P3379 【模板】最近公共祖先(LCA)【题解】(重链剖分法)
本文讲解重链剖分法求 LCA
关于Tarjan法:P3379 【模板】最近公共祖先(LCA)【题解】(Tarjan法)
关于倍增法:P3379 【模板】最近公共祖先(LCA)【题解】(倍增法)
P3379 【模板】最近公共祖先(LCA)
题目描述
如题,给定一棵有根多叉树,请求出指定两个点直接最近的公共祖先。
输入格式
第一行包含三个正整数 N , M , S N,M,S N,M,S,分别表示树的结点个数、询问的个数和树根结点的序号。
接下来 N − 1 N-1 N−1 行每行包含两个正整数 x , y x, y x,y,表示 x x x 结点和 y y y 结点之间有一条直接连接的边(数据保证可以构成树)。
接下来 M M M 行每行包含两个正整数 a , b a, b a,b,表示询问 a a a 结点和 b b b 结点的最近公共祖先。
输出格式
输出包含 M M M 行,每行包含一个正整数,依次为每一个询问的结果。
输入输出样例 #1
输入 #1
5 5 4
3 1
2 4
5 1
1 4
2 4
3 2
3 5
1 2
4 5
输出 #1
4
4
1
4
4
说明/提示
对于 30 % 30\% 30% 的数据, N ≤ 10 N\leq 10 N≤10, M ≤ 10 M\leq 10 M≤10。
对于 70 % 70\% 70% 的数据, N ≤ 10000 N\leq 10000 N≤10000, M ≤ 10000 M\leq 10000 M≤10000。
对于 100 % 100\% 100% 的数据, 1 ≤ N , M ≤ 500000 1 \leq N,M\leq 500000 1≤N,M≤500000, 1 ≤ x , y , a , b ≤ N 1 \leq x, y,a ,b \leq N 1≤x,y,a,b≤N,不保证 a ≠ b a \neq b a=b。
样例说明:
该树结构如下:
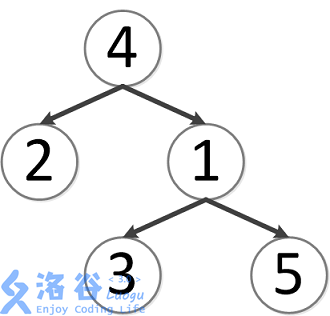
第一次询问: 2 , 4 2, 4 2,4 的最近公共祖先,故为 4 4 4。
第二次询问: 3 , 2 3, 2 3,2 的最近公共祖先,故为 4 4 4。
第三次询问: 3 , 5 3, 5 3,5 的最近公共祖先,故为 1 1 1。
第四次询问: 1 , 2 1, 2 1,2 的最近公共祖先,故为 4 4 4。
第五次询问: 4 , 5 4, 5 4,5 的最近公共祖先,故为 4 4 4。
故输出依次为 4 , 4 , 1 , 4 , 4 4, 4, 1, 4, 4 4,4,1,4,4。
2021/10/4 数据更新 @fstqwq:应要求加了两组数据卡掉了暴力跳。
解析:
1.有关LCA
👉详见P3379 【模板】最近公共祖先(LCA)【题解】(Tarjan法)
2.有关重链剖分
👉详见P3384 【模板】重链剖分/树链剖分
其实这题里面有部分与
L
C
A
LCA
LCA 的重链剖分求法相似
3.思路
用暴力算法时,我们使
u
,
v
u,v
u,v均一个深度一个深度的上升,导致了效率低下。
而观察重链剖分算法,每次上升时可以上升大量的深度,效率大大提高了。
于是就将 L C A LCA LCA 与重链剖分结合。具体用法见下👇:
对于两点,选择所在位置的重链顶端深度较小的那个点,上升到所在位置的重链顶端的父亲。
再选择所在位置的重链顶端深度较小的那个点,上升到所在位置的重链顶端的父亲。
……(我们都知道每个重链顶端的父亲都在其它重链上,这就使两点最终一定能到达同个重链上)
(至于为啥选择所在位置的重链顶端深度较小的那个点操作,是因为两个点若不在同个重链上,就至少有一个点的的重链顶端深度小于
L
C
A
LCA
LCA ,即不可能两个点的的重链顶端深度都小于
L
C
A
LCA
LCA,因为
L
C
A
LCA
LCA 点延伸下来就只有一条重链,绝不会有两条重链。而我们跳点不能跳到深度比
L
C
A
LCA
LCA 还小的点)
如此循环,直到两点在同条重链上为止。两者中深度较小的即为最小公共祖先了。
4.代码
#include<bits/stdc++.h>
using namespace std;
const int MAXN=1000005;
int n,m,s;
struct EDGE{
int to,nxt;
}edge[MAXN];
int head[MAXN];
int tot;
void add(int u,int v){
tot++;
edge[tot].nxt=head[u];
edge[tot].to=v;
head[u]=tot;
}
struct tree{
int wc,size,d,fa,top;
}p[MAXN];
void dfs1(int u,int fa){
p[u].d=p[fa].d+1;p[u].fa=fa;p[u].size=1;
for(int i=head[u];i;i=edge[i].nxt){
int v=edge[i].to;
if(v==fa) continue;
dfs1(v,u);
p[u].size+=p[v].size;
if(p[v].size>p[p[u].wc].size) p[u].wc=v;
}
}
void dfs2(int u,int Top){
p[u].top=Top;
if(p[u].wc!=0){
dfs2(p[u].wc,Top);
for(int i=head[u];i;i=edge[i].nxt){
int v=edge[i].to;
if(v==p[u].fa||v==p[u].wc) continue;
dfs2(v,v);
}
}
}
int find(int x,int y){
while(p[x].top!=p[y].top){//两点所在链不相同
if(p[p[x].top].d<p[p[y].top].d) swap(x,y);//保持x点更深
x=p[p[x].top].fa;//到所在链顶端的父亲
}
return p[x].d>p[y].d?y:x;//此时x,y在同条链上了,只需返回两者中深度较小的
}
int main(){
int ui,vi;
cin>>n>>m>>s;
/*建树部分*/
for(int i=1;i<n;i++){
cin>>ui>>vi;
add(ui,vi);
add(vi,ui);
}
/*重链剖分部分*/
dfs1(s,0);
dfs2(s,s);
/*查询部分*/
for(int i=1;i<=m;i++){
cin>>ui>>vi;
cout<<find(ui,vi)<<endl;
}
return 0;
}