Redis原理:为什么要rehash
在 Redis的数据结构(一),有提到Redis的dict结构中,有两个dictEntry的数组

之前只是提到,它是作为rehash时使用的,那为什么需要rehash呢?
Redis是作为一个字典表存在的,它是基于hash表进行查找数据的
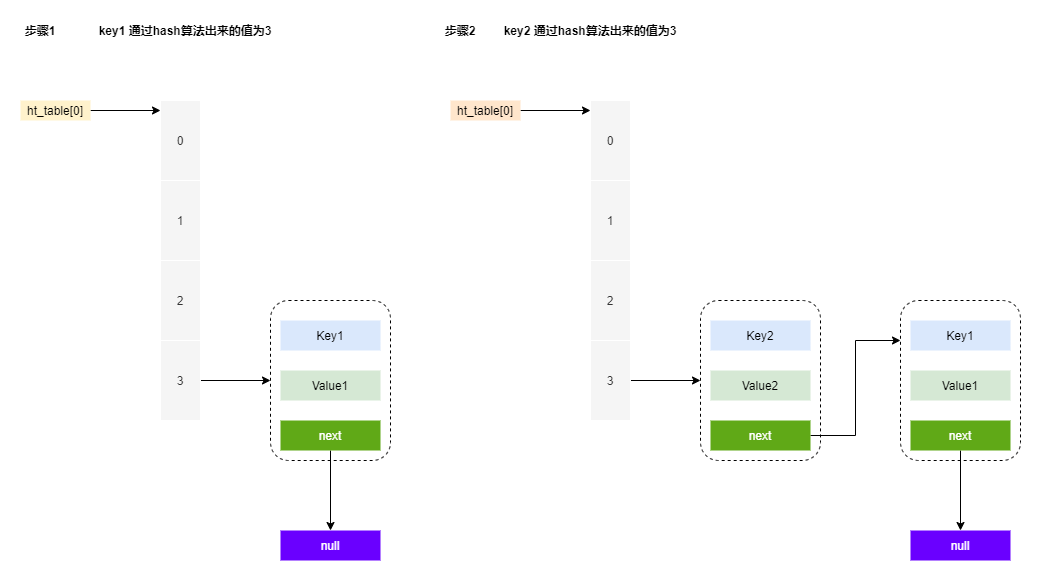
那它的查找方式基于以下的步骤
- 通过hash算法,获取在当前hash表中的位置,时间复杂度 O(1)
- 如果有hash冲突,则遍历当前的位置的各个dictEntry,比对相应的值,时间复杂度为 O(N)
为什么会有O(N)的出现呢,因为hash算法会存在hash碰撞,当出现hash碰撞时,redis 通过使用链表的方式来存储对应的键值,如果熟悉Java中的HashMap的算法,其中的原理是类似的。
那要解决的问题,主要是尽量使hash 碰撞的概率减小,解决方案便是进行hash表的扩容。而上面提到的两个ht_table表就是为了在扩容或是缩容时使用的。来看下具体的源码
