s1: Simple test-time scaling 【论文阅读笔记】
s1: Simple test-time scaling
关于test-time scaling
这个概念其实是相对 train scaling而言的。train scalling 指的是增加训练数据,增加训练flops等等,投入更多资源在train上。test-time scaling,其实现在简化点的理解,就是
显式或者隐藏的要求模型在decoding的过程中多探索,多思考。
可以参考 HuggingFace上的一篇blog
另外蚂蚁有一篇综述类的文章
一句话总结
本文用了1000个样本训练一个32B模型(是的,还是Qwen2.5-32B),使得模型可以被【强制结束】和【强制继续】(插入Wait这个词的token)这两种方式控制生成长度,进而做到<budget forcing>
但是作者没说什么问题适合多少budget。
关键细节
1. 数据集怎么选严重影响对模型budget 的可控性
首先1000个最终样本是从6W个样本的池子里选的。说了选数据集时候考虑的三个要素 <质量>,<难度>和 <多样性>。
除了AIME Olympic这些经典难数据集以外,Standford就是不一样啊,把博士生的入学数学考给弄进来了。
推理的Trace是用 Google Gemini Flash Thinking API 生成的(没有其他的API是因为啥呢)
怎么算<质量好>:格式没问题,有正确连接引用等,规则卡的
怎么算<难>:拿Qwen7B和Qwen32B解一遍,解法步骤长的更难。俩模型都会解的,算简单。
怎么算<多样>:也是用的问题的领域(数学与其他领域的交叉问题),先做分类,再做分层抽样
单就筛选细节这部分,其实跟LIMO的思路没啥差别。
关于LIMO的笔记可以看 我之前关于LIMO的笔记
