数字人对嘴型Wav2Lip模型原理与源码详解(推理部分)
本文完整代码地址: Github
文章目录
- 1. 对嘴型(Lip-Syncing)任务介绍
- 2. Wav2Lip 概述
- 3. Wav2Lip各个模块详解
- 3.1 Face Detect
- 3.2 Mel Spectrogram提取音频特征
- 3.3 Face Encoder
- 3.4 Audio Encoder
- 3.5 Face Decoder
- 3.5 Output Block
- 4. 实战:使用Wav2Lip模型生成视频
- 5. Wav2Lip总结
- 参考文献
1. 对嘴型(Lip-Syncing)任务介绍
目前市面上有很多有关数字人项目和产品,比较常见的有:ER-NeRF, EchoMimic, EchoMimic2, hallo2 等等
这些项目的目标各不同,但都离不开一个核心,那就是对嘴型。
对嘴型的模型可以简单的用下图来表示:
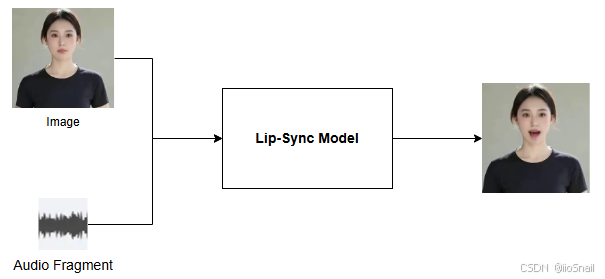
给模型一张图片和一小段人声音频,模型输出与音频对应口型的图片。
2. Wav2Lip 概述
为了解决“对嘴型”问题,Wav2Lip模型提出了一种简单却有效的方法,如下图所示:
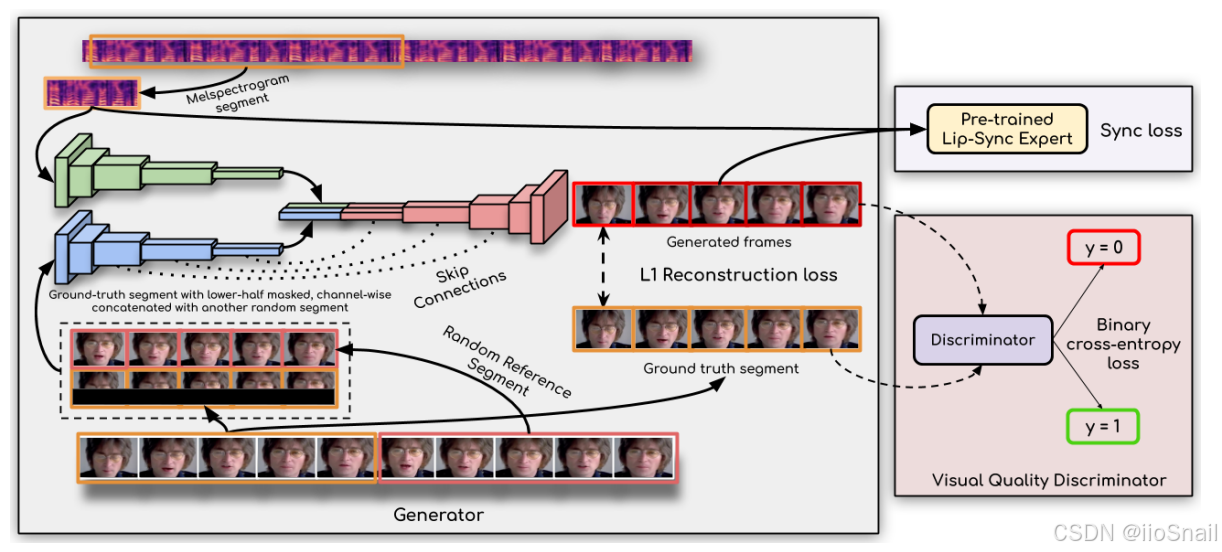
这是Wav2Lip论文中的模型架构图,这张图中详细说明了Wav2Lip是如何进行训练和推理的。
不过,本文并不讨论Wav2Lip的训练部分,仅针对推理部分进行解释。Wav2Lip模型架构的推理部分可以详细描述为下图:
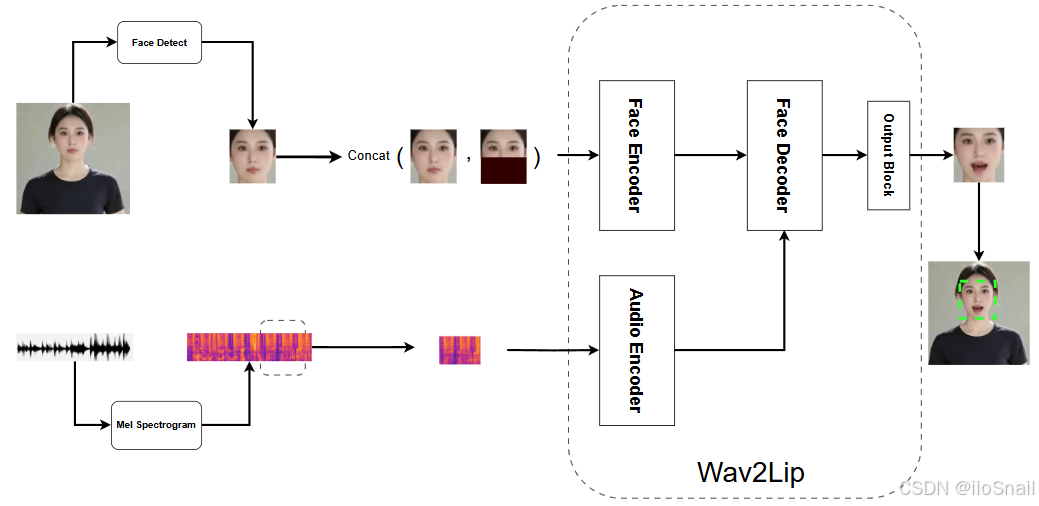
在Wav2Lip推理过程如下:
(1)数据处理阶段:
- 使用一个“人脸检测(Face Detect)”网络找到图片中人脸所在的位置,你也可以通过
face_box这个参数来告诉模型人脸所在的位置。 - 之后将人脸的下半部分遮住,然后和整张人脸进行concat,作为人脸的输入。
- 对于音频来说,模型会先提取整个音频的“梅尔频谱图(Mel Spectrogram)”,然后截取出要对嘴型的那一小段音频作为音频输入
(2)模型推理阶段:
- Wav2Lip的“Face Encoder”会对人脸进行编码,而“Audio Encoder”会对音频进行编码。
- 在编码之后,它们会作为“Face Decoder”的输入来生成对应口型的图片,Face Decoder会输出对口型后的人脸编码。
- 最终,由一个“Output block”将其输出为人脸图片。
(3)输出处理:
- 在模型输出人脸后,将其覆盖到原来的人脸图片上即可。
3. Wav2Lip各个模块详解
上一章中,本文粗略讲解了Wav2Lip的模型整体架构,其中忽略了很多细节。本章将会对各个模块结合源码进行细致讲解。
3.1 Face Detect
