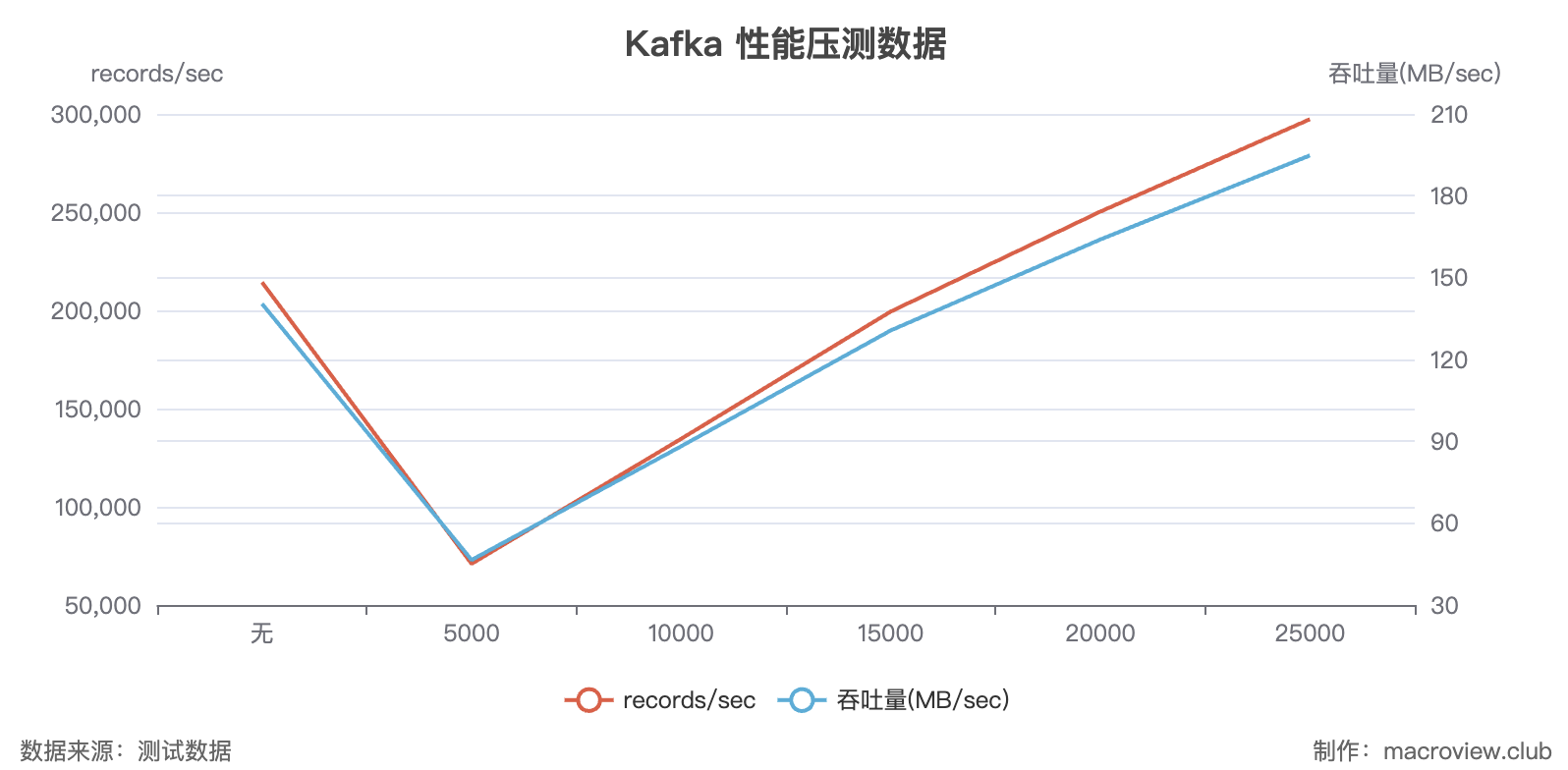
根据两个压测结果来看:
batch-size 越大,吞吐量越高,性能的瓶颈在于 troughput 的大小(接口 QPS/程序每秒能发多少数据给 Kafka)
- batch-size 如何选择: 根据业务接口的 QPS 进行确定;在固定的 QPS 调用的情况下,batch-size 增加到一定值之后变化就不大了
- 比如在 go 的 sdk 的情况下测试,batch-size 1000-5000 波动并不多,5000 之后甚至还有下降的趋势
分区数:发送数据(MB/s)
条件: 发送线程数 1; batch-size:5000;数据大小 79 字节
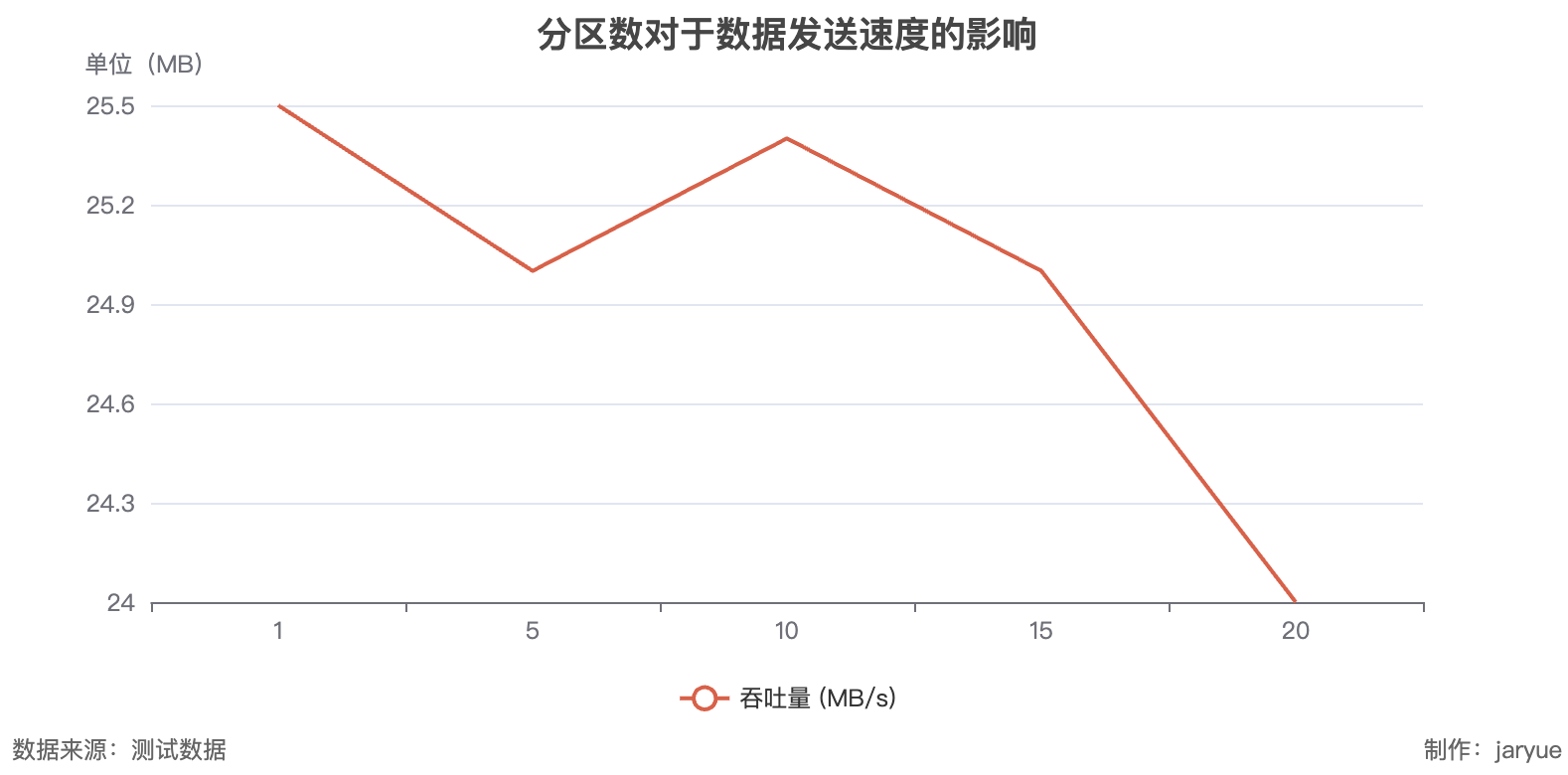
go sdk测试结果
| 分区数 | 吞吐量 (MB/s) | 发送数据 (条/s) |
|---|---|---|
| 1 | 25.5 | 322,785 |
| 5 | 25 | 316,456 |
| 10 | 25.4 | 321,518 |
| 15 | 25 | 316,456 |
| 20 | 24 | 303,797 |
Kafka 自带脚本压测结果
