【强化学习】DAPO 论文解读
DAPO: 开源大规模LLM强化学习系统
- 论文: https://arxiv.org/abs/2503.14476 (2025.03.17)
- Project: https://dapo-sia.github.io/
- 代码: https://github.com/volcengine/verl
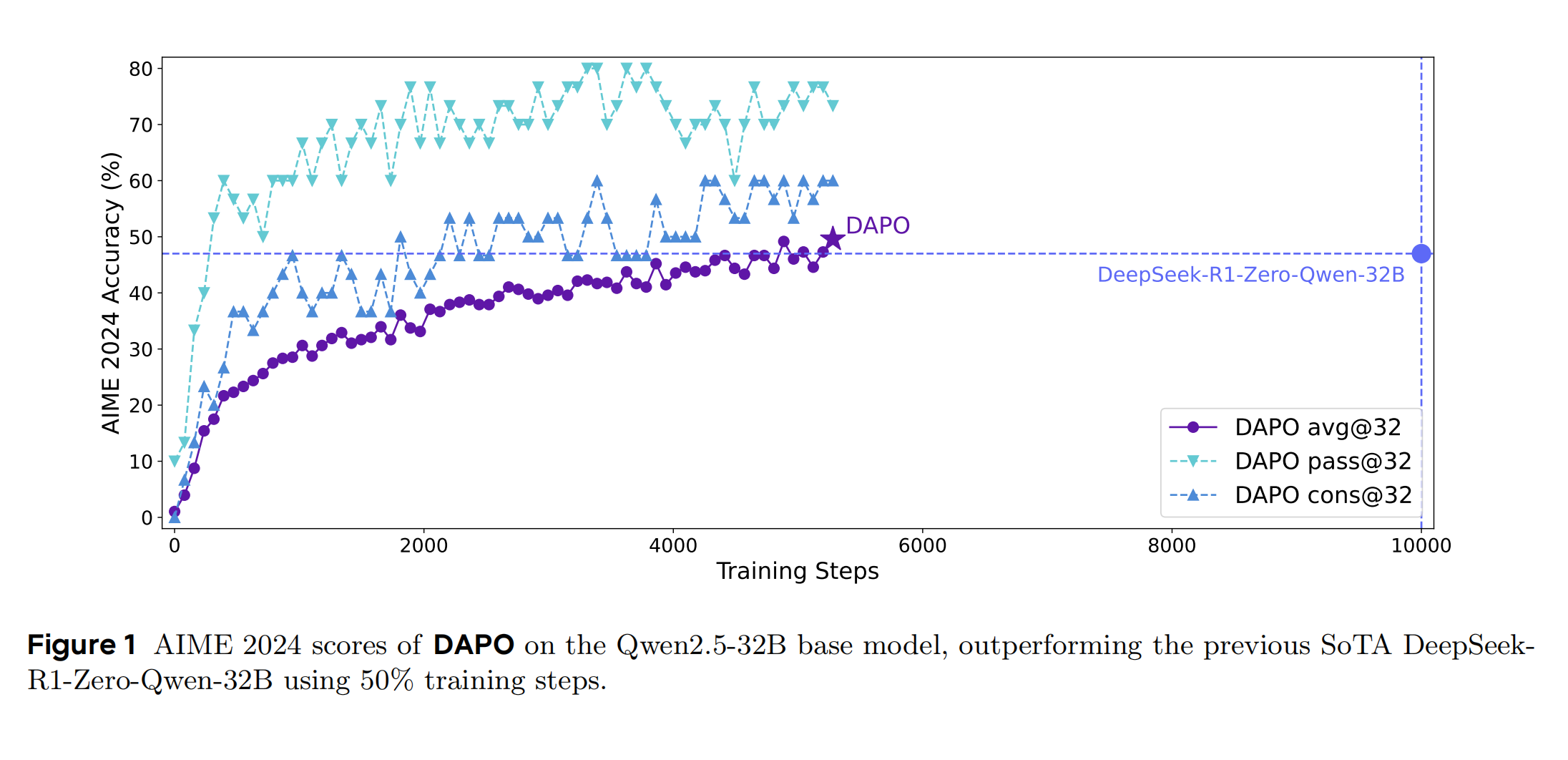
之前总结了"近端策略优化(PPO) " 和 “近端策略优化(PPO)” ,最近字节联合清华最近发表了新的强化学习算法:《动态奖励策略优化(DAPO)》。DAPO在PPO和GRPO的技术上做了诸多改进,并开源完整系统,在Qwen2.5-32B模型上实现AIME 2024的50分成绩(超越DeepSeek-R1-Zero-Qwen-32B的47分)。
文章目录
- DAPO: 开源大规模LLM强化学习系统
- @[toc]
- 1. 引言
- 1.1 研究背景与挑战
- 1.2 核心贡献
- 2. 初步知识
- 2.1 近端策略优化(PPO)
- 2.2 群组相对策略优化(GRPO)
- ✨ 创新1:无Critic架构(解决显存问题)
- ✨ 创新2:相对优势估计(解决偏差问题)
- ✨ 创新3:双重约束机制(优化策略更新)
- 3. DAPO算法
- 3.1 核心技术创新
- 3.1.1 ✨ 改进1:解耦剪裁范围: Clip-Higher策略
- 3.1.2 ✨ 改进2:动态采样(过滤无效样本)
- 3.1.3 ✨ 改进3:Token级损失(重视细节)
- 3.1.4 ✨ 改进4:超长奖励塑形(控制答案长度)
- 3.2 算法流程
- 4. 实验与结果
- 4.1 主要结果
- 4.2 训练动态分析
- 4.3 案例研究
- 5. 结论与未来方向
- 5.1 贡献总结
- 5.2 未来方向
文章目录
- DAPO: 开源大规模LLM强化学习系统
- @[toc]
- 1. 引言
- 1.1 研究背景与挑战
- 1.2 核心贡献
- 2. 初步知识
- 2.1 近端策略优化(PPO)
- 2.2 群组相对策略优化(GRPO)
- ✨ 创新1:无Critic架构(解决显存问题)
- ✨ 创新2:相对优势估计(解决偏差问题)
- ✨ 创新3:双重约束机制(优化策略更新)
- 3. DAPO算法
- 3.1 核心技术创新
- 3.1.1 ✨ 改进1:解耦剪裁范围: Clip-Higher策略
- 3.1.2 ✨ 改进2:动态采样(过滤无效样本)
- 3.1.3 ✨ 改进3:Token级损失(重视细节)
- 3.1.4 ✨ 改进4:超长奖励塑形(控制答案长度)
