深度学习论文: Transformers without Normalization
深度学习论文: Transformers without Normalization
Transformers without Normalization
PDF: https://arxiv.org/abs/2503.10622v1
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
归一化层在现代神经网络中广泛应用且长期被视为不可或缺的组件。本研究突破性地证明,通过一种极为简洁的技术,无需归一化层的 Transformer 模型即可达到甚至超越传统架构的性能。本文提出动态双曲正切模块 DyT(Dynamic Tanh),其逐元素操作定义为 DyT (x) = tanh (αx),可直接替代 Transformer 中的归一化层。这一设计源于对 Transformer 中 LayerNorm 层普遍呈现类 tanh 型 S 曲线输入输出映射的观察。
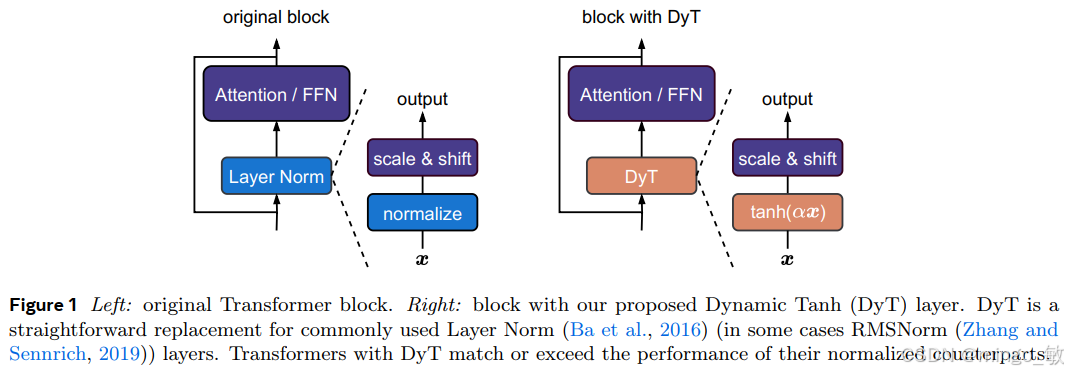
实验表明,嵌入 DyT 的非归一化 Transformer 模型在大多数任务中无需复杂超参数调整,即可达到或超越传统归一化模型的性能。本文在从识别到生成、监督学习到自监督学习、计算机视觉到语言模型的多领域场景中验证了该方案的有效性。这些发现不仅挑战了归一化层在现代神经网络中不可替代的传统认知,更为深入理解深度网络中归一化机制的本质作用提供了新视角。
