AI知识补全(四):微调 Fine-tuning 是什么?
名人说:人生如逆旅,我亦是行人。 ——苏轼《临江仙·送钱穆父》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
上一篇:AI知识补全(三):RAG 检索增强生成是什么?
目录
- 一、微调(Fine-tuning)基础概念
- 1. 什么是微调
- 2. 微调与从头训练的区别
- 3. 微调的重要性与应用场景
- 二、微调的工作原理
- 1. 预训练-微调范式的技术基础
- 2. 参数冻结与选择性训练
- 3. 学习率设置与其重要性
- 三、微调的常见技术与策略
- 1. 全参数微调 (Full Fine-tuning)
- 2. 参数高效微调 (Parameter-Efficient Fine-tuning)
- - Adapter 方法
- - LoRA(低秩适应)
- - Prompt Tuning 和 P-Tuning
- 3. 领域适应性微调 (Domain Adaptation)
- 四、实战案例:BERT模型微调
- 1. 任务描述与数据准备
- 2. 微调代码实现
- 3. 结果分析与性能评估
- 五、微调最佳实践与常见问题
- 1. 过拟合问题及解决方案
- 2. 训练资源优化
- 3. 微调效果评估方法
- 六、前沿发展与未来趋势
- 1. 大模型的微调技术
- 2. 少样本学习与微调
- 3. 微调在各行业的创新应用
- 小结:微调过后,是新的开始
很高兴你打开了这篇博客,更多AI知识,请关注我、订阅专栏《AI大白话》,内容持续更新中…
作为深度学习领域的关键技术,微调(Fine-tuning)已成为高效开发人工智能应用的重要方法。本文将以通俗易懂的方式,带领您全面了解微调技术的原理、方法和实践,帮助您快速掌握这一强大的模型优化方式。
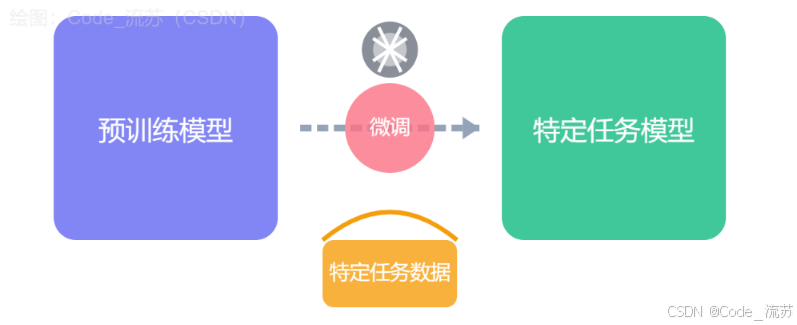
一、微调(Fine-tuning)基础概念
1. 什么是微调
微调是一种迁移学习技术✅,它利用在大规模数据上预先训练好的模型,通过额外的训练使其适应特定任务或领域。
微调的流程大概如下图所示:

简单来说,微调就像是在一位已经掌握了广泛知识的"专家"基础上,对其进行专项"补课",使其能更好地解决特定问题。
2. 微调与从头训练的区别
从头训练模型需要大量数据和计算资源,而且训练时间长。相比之下,微调有以下明显优势:
1️⃣训练效率高:微调只需调整部分参数,训练时间更短
2️⃣所需数据少:通常只需要少量特定领域数据
3️⃣性能更好:预训练的知识能帮助模型更好地泛化到新任务
4️⃣资源要求低:计算资源需求大幅降低

3. 微调的重要性与应用场景
微调技术的出现彻底改变了深度学习的应用方式,使得AI技术的落地变得更加高效。主要应用场景包括:
- 自然语言处理:情感分析、文本分类、命名实体识别等
- 计算机视觉:图像分类、目标检测、图像分割等
- 语音识别:特定领域的语音转文本系统
- 医疗诊断:基于医疗图像的疾病检测
- 推荐系统:个性化推荐算法的优化
二、微调的工作原理
1. 预训练-微调范式的技术基础
预训练-微调范式的核心在于知识迁移。在预训练阶段,模型学习通用表示和特征;而在微调阶段,模型利用这些知识来解决特定任务。
2. 参数冻结与选择性训练
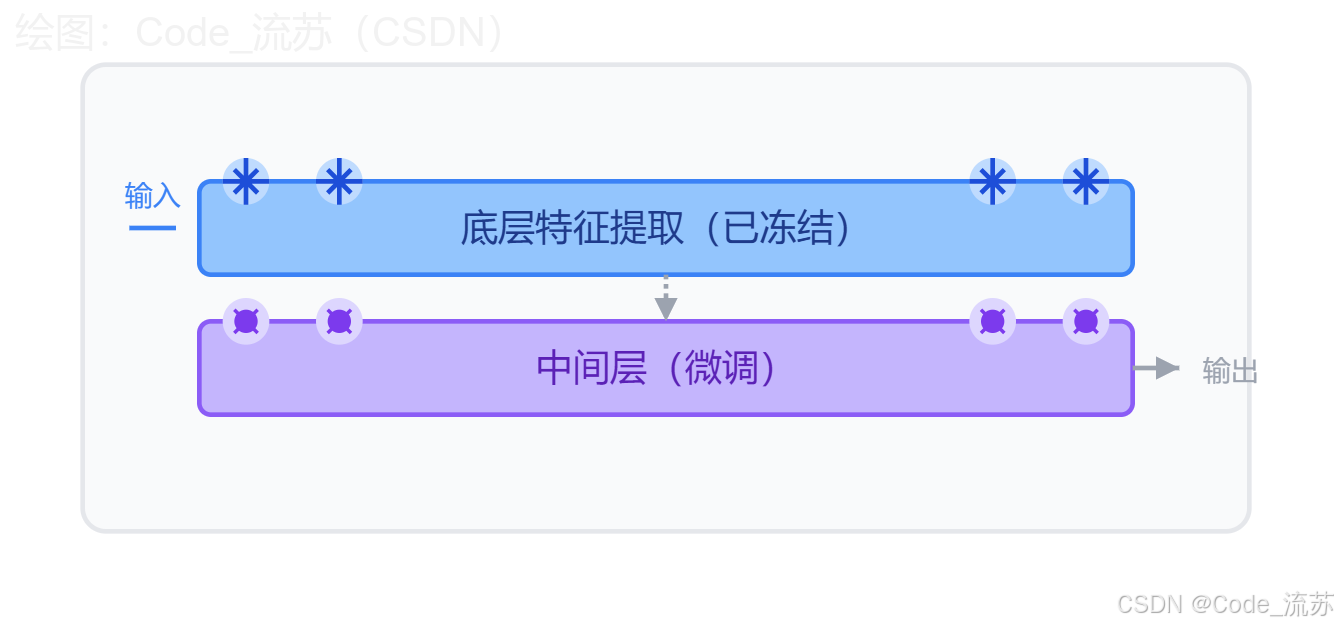
预训练模型通常包含了多层神经网络结构,在微调时,会采取两种主要参数操作策略:
- 全参数微调:调整模型中的所有参数,适应新任务
- 选择性参数微调:冻结底层特征提取层,只训练上层任务相关的参数,这样更高效且不易过拟合
3. 学习率设置与其重要性
微调过程中,学习率设置至关重要:
- 太大的学习率会使模型不稳定或破坏预训练知识
- 太小的学习率会导致训练效率低下
- 最佳实践:通常使用比初始训练更小的学习率(如原始学习率的1/10)
- 学习率衰减策略能帮助模型更好地收敛
三、微调的常见技术与策略
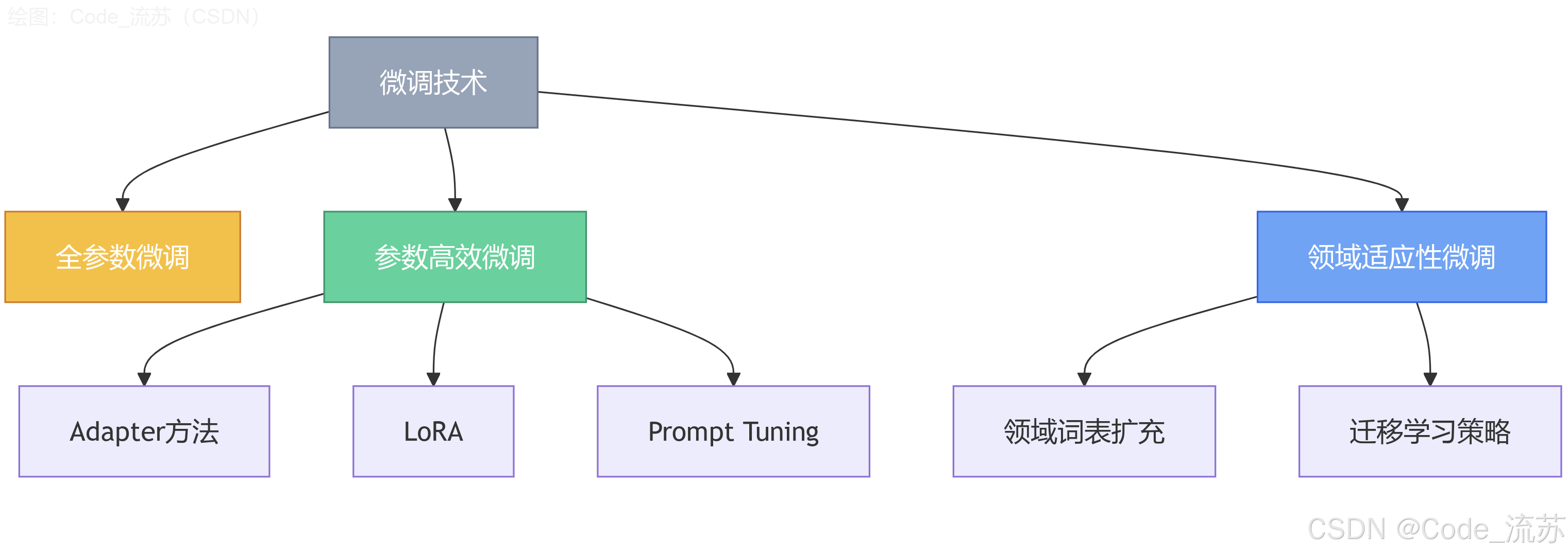
1. 全参数微调 (Full Fine-tuning)
全参数微调是最直接的微调方法,调整模型中的所有参数以适应新任务。这种方法通常能够获得最佳性能,但也需要更多的计算资源和数据。
# PyTorch中的全参数微调示例 (以BERT为例)
from transformers import BertForSequenceClassification, Trainer, TrainingArguments
# 1. 加载预训练模型
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=2)
# 2. 设置训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
learning_rate=5e-5, # 较小的学习率