- 3.2 算法流程
- 4. 实验与结果
- 4.1 主要结果
- 4.2 训练动态分析
- 4.3 案例研究
- 5. 结论与未来方向
- 5.1 贡献总结
- 5.2 未来方向
1. 引言
1.1 研究背景与挑战
近年来,LLM在数学推理领域取得显著进展(如DeepSeekMath的MATH基准51.7%准确率),但闭源模型(如GPT-4、Gemini)的关键技术细节未公开,导致开源社区难以复现其强化学习(RL)效果。于是提出了**Decoupled Clip and Dynamic sAmpling Policy Optimization(DAPO)**算法,旨在解决大规模RL训练的关键挑战,。
1.2 核心贡献
- 算法创新:提出DAPO算法,包含4项关键技术(Clip-Higher、动态采样、Token级策略梯度损失、超长奖励塑形),解决传统RL的熵坍塌、奖励噪声等问题。
- 系统开源:基于verl框架的训练代码、精心处理的数据集,提升行业级RL的可复现性。
- 性能突破:在AIME 2024基准上达到50分,仅用DeepSeek-R1-Zero训练步数的50%。
2. 初步知识
2.1 近端策略优化(PPO)
传统PPO通过限制策略更新步长平衡探索与利用,其目标函数为:
J
PPO
(
θ
)
=
E
[
min
(
π
θ
π
old
A
t
,
clip
(
⋅
)
⋅
A
t
)
]
\mathcal{J}_{\text{PPO}}(\theta) = \mathbb{E}\left[ \min\left( \frac{\pi_{\theta}}{\pi_{\text{old}}} A_t, \text{clip}(\cdot) \cdot A_t \right) \right]
JPPO(θ)=E[min(πoldπθAt,clip(⋅)⋅At)]
上面的公式看起来不好理解。我们可以简化成:
L P P O = min ( 新策略 旧策略 ⋅ 优势 , 截断后 ⋅ 优势 ) \mathcal{L}^{PPO} = \min\left( \frac{\text{新策略}}{\text{旧策略}} \cdot \text{优势}, \text{截断后} \cdot \text{优势} \right) LPPO=min(旧策略新策略⋅优势,截断后⋅优势)
其中:
优势
=
奖励
−
基准分
(绝对优势)
\text{优势} = \text{奖励} - \text{基准分} \quad \text{(绝对优势)}
优势=奖励−基准分(绝对优势)
通俗比喻 **老师(价值模型)**用历史平均分(基准分)评估学生进步。同时,进步超过20%的部分不计入奖励,退步超过20%的部分不惩罚。但是,老师可能打错基准分(价值网络不准),导致评估偏差。