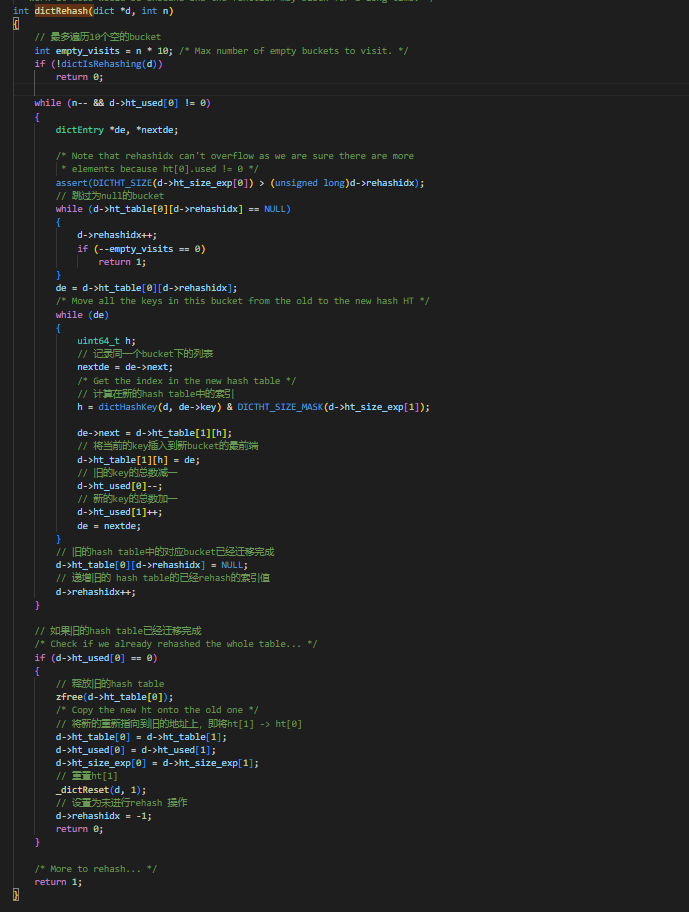
- rehash 的过程是从ht_table[0]中,按索引的位置,将该bucket中的列表逐个迁移到ht_table[1]中,这也是为了防止在迁移过程中长时间的阻塞导致redis不可用,并不是一次性进行迁移的,而是渐进式的
- 更新ht_table[0] 的 rehashidx的值
- 在ht_table[0]迁移完成后,会释放ht_table[0],同时重新将ht_table[1] 设置为 ht_table[0]
既然在rehash的过程,会将数据分散在两个表中,那在查找、新增、删除时是如何处理呢?来看下获取对应key的过程
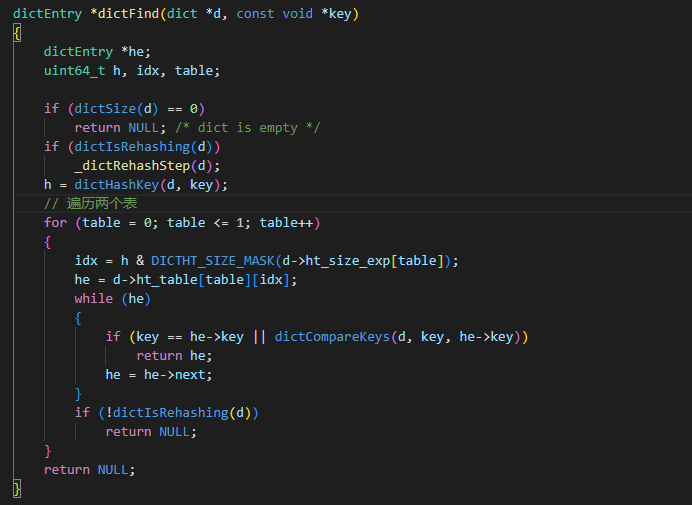
这里会分别在两个ht_table中进行查找。
而新增呢?
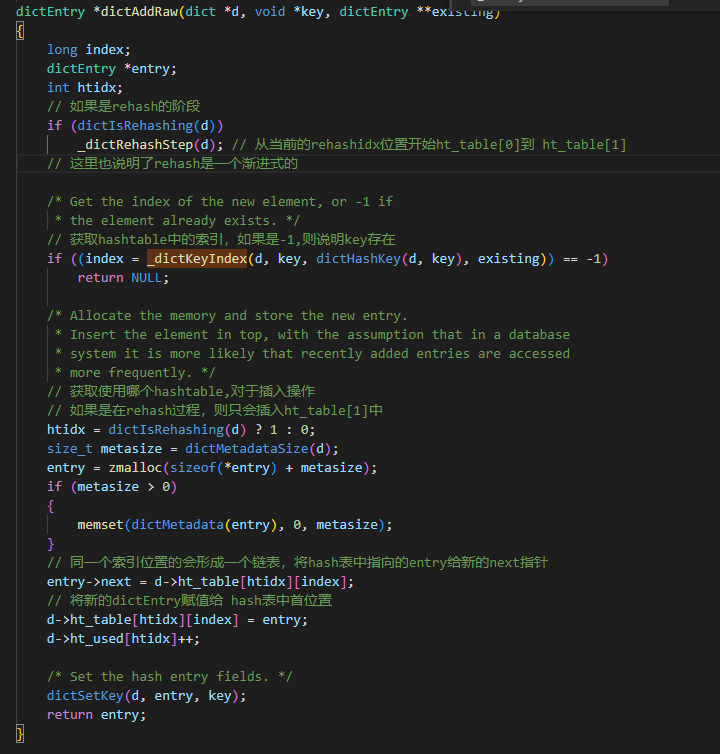
从以上逻辑可以知道,当在插入时,只会插入到ht_table[1]中。
既然 rehash 是为了解决hash冲突的问题,那什么时候会触发呢?