2 Dynamic Tanh (DyT)
研究团队首次通过实证方法系统分析了深度神经网络中归一化层的行为特征。针对视觉 Transformer(ViT)、语音模型 wav2vec 2.0 和扩散模型 DiT 这三种典型网络架构,研究人员通过前向传播实验获取了各 LayerNorm 层在仿射变换前的输入输出数据,并建立了元素级的对应关系可视化分析框架。
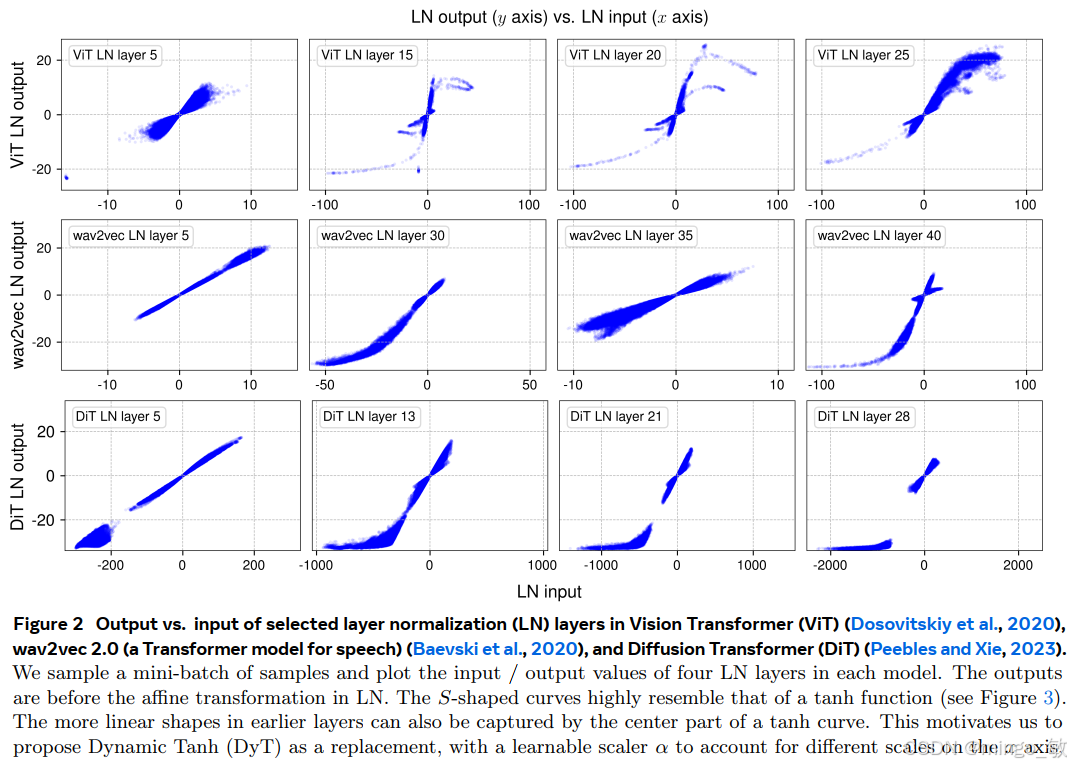
研究发现传统认知中的线性变换特性与实际观测结果存在显著差异:LayerNorm 在整体映射关系上呈现出与双曲正切函数(tanh)高度相似的非线性特征。基于这一重要发现,团队创新性地提出了动态变换层 DyT 作为归一化层的替代方案。该模块的数学定义为:
D y T ( x ) = γ ∗ t a n h ( α x ) + β DyT (x) = γ * tanh(αx) + β DyT(x)=γ∗tanh(αx)+β
其中 α 为可学习标量参数,用于输入信号的尺度调整;γ 和 β 为逐通道可学习向量参数,实现输出信号的任意尺度缩放。
class DyT(nn.Module):
def __init__(self, num_features, alpha_init_value=0.5):
super().__init__()