2. 跟其他一些Test-time Scaling的方法比较
文章选的对比组有这几个
指定生成长度 (Token-conditional control):在提示中指定生成的最大token数(如2048 tokens),期望模型控制生成长度。
指定最大推理步数(Step-conditional control):指定生成的最大步骤数(如64 steps),每步约100 tokens。
指定长思考/短思考 (Class-conditional control):通过通用提示(如“短时间思考”或“长时间思考”)控制生成长度。
拒绝采样 (Rejection sampling):通过多次采样直到生成结果符合预设计算预算(如长度限制),近似后验分布。
下面这张图对比budget forcing和其他方案的可控性,生成长度和正确率的斜率关系(scaling这列)和在AIME上的效果。
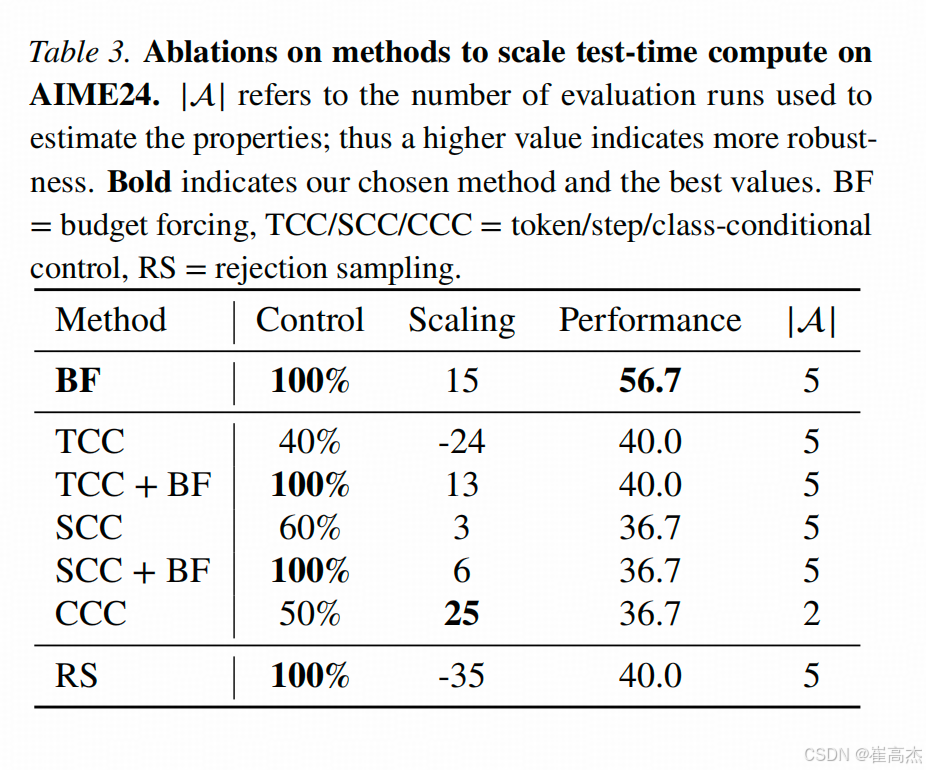
单从这个效果上看,其他方法惨败。要不然就是控制成功率上不来,要不然就是长了之后效果更拉了。
这个表格有个问题,没有明确说明这里比较的模型是S132B w/o BF。但问题在于,S132B做了训练,虽然引入了非常强的样本,但同时也加入了和BF相关的Token,这样对其他方法来说,在控制成功率这点上就已经不公平了。不过这个问题还是留给作者和评审在Rebuttal阶段讨论吧。总之,这个表格里的control和Performance两列的可信度都需要打点折扣。
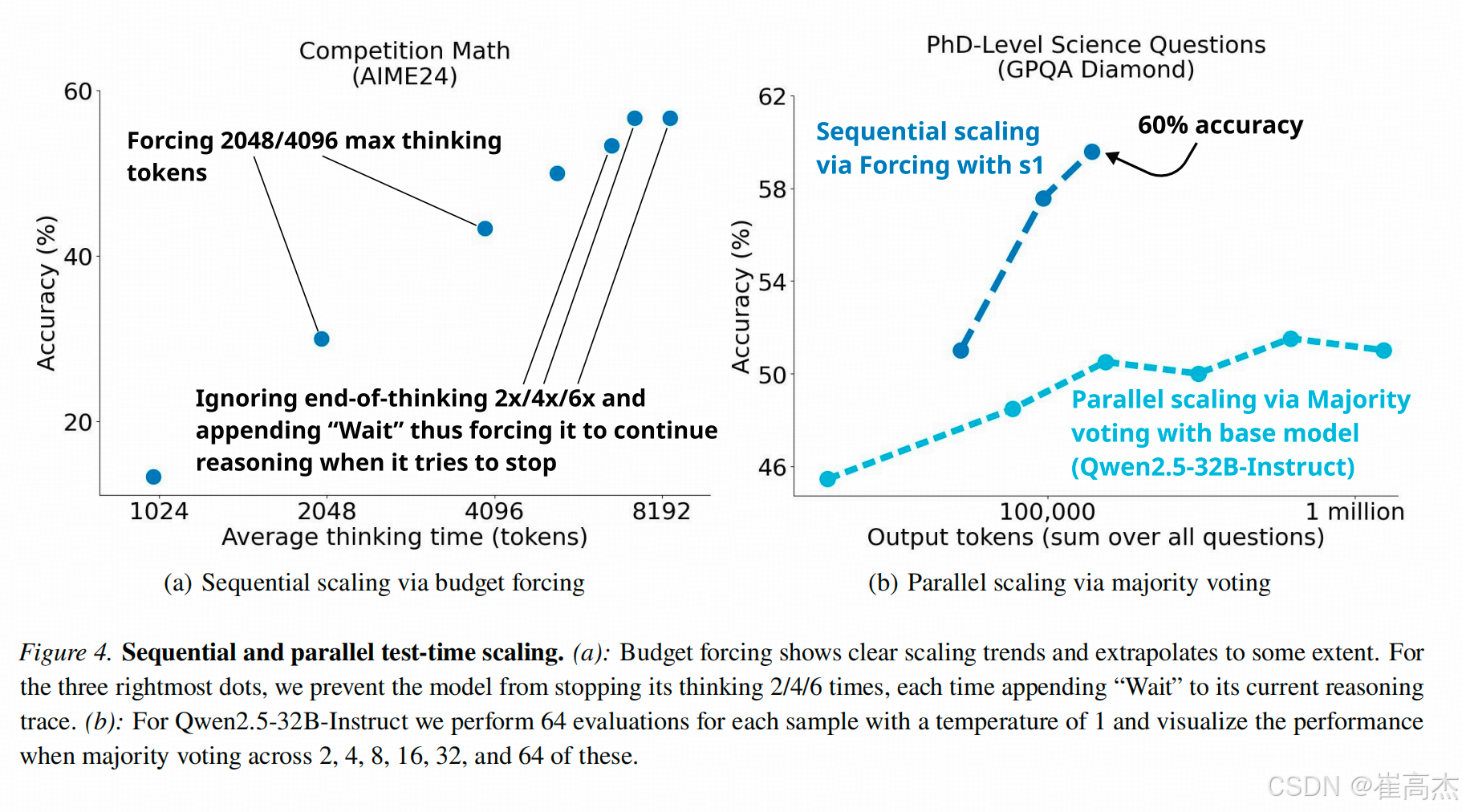
其实这里“scaling”的含义就比较明显了:“S132B的思考步长越长,难题的准确率就越高”(就是忘了deepseek和其他几个工作在这个数据集上的数了)
