SiLU与GeLU激活函数:现代大模型的选择
SiLU与GeLU激活函数:现代大模型的选择
近年来,随着深度学习技术的飞速发展,激活函数的选择在神经网络设计中变得越来越重要。传统的ReLU(Rectified Linear Unit)虽然简单高效,但在一些复杂任务中逐渐暴露出了局限性。为了应对这些问题,新的激活函数如 SiLU(Sigmoid Linear Unit)和 GeLU(Gaussian Error Linear Unit)开始受到广泛关注,尤其是在现代大型语言模型(如Transformer架构)中频频亮相。那么,为什么这些激活函数会成为新宠?它们又有哪些优越的性质呢?本文将为你详细解析。
一、什么是SiLU和GeLU?
1. SiLU(Sigmoid Linear Unit)
SiLU 是由 Sigmoid 函数和线性变换结合而成的激活函数,公式如下:
SiLU ( x ) = x ⋅ σ ( x ) \text{SiLU}(x) = x \cdot \sigma(x) SiLU(x)=x⋅σ(x)
其中,( σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1) 是标准的 Sigmoid 函数。简单来说,SiLU 将输入 ( x x x) 与其通过 Sigmoid 函数的输出相乘。这种设计既保留了非线性特性,又引入了平滑性。
2. GeLU(Gaussian Error Linear Unit)
GeLU 则基于高斯分布的累积分布函数(CDF),其定义为:
GeLU ( x ) = x ⋅ Φ ( x ) \text{GeLU}(x) = x \cdot \Phi(x) GeLU(x)=x⋅Φ(x)
其中,( Φ ( x ) \Phi(x) Φ(x)) 是标准正态分布的累积分布函数。由于直接计算 ( Φ ( x ) \Phi(x) Φ(x)) 较为复杂,实践中通常使用近似公式:
GeLU ( x ) ≈ x ⋅ σ ( 1.702 x ) \text{GeLU}(x) \approx x \cdot \sigma(1.702x) GeLU(x)≈x⋅σ(1.702x)
或者更精确的近似:
GeLU ( x ) ≈ 0.5 x ( 1 + tanh ( 2 π ( x + 0.044715 x 3 ) ) ) \text{GeLU}(x) \approx 0.5x \left(1 + \tanh\left(\sqrt{\frac{2}{\pi}}(x + 0.044715x^3)\right)\right) GeLU(x)≈0.5x(1+tanh(π2(x+0.044715x3)))
GeLU 的灵感来源于高斯分布,因此它在处理输入时具有一定的概率特性。
二、为什么现代大模型选择SiLU和GeLU?
传统的激活函数如 ReLU 虽然计算简单,但在深度网络中容易导致“神经元死亡”(即部分神经元输出恒为0),从而限制模型的表达能力。相比之下,SiLU 和 GeLU 展现出了以下几个关键优势:
1. 平滑性与连续性
- ReLU 的问题:ReLU 在 ( x = 0 x = 0 x=0) 处不可导(导数不连续),这可能导致梯度更新不稳定,尤其是在深层网络中。
- SiLU 和 GeLU 的改进:两者都是平滑函数,导数连续,避免了 ReLU 的“硬切换”问题。这种平滑性有助于优化过程更加稳定,尤其是在训练超大规模模型时。
2. 非线性与动态范围
- SiLU 和 GeLU 都保留了非线性特性,但与 Sigmoid 或 Tanh 不同,它们不会将输出限制在一个狭窄的范围(如 [0,1] 或 [-1,1])。这使得它们更适合处理具有较大动态范围的输入数据。
- 例如,SiLU 在 ( x > 0 x > 0 x>0) 时近似于线性,而在 ( x < 0 x < 0 x<0) 时逐渐趋于 0,这种特性既保留了 ReLU 的稀疏性优势,又避免了完全截断负值。
3. 负值区域的处理
- ReLU 的局限:ReLU 对负值直接置零,可能丢弃部分有用信息。
- SiLU 和 GeLU 的优势:它们允许负值区域有一定的输出(尽管很小),这在某些任务中能更好地捕捉输入的细微特征。例如,GeLU 的负值输出基于高斯分布的概率特性,使得模型对负输入的响应更加“柔和”。
4. 与注意力机制的契合
现代大模型(如 BERT、GPT 等)广泛使用 Transformer 架构,而 Transformer 中的注意力机制对激活函数的平滑性和表达能力有较高要求。SiLU 和 GeLU 的设计恰好满足了这一点:
- SiLU:其 Sigmoid 加权机制与注意力分数的计算逻辑有一定相似性,能够增强模型对输入的加权处理能力。
- GeLU:其概率特性与注意力机制中的 softmax 操作有某种隐含的联系,使得它在 Transformer 中表现尤为出色。
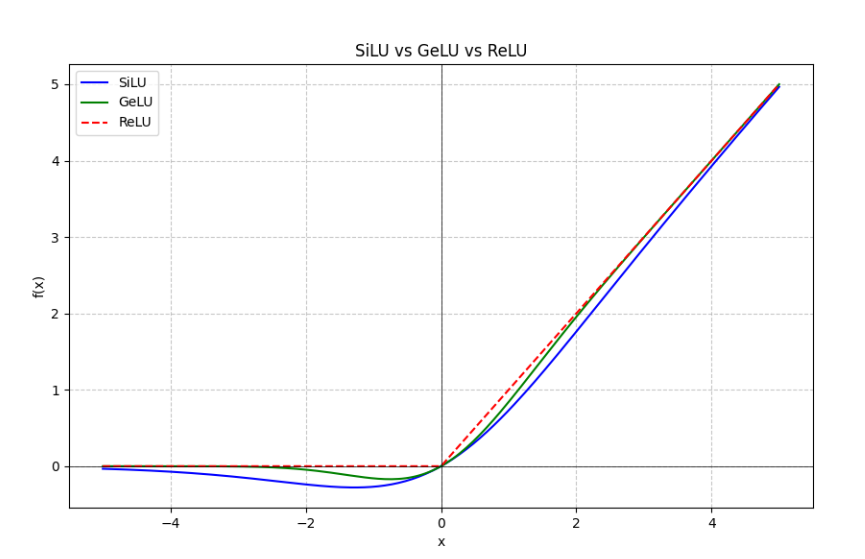
5. 图像