其实严格来说,Face Detect并不能算Wav2Lip的一部分。它只是拿过来识别人脸区域的。
在Wav2Lip的源码中,默认使用的是S3FD模型实现的人脸检测。部分源码如下:
def face_detect(images):
detector = face_detection.FaceAlignment(face_detection.LandmarksType._2D,
flip_input=False, device=device)
# ...
models_urls = {
's3fd': 'https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth',
}
class SFDDetector(FaceDetector):
def __init__(self, device, path_to_detector=os.path.join(os.path.dirname(os.path.abspath(__file__)), 's3fd.pth'), verbose=False):
super(SFDDetector, self).__init__(device, verbose)
# Initialise the face detector
if not os.path.isfile(path_to_detector):
model_weights = load_url(models_urls['s3fd'])
else:
model_weights = torch.load(path_to_detector)
self.face_detector = s3fd()
self.face_detector.load_state_dict(model_weights)
self.face_detector.to(device)
self.face_detector.eval()
# ...
相比在推理过程中检测人脸,你也可以选择提前使用该模型检测人脸,在推理时直接作为参数传入,这样可以极大的降低推理时间。
不过在源码中,你只能传入一个人脸box。也就是说,你的输入最好是一个静态图片,要是一段视频,那人脸就要保持一个位置不要动。该参数在源码中如下:
parser.add_argument('--box', nargs='+', type=int, default=[-1, -1, -1, -1],
help='Specify a constant bounding box for the face. Use only as a last resort if the face is not detected.'
'Also, might work only if the face is not moving around much. Syntax: (top, bottom, left, right).')