weight_decay=0.01,
logging_dir='./logs',
)
# 3. 训练模型
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
trainer.train()
2. 参数高效微调 (Parameter-Efficient Fine-tuning)
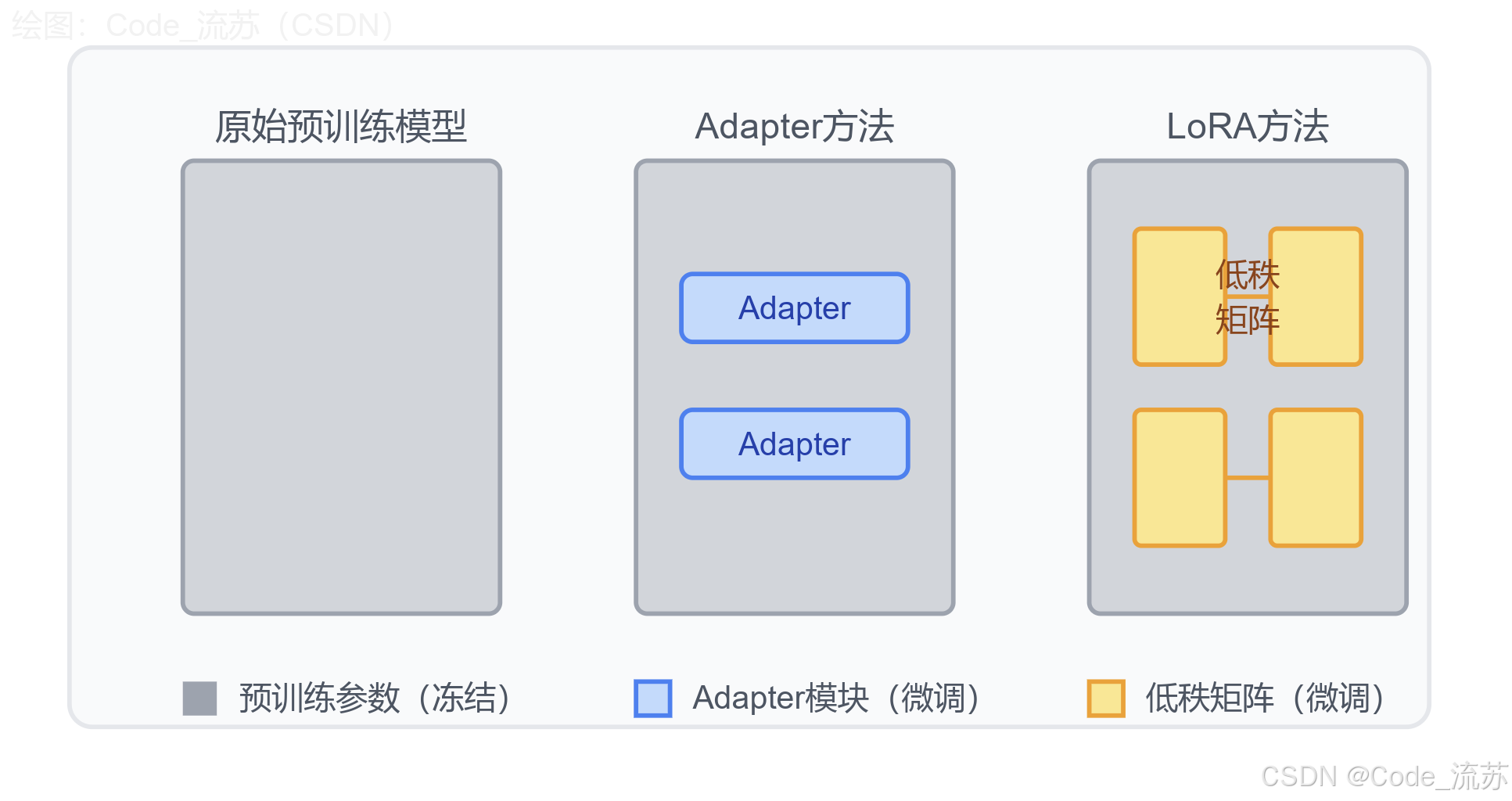
参数高效微调技术通过只调整少量参数来适应新任务,大大降低了计算和存储开销,主要包括以下方法:
- Adapter 方法
Adapter方法在预训练模型的层与层之间插入小型可训练模块,只训练这些新增模块,保持原始模型参数不变。
# 使用Hugging Face的PEFT库实现Adapter微调
from transformers import AutoModelForSequenceClassification
from peft import get_peft_config, get_peft_model, TaskType, AdapterConfig
# 1. 加载预训练模型
model = AutoModelForSequenceClassification.from_pretrained("bert-base-chinese", num_labels=2)
# 2. 定义Adapter配置
peft_config = AdapterConfig(
task_type=TaskType.SEQ_CLS,
reduction_factor=16, # 降维因子,决定Adapter模块的大小
inference_mode=False
)
# 3. 创建PEFT模型
peft_model = get_peft_model(model, peft_config)
# 打印可训练参数量
trainable_params = sum(p.numel() for p in peft_model.parameters() if p.requires_grad)
total_params = sum(p.numel() for p in peft_model.parameters())
