海量数据处理
1.海量数据处理问题
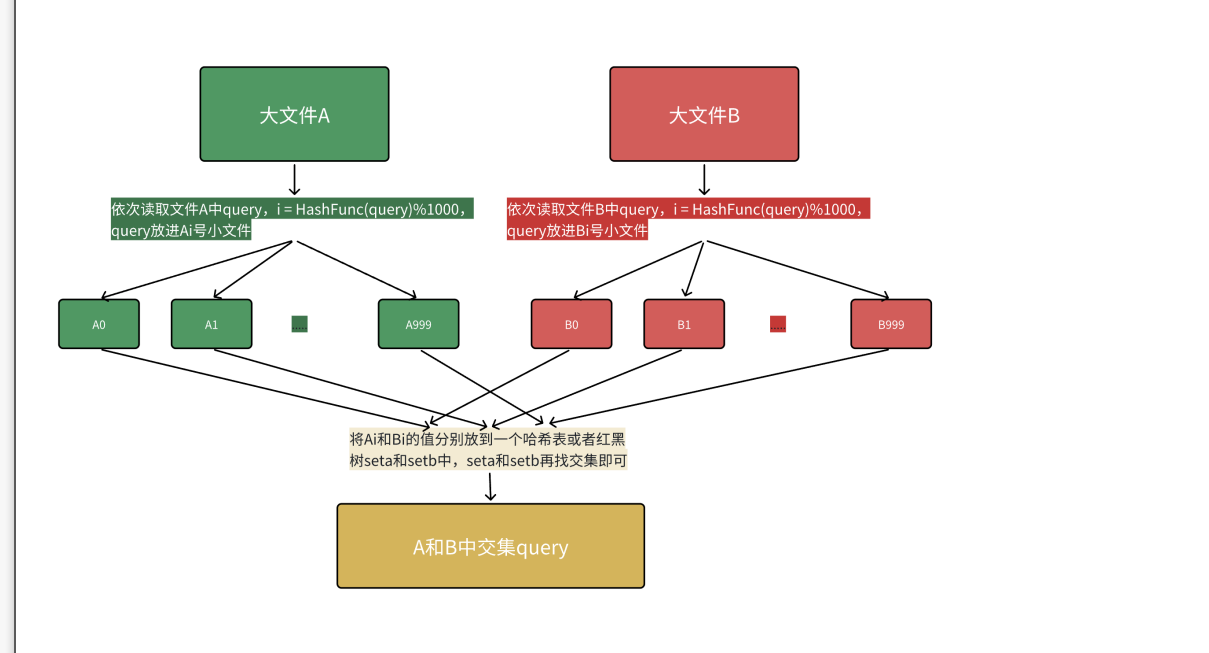
给两个文件,分别有100亿个query,只有1G内存,如何找到两个文件交集?
解决方案一:
可以先用布隆过滤器,一个文件的query放进布隆过滤器,另一个文件依次查找,在的就是交集,但存在缺陷,因为存在的值可能是误判的,也就是说交集不一定准确。
解决方案二:
哈希切分,首先内存的访问速度远大于硬盘,大文件放到内存搞不定,就可以切分为小文件,再放进内存处理。但不是平均切分,因为平均切分就需要双重循环遍历,低效率。可以使用哈希切分,依次读取⽂件中query,i = HashFunc(query)%N,N为准备切分多少分⼩⽂ 件,N取决于切成多少份,内存能放下,query放进第i号小文件,这样A和B中相同的query算出的hash值是一样的,相同的query就进入编号相同的文件直接找交集,不用交叉找,效率就提升了。
本质就是相同的query在哈希切分过程中,一定进入的同一个小文件Ai和Bi,不可能出现A中的query进入Ai,就可以对应Ai和Bi进行求交集,一一对应的,从n^2变成n。
哈希切分的问题就是每个小文件不是均匀的,可能会导致某个文件要存储很多数据存不下。会出现两种情况:1.这个小文件中大部分是同一个query。2.这个小文件是有很多的不同的query构成,本质是这些的query冲突了。针对情况一set是可以放得下的,因为set可以去重。对于2,就可以用别的哈希函数进行二次切分。遇到大于1G文件,继续放到set找交集,如果set抛出异常就说明是内存放不下,换个哈希函数进行二次切分再对应找交集。
2.给一个超过100G大小的log file。log中存着ip地址,设计算法找到出现次数最多的ip地址,查找出出现次数前十的ip地址
本题的思路跟上题完全类似,依次读取⽂件A中query,i = HashFunc(query)%500,query放进Ai号⼩ ⽂件,然后依次⽤map<string, int>对每个Ai⼩⽂件统计ip次数,同时求出现次数最多的ip或者topk ip。本质是相同的ip在哈希切分过程中,⼀定进⼊的同⼀个⼩⽂件Ai,不可能出现同⼀个ip进⼊Ai和Aj 的情况,所以对Ai进⾏统计次数就是准确的ip次数。(每个小文件都可以得到一个最大数,然后建成一个大堆出来,去堆顶的数据就是最多数)