在提取人脸之后,我们需要将人脸从原始图片中抠出来。之后,我们需要将整张人脸和一个半张人脸进行concat,将该结果作为输入。代码如下:
y1, y2, x1, x2 = face_box
# 从原始的图片中把人脸抠出来
face = image[y1: y2, x1:x2]
# 将人脸resize到96x96
face = cv2.resize(face, (96, 96))
# 构建一个batch的人脸,该人脸包含嘴巴。
face_batch = np.asarray([face] * batch_size)
# 构建一个不含嘴巴的人脸,方法就是将人脸的下半部分置为0
masked_batch = face_batch.copy()
masked_batch[:, 48:] = 0
# 将人脸和不含嘴巴的人脸concat到一起
face_batch = np.concatenate((masked_batch, face_batch), axis=3) / 255.
# 调整一下张量的shape,原来为(batch_size, 96, 96, 6), 调整后为(4, 6, 96, 96)
# 也就是将RGB这个维度调到batch_size后面
face_batch = np.transpose(face_batch, (0, 3, 1, 2))
face_batch = torch.FloatTensor(face_batch).to(self.device)
上述代码中,输入的是静态图片。如果要是输入视频的话,需要对每一帧采用不同的face_box,在构建face_batch是将每帧的人脸拼一起。
3.2 Mel Spectrogram提取音频特征
音频是一段声波,通常不会直接作为输入,而是要通过一些方法提取出音频特征作为输入。Wav2Lip中采用的是传统的梅尔频谱图(Mel Spectrogram)作为音频的特征提取方式。
对于提取音频特征来说,最重要的参数就是采样率(Sample Rate),它表示这段音频每秒使用多少个样本点来表示。例如:
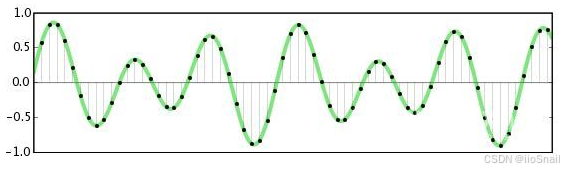
对于一个采样率为16000的音频,它每秒会使用16000个点(如上图中黑点)来表示该音频的波形。
因此,原始音频数据是一个一维的向量。例如:一个5秒钟的音频,采样率为16000,则读取为numpy向量后,其shape为 (80000, )
将一个音频转换为频谱图后,就会包含更多的信息。例如,以下是一个频谱图:
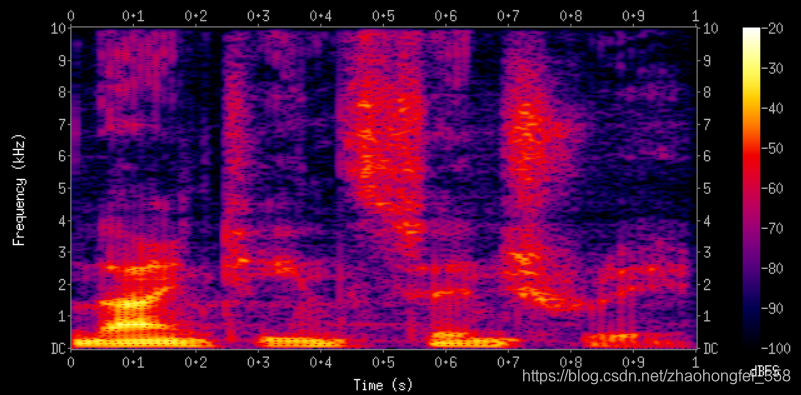
它包含以下几个部分:
- 横坐标(时间序列):横坐标表示时间序列
- 纵坐标(频率):纵坐标表示声音频率,纵坐标越大,说明频率越高,越接近0,说明频率越低。
- 颜色(振幅):颜色代表振幅,颜色越亮,表示振幅越高。越暗,表示振幅越小
计算频谱图的大致过程如下:
- 声音采样:将音频声音信号切分成小块,每段大概10-40毫秒。
- 傅里叶变换:将声波转换为频率和强度后,转换为梅尔尺度。之后将采样窗口向前推进,继续转换。
- 结果拼接:将每个转换后的小段拼接起来。
例如:假设有一个5秒的音频,采样率为16000,则一共有80000个点。计算频谱图时,窗口大小设为800(n_fft=800),步长设置为200(hop_length=200),梅尔带的数量设置为80(n_mel=80,可以理解将每个窗口的数据编码成80维的向量),则提取后的音频特征的shape为:(80, 80000/200 + 1) = (800, 401)
具体的处理过程可以简化为下图:
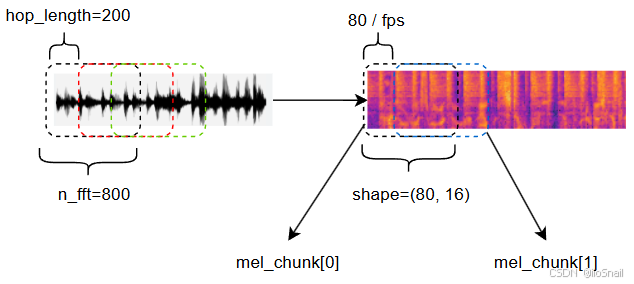
Wav2Lip关于提取音频特征的部分代码如下:
def extract_mel(self, audio_path):
sample_rate = 16000
# wav是一个numpy array. 音频文件的时长是5.544秒,因此,wav向量的长度就是
# 5.544 * 16000 = 88704。也就是说 wav.shape=(88704, )
wav = audio.load_wav(audio_path, sample_rate)
"""
从wav中提取梅尔频谱图。默认的参数为:
- n_mel: 80
- n_fft: 800
- hop_length: 200
提取后的mel的shape为 (80, 444). 444 = 88704 / 200 + 1
"""
mel = audio.melspectrogram(wav)
"""
将梅尔频谱图分割成多个块(chunks). 每个块对应一个视频帧. 例如:假设视频是25帧/秒,