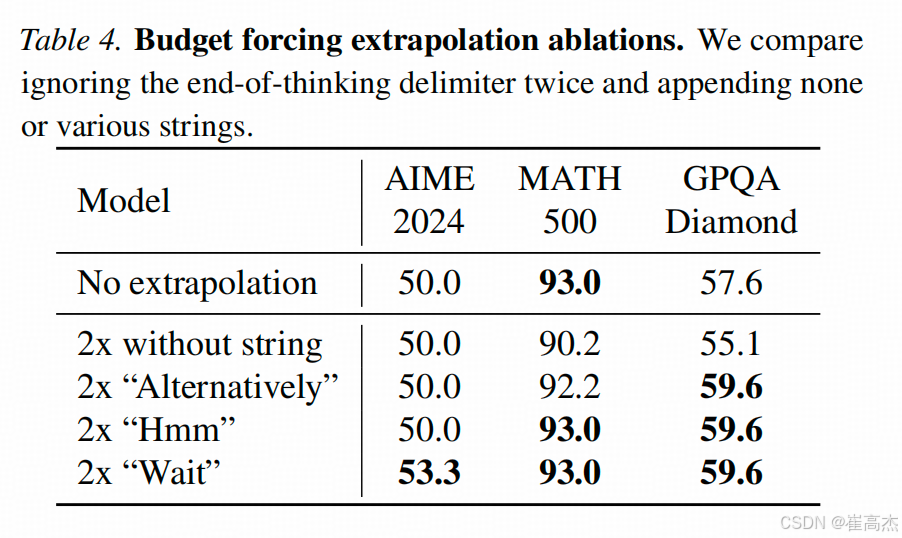
3. Wait这个词有“奇效”?
作者比较了用什么词要求延长思考过程,思考的质量更高。这个表比较了几个词的效用,“Wait”稍好。
评价
1. 高质量的训练数据对能力的影响占了实验的大头
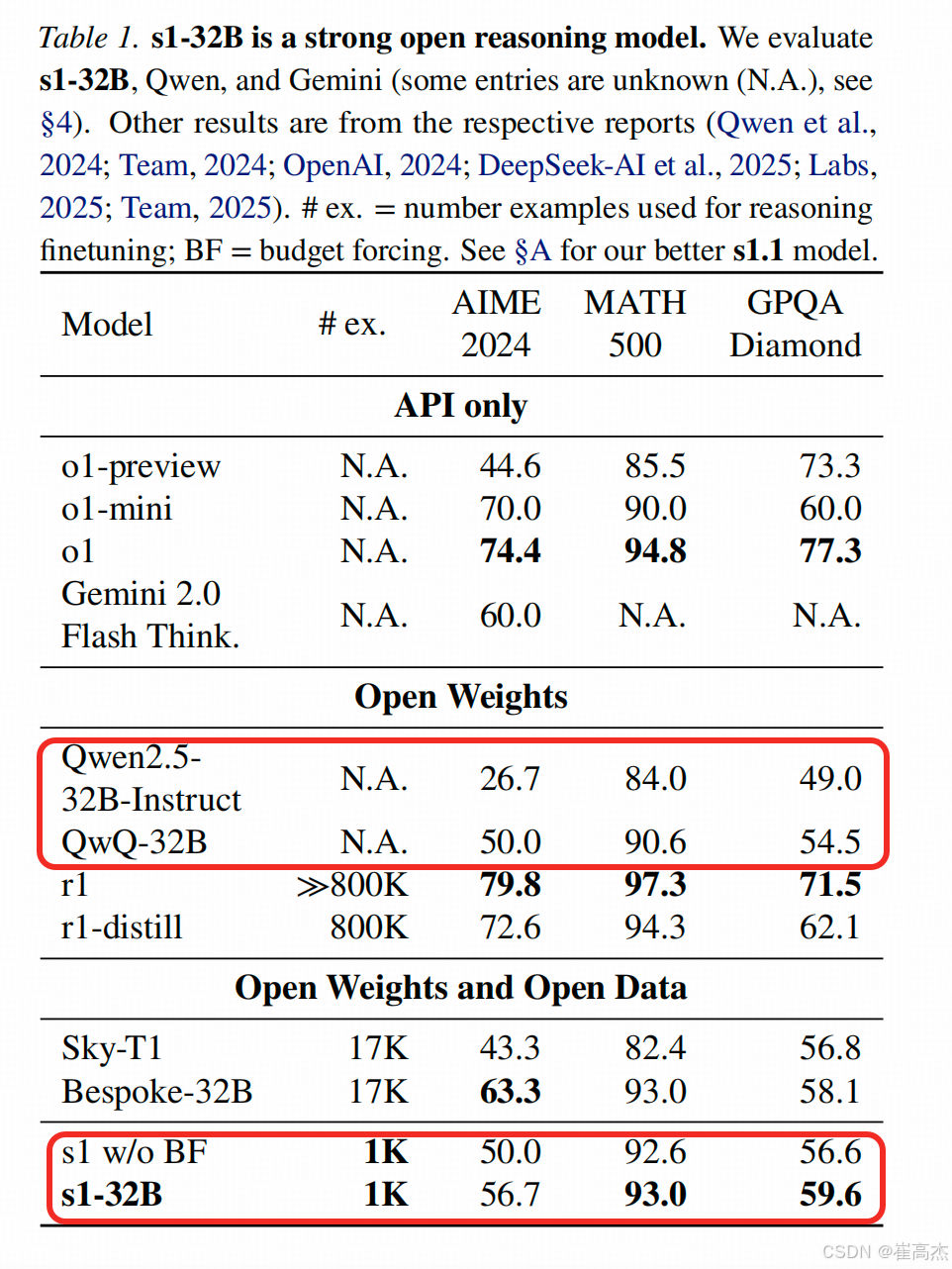
比较table1 中我画红框的地方,可以看到
