跟李沐学AI:DALL·E 2 论文精读
原视频:DALL·E 2(内含扩散模型介绍)【论文精读】_哔哩哔哩_bilibili
原论文:[2204.06125] Hierarchical Text-Conditional Image Generation with CLIP Latents
背景知识
GAN (Generative Adversarial Networks)
生成对抗网络 (GAN) 是一种生成式模型,它由两个核心组件构成:一个生成器 (Generator, G) 和一个判别器 (Discriminator, D)。
-
生成器 (G) 的目标是学习真实数据分布,并生成与真实数据高度相似的合成数据样本。 它通常以一个从预定义的先验分布(例如,高斯分布或均匀分布)中随机采样的噪声向量 (latent vector, z) 作为输入。生成器通过一系列复杂的变换(通常由深度神经网络实现),将这个低维的噪声向量映射到高维的数据空间,例如生成图像的像素矩阵。理想情况下,生成器希望其生成的“假”数据能够以假乱真,使得判别器难以区分真伪。
-
判别器 (D) 的目标是一个二分类任务:判断给定的数据样本是来自真实数据分布的“真”样本,还是由生成器产生的“假”样本。 判别器接收一个数据样本作为输入(这个样本可能是真实的训练数据,也可能是生成器生成的伪造数据),并输出一个概率值(通常在 0 到 1 之间),表示该样本是真实数据的可能性。判别器的训练目标是准确地区分真实数据和生成器产生的假数据。
AE (Auto Encoder)
自编码器AE主要由两部分组成:
- Encoder编码器:接受输入数据x,经过一系列非线性变化,将其映射为一个低维度的潜在表示z,z=E(x)。这个过程可以看作是对输入数据的压缩或特征提取。
- Decoder解码器:接受潜在表示z,经过非线性变换,将z还原为符合原始数据分布的
,
。解码器的目标是尽可能地从潜在表示中恢复出原始输入数据。
AE的训练目标是最小化真实数据x和重构数据之间的误差。
DAE (Denosing Auto Encoder)
DAE与AE相比最主要的区别为:DAE 的目标不是直接学习输入x的恒等映射(即 ),而是学习一个从被污染的输入
映射到原始的、干净的输入
的函数。
具体来说,DAE训练包括如下流程:
- 对原始数据x添加噪声得到
。其中 C 是一个随机 corruption 过程。常见的噪声类型包括高斯噪声、遮挡部分像素(对于图像)、随机交换词语(对于文本)等。
- 将噪声数据
输入编码器得到低维潜在特征
- 解码器将z重构为
- DAE 的训练目标是最小化重构
之间的差异,即最小化
。
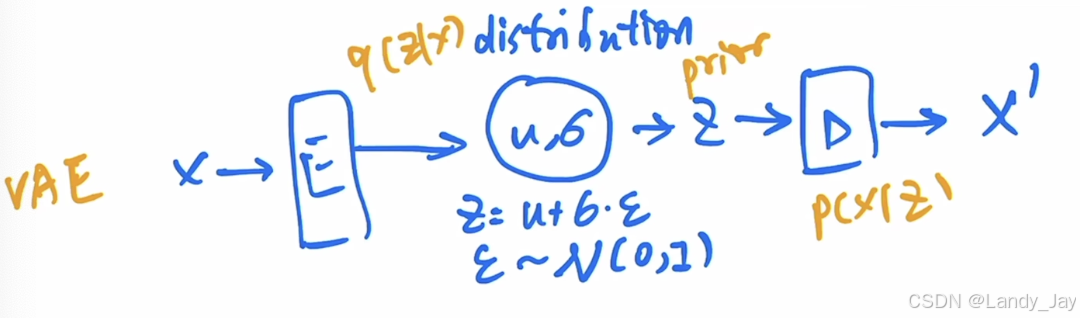
VAE (Variation Auto Encoder)
AE和DAE主要都是为了学习原始输入X经过Encoder后得到的潜在特征z,而不是学习一个概率分布,主要用于分类、分割任务等。z不能进行随机采样,不能用于生成任务。为了将Encoder-Decoder的架构用于生成类任务,VAE主要学习一个概率分布(假设为高斯分布),而不是z特征。
具体来说,VAE在得到Encoder的输出后,将输出特征通过全连接层预测概率分布的均值和方差。得到均值方差后,根据特定的公式:来采样一个z交给解码器。这样VAE就可以用于生成任务了,模型解码时无需Encoder,只需要从学习到的分布进行随机采样即可。