音频持续5.544秒,那么chunks的数量大约就是 5.544 * 25 = 138.6,也就是138个chunk。
不过实际上只有136。后续代码会说明原因
"""
mel_chunks = []
# mel_step_size是指每个视频帧包含多少个mel帧. 默认值为16.
# 也就是说,每个mel_chunk的shape为(80, 16).
mel_step_size = 16
# mel_idx_multiplier每计算一个chunk后,往后走多少个mel帧. 例如, 如果fps是25
# 则mel_idx_multiplier为 80/25=3.2。也就是说步长为3.2。具体来说,对于第1个
# 视频帧,对应前16个mel帧,即`mel[:, 0:16]`. 对于第2个视频帧,对应3到19个mel帧
# 即`mel[:, 3:3+16]`,依次类推。这里之所以是80,是因为 1 / 80 = 0.0125 = 200 / 16000
mel_idx_multiplier = 80./self.fps
i = 0
while True:
start_idx = int(i * mel_idx_multiplier)
# 对于最后两个视频帧,mel帧不够了,所以最后两个视频帧不生成。
# 这就就是上面为什么最后只有136个chunk的原因
if start_idx + mel_step_size > len(mel[0]):
mel_chunks.append(mel[:, len(mel[0]) - mel_step_size:])
break
mel_chunks.append(mel[:, start_idx : start_idx + mel_step_size])
i += 1
print("Length of mel chunks: {}".format(len(mel_chunks)))
return mel_chunks
3.3 Face Encoder
Face Encoder模块用于对人脸进行编码。这个模块很简单,就是一些堆叠起来的卷积层。
Face Encoder的模型代码如下:
self.face_encoder_blocks = nn.ModuleList([
nn.Sequential(Conv2d(6, 16, kernel_size=7, stride=1, padding=3)), # 16, 96, 96
nn.Sequential(Conv2d(16, 32, kernel_size=3, stride=2, padding=1), # 32, 48, 48
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True)),
nn.Sequential(Conv2d(32, 64, kernel_size=3, stride=2, padding=1), # 64, 24, 24
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True)),
nn.Sequential(Conv2d(64, 128, kernel_size=3, stride=2, padding=1), # 128, 12, 12
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True)),
nn.Sequential(Conv2d(128, 256, kernel_size=3, stride=2, padding=1), # 256, 6, 6
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True)),
nn.Sequential(Conv2d(256, 512, kernel_size=3, stride=2, padding=1), # 512, 3, 3
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),),
nn.Sequential(Conv2d(512, 512, kernel_size=3, stride=1, padding=0), # 512, 1, 1
Conv2d(512, 512, kernel_size=1, stride=1, padding=0)),
])
Face Encoder的前向传播过程代码如下:
feats = []
x = face_sequences
# 逐层进行前向传播
for f in self.face_encoder_blocks:
x = f(x)
feats.append(x) # 将每层生成的特征记录到