S1-32B训练前(Qwen32B-Instruct)==> 是26/84/49
训练后 ==>是50/90/54
用了显示的BF==>是56/93/59
同时QwQ-32B ==> 是50/90/54.5
没有找到对QwQ-32B做BF和w/o BF 的实验,这样这个逻辑链路就不是很清楚。
只能验证用高质量难数据训练出来的推理模型在难题上的性能有显著飞跃,但test-time scaling 的效果没有那么明显。
2. 没有继续深入研究合理的推理步骤
没有深入推理步骤是指,<没有说到底什么问题限制多长效果最好 >,能做可控scaling的下一个最naive的想法,希望是作者下一个研究能cover一些。
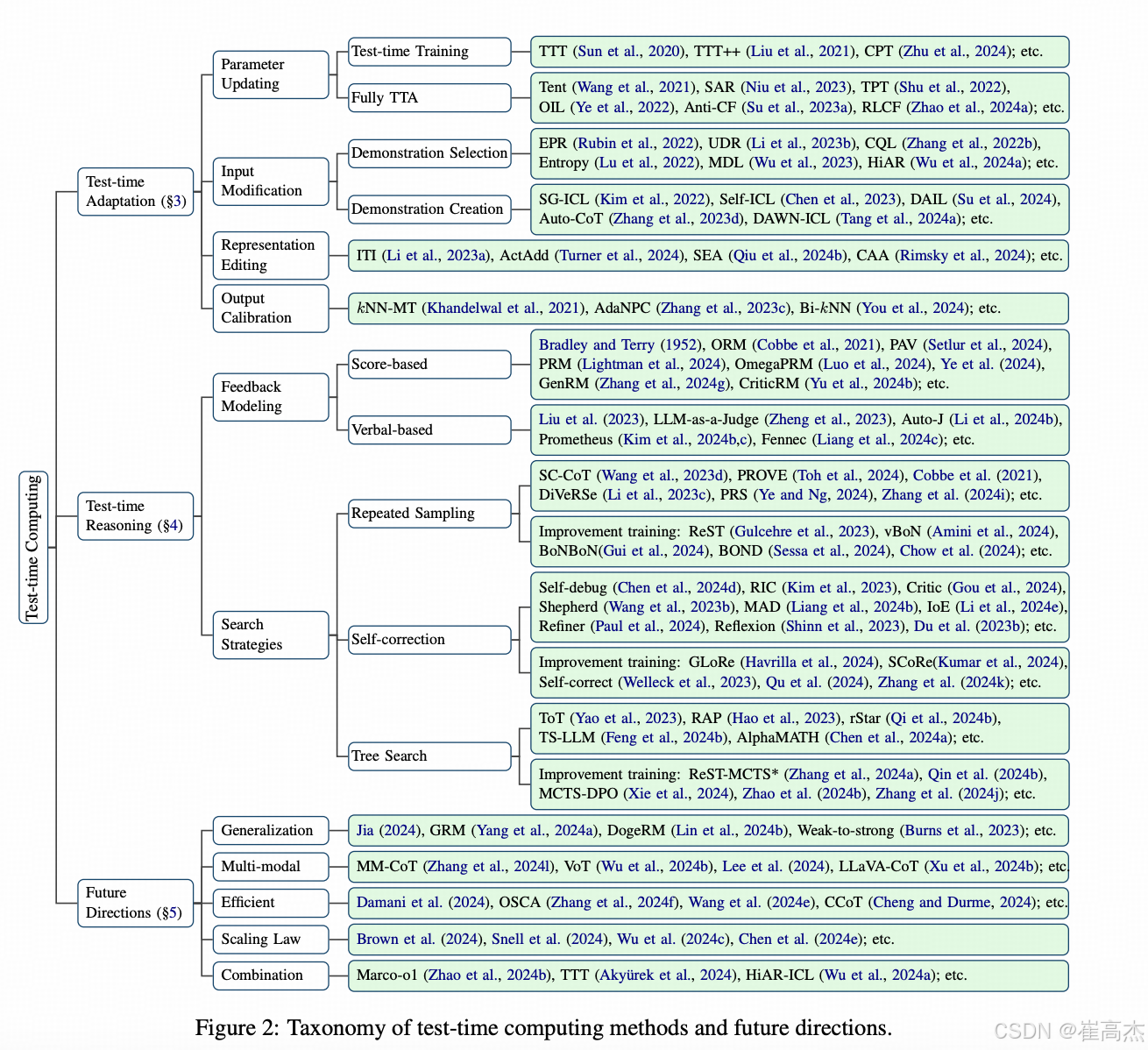
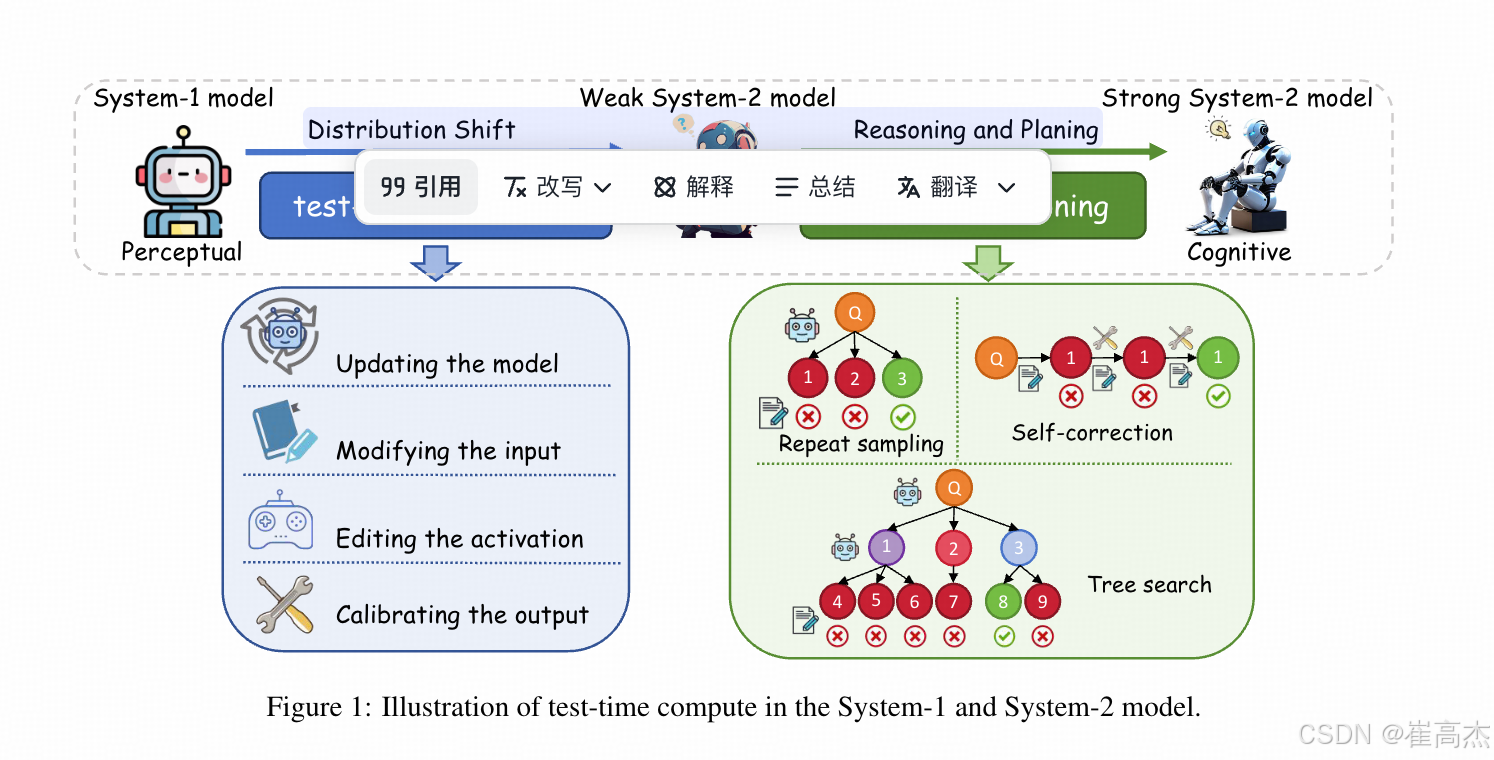
附赠一张 蚂蚁的Survey给出来的图,挺好的
虽然比较好,但是方法其实也不全,总体来说两种思路,一种是在生成的步骤上【横向】增加运算budget,一种是在生成的过程中【纵向】生成上增加budget(我说的这两种就是本篇(Simple test-time scaling)的分类方法
附赠Google的一篇的思路
原文是 SETS: Leveraging Self-Verification and Self-Correction for Improved Test-Time Scaling 图画的挺好,基本上是一个横向加纵向的方案(虽然看起来有点笨(*/ω\*))
