哈希--哈希桶
哈希桶是哈希表(散列表)中的一个概念,是哈希表数组中的每个元素 ,用于存储键值对数据。它有以下特点和相关要点:
- 结构与原理:哈希表底层常由数组构成,数组的每个元素即哈希桶。通过哈希函数计算键的哈希值,该值作为索引指向对应的哈希桶。比如,用哈希函数
Hash(key)=key % 10计算键key的哈希值,就能确定其对应的哈希桶位置。 - 冲突处理:不同键经哈希函数计算后可能得到相同哈希值,即哈希冲突。常见的处理方式有:
- 链地址法:也叫开散列法,每个哈希桶维护一个链表(或其他可链接的数据结构)。冲突发生时,将新键值对添加到对应哈希桶的链表末尾。例如,多个键计算出的哈希值都对应数组的第 3 个位置,这些键值对就依次链接在该位置的链表上。
- 开放寻址法:不借助额外链表,所有键值对直接存于哈希表数组。冲突发生时,通过线性探测、二次探测或双重哈希等方式,在数组中找下一个空闲位置存储键值对。
- 负载因子与扩容:负载因子 = 填入表中元素的个数 / 散列表的长度,用于衡量哈希表的填充程度。负载因子过高会增加哈希冲突概率,影响性能。当达到预设阈值(如 0.75)时,通常会对哈希表进行扩容,创建更大容量的数组,并重新计算所有键的哈希值,将键值对迁移到新数组的哈希桶中 。
- 应用场景:广泛应用于需要快速查找、插入和删除数据的场景,如数据库索引、缓存系统、编程语言中的集合类(如 Java 的
HashMap、C++ 的unordered_map) 。像在电商系统中,可使用哈希桶快速查找商品信息;在编译器中,用于符号表的管理,快速查找变量和函数定义。
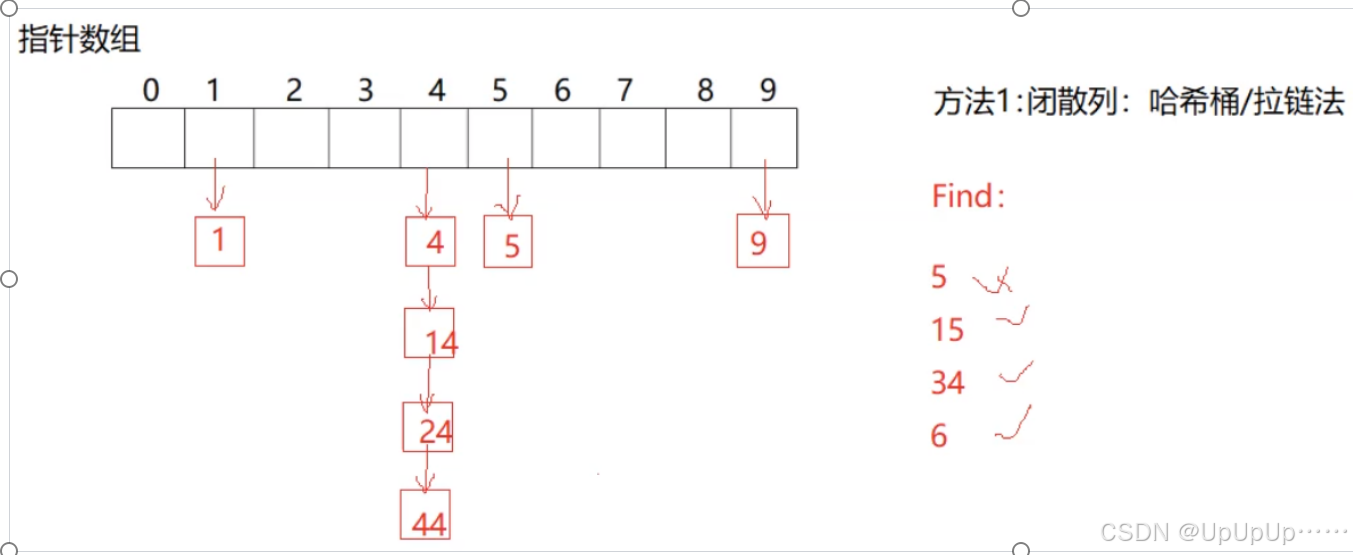
哈希桶的实现:
namespace hash_bucket
{
template<class K>
struct hashFunc
{
size_t operator()(const K& key)
{
return static_cast<size_t>(key);
}
};
template<>
struct hashFunc<string>
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (auto e : key)
{
hash *= 131;
hash += e;
}
return hash;
}
};
template<class K,class V>
struct HashNode
{
HashNode<K, V>* next;
pair<K, V> _kv;
HashNode() {};
HashNode(const pair<K,V>& kv):_kv(kv),next(nullptr){}
};
template<class K,class V,class Hash=hashFunc<K>>
class hashTables
{
using node = HashNode<K, V>;
//typedef HashNode<K, V> node;
public:
hashTables()
{
_tables.resize(10);
}
bool insert(const pair<K, V>& kv)
{
if (find(kv.first))
{
return false;
}
//下面是扩容,这里需要注意的是它的负载因子可以达到 1
/*if (_n == _tables.size())
{
size_t newsize = _tables.size() * 2;
hashTables<K, V> newTables;
newTables._tables.resize(newsize);
for (size_t i = 0; i < _tables.size(); i++)
{
node* cur = _tables[i];
while (cur)
{
newTables.insert(cur->_kv);
cur = cur->next;
}
}
_tables.swap(newTables._tables);
}*/
//这一段相比较上一段减少了insert调用,减少了开销!