| 分区数 | 记录发送速率 (records/sec) | 吞吐量 (MB/sec) | 平均延迟 (ms) | 最大延迟 (ms) | 50th 百分位延迟 (ms) | 95th 百分位延迟 (ms) | 99th 百分位延迟 (ms) | 99.9th 百分位延迟 (ms) |
|---|---|---|---|---|---|---|---|---|
| 5 | 457,163.76 | 299.52 | 25.63 | 596.00 | 2 | 140 | 263 | 585 |
| 10 | 483,582.38 | 316.83 | 37.15 | 423.00 | 5 | 172 | 244 | 375 |
| 15 | 603,718.91 | 395.54 | 28.11 | 540.00 | 4 | 122 | 172 | 513 |
| 20 | 594,459.64 | 389.47 | 17.25 | 558.00 | 2 | 88 | 246 | 529 |
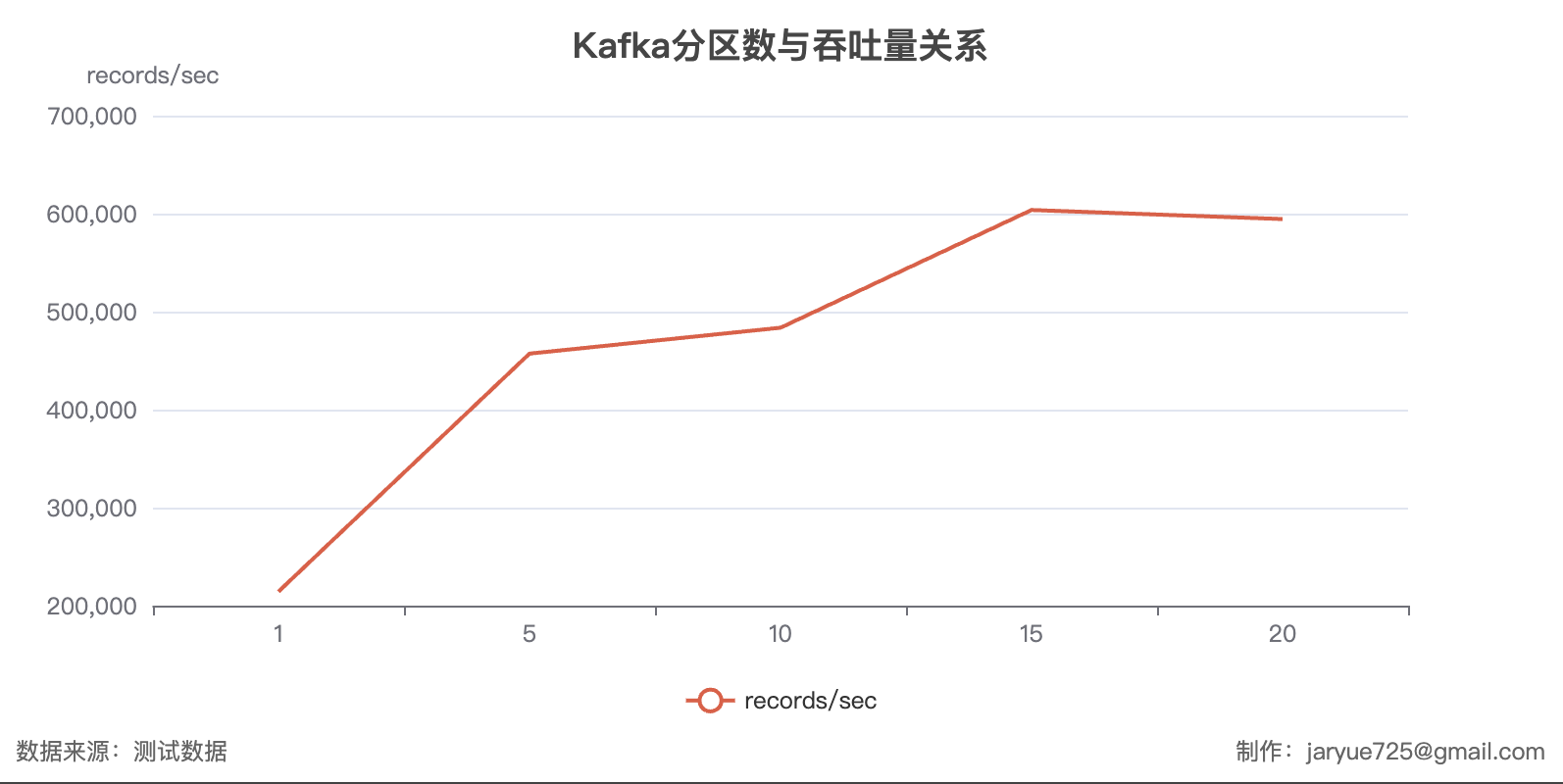
结论:
- 两个压测的数据差距非常大,可以说是背道而驰
- 因为分区的作用是改变多线程下的磁盘 IO;