在上面的流程里,有调用 _dictExpandIfNeeded 方法
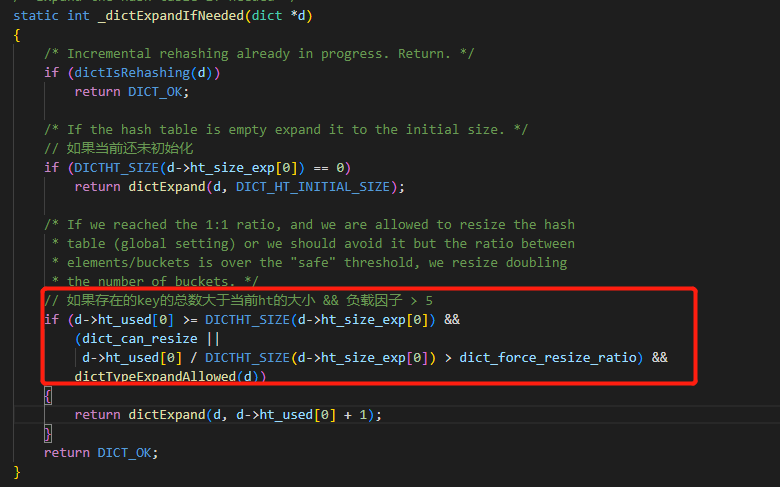
这里可以总结下扩容的时机点:
- 未初始化,会进行初始化第一个ht_table
- 当key的总数大于hashtable的大小,接近1:1 时,并且 dict_can_resize为1 或是 负载因子大于5时
- 扩容规则是找到大于当前key的总数的最小2的指数倍
- 扩容以后,会将dict中的rehashidx的值会被置为0
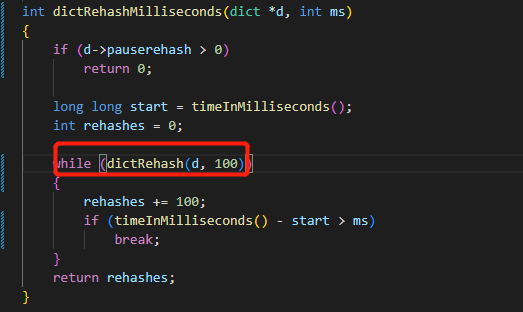
扩容以后,后台线程(1秒钟执行10次)检查是否在扩容后,需要rehash,如果需要,则会调用以下的方法
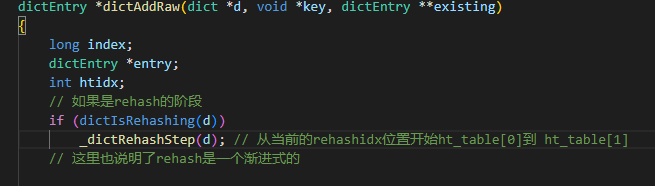
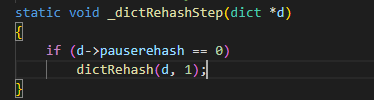
或是新增、删除key时判断是需要rehash,之后会调用 _dictRehashStep进行迁移一个bucket
总结
Redis的rehash 是为了解决hash冲突带来的性能问题,将原来紧凑的数据分布,进行松散分布,可以使key的查找尽可能达到O(1)