2.2 群组相对策略优化(GRPO)
GRPO通过组内奖励标准化省去价值函数,优势计算为:
A
^
i
,
t
=
r
i
−
mean
(
r
)
std
(
r
)
\hat{A}_{i,t} = \frac{r_i - \text{mean}(r)}{\text{std}(r)}
A^i,t=std(r)ri−mean(r)
目标函数引入KL散度正则化:
J
GRPO
(
θ
)
=
E
[
1
G
∑
i
∑
t
(
clip
(
⋅
)
⋅
A
^
i
,
t
−
β
D
KL
)
]
\mathcal{J}_{\text{GRPO}}(\theta) = \mathbb{E}\left[ \frac{1}{G} \sum_i \sum_t \left( \text{clip}(\cdot) \cdot \hat{A}_{i,t} - \beta \mathcal{D}_{\text{KL}} \right) \right]
JGRPO(θ)=E[G1i∑t∑(clip(⋅)⋅A^i,t−βDKL)]
同样我们可以转化为下面几个可以通俗理解的部分。
✨ 创新1:无Critic架构(解决显存问题)
主要是去掉价值网络,用群体采样直接计算相对优势,对每个状态采样G个动作(群体),计算组内归一化奖励。显存节省30%+(仅需维护Actor网络):
A
^
t
=
单个动作奖励
−
组内平均奖励
组内奖励标准差
+
ϵ
(自动归零中心化和归一化)
\hat{A}_t = \frac{\text{单个动作奖励} - \text{组内平均奖励}}{\text{组内奖励标准差} + \epsilon} \quad \text{(自动归零中心化和归一化)}
A^t=组内奖励标准差+ϵ单个动作奖励−组内平均奖励(自动归零中心化和归一化)
✨ 创新2:相对优势估计(解决偏差问题)
PPO用绝对优势(依赖价值网络),GRPO用相对优势(组内竞争),把专家打分改成组内内卷:
组内平均奖励
=
1
G
∑
奖励
,
组内标准差
=
1
G
∑
(
奖励
−
平均
)
2
\text{组内平均奖励} = \frac{1}{G}\sum \text{奖励}, \quad \text{组内标准差} = \sqrt{\frac{1}{G}\sum (\text{奖励}-\text{平均})^2}
组内平均奖励=G1∑奖励,组内标准差=G1∑(奖励−平均)2
✨ 创新3:双重约束机制(优化策略更新)
PPO的单一截断 → GRPO的双重约束。柔性控制策略更新(局部+全局约束):