VAE 假设数据 x 是由一个隐藏的、连续的潜在变量 z 生成的。VAE 的目标是学习这个潜在变量的分布 以及给定潜在变量生成数据的条件分布
。由于真实的后验分布
通常难以直接计算,VAE 通过引入一个近似的后验分布
来进行学习。
在图像生成任务中VAE相比GAN具有更好的多样性。
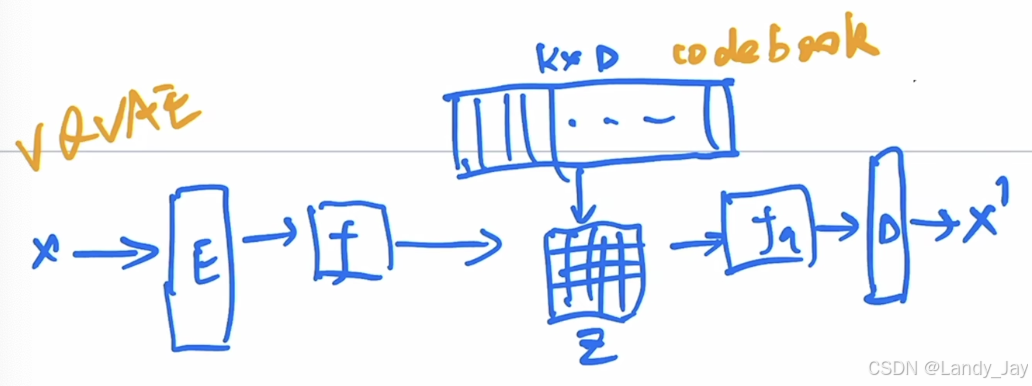
VQVAE (Vector Quantized Variational Autoencoder)
VQVAE相对于VAE的核心改进为:将学习一个潜在分布的目标改变为,学习K个d维度的特征向量来简化学习目标。
标准VAE中,学习一个连续的分布存在如下挑战:
- 需要模型能表示这个分布在连续空间的形状
- 需要保障潜在空间是连续且有意义的
- 从连续分布中随机采样生成高质量的样本有时比较困难
VQ-VAE 的关键创新在于引入了码本,这是一个包含 K 个 d 维向量(码字)的集合。编码器仍然输出一个连续的特征映射,但是这个特征映射随后被量化到码本中最接近的码字。这个量化过程本质上是将连续的潜在空间离散化为 K 个“类别”或“原型”。
VQVAE的组成为:
Encoder:将输入 x 映射到连续的潜在空间,输出一个特征映射e(x)
Codebook:创建Codebook,包含K个Codewords,每个Codeword是d维的向量。
量化:将Encoder中输出的每个e(x),从Codebook中找到与之最相近的Codeword(通常通过欧氏距离),将每个e(x)替换为codeword
Decoder:将量化后的的离散潜在表示作为输出,尝试重构
VQVAE无法直接用于生成任务,需要额外的Prior网络才能进行生成。
即将一个预训练好的VQVAE对原始数据进行编码得到特征映射,随后我们可以将这个特征映射中的每个离散的潜在编码看作序列中的一个元素。
然后,我们可以使用像 PixelCNN、Transformer 或 RNN 这样的自回归模型来学习这些离散潜在编码的条件概率分布。
1. VQ-VAE 的局限性
VQ-VAE 本身只是一个压缩模型,它的功能是:
- 编码器:将输入数据(如图像)映射到离散的潜在编码(即
codebook中的向量索引)。 - 解码器:根据离散编码重建数据。
但问题在于:
VQ-VAE 没有学习数据的概率分布,因此无法直接生成新的离散编码(即无法“创造”新数据)。
2. 解决方案:引入 Prior 网络
为了生成新数据,需要额外训练一个 Prior 网络(即自回归模型),学习离散潜在编码的分布。具体步骤如下:
步骤 1:用 VQ-VAE 压缩数据
- 输入图像 → VQ-VAE 编码器 → 得到离散潜在编码序列 z(例如,一张图像被编码为 32×32 的整数矩阵,每个整数对应
codebook中的一个向量)。
# 伪代码示例
z = vqvae_encoder(image) # 输出形状 [32, 32],每个元素是codebook的索引
步骤 2:将离散编码视为序列
- 将 z 展平为序列(如按光栅顺序排列成 1024 长度的序列),每个位置的值是离散的(类似文本中的单词索引)。
z_sequence = flatten(z) # 例如 [12, 5, 9, ..., 42](共1024个token)