print(f"可训练参数: {trainable_params} ({100 * trainable_params / total_params:.2f}% of {total_params})")
- LoRA(低秩适应)
LoRA通过将预训练权重矩阵的更新分解为低秩矩阵的乘积,大幅减少了可训练参数的数量,特别适合大型语言模型的微调。
# 使用PEFT库实现LoRA微调
from peft import LoraConfig, get_peft_model
# 1. 定义LoRA配置
lora_config = LoraConfig(
r=8, # 低秩维度
lora_alpha=32, # 缩放因子
target_modules=["query", "key", "value"], # 目标模块
lora_dropout=0.1,
bias="none",
task_type=TaskType.SEQ_CLS
)
# 2. 创建PEFT模型
peft_model = get_peft_model(model, lora_config)
- Prompt Tuning 和 P-Tuning
这些方法通过调整或优化提示(prompt)来适应下游任务,只需要训练少量的嵌入参数。
3. 领域适应性微调 (Domain Adaptation)
领域适应性微调专注于将模型从源领域(如通用文本)调整到特定目标领域(如医学、法律等专业文本)。
# 领域适应性微调的一般步骤
# 1. 收集目标领域数据
# 2. 调整预训练模型的词表(可选)
# 3. 在领域数据上继续预训练
# 4. 在特定任务上进行微调
from transformers import BertForMaskedLM, DataCollatorForLanguageModeling
from transformers import Trainer, TrainingArguments
# 加载预训练模型
model = BertForMaskedLM.from_pretrained('bert-base-chinese')
# 设置训练参数
training_args = TrainingArguments(
output_dir='./domain_adapted_model',
num_train_epochs=5,
per_device_train_batch_size=8,
save_steps=10_000,
save_total_limit=2,
)