self.alpha = nn.Parameter(torch.ones(1) * alpha_init_value)
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
def forward(self, x):
x = torch.tanh(self.alpha * x)
return x * self.weight + self.bias
DyT 模块可无缝嵌入注意力块、前馈网络块及最终归一化层等结构。值得注意的是,尽管该模块引入了非线性激活机制,但实验表明,该模块在保持原有架构激活函数和其他组件不变的情况下,无需对原始超参数进行显著调整即可获得理想性能。这种设计特性使得 DyT 在保持模型架构稳定性的同时,为提升模型表达能力提供了新的技术路径。
3 Experiments
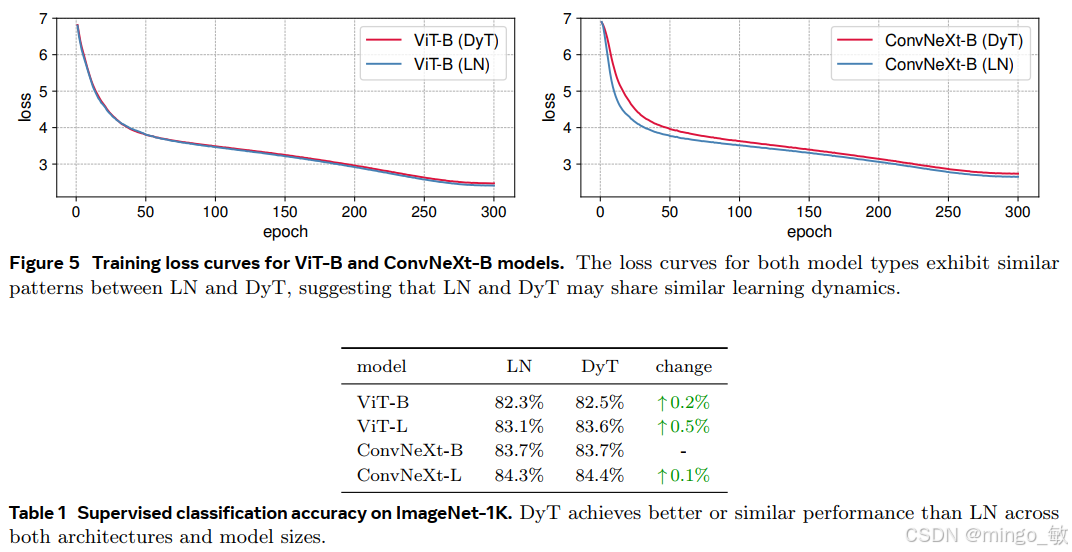
Supervised learning in vision
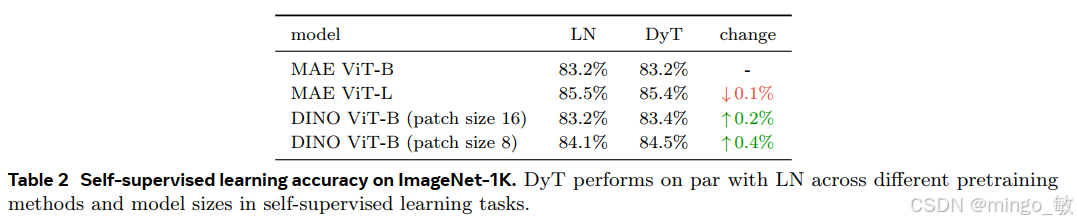
Self-supervised learning in vision
Diffusion models

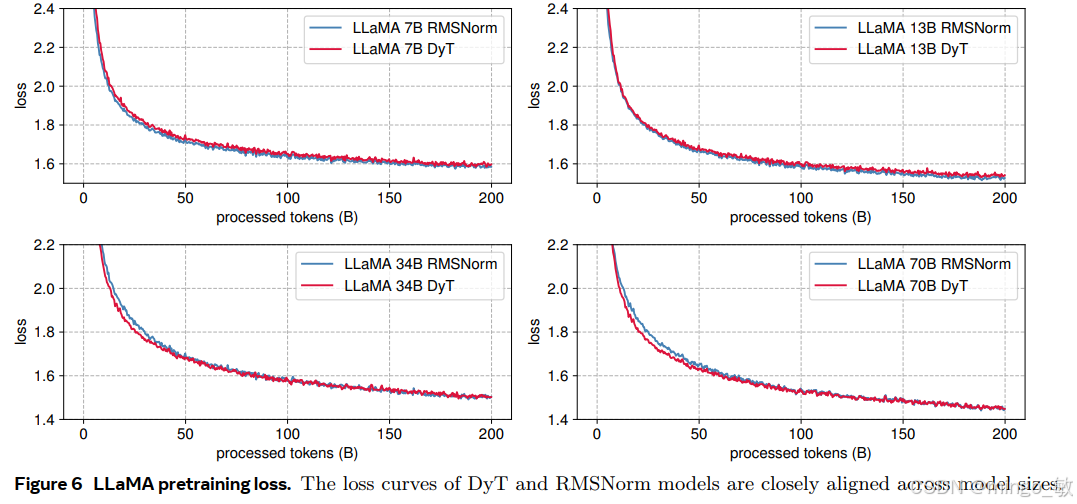
Large Language Models

Self-supervised learning in speech

DNA sequence modeling