- Kafka 每个分区都是一个单独的文件,单线程读写其实就是一个文件 IO 的效率,会有上下波动;但是并不大也就是一个文件的 IO 效率
- 但是在多线程情况下,IO 的效率将是每个文件的 IO 的总和(这一点可以很明显的体现在多线程读取 情况下,多分区的读取效率明显大幅提升
消费-线程数(15 分区)
sdk测试结果
| 消费者数量 | 每个线程消费数据 (条/5s) | 每秒消费的总条数 (条/s) | 吞吐量 (MB/s) |
|---|---|---|---|
| 1 | 7,931,777 | 1,586,355 | 119.9 |
| 3 | 4,221,217; 4,263,885; 4,130,602 | 2,523,141 | 190.6 |
| 6 | 2,738,983; 2,735,468; 2,630,453; 2,649,757; 2,739,442; 2,641,324 | 3,183,086 | 240.5 |
| 9 | 2,009,912; 1,968,823; 1,975,723; 1,965,374; 2,039,036; 1,968,965; 1,961,928; 1,899,827; 1,887,832 | 3,563,936 | 269.3 |
| 12 | 1,634,192; 1,623,847; 1,608,319; 1,705,832; 1,621,312; 1,696,289; 1,587,789; 1,634,192; 1,639,367; 1,666,854; 1,633,038; 1,672,544 | 3,950,318 | 298.5 |
| 15 | 1,832,556; 1,766,294; 1,810,132; 1,758,385; 1,791,158; 1,780,809; 1,784,259; 1,826,931; 1,800,389; 1,769,654; 1,791,158; 1,758,385; 1,813,582; 1,798,058; 1,785,984 | 5,337,870 | 403.3 |
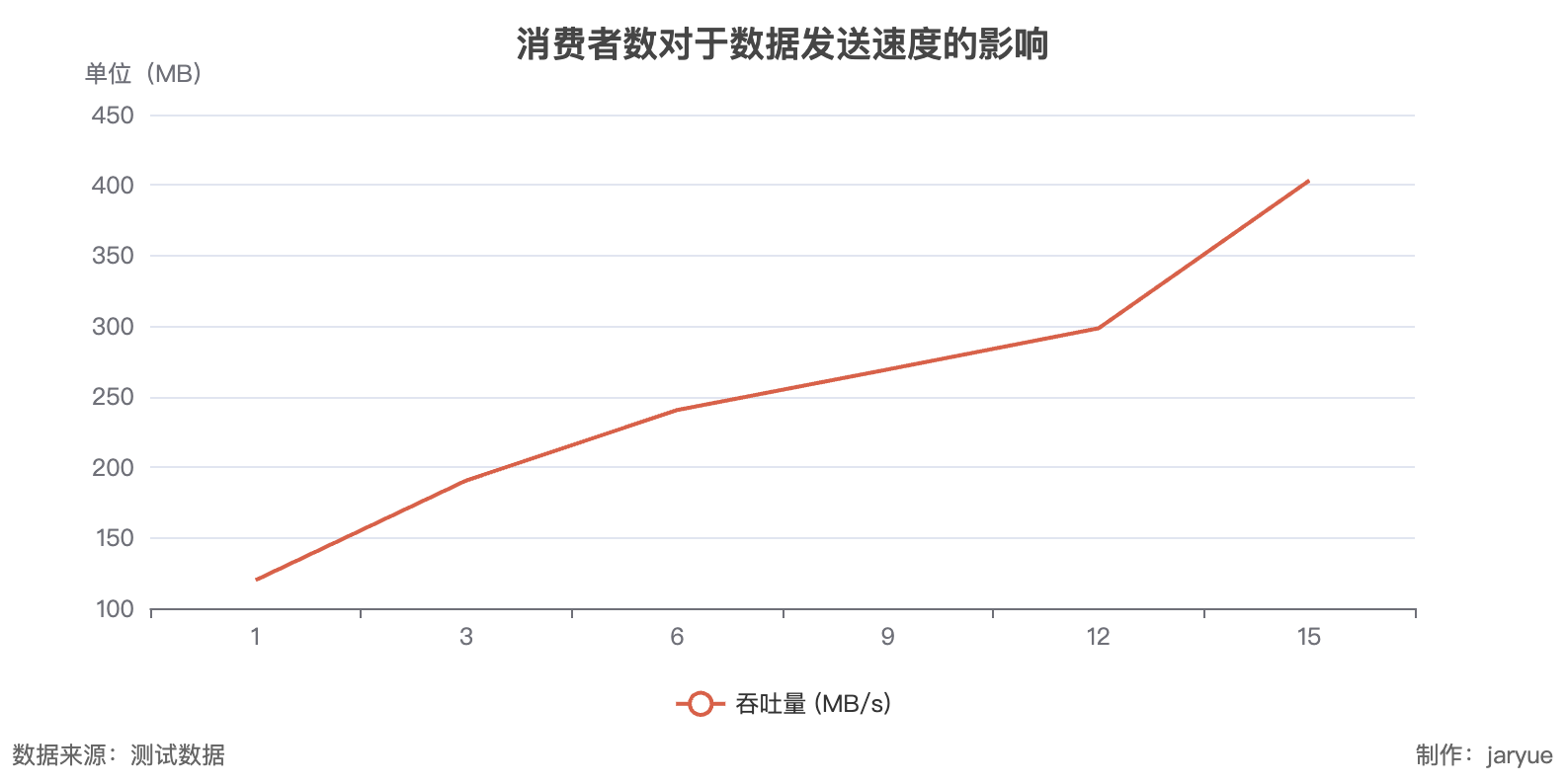
**结论: **
- 当 (消费者数量<=分区数量): 消费者越多,消费越快
- 当(消费者数量>分区数量): 消费者越多,消费速度影响不大
- 原因是一个分区只能同时被一个消费者持有(相同 groupId 情况下),当消费者数量>分区情况下,有的消费者将无法获取到分区,进而无法消费到消息,知道有消费者的分区释放,才会尝试获取分区
- **在在 15 分区,20 个消费者情况下压力测试: 有 5 个分区没有消费到一条消息