- 截断约束(Clipping):限制单步策略更新幅度(同PPO)
- KL散度惩罚:显式约束新旧策略分布差异(避免整体剧烈变化)
对应公式:
L
G
R
P
O
=
min
(
截断项
,
原始项
)
−
β
⋅
KL
(
旧策略
∣
∣
新策略
)
\mathcal{L}^{GRPO} = \min(\text{截断项}, \text{原始项}) - \beta \cdot \text{KL}(旧策略||新策略)
LGRPO=min(截断项,原始项)−β⋅KL(旧策略∣∣新策略)
通俗比喻:班级考试,每个学生的进步看班级排名(自动抵消试卷难度差异)。老师操作:不允许单题进步/退步超过20%(截断),全班整体成绩不能波动太大(KL散度惩罚)。优点:无需老师打分,避免基准偏差。
对比 PPO vs GRPO:
| 组件 | PPO | GRPO |
|---|---|---|
| 基准 | 老师评分(价值网络) | 班级排名(群体采样) |
| 优势 | 绝对优势(奖励-基准) | 相对优势(排名归一化) |
| 约束 | 单一截断约束 | 截断 + KL散度双重约束 |
| 网络 | Actor + Critic(双网络) | 仅Actor(群体采样) |
3. DAPO算法
3.1 核心技术创新
3.1.1 ✨ 改进1:解耦剪裁范围: Clip-Higher策略
传统PPO的剪裁范围限制低概率token的探索空间。DAPO提出解耦剪裁范围:允许低概率token进步更多,高概率token退步限制更严:
J D A P O ( θ ) = E [ min ( r i , t A ^ i , t , clip ( r i , t , 1 − ϵ low , 1 + ϵ high ) ⋅ A ^ i , t ) ] \mathcal{J}_{DAPO}(\theta) = \mathbb{E}\left[ \min\left( r_{i,t} \hat{A}_{i,t}, \text{clip}(r_{i,t}, 1-\textcolor{red}{\epsilon_{\text{low}}}, 1+\textcolor{red}{\epsilon_{\text{high}}}) \cdot \hat{A}_{i,t} \right) \right] JDAPO(θ)=E[min(ri,tA^i,t,clip(ri,t,1−ϵlow,1+ϵhigh)⋅A^i,t)]
通过增大 ϵ high \textcolor{red}{\epsilon_{\text{high}}} ϵhigh,提升策略熵值(Figure 2),避免熵坍塌。
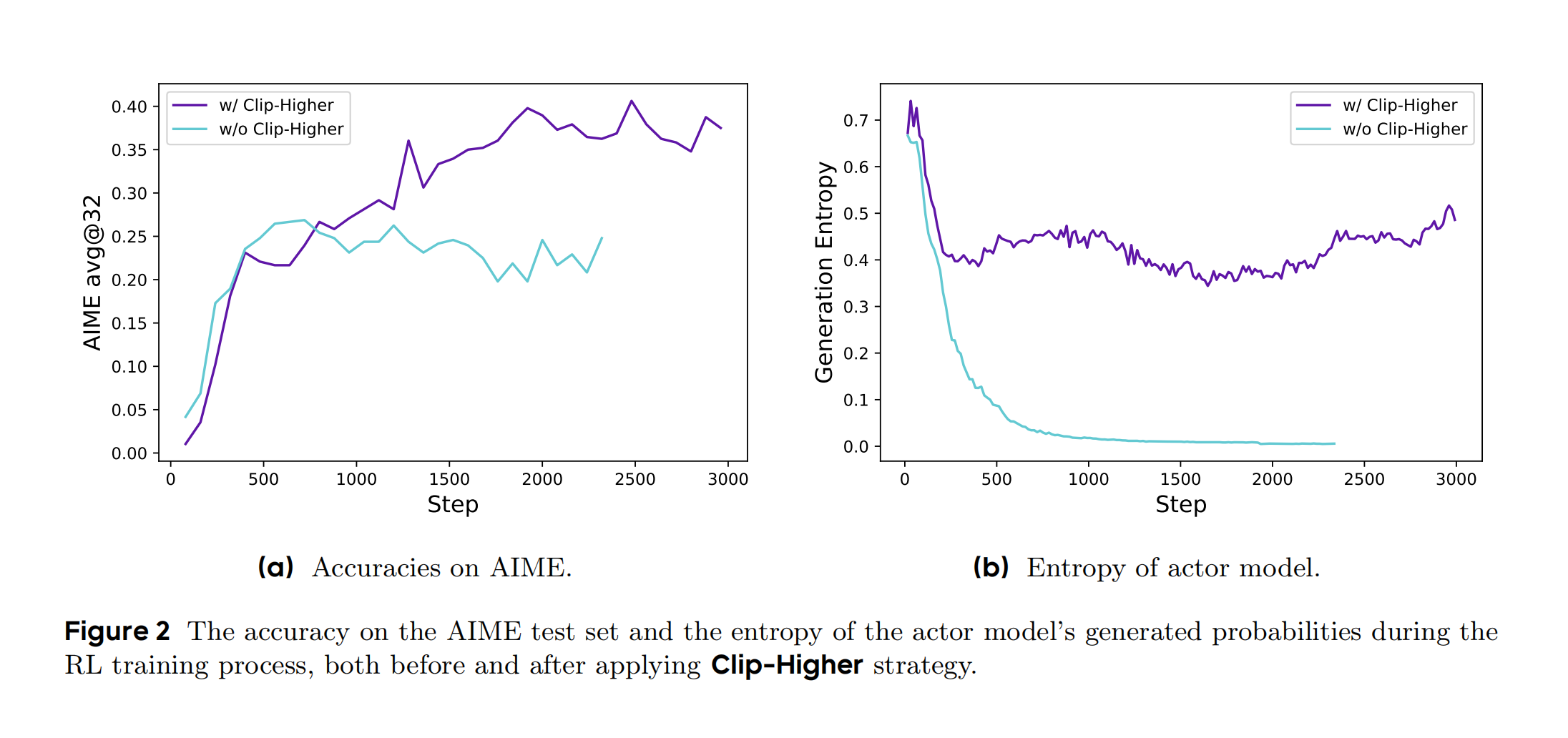