将每层得到的特征存入feats列表,后续decode的时候要用。由于有7个nn.Sequential,因此len(feats)==7
输入的face_sequence.shape为(batch_size, 6, 96, 96),最后一层的feats[-1].shape为(batch_size, 512, 1, 1)
3.4 Audio Encoder
Audio Encoder和Face Encoder类似,都是一些卷积层堆叠而成的。
Audio Encoder的模型代码如下:
self.audio_encoder = nn.Sequential(
Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(32, 64, kernel_size=3, stride=(3, 1), padding=1),
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(64, 128, kernel_size=3, stride=3, padding=1),
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(128, 256, kernel_size=3, stride=(3, 2), padding=1),
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(256, 512, kernel_size=3, stride=1, padding=0),
Conv2d(512, 512, kernel_size=1, stride=1, padding=0),
)
Audio Encoder的前向传播过程代码如下:
audio_embedding = self.audio_encoder(audio_sequences)
输入的audio_sequences.shape为(batch_size, 1, 80, 16),输出audio_embedding.shape为(batch_size, 512, 1, 1)。 其和Face Embedding一致。这是为了后面可以相加进行融合。
3.5 Face Decoder
Face Decoder本身并不复杂,其就是一些卷积层和反卷积层的堆叠。卷积层可以提取图片特征,而反卷积层与其刚好相反,其是将图片特征逐步还原成原始图片。关于反卷积层,可以参考文章反卷积通俗详细解析与nn.ConvTranspose2d重要参数解释
Face Decoder的代码如下:
self.face_decoder_blocks = nn.ModuleList([
nn.Sequential(Conv2d(512, 512, kernel_size=1, stride=1, padding=0),), # 512, 1, 1
nn.Sequential(Conv2dTranspose(1024, 512, kernel_size=3, stride=1, padding=0), # 512, 3, 3
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),),
nn.Sequential(Conv2dTranspose(1024, 512, kernel_size=3, stride=2, padding=1, output_padding=1),
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),), # 512, 6, 6
nn.Sequential(Conv2dTranspose(768, 384, kernel_size=3, stride=2, padding=1, output_padding=1),
Conv2d(384, 384, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(384, 384, kernel_size=3, stride=1, padding=1, residual=True),), # 384, 12, 12
nn.Sequential(Conv2dTranspose(512, 256, kernel_size=3, stride=2, padding=1, output_padding=1),
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),), # 256, 24, 24
nn.Sequential(Conv2dTranspose(320, 128, kernel_size=3, stride=2, padding=1, output_padding=1),