**
RocketMQ
生产
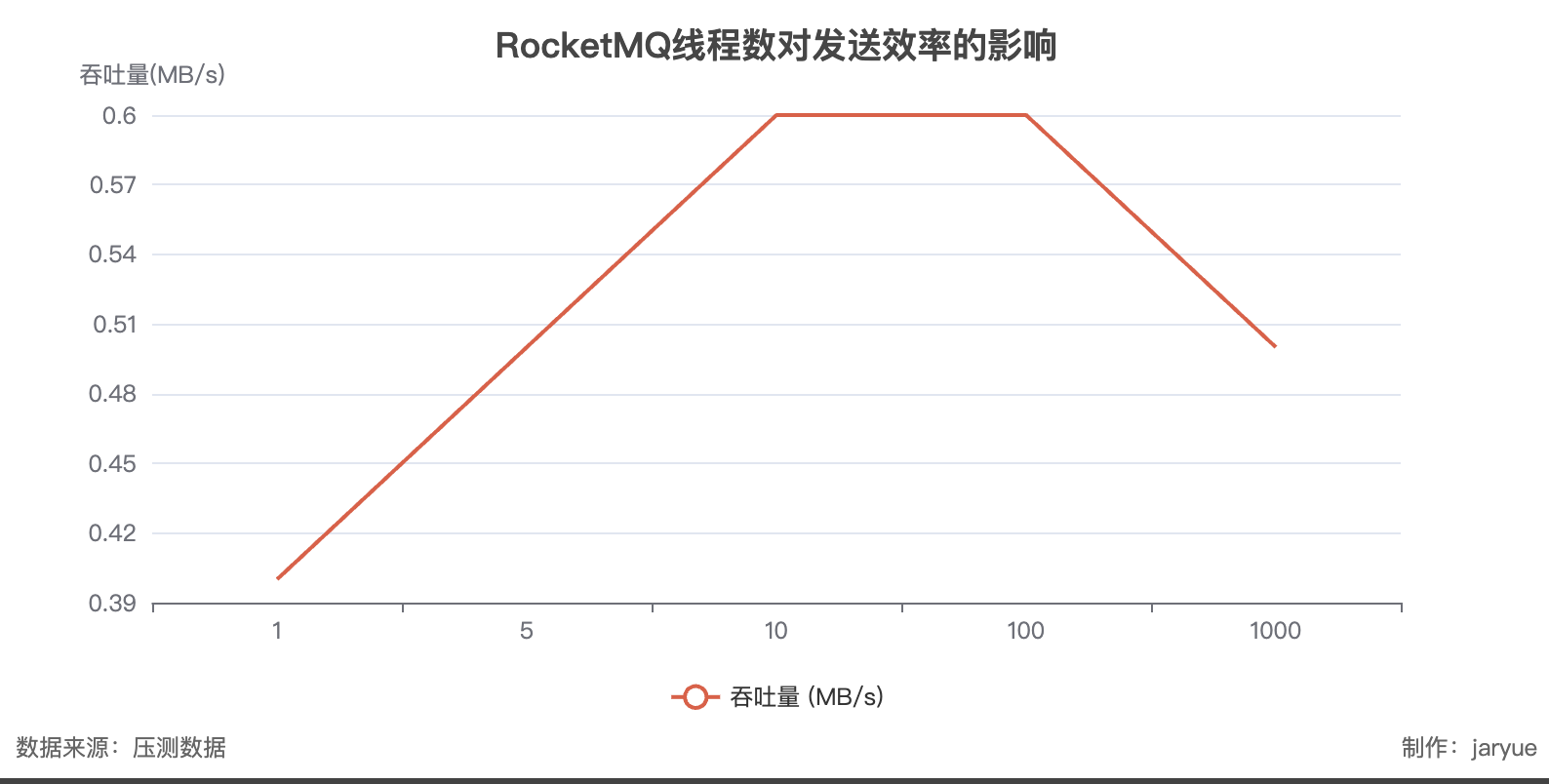
生产者数量
| 生产者线程数 | 吞吐量 (MB/s) | 折算消息量 (万条/s) |
|---|---|---|
| 1 | 0.4 | 4.0 |
| 5 | 0.5 | 5.0 |
| 10 | 0.6 | 6.0 |
| 100 | 0.6 | 6.0 |
| 1000 | 0.5 | 5.0 |
**
**
批量大小(batch-size)
| 批量大小(条) | 吞吐量 (MB/s) | 折算消息量(万条/s) |
|---|---|---|
| 10 | 0.5 | 5.0 |
| 500 | 5.0 | 50.0 |
| 1000 | 7.0 | 70.0 |
| 1500 | 8.6 | 86.0 |
| 2000 | 8.0 | 80.0 |
| 2500 | 9.0 | 90.0 |
| 3000 | 10.0 | 100.0 |
| 4000 | 10.3 | 103.0 |
| 5000 | 10.2 | 102.0 |
| 6000 | 10.6 | 106.0 |
| 10000 | 12.0 | 120.0 |
