【Linux】--- 线程互斥
【Linux】--- 线程互斥
- 一、线程互斥
- 1、进程线程间的互斥相关背景概念
- 2、互斥锁 mutex
- 3、互斥锁原理
- 二、常见的锁
- 1、死锁
- 2、自旋锁
- 3、其他锁
一、线程互斥
1、进程线程间的互斥相关背景概念

进程之间如果要进行通信我们需要先创建第三方资源,让不同的进程看到同一份资源,由于这份第三方资源可以由操作系统中的不同模块提供,于是进程间通信的方式有很多种。
进程间通信中的第三方资源就叫做:临界资源,访问第三方资源的代码就叫做临界区。
例如,下面我们模拟实现一个抢票系统,我们将记录票的剩余张数的变量定义为全局变量,主线程创建四个新线程,让这四个新线程进行抢票,当票被抢完后这四个线程自动退出。
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
int tickets = 1000;
void* TicketGrabbing(void* arg)
{
const char* name = (char*)arg;
while (1){
if (tickets > 0){
usleep(10000);
printf("[%s] get a ticket, left: %d\n", name, --tickets);
}
else{
break;
}
}
printf("%s quit!\n", name);
pthread_exit((void*)0);
}
int main()
{
pthread_t t1, t2, t3, t4;
pthread_create(&t1, NULL, TicketGrabbing, "thread 1");
pthread_create(&t2, NULL, TicketGrabbing, "thread 2");
pthread_create(&t3, NULL, TicketGrabbing, "thread 3");
pthread_create(&t4, NULL, TicketGrabbing, "thread 4");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
return 0;
}
运行结果显然不符合我们的预期,因为其中出现了剩余票数为负数的情况。
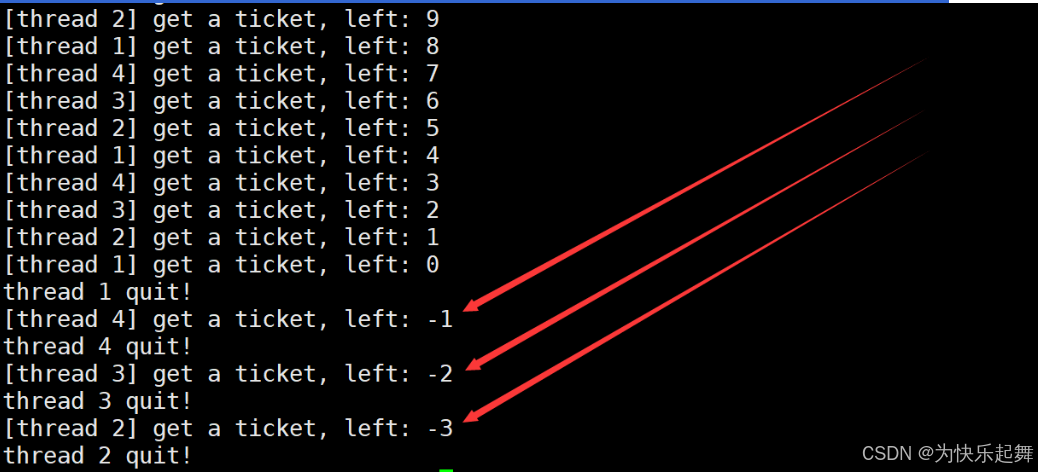
该代码中记录剩余票数的变量tickets就是临界资源,因为它被多个执行流同时访问,而判断tickets是否大于0、打印剩余票数以及–tickets这些代码就是临界区,因为这些代码对临界资源进行了访问。
剩余票数出现负数的原因:
- if语句判断条件为真以后,代码可以并发的切换到其他线程。
- usleep用于模拟漫长业务的过程,在这个漫长的业务过程中,可能有很多个线程会进入该代码段。
- –ticket操作本身就不是一个原子操作。
为什么- -ticket不是原子操作?