下面是使用 Python 和 Matplotlib 绘制 SiLU 和 GeLU 激活函数图像的代码。代码中定义了这两个函数,并在一个图中展示了它们的曲线,同时与 ReLU 进行对比。
import numpy as np
import matplotlib.pyplot as plt
# 定义激活函数
def silu(x):
return x / (1 + np.exp(-x))
def gelu(x):
# 使用近似公式
return 0.5 * x * (1 + np.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * x**3)))
def relu(x):
return np.maximum(0, x)
# 生成 x 值
x = np.linspace(-5, 5, 200)
# 计算对应的 y 值
y_silu = silu(x)
y_gelu = gelu(x)
y_relu = relu(x)
# 绘制图像
plt.figure(figsize=(10, 6))
plt.plot(x, y_silu, label='SiLU', color='blue')
plt.plot(x, y_gelu, label='GeLU', color='green')
plt.plot(x, y_relu, label='ReLU', color='red', linestyle='--')
plt.axhline(0, color='black', linewidth=0.5)
plt.axvline(0, color='black', linewidth=0.5)
plt.grid(True, linestyle='--', alpha=0.7)
plt.legend()
plt.title('SiLU vs GeLU vs ReLU')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.show()
运行这段代码后,你会看到一个包含 SiLU(蓝色)、GeLU(绿色)和 ReLU(红色虚线)的图像。SiLU 和 GeLU 的平滑性以及它们在负值区域的非零输出会非常直观地展示出来,而 ReLU 的“硬截断”特性也一目了然。
三、SiLU 和 GeLU 的具体性质
SiLU 的性质
- 平滑且无上界:SiLU 在正半轴上趋近于线性,而在负半轴上平滑衰减到 0,没有严格的上限。
- 自归一化倾向:由于 Sigmoid 的加权作用,SiLU 对输入有一定的“归一化”效果,有助于缓解梯度爆炸问题。
- 计算简单:虽然比 ReLU 多了一个 Sigmoid 计算,但现代硬件(如 GPU)对这种操作优化良好,计算开销可接受。
GeLU 的性质
- 概率特性:GeLU 的设计灵感来源于高斯分布,输出可以看作是对输入“保留”的概率加权结果。这种特性在随机丢弃(如 dropout)机制中有天然的契合。
- 非单调性:与 SiLU 不同,GeLU 在负值区域有微小的非单调行为(由于高斯分布的形状),这可能增加模型的表达能力。
- 广泛验证:GeLU 在 BERT 等模型中的成功应用证明了它在大规模预训练任务中的优越性。
四、SiLU 和 GeLU 的对比
| 特性 | SiLU | GeLU |
|---|---|---|
| 定义 | ( x ⋅ σ ( x ) x \cdot \sigma(x) x⋅σ(x)) | ( x ⋅ Φ ( x ) x \cdot \Phi(x) x⋅Φ(x)) |
| 平滑性 | 平滑且连续 | 平滑且连续 |
| 负值处理 | 平滑趋于 0 | 小幅保留负值信息 |
| 计算复杂度 | 较低 | 稍高(需近似计算) |
虽然两者在性质上有相似之处,但 GeLU 更偏向于概率加权,而 SiLU 则更注重平滑性和计算效率。选择哪种激活函数通常取决于具体任务和模型架构。
五、实际应用与未来展望
- SiLU 的应用:SiLU 在 Swin Transformer 等视觉模型中表现出色,其简单高效的特点使其逐渐成为 ReLU 的替代者。
- GeLU 的应用:GeLU 最早在 BERT 中被提出,随后在 GPT 等语言模型中得到广泛应用,证明了它在自然语言处理领域的强大能力。
未来,随着模型规模的进一步扩大和任务复杂度的提升,激活函数的设计可能会更加多样化。SiLU 和 GeLU 的成功或许只是一个开始,研究者们可能会基于它们的优点开发出更高效、更具针对性的变体。
六、总结
SiLU 和 GeLU 之所以能在现代大模型中脱颖而出,归功于它们的平滑性、非线性、负值处理能力以及与注意力机制的良好契合。相比传统的 ReLU,它们在深层网络中能够提供更稳定的梯度传播和更强的表达能力。如果你正在设计一个新的神经网络,不妨尝试将 SiLU 或 GeLU 融入其中,或许会带来意想不到的性能提升!
后记
2025年3月26日19点52分于上海,在grok 3大模型辅助下完成。