# 数据整理器
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=True,
mlm_probability=0.15
)
# 训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=domain_dataset,
data_collator=data_collator,
)
trainer.train()
四、实战案例:BERT模型微调
1. 任务描述与数据准备
让我们以中文情感分析为例,微调BERT模型来对电影评论进行情感分类(正面/负面)。
# 数据准备
import pandas as pd
from sklearn.model_selection import train_test_split
from transformers import BertTokenizer
# 加载数据集
df = pd.read_csv('movie_reviews.csv')
texts = df['review'].tolist()
labels = df['sentiment'].tolist() # 0为负面,1为正面
# 划分训练集和验证集
train_texts, val_texts, train_labels, val_labels = train_test_split(
texts, labels, test_size=0.2, random_state=42
)
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
# 处理数据集
def process_data(texts, labels):
encodings = tokenizer(texts, truncation=True, padding=True, max_length=128)
dataset = []
for i in range(len(texts)):
item = {key: val[i] for key, val in encodings.items()}
item['labels'] = labels[i]
dataset.append(item)
return dataset
train_dataset = process_data(train_texts, train_labels)
val_dataset = process_data(val_texts, val_labels)
2. 微调代码实现
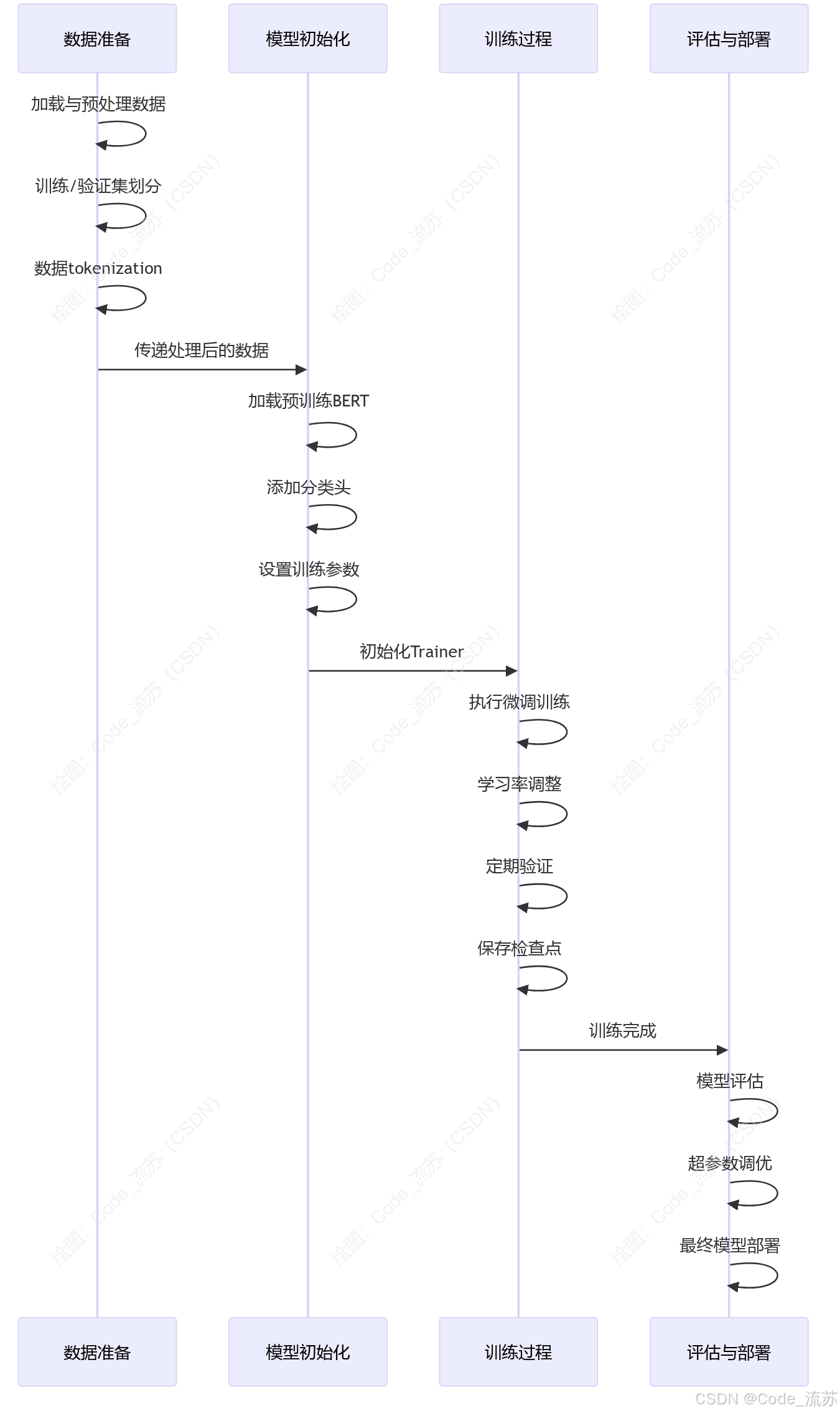
现在我们来以BERT模型的微调为例:
from transformers import BertForSequenceClassification, Trainer, TrainingArguments
from datasets import load_metric
import numpy as np
from torch.utils.data import Dataset
# 自定义Dataset类
class SentimentDataset(Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
# 处理数据
train_encodings = tokenizer(train_texts, truncation=True, padding=True, max_length=128)
val_encodings = tokenizer(val_texts, truncation=True, padding=True, max_length=128)
train_dataset = SentimentDataset(train_encodings, train_labels)
val_dataset = SentimentDataset(val_encodings, val_labels)
# 加载预训练模型
model = BertForSequenceClassification.from_pretrained(
'bert-base-chinese',
num_labels=2,
output_attentions=False,
output_hidden_states=False,
)
# 定义评估函数
metric = load_metric("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# 设置训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
logging_steps=10,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