我们对一个变量进行- -,我们实际需要进行以下三个步骤:
- load:将共享变量tickets从内存加载到寄存器中。
- update:更新寄存器里面的值,执行-1操作。
- store:将新值从寄存器写回共享变量tickets的内存地址。
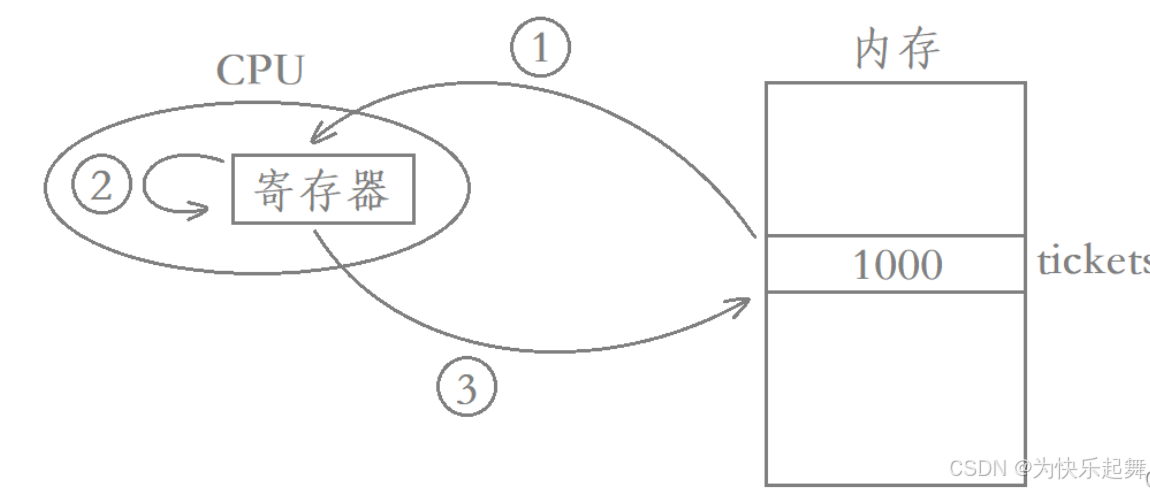

既然–操作需要三个步骤才能完成,那么就有可能当thread1刚把tickets的值读进CPU就被切走了,也就是从CPU上剥离下来,假设此时thread1读取到的值就是1000,而当thread1被切走时,寄存器中的1000叫做thread1的上下文信息,因此需要被保存起来,之后thread1就被挂起了。
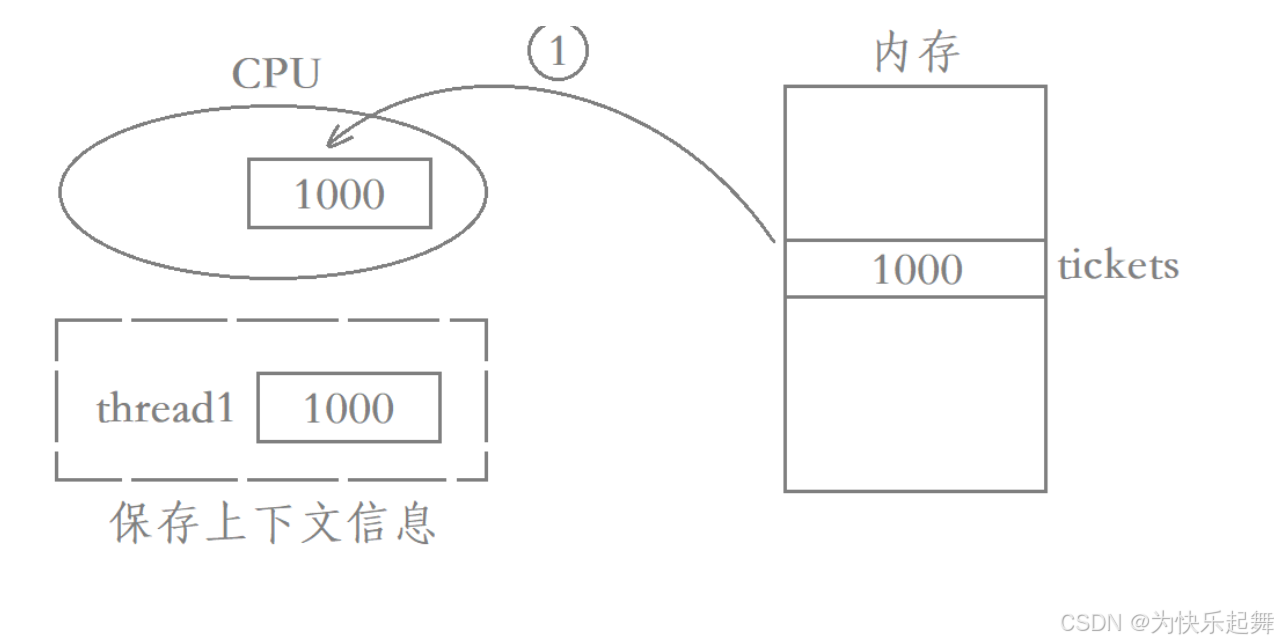
假设此时thread2被调度了,由于thread1只进行了- -操作的第一步,因此thread2此时看到tickets的值还是1000,而系统给thread2的时间片可能较多,导致thread2一次性执行了100次- -才被切走,最终tickets由1000减到了900。
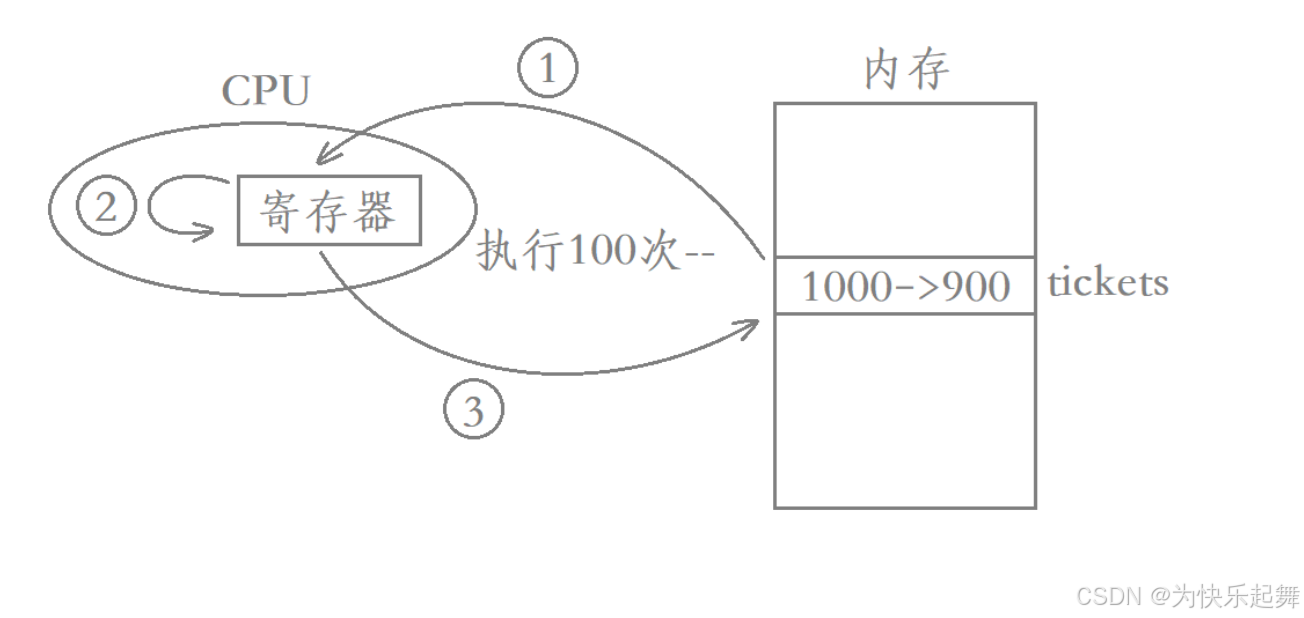
此时系统再把thread1恢复上来,恢复的本质就是继续执行thread1的代码,并且要将thread1曾经的硬件上下文信息恢复出来,此时寄存器当中的值是恢复出来的1000,然后thread1继续执行- -操作的第二步和第三步,最终将999写回内存。
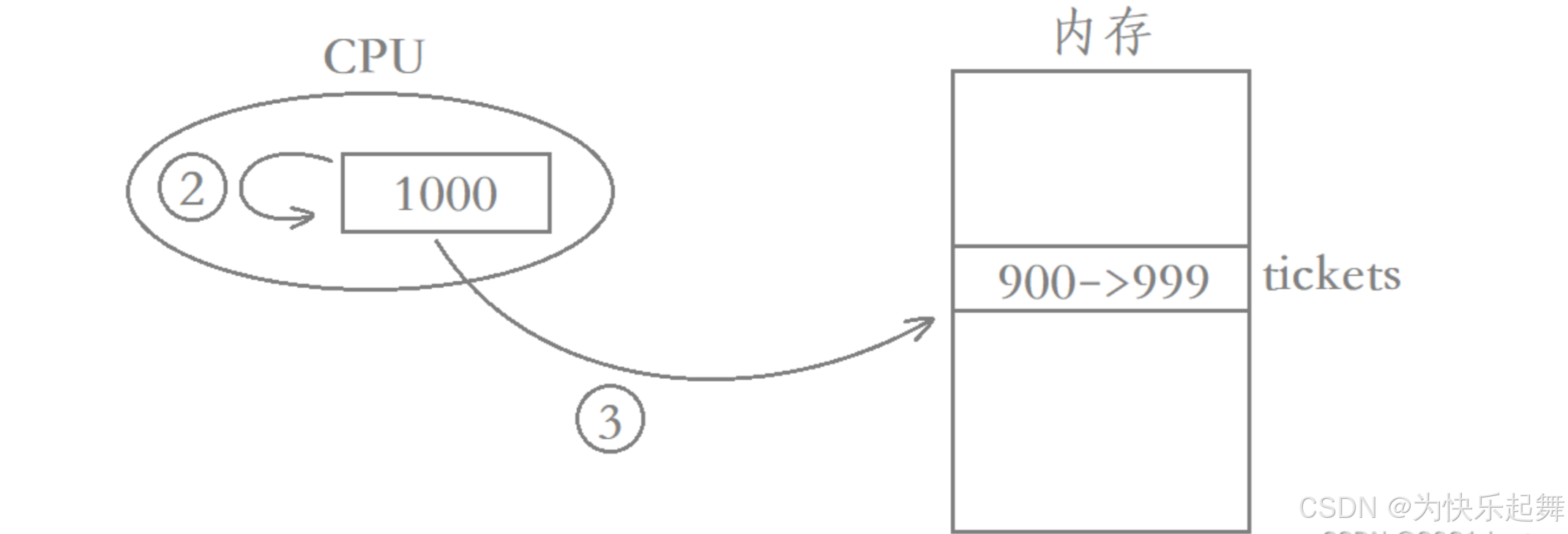
在上述过程中,thread1抢了1张票,thread2抢了100张票,而此时剩余的票数却是999,也就相当于多出了100张票。
因此对一个变量进行–操作并不是原子的,虽然–tickets看起来就是一行代码,但这行代码被编译器编译后本质上是三行汇编,相反,对一个变量进行++也需要对应的三个步骤,即++操作也不是原子操作。
2、互斥锁 mutex
互斥锁是pthread库提供的,英文名为mutex(互斥),需要头文件<pthread.h>,先讲解互斥锁的基本创建和销毁方法。
互斥锁的类型是pthread_mutex_t,分为全局互斥锁 和 局部互斥锁,它们的创建方式不同。
(1)全局mutex:
想要创建一个全局的互斥锁很简单,直接定义即可:
pthread_mutex_t xxx = PTHREAD_MUTEX_INITIALIZER;
这样就创建了一个名为xxx的变量,类型是pthread_mutex_t,即这个变量是一个互斥锁,全局的互斥锁必须用宏:PTHREAD_MUTEX_INITIALIZER进行初始化!
另外,全局的互斥锁不需要手动销毁。
(2)局部mutex:
局部的互斥锁是需要通过接口来初始化与销毁的,接口如下:
①pthread_mutex_init:
pthread_mutex_init函数用于初始化一个互斥锁,函数原型如下:
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);
参数:
- restrict mutex:类型为pthread_mutex_t *的指针,指向一个互斥锁变量,对其初始化
- restrict attr:用于设定该互斥锁的属性,一般不用,设为空指针即可
返回值:成功返回0;失败返回错误码
②pthread_mutex_destroy:
pthread_mutex_destroy函数用于销毁一个互斥锁,函数原型如下:
int pthread_mutex_destroy(pthread_mutex_t *mutex);
参数:类型为pthread_mutex_t *的指针,指向一个互斥锁变量,销毁该锁
返回值:成功返回0;失败返回错误码
创建好互斥锁后,就要使用这个锁,主要是两个操作:申请锁和释放锁。
三个函数的原型如下:
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_trylock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);

这三个函数的参数都是pthread_mutex_t *mutex,即指向互斥锁变量的指针,表示要操作哪一个互斥锁。
接下来我们修改一下最初的抢票代码,给它加锁,保证抢票g_ticket–的原子性:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; //全局互斥锁
void *buyTicket(void *args)
{
customer *cust = (customer *)args;
while (true)
{
pthread_mutex_lock(&mutex); // 加锁