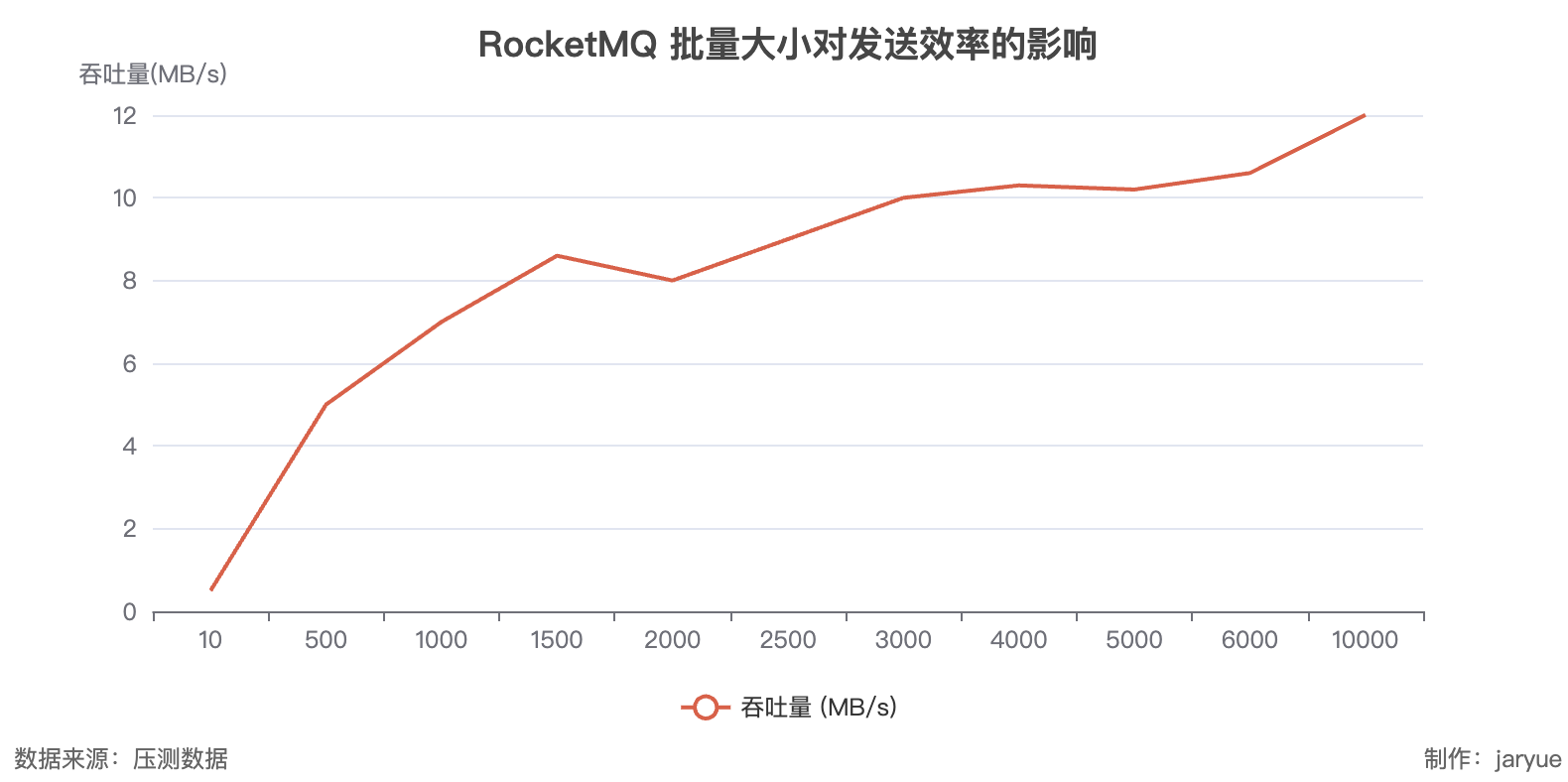
消费
消费者数量
| 消费者数量 | 各消费者消息数 (5秒) | 总消费量 (条) | 每秒总消费量 (条/s) | 吞吐量 (MB/s) |
|---|---|---|---|---|
| 1 | [206,712] | 206,712 | 41,342 | 1.97 |
| 2 | [92,960, 93,272] | 186,232 | 37,246 | 1.78 |
| 3 | [90,064, 45,784, 45,800] | 181,648 | 36,330 | 1.73 |
| 4 | [45,418, 45,480, 45,120, 44,968] | 180,986 | 36,197 | 1.73 |
| 5 | [35,304, 35,336, 34,920, 35,008, 0] | 140,568 | 28,114 | 1.34 |
| 10 | [42,840, 43,184, 42,880, 43,039, 0×6] | 171,943 | 34,389 | 1.64 |
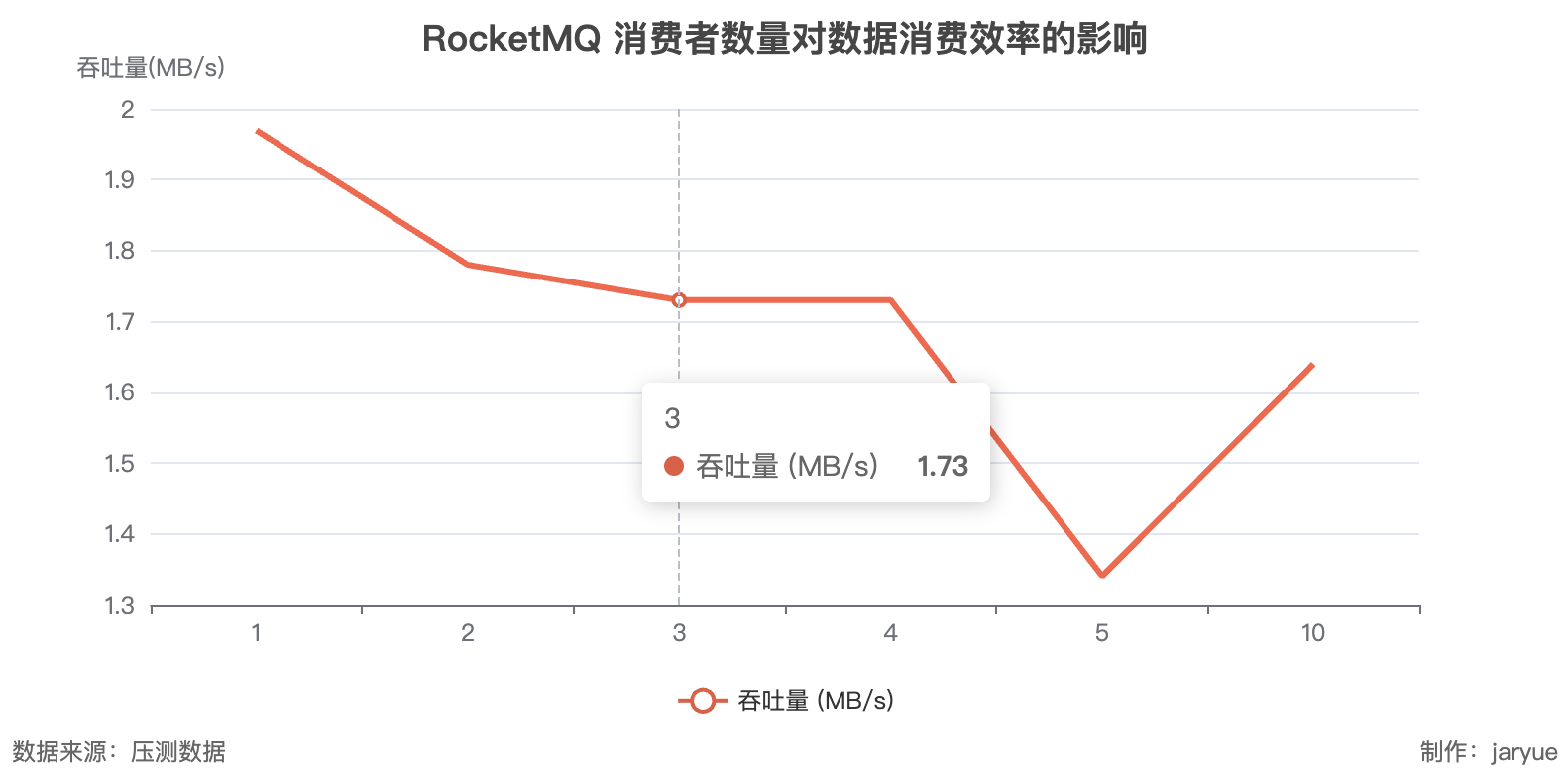
问题: 为什么消费者越多,性能月底?