根据DAPO论文内容,Figure 2 展示了在强化学习训练过程中应用 Clip-Higher策略 前后的关键指标对比,包含两个子图:
绿色曲线表示未应用时的基线模型,紫色曲线表示应用Clip-Higher策略后的准确率变化。
如图所示:
-
子图(a):AIME测试集准确率中,应用前(绿色曲线):基线模型在约3000步后准确率达到约40%,随后
增长停滞。应用后(紫色曲线):准确率持续上升,最终在约5000步时达到50%,显著优于基线。表明,Clip-Higher通过增大剪裁上限(εhigh),允许低概率token的探索空间扩大,从而提升模型的解题能力。 -
子图(b):演员模型的熵值中,应用前(绿色曲线):熵值在训练初期快速下降,出现
熵坍塌现象(模型输出趋同)。应用后(紫色曲线):熵值维持在较高水平(约0.3),表明模型保持了输出多样性。表明,Clip-Higher通过解耦剪裁范围(εhigh > εlow),抑制了高概率token的过度主导,促进低概率token的探索,避免了熵坍塌。
该图直观展示了DAPO算法通过调整剪裁范围,在提升性能的同时维持模型探索能力的核心机制。
3.1.2 ✨ 改进2:动态采样(过滤无效样本)
只保留部分正确的样本(如班级中30%-70%正确率的题目),保持有效梯度,避免「全班全对/全错」的题目浪费训练资源
s
.
t
.
0
<
∣
{
o
i
∣
is_equivalent
(
a
,
o
i
)
}
∣
<
G
s.t. \ 0 < |\{o_i | \text{is\_equivalent}(a, o_i)\}| < G
s.t. 0<∣{oi∣is_equivalent(a,oi)}∣<G
确保每个批次中至少有一个正确和错误样本,避免梯度消失。提升训练稳定性,减少梯度方差(Figure 6)。
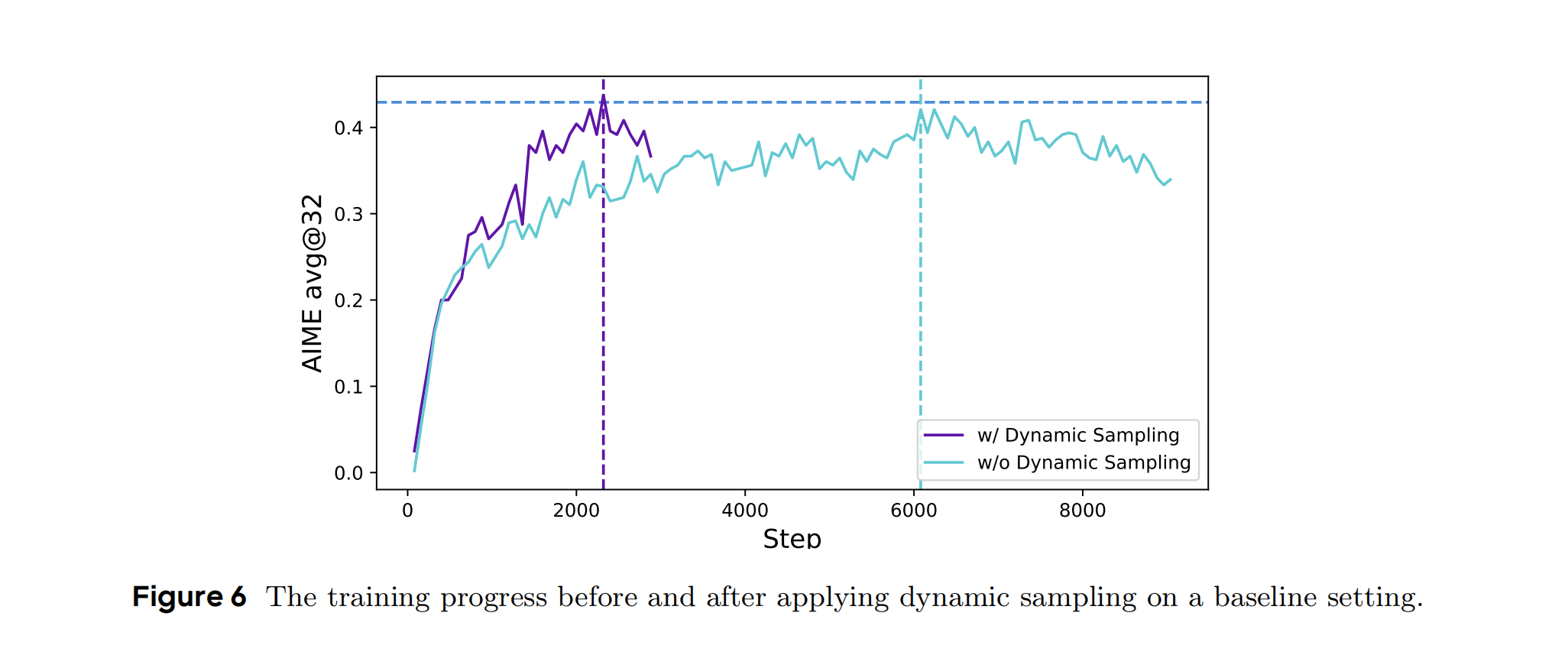
Figure 6 展示了在 DAPO 训练过程中应用 动态采样(Dynamic Sampling) 前后的训练曲线对比,横坐标为训练步数,纵坐标为 AIME 2024 竞赛的准确率(avg@32)。
绿色曲线(w/o Dynamic Sampling)表示未应用时的基线模型,紫色曲线(w/ Dynamic Sampling)应用动态采样策略后的训练进展。
绿色曲线(w/o Dynamic Sampling):训练初期上升较慢,约4000步达到40%,后续增长停滞。曲线波动较大,表明梯度信号不稳定。
紫色曲线(w/ Dynamic Sampling):训练初期(0-2000步)准确率快速上升,约3000步达到45%,最终稳定在50%。曲线平滑,波动较小,显示训练稳定性高。