if (g_ticket > 0)
{
usleep(1000);
cout << cust->_name << " get ticket: " << g_ticket << endl;
g_ticket--;
pthread_mutex_unlock(&mutex); // 解锁
cust->_ticket_num++;
}
else
{
pthread_mutex_unlock(&mutex); // 解锁
break;
}
}
return nullptr;
}
1、我在此使用的是全局的互斥锁,第一行pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;就是定义了一个全局的互斥锁,并对其初始化。
2、在访问临界区前,对mutex加锁,在此我在if (g_ticket > 0)前加锁,因为不仅仅是g_ticket- -是临界区,if (g_ticket > 0)也是临界区,它们都访问了临界资源g_ticket。
3、在if的第一个分支中,当g_ticket- -完毕,此时当前线程就不会再访问g_ticket了,于是离开临界区,并对mutex解锁。在第二个分支else中,线程马上要break出循环了,并且退出,此时也要解锁,不然别的线程永远处于阻塞状态了。
4、可以想象一下,当第一个线程被调度,它要进行抢票,现在先对mutex加锁,然后再去if中访问g_ticket。假如在某个访问临界资源的过程中,CPU调度了其它线程,此时第二个线程进入。
5、第二个线程也想访问g_ticket,于是也对mutex加锁,但是由于锁已经被第一个线程申请走了,此时第二个线程pthread_mutex_lock就会失败,然后阻塞等待。
6、等到第一个线程再次被调度,访问完临界区后,对mutex解锁,此时锁又可以被申请了。
于是线程二申请到锁,再去访问g_ticket。
7、加锁可以保证,任何时候都只有一个线程访问临界区。
8、当第二个线程访问临界区时,一定是其他线程访问完毕了临界区,或者其它线程还没有访问临界区。这就保证了临界区的原子性,从而维护线程的安全!
3、互斥锁原理
加锁后的原子性体现在哪里?
引入互斥量后,当一个线程申请到锁进入临界区时,在其他线程看来该线程只有两种状态,要么没有申请锁,要么锁已经释放了,因为只有这两种状态对其他线程才是有意义的。