metric_for_best_model="accuracy",
)
# 初始化Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics,
)
# 开始训练
trainer.train()
# 保存最终模型
model.save_pretrained("./chinese-sentiment-bert")
tokenizer.save_pretrained("./chinese-sentiment-bert")
3. 结果分析与性能评估
训练完成后,我们可以对模型进行评估:
# 在测试集上评估模型
results = trainer.evaluate()
print(f"评估结果: {results}")
# 对新数据进行预测
def predict_sentiment(text):
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True, max_length=128)
outputs = model(**inputs)
probs = torch.nn.functional.softmax(outputs.logits, dim=-1)
pred_class = torch.argmax(probs, dim=-1).item()
confidence = probs[0][pred_class].item()
sentiment = "正面" if pred_class == 1 else "负面"
return sentiment, confidence
# 测试几个样例
test_samples = [
"这部电影太棒了,情节紧凑,演员表演到位。",
"剧情平淡无奇,浪费了我两个小时的时间。",
"虽然开头有点慢,但后面的发展非常精彩。"
]
for sample in test_samples:
sentiment, confidence = predict_sentiment(sample)
print(f"文本: {sample}")
print(f"情感: {sentiment}, 置信度: {confidence:.2f}")
print("-" * 50)
五、微调最佳实践与常见问题
1. 过拟合问题及解决方案
微调过程中常见的过拟合问题可通过以下方法缓解:
- 使用正则化技术:如权重衰减、Dropout等