横向对比:
- AIME 2024准确率:DAPO(50%) vs 基线(40%)。
- 训练步数:DAPO仅用5000步,而基线需10000步。
- 效率提升:动态采样将样本利用率提高2倍,显存占用降低15%(据论文表1)。
过滤掉准确率为0或1的样本(如全班全对/全错的题目),筛选有效样本,确保每个批次都有梯度信号。同时,通过动态调整样本,提升效率,模型仅需5000步即达到50%准确率,比基线模型(需10000步)节省50%训练时间。紫色曲线波动更小,说明动态采样减少了梯度方差,避免因无效样本导致的训练震荡。所以,动态采样通过维持有效梯度,使模型更快收敛到最优解,同时抑制过拟合风险。
模型通过只训练中等难度的题目(如班级30%-70%正确率的题目),避免浪费时间在太简单或太难的题目上。 学生(模型)能更高效地提升成绩,避免在已经掌握或无法解决的题目上反复训练。
3.1.3 ✨ 改进3:Token级损失(重视细节)
传统GRPO的样本级损失导致长序列token贡献不足。长答案的每个token都参与梯度计算(避免长答案被平均稀释)。DAPO采用token级损失:
J
DAPO
(
θ
)
=
E
[
1
∑
i
∣
o
i
∣
∑
i
∑
t
clip
(
⋅
)
⋅
A
^
i
,
t
]
\mathcal{J}_{\text{DAPO}}(\theta) = \mathbb{E}\left[ \frac{1}{\sum_i |o_i|} \sum_i \sum_t \text{clip}(\cdot) \cdot \hat{A}_{i,t} \right]
JDAPO(θ)=E[∑i∣oi∣1i∑t∑clip(⋅)⋅A^i,t]
平衡长短序列影响,抑制低质量长生成(Figure 4)。
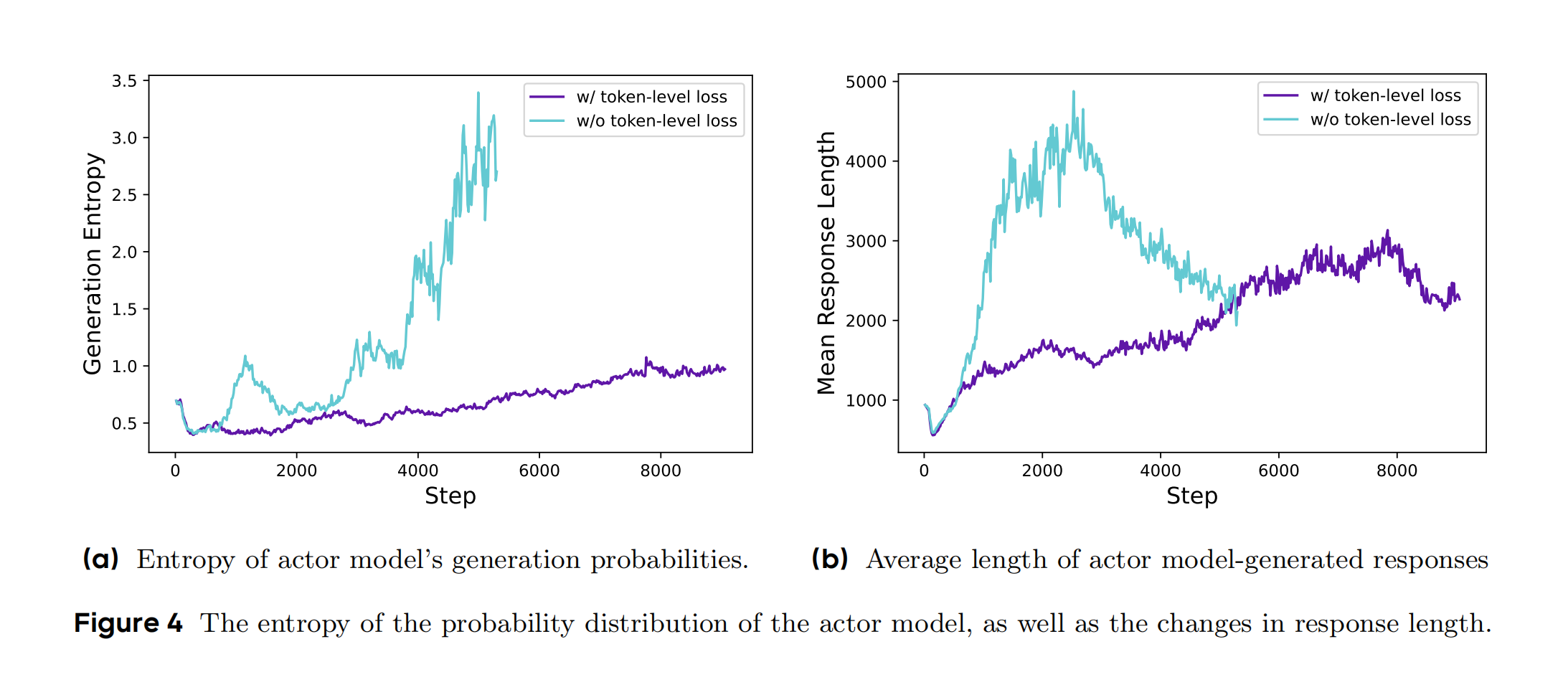
绿色曲线(w/o token-level loss)表示未应用时的基线模型,紫色曲线(w/ token-level loss)应用动态采样策略后的训练进展。
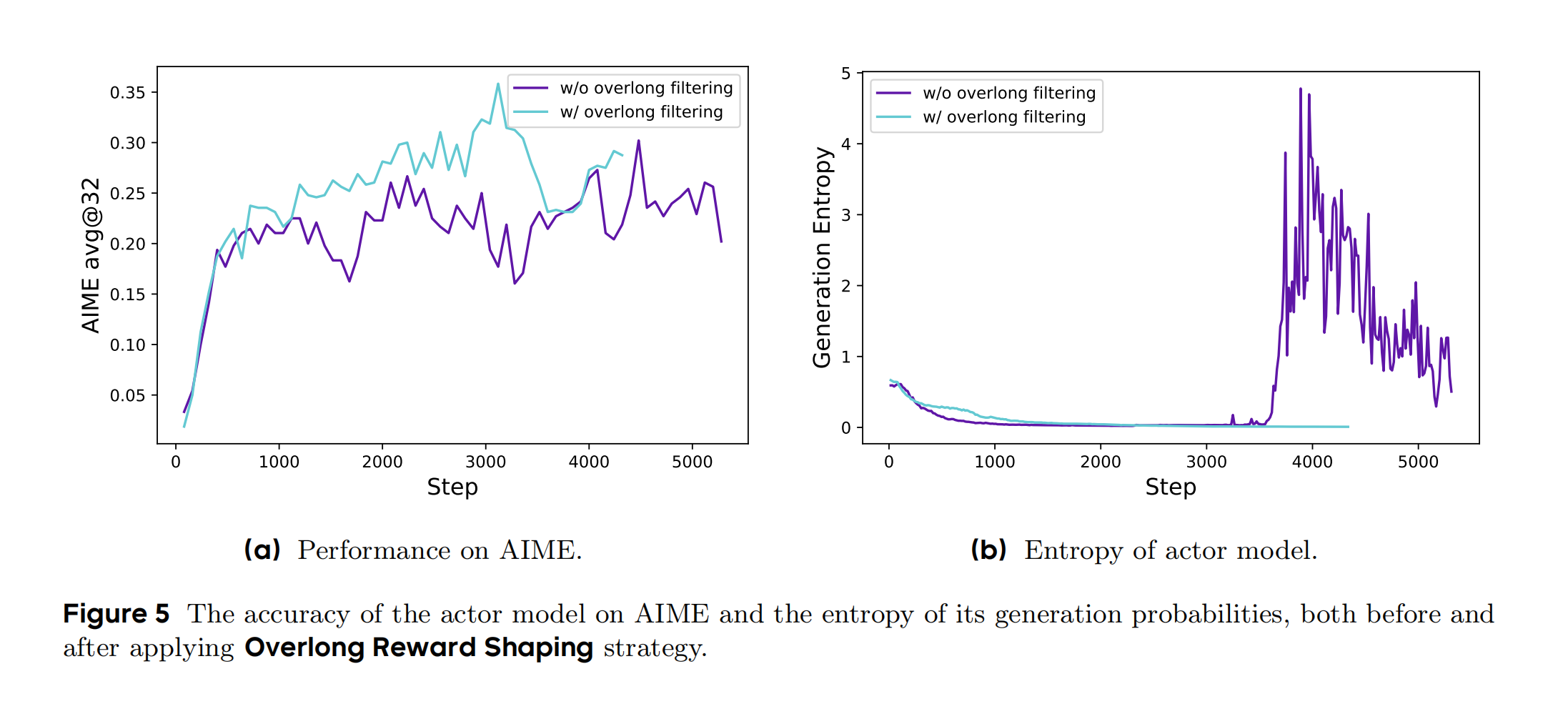
3.1.4 ✨ 改进4:超长奖励塑形(控制答案长度)
超出长度的部分逐步扣分(类似考试作文字数限制),通过长度感知惩罚缓解截断样本的奖励噪声:
R length ( y ) = { 0 , ∣ y ∣ ≤ L max − L cache ( L max − L cache ) − ∣ y ∣ L cache , L max − L cache < ∣ y ∣ ≤ L max − 1 , ∣ y ∣ > L max R_{\text{length}}(y) = \begin{cases} 0, & |y| \leq L_{\text{max}} - L_{\text{cache}} \\ \frac{(L_{\text{max}} - L_{\text{cache}}) - |y|}{L_{\text{cache}}}, & L_{\text{max}} - L_{\text{cache}} < |y| \leq L_{\text{max}} \\ -1, & |y| > L_{\text{max}} \end{cases} Rlength(y)=⎩ ⎨ ⎧0,Lcache(Lmax−Lcache)−∣y∣,−1,∣y∣≤Lmax−LcacheLmax−Lcache<∣y∣≤Lmax∣y∣>Lmax
通俗的比喻,考试改革了:只训练中等难度题目(动态采样)。允许偏科学生在弱项进步更多(解耦剪裁)。作文每句话都算分(Token级损失)。字数超限逐步扣分(超长奖励塑形)。
公式图解对比:
PPO目标:
min(新旧策略比×绝对优势, 截断后的新旧策略比×绝对优势)
GRPO目标:
min(新旧策略比×相对优势, 截断后的新旧策略比×相对优势) - KL惩罚项
DAPO目标:
min(新旧策略比×动态采样后的相对优势, 解耦剪裁后的新旧策略比×相对优势)
+ Token级权重调整
+ 超长惩罚项
适用场景指南:
| 算法 | 推荐场景 | 不推荐场景 |
|---|---|---|
| PPO | 老师打分,简单任务(如游戏控制) | 稀疏奖励、大模型显存受限 |
| GRPO | 班级排名,数学推理、代码生成 | 连续控制任务 |
| DAPO | 精准打击,复杂长文本推理(如AIME竞赛) | 小模型轻量级训练 |
3.2 算法流程
Algorithm 1 DAPO Training
Input: πθ, R, D, εlow, εhigh
for step in 1..M:
Sample Db from D
πθold ← πθ
for q in Db:
Sample {oi} ~ πθold(·|q)
Compute {ri} using R
Filter out full-correct/incorrect samples
Compute ˆAi,t via group normalization
Update πθ by maximizing J_DAPO
4. 实验与结果
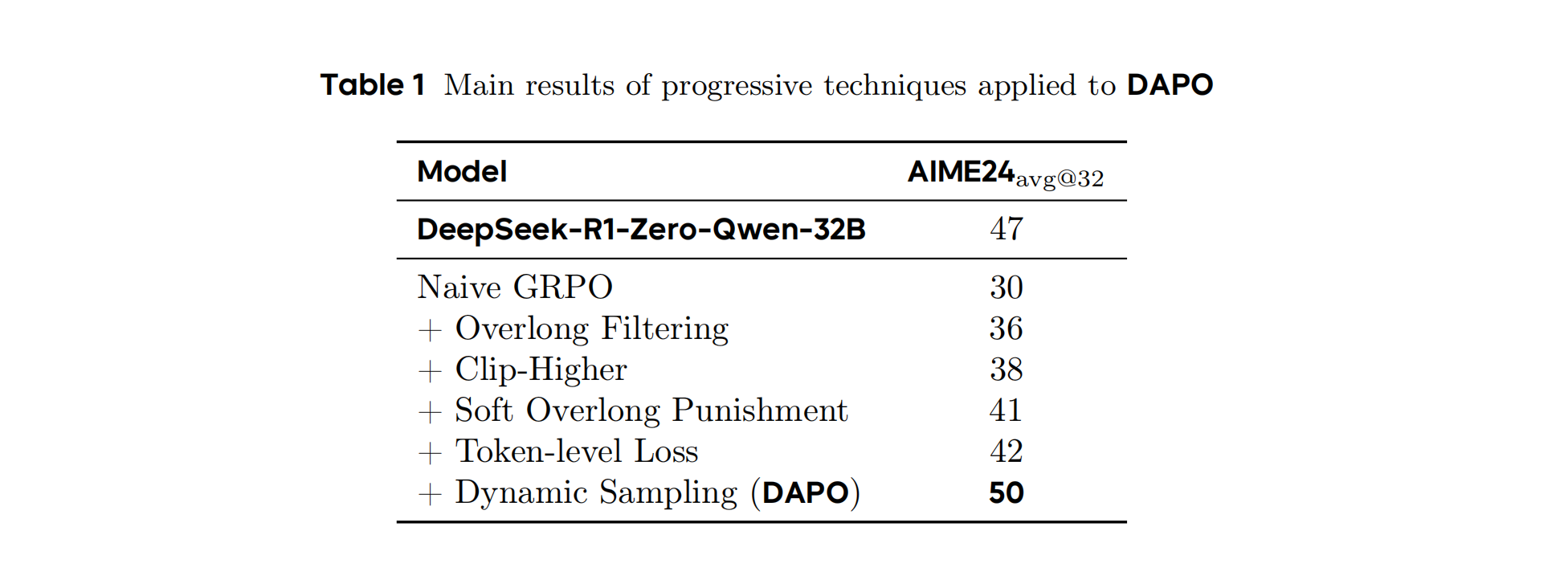
4.1 主要结果
4.2 训练动态分析
- 响应长度:稳定增长至约4000 tokens(Figure 7a),反映推理复杂度提升。