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),), # 128, 48, 48
nn.Sequential(Conv2dTranspose(160, 64, kernel_size=3, stride=2, padding=1, output_padding=1),
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),), # 64, 96, 96
])
虽然Face Decoder的模型架构比较简单,但前向传播过程稍微有一丢丢复杂。它在前向传播过程需要结合每次的输出和之前Face Encoder的每一层输入。
具体过程如下图所示:
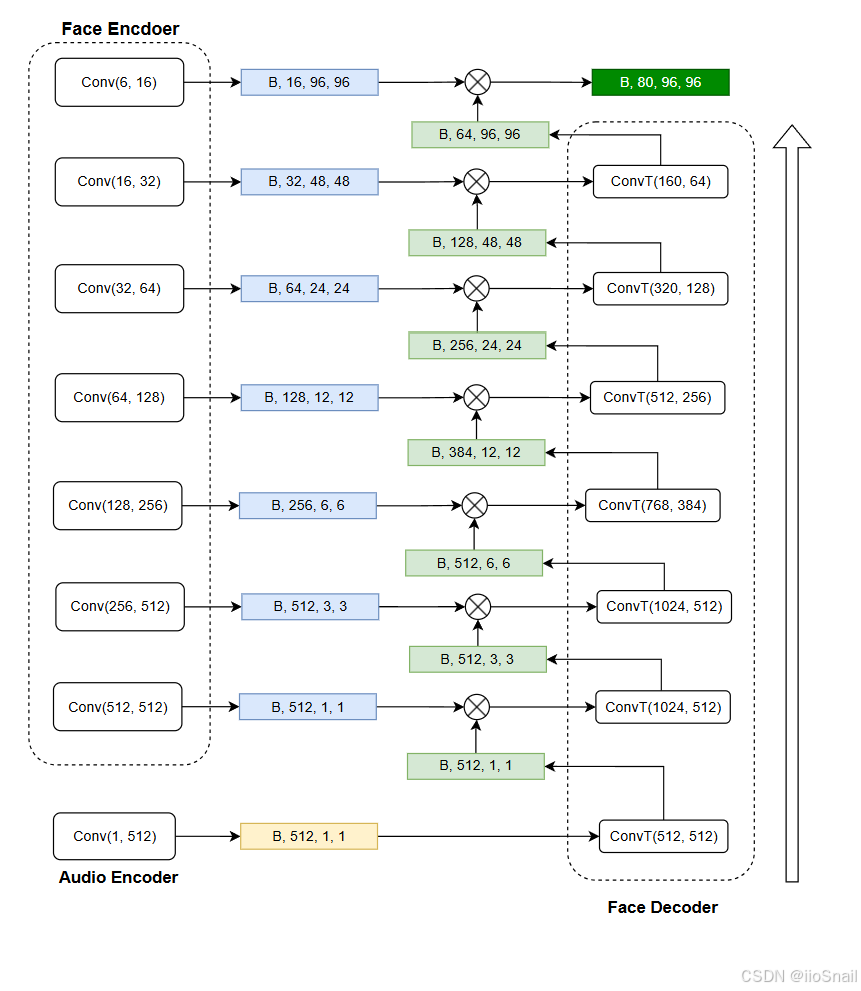
这张图中,我Conv表示卷积层,ConvT表示反卷积层。
⨂
\bigotimes
⨂ 表示concat操作。(这里我做了简化,省去了那些不会改变输入输出tensor维度的层)。
从图上可以看出,Face Decoder的最初输入是音频特征audio_emebdding。在这之后,每一层的输出都要和Face Encoder的每一层输出进行concat方式的融合,将其结果作为下一层的反卷积的输入。
最终,Face Decoder会输出一个shape为(batch_size, 80, 96, 96)的tensor。
3.5 Output Block
Face Decoder的输出蕴含了“人脸应该如何绘制”的信息。此时,只需要将其映射成具体的图片像素即可。因此,最后需要一个Output Block来做这个映射。
Output Block就是两个堆叠的卷积层,负责将face decoder的输出从(batch_size, 80, 96, 96) 映射到 (batch_size, 3, 96, 96)。最后,再用一个sigmoid将每个数值映射到0~1之间。
Output Block的模型代如下:
self.output_block = nn.Sequential(Conv2d(80, 32, kernel_size=3, stride=1, padding=1),
nn.Conv2d(32, 3, kernel_size=1, stride=1, padding=0),
nn.Sigmoid())
前向传播过程代码如下:
x = self.output_block(x)
输出人脸图片后,将其覆盖到原来人脸的区域即可。代码如下:
# 使用wav2lip生成人脸。preds就是上面的x
preds = self.wav2lip(mel_batch, face_batch)
# 将shape从(batch_size, 3, 96, 96)转为(batch_size, 96, 96, 3),同时数值映射到0-255
preds = preds.cpu().detach().numpy().transpose(0, 2, 3, 1) * 255.
for pred in preds:
# 读取原来人脸在照片上的位置
y1, y2, x1, x2 = face_box_list[index]
# 获取原来的照片
image = image_list[index]
# 将人脸从96x96拉伸到原来照片上人脸的大小
pred = cv2.resize(pred.astype(np.uint8), (x2 - x1, y2 - y1))
new_image = image.copy()
# 覆盖原始照片上的人脸
new_image[y1: y2, x1:x2] = pred
4. 实战:使用Wav2Lip模型生成视频
- Github
- 使用Google Colab运行
5. Wav2Lip总结
从本文的介绍可以得知,Wav2Lip是将人脸从图片中抠出来,然后变换成96x96的,之后用encoder提取特征之后,再用decoder生成新的人脸。因此,Wav2Lip存在如下局限性:
- 新生成的人脸清晰度会非常低。原图清晰度越高,反差就会越明显
- 如果用户使用的是静态图片,那么生成的结果就只有嘴会动。
Wav2Lip的优点:
- 生成的嘴型非常准确,甚至由于过于准确,会有一些违和感。
- 推理速度快,模型只有400M
- 不限人物类型,无论是真人还是动漫人物,都可以生成。
参考文献
- Wav2Lip官方代码 : https://github.com/Rudrabha/Wav2Lip
- Wav2Lip论文 : https://arxiv.org/abs/2008.10010