步骤 3:训练 Prior 网络学习序列分布
用自回归模型(如 Transformer、PixelCNN)学习这些离散编码的联合概率分布
- 训练目标:给定前 i−1 个 token,预测第 i个 token(类似语言模型)。
- 生成时:Prior 网络逐步采样 z1,z2,...,zn 生成全新的离散编码序列。
步骤 4:用 VQ-VAE 解码生成数据
将 Prior 网络生成的离散序列 z 输入 VQ-VAE 解码器,得到最终生成的数据。
generated_image = vqvae_decoder(z_sequence)
标题解读
使用CLIP训练好的特征,进行层级式的,基于文本的图片生成。
层级式:DALLE2先生成一个64*64分辨率的小图片,再上采样到256*256,最后再上采样到1024*1024
CLIP特征:DALLE2先训练好一个CLIP模型,利用与训练好的CLIP文本编码器得到文本特征,然后使用训练好的Prior模型,根据文本特征得到图像特征,然后将图像特征输入给解码器得到完整的图像。
摘要
如CLIP等基于对比学习的模型,已经学会了如何捕捉一个稳健的、包含语意和风格的图像特征。为了将这种特征利用与图像生成任务,作者团队提出了一个两阶段的模型:1. 一个Prior模型根据给定的文本描述,生成CLIP图像Embedding;2. 一个根据图像Embedding生成图片的Decoder。
具体流程为:
文本 -> CLIP生成文本特征 -> 根据文本特征生成图像特征(Prior) -> 解码器根据图像特征生成图像
作者团队发现。显式地加入文本特征可以在最小损害图像真实性和文本相似性的情况下,提升图像的多样性。即图片生成的结果又逼真又多样。
在CLIP模型的文本-图像联合语义空间下,用户可以使用自然语言直接对生成的图像进行操控。
作者团队使用扩散模型作为decoder,然后对Autoregressive模型和Diffusion模型都进行实验后,发现Diffusion模型更适合作为模型架构中的Prior模型。
引言
1. CLIP模型
在大规模的从网络收集的图-文对数据集框架中,CLIP模型展现出了强大的图像特征学习能力。CLIP Embeddings在图像特征偏移的问题上展现了强大的健壮性、拥有强大的zero-shot能力和很好的图像文本任务微调迁移能力。
2. Diffusion模型
扩散模型展现出强大的图像、视频生成能力。为了实现更逼真的生产结果,扩散模型利用“guidance technique”,以牺牲采样的多样性,来提升结果的真实性。
方法
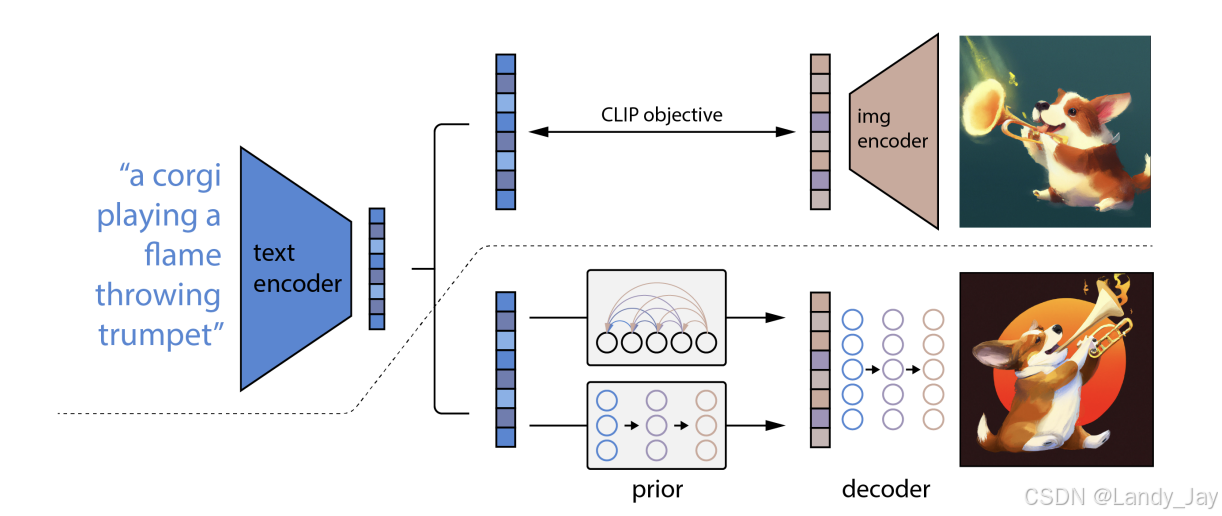
图像上半部分:预训练好的CLIP模型。将文本Emedding和图片Embedding使用对比学习的方式进行对齐。
图像下半部分:在锁住已经预训练好的CLIP模型的基础上,训练Prior模型,训练目标如下:根据CLIP文本Embedding,Prior模型能生成一个图像Embedding。具体而言,训练时,Prior模型的输入式CLIP模型的文本Embedding,随后将CLIP图像编码器生成的Embedding作为Ground Truth进行训练。训练完成后,Prior模型能直接从文本特征得到后续用于解码的图像特征。