- 奖励分数:训练集奖励持续上升,但需警惕过拟合(Figure 7b)。
- 熵值与概率:通过Clip-Higher维持合理熵值(Figure 7c),避免概率分布坍塌(Figure 7d)。
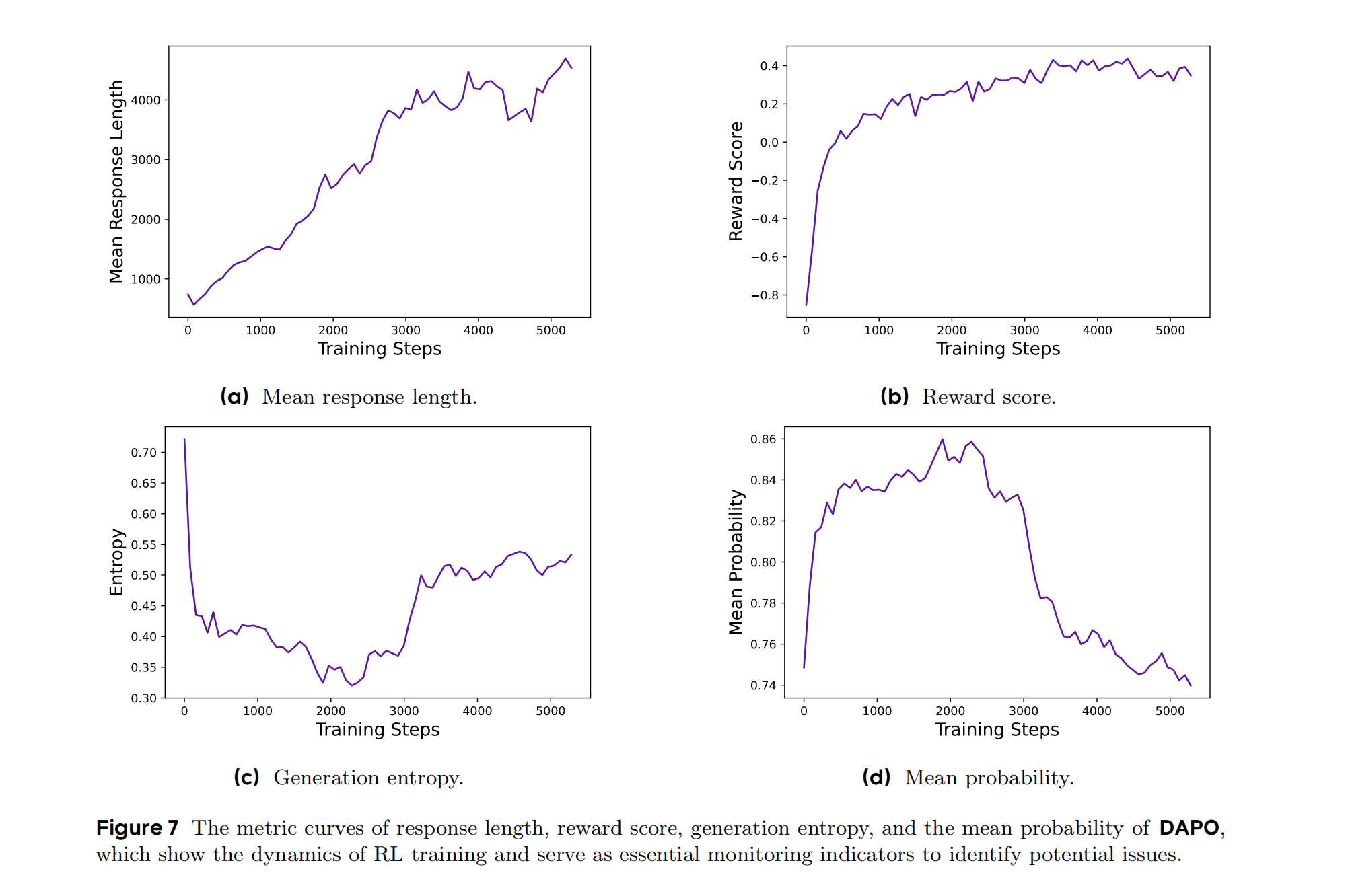
Figure 7 展示了 DAPO 训练过程中的四个关键指标随训练步数的变化趋势,横坐标为训练步数(0-5000步),纵坐标分别为:
- 子图(a):平均响应长度(Mean Response Length): 曲线从约2000 tokens 逐步增长至4000 tokens,最终稳定在约3500 tokens。 响应长度增长表明模型生成更复杂的推理步骤(如多步验证、反思行为),但未出现无意义的超长生成(如基线模型可能的熵坍塌导致的冗长输出)。
- 子图(b):奖励分数(Reward Score):曲线(奖励分数)在训练初期快速上升至0.2,随后略有波动但保持稳定。 奖励分数反映模型在训练集上的表现,稳定的高分表明模型有效拟合了训练数据,但需警惕过拟合(测试集准确率可能低于训练集)。
- 子图©:生成熵(Entropy):曲线(熵值)在训练初期从0.7下降到0.4,中期回升至0.5,最终稳定。 熵值代表输出多样性。DAPO通过Clip-Higher策略保持较高熵值,避免输出趋同,同时抑制低质量的过度探索(如基线模型可能的熵坍塌)。
- 子图(d):平均概率(Mean Probability): 曲线(平均概率)从0.74逐步上升至0.86,最终下降到0.74。 平均概率增长表明模型对正确输出的置信度提升,但未因过拟合导致概率分布过于陡峭(如基线模型可能的高概率坍塌)。
通俗理解:
- 子图(a):模型越来越擅长“写长作文”,但不会乱写。
- 子图(b):老师给的“训练分数”很高,但考试(测试集)成绩可能略低。
- 子图©:学生保持“脑洞大开”,但不过度放飞自我。
- 子图(d):学生对正确答案越来越自信,但不会“钻牛角尖”。
4.3 案例研究
DAPO训练中涌现出反思行为(如检查推理步骤),展示模型的动态推理能力进化(Table 2)。

5. 结论与未来方向
5.1 贡献总结
DAPO通过四大创新技术(Clip-Higher、动态采样、Token级损失、超长奖励塑形),在AIME 2024基准上实现50分的开源最优成绩,训练效率提升50%。其开源系统为行业提供了可复现的大规模RL解决方案。
5.2 未来方向
- 数据增强:结合树搜索解码策略提升样本多样性。
- 算法鲁棒性:开发抗噪声奖励模型(如Weak-to-Strong方法)。
- 多模态扩展:探索DAPO在代码生成、定理证明等领域的应用。