if (_n == _tables.size())
{
vector<node*> newtables;
newtables.resize(_tables.size() * 2);
for (size_t i = 0; i < _tables.size(); i++)
{
node* cur = _tables[i];
while (cur)
{
node* next = cur->next;
size_t hashi = hs(cur->_kv.first) % newtables.size();
cur->next = newtables[hashi];
newtables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtables);
}
size_t hashi = hs(kv.first) % _tables.size();
node* newnode = new node(kv);
//头插
newnode->next = _tables[hashi];
_tables[hashi] = newnode;//更新头结点!
++_n;
}
node* find(const K& key)
{
size_t hashi =hs(key) % _tables.size();
node* cur = _tables[hashi];
while (cur)
{
if (cur->_kv.first == key)
{
return cur;
}
cur = cur->next;
}
return nullptr;
}
bool erase(const K& key)
{
size_t hashi =hs( key) % _tables.size();
node* cur = _tables[hashi];
node* prev = nullptr;
while (cur)
{
/*prev = cur;*/
if (cur->_kv.first == key)
{
if (prev==nullptr)//头删
{
_tables[hashi] = cur->next;
}
else//后续正常删
{
prev->next = cur->next;
}
delete cur;
return true;
}
prev = cur;
cur = cur->next;
}
return false;
}
~hashTables()
{
for (size_t i = 0; i < _tables.size(); i++)
{
node* cur = _tables[i];
while (cur)
{
node* next = cur->next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
void print()
{
for (size_t i = 0; i <_tables.size(); i++)
{
node* cur = _tables[i];
while (cur)
{
cout << "key: " << cur->_kv.first << "-> " << cur->_kv.second << endl;
cur = cur->next;
}
}
}
private:
vector<node*> _tables;//指针数组
size_t _n=0;
Hash hs;
};
}
void test_hush3()
{
hash_bucket::hashTables<int, int> h;
int a[] = { 1,2,3,4,5,6,7 };
for (auto e : a)
{
h.insert(make_pair(e, e));
}
h.insert({ 8,8 });
h.print();
h.erase(8);
h.print();
}头插的时候:

上面的代码要注意的是它的扩容,它直接重新申请一个数组链表,而不是像开放地址法一样,进行一个重新搞一个对象,然后在对象的新表里面进行挪动数据了。现在哈希桶的这个扩容方法减少了insert的调用!!!