按照 Kafka 的压测数据来讲,生产者与消费者数量越高,效率应该增加(在数量<分区数时)
其他配置
RocketMQ
生产者类型
- sync:同步发送;阻塞等待发送结果;
- async:异步发送;不会阻塞等待发送结果;
消费者类型:
- push: 监听的形式,监听 broker 的消息
- pull: 接口调用的形式,从通过调用接口的方式获取 broker 消息
消息的类型:
- 普通消息:
特点: 不保证顺序,性能最高
- 顺序消息(FIFO): 消息保证顺序消费
- 延时(delay):延时消息(只有到延时时间才可以消费)
- 事务:两阶段提交,开始是半提交状态,可以进行 rollback 与 commit 操作
kafka
生产者类型
- sync:同步发送;阻塞等待发送结果;
- async:异步发送;不会阻塞等待发送结果;
高可用
参考:https://rocketmq-learning.com/faq/ons-user-question-history16752/
RocketMQ 的高可用主要分为两个方面:
- 数据的冗余: RocketMQmaster 可以配置 selve 节点,冗余数据,保证数据不丢失;当 master 故障,selve 节点会接替成为新的 master 进行工作
- leader 节点选举: 当 RocketMQ 的中心节点(leader)宕机,其他节点会进行选举(raft 算法);选择出新的 leader 节点;保证服务的正常运行
消息队列幂等
消息队列的幂等主要分为两个阶段
- 消息队列的幂等:
- 避免发送方的重试导致出现多条消息,确保消息队列同一条消息
- 一般会使用全局唯一的 id 对消息进行去重,确保不会出现相同的消息
- 消费者(客户端)的幂等
- 避免消费者超时重试导致的重复消费问题
- 每条消息都回有全局唯一 id,每次消费都回先检查消息是否消费过了
case:
订单问题:
每一笔订单都回有一个全局唯一的订单 id; 每次消费都回检查是否消费过
参考
https://kafka.apache.org/documentation/#introduction
https://rocketmq.apache.org/zh/docs/featureBehavior/01normalmessage
https://blog.csdn.net/m0_71513446/article/details/143386962
https://rocketmq-learning.com/faq/ons-user-question-history16752/
若有收获,就点个赞吧