下城区做网站营销平台有哪些
LORA 微调 LoRA 介绍与 LoRA 微调指南
LoRA微调的基本概念
LoRA(Low-Rank Adaptation)是一种用于微调大型预训练模型的技术,特别适用于自然语言处理任务。它通过在预训练模型的权重矩阵中引入低秩矩阵来减少参数量,从而在保持模型性能的同时降低计算成本。在这里插入图片描述
LoRA微调的步骤
- 选择预训练模型:选择一个适合任务的预训练模型,如BERT、GPT等。
- 定义低秩矩阵:在预训练模型的权重矩阵中引入低秩矩阵,这些矩阵的参数数量远小于原始权重矩阵。
- 冻结原始权重:在微调过程中,冻结预训练模型的原始权重,只更新低秩矩阵的参数。
- 训练低秩矩阵:使用任务特定的数据集对低秩矩阵进行训练,使其适应特定任务。
- 评估模型性能:在验证集上评估微调后的模型性能,确保其在目标任务上的表现。
总的来说LoRA是一种高效的大模型微调技术,由微软团队提出。它的核心思想是冻结预训练模型的大部分参数,仅通过低秩矩阵(Low-Rank Matrices)微调少量参数,从而大幅减少计算和存储开销。
LoRA 的优势:
• ✅ 计算高效:仅微调少量参数(通常 <1%),比全参数微调(Full Fine-Tuning)快得多。
• ✅ 内存友好:不需要存储完整的梯度,适合资源受限的环境(如 Colab)。
• ✅ 可插拔:训练后的 LoRA 权重可以独立保存,并应用到不同的任务上。
- 缓解过拟合
传统全参数微调(Full Fine-Tuning)在小数据集上容易过拟合,而 LoRA 仅调整少量参数(如 0.1%~1%),能更好地保留预训练知识,提升泛化性。- 适用场景:数据量少、任务与预训练差异较大时(如领域适配)。
- 稳定训练
冻结大部分参数可避免梯度爆炸/消失问题,尤其对大模型(如 LLaMA、GPT-3)更友好。 - 任务适配灵活性
通过调整rank和alpha,可平衡新任务学习与原始知识保留:- 高
rank(如 64)增强任务适配能力,但可能破坏预训练特征; - 低
rank(如 4)更适合数据相似性高的任务。
- 高
⚠️** 局限性**
- 理论性能上限
LoRA 的参数量远小于全参数微调,在复杂任务(如需要多模态推理)或大数据场景下,效果可能不如全参数微调。 - 依赖初始模型
若预训练模型本身能力不足(如小规模模型),LoRA 无法显著提升效果。
2. LoRA 的工作原理

3. 如何在任务中使用 LoRA 微调?
以 Hugging Face Transformers 为例,介绍如何使用 LoRA 微调模型(如 BERT、GPT-2、LLaMA)。
方法 1:使用 peft 库(推荐)
peft(Parameter-Efficient Fine-Tuning)是 Hugging Face 提供的 LoRA 实现库。
安装:
pip install peft transformers torch
示例代码(微调 GPT-2):
from transformers import GPT2LMHeadModel, GPT2Tokenizer, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model
import torch# 1. 加载模型和 tokenizer
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")# 2. 配置 LoRA
lora_config = LoraConfig(r=8, # LoRA 秩(rank)lora_alpha=32, # 缩放因子(alpha)target_modules=["c_attn"], # 目标模块(GPT-2 的注意力层)lora_dropout=0.1, # Dropoutbias="none", # 是否微调偏置
)# 3. 应用 LoRA
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 查看可训练参数(应该很少)# 4. 训练(使用 Trainer)
training_args = TrainingArguments(output_dir="./output",per_device_train_batch_size=4,num_train_epochs=3,save_steps=500,logging_steps=100,
)trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset, # 替换为你的数据集
)trainer.train()
4. LoRA 适用场景
• 大语言模型(LLM)微调(如 LLaMA、GPT-3)
• 扩散模型(Diffusion)微调(如 Stable Diffusion)
• 低资源训练(单卡 GPU 微调 7B+ 模型)
5. 进阶技巧
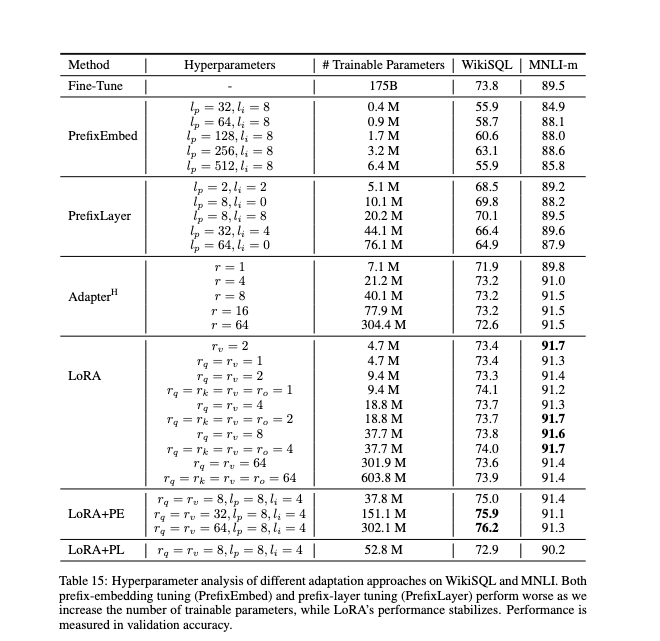
• 调整 rank:rank 越大,微调能力越强,但计算量也增加(通常 4~64)。
• 选择 target_modules:不同模型的关键层不同:
• GPT/LLaMA:q_proj, v_proj, c_attn
• BERT:query, value
• 结合量化(QLoRA):进一步降低显存占用(适用于 24GB 以下 GPU)。
6. 参考资源
• 论文:LoRA: Low-Rank Adaptation of Large Language Models
• peft 官方文档:https://huggingface.co/docs/peft/
• Colab 示例:Fine-tune LLaMA with LoRA