- 提前停止:当验证集性能开始下降时停止训练
- 数据增强:通过各种变换扩充训练数据
- 渐进式微调:先在大数据集上微调,再在小数据集上微调
2. 训练资源优化
针对资源受限的情况,可考虑:
- 使用参数高效微调方法(如LoRA、Adapter等)
- 降低精度训练(如使用FP16或INT8量化)
- 梯度积累:使用较小的批次大小但累积多步梯度
- 模型裁剪:去除不必要的模型组件
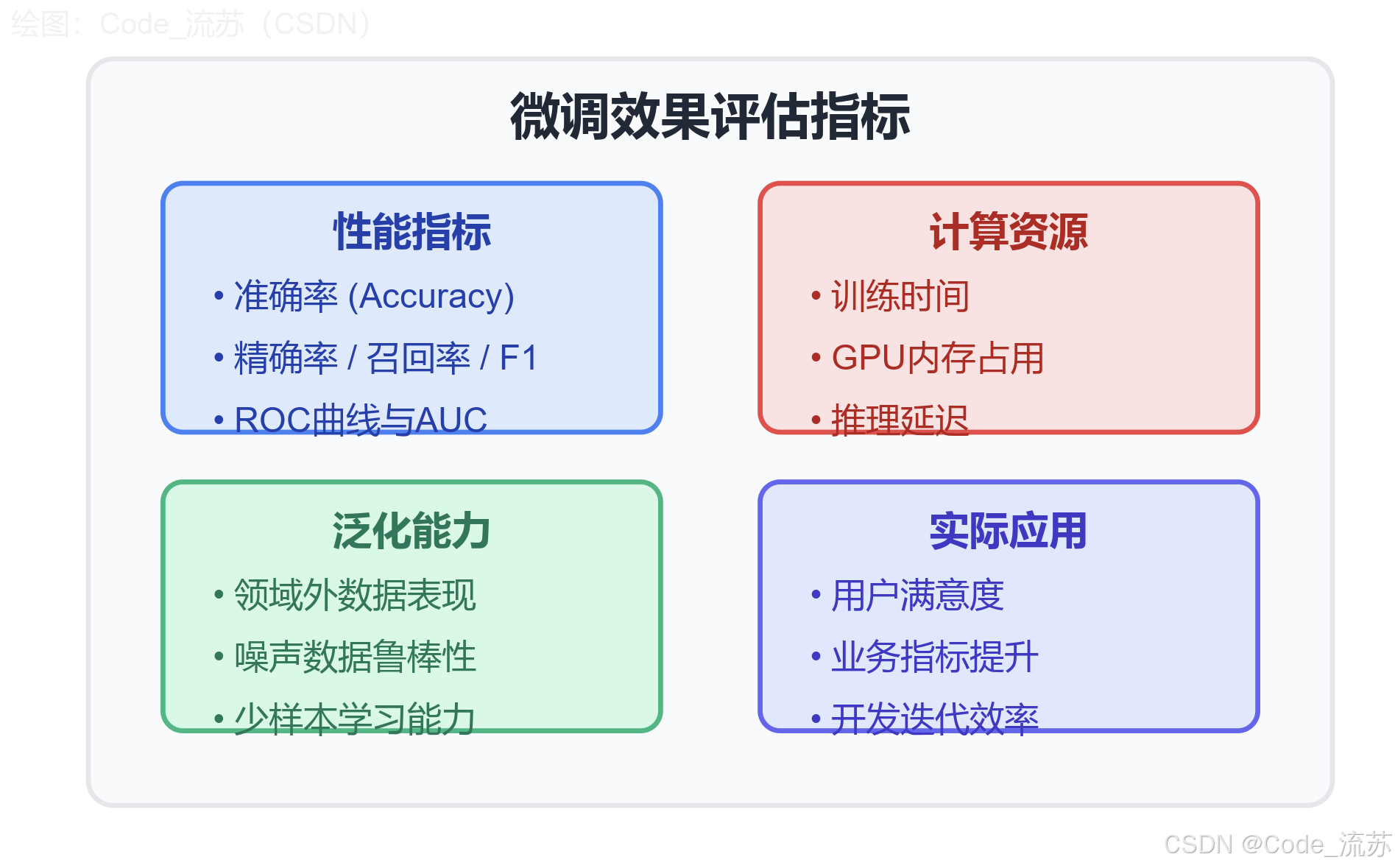
3. 微调效果评估方法
评估微调效果应注重以下几个方面:
- 性能指标:准确率、F1分数、ROC曲线等
- 泛化能力:在不同域数据上的表现
- 推理速度:实际应用中的响应时间
- 资源消耗:内存和计算开销
六、前沿发展与未来趋势
1. 大模型的微调技术
随着GPT、LLaMA等大语言模型的兴起,微调技术也在不断演进:
- 指令微调(Instruction Fine-tuning):使模型更好地遵循人类指令
- RLHF(基于人类反馈的强化学习):通过人类反馈进一步改进模型
- 量化微调(QLoRA):在量化模型上进行低秩适应微调,进一步降低资源需求
2. 少样本学习与微调
- Prompt Engineering:通过精心设计的提示引导模型理解任务
- In-context Learning:在上下文中提供少量示例,无需更新参数
- Meta-learning:训练模型快速适应新任务的能力
3. 微调在各行业的创新应用
微调技术已在各行业广泛应用:
- 医疗健康:医学影像分析、临床文本理解、药物研发
- 金融服务:智能投顾、风险评估、反欺诈系统
- 教育领域:个性化学习、智能批改、教育内容生成
- 智能制造:设备故障预测、生产优化、质量控制
小结:微调过后,是新的开始
微调技术已成为深度学习领域不可或缺的一部分,它使得AI模型的开发变得更加高效和可行。
通过对预训练模型进行针对性的调整,开发者可以用较少的资源和数据,快速构建出高性能的AI应用。随着技术的不断革新,微调方法正变得越来越高效和灵活,为AI的广泛应用创造了更好的条件。
无论您是AI研究者还是应用开发者,掌握微调技术都是提升工作效率的关键。希望本文的介绍能帮助您更好地理解和应用微调,为您的项目带来更多可能性!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)