例如,图中线程1进入临界区后,在线程2、3、4看来,线程1要么没有申请锁,要么线程1已经将锁释放了,因为只有这两种状态对线程2、3、4才是有意义的,当线程2、3、4检测到其他状态时也就被阻塞了。

此时对于线程2、3、4而言,它们就认为线程1的整个操作过程是原子的。
临界区内的线程可能进行线程切换吗?
临界区内的线程完全可能进行线程切换,但即便该线程被切走,其他线程也无法进入临界区进行资源访问,因为此时该线程是拿着锁被切走的,锁没有被释放也就意味着其他线程无法申请到锁,也就无法进入临界区进行资源访问了。
其他想进入该临界区进行资源访问的线程,必须等该线程执行完临界区的代码并释放锁之后,才能申请锁,申请到锁之后才能进入临界区。
锁是否需要被保护?
我们说被多个执行流共享的资源叫做临界资源,访问临界资源的代码叫做临界区。所有的线程在进入临界区之前都必须竞争式的申请锁,因此锁也是被多个执行流共享的资源,也就是说锁本身就是临界资源。
既然锁是临界资源,那么锁就必须被保护起来,但锁本身就是用来保护临界资源的,那锁又由谁来保护的呢?
锁实际上是自己保护自己的,我们只需要保证申请锁的过程是原子的,那么锁就是安全的。
如何保证申请锁的过程是原子的?
- 上面我们已经说明了- -和++操作不是原子操作,可能会导致数据不一致问题。
- 为了实现互斥锁操作,大多数体系结构都提供了swap或exchange指令,该指令的作用就是把寄存器和内存单元的数据相交换。
- 由于只有一条指令,保证了原子性,即使是多处理器平台,访问内存的总线周期也有先后,一个处理器上的交换指令执行时,另一个处理器的交换指令只能等待总线周期。

下面我们来看看lock和unlock的伪代码:

我们可以认为mutex的初始值为1,al是计算机中的一个寄存器,当线程申请锁时,需要执行以下步骤:
- 先将al寄存器中的值清0。该动作可以被多个线程同时执行,因为每个线程都有自己的一组寄存器(上下文信息),执行该动作本质上是将自己的al寄存器清0。
- 然后交换al寄存器和mutex中的值。xchgb是体系结构提供的交换指令,该指令可以完成寄存器和内存单元之间数据的交换。
- 最后判断al寄存器中的值是否大于0。若大于0则申请锁成功,此时就可以进入临界区访问对应的临界资源;否则申请锁失败需要被挂起等待,直到锁被释放后再次竞争申请锁。
例如,此时内存中mutex的值为1,线程申请锁时先将al寄存器中的值清0,然后将al寄存器中的值与内存中mutex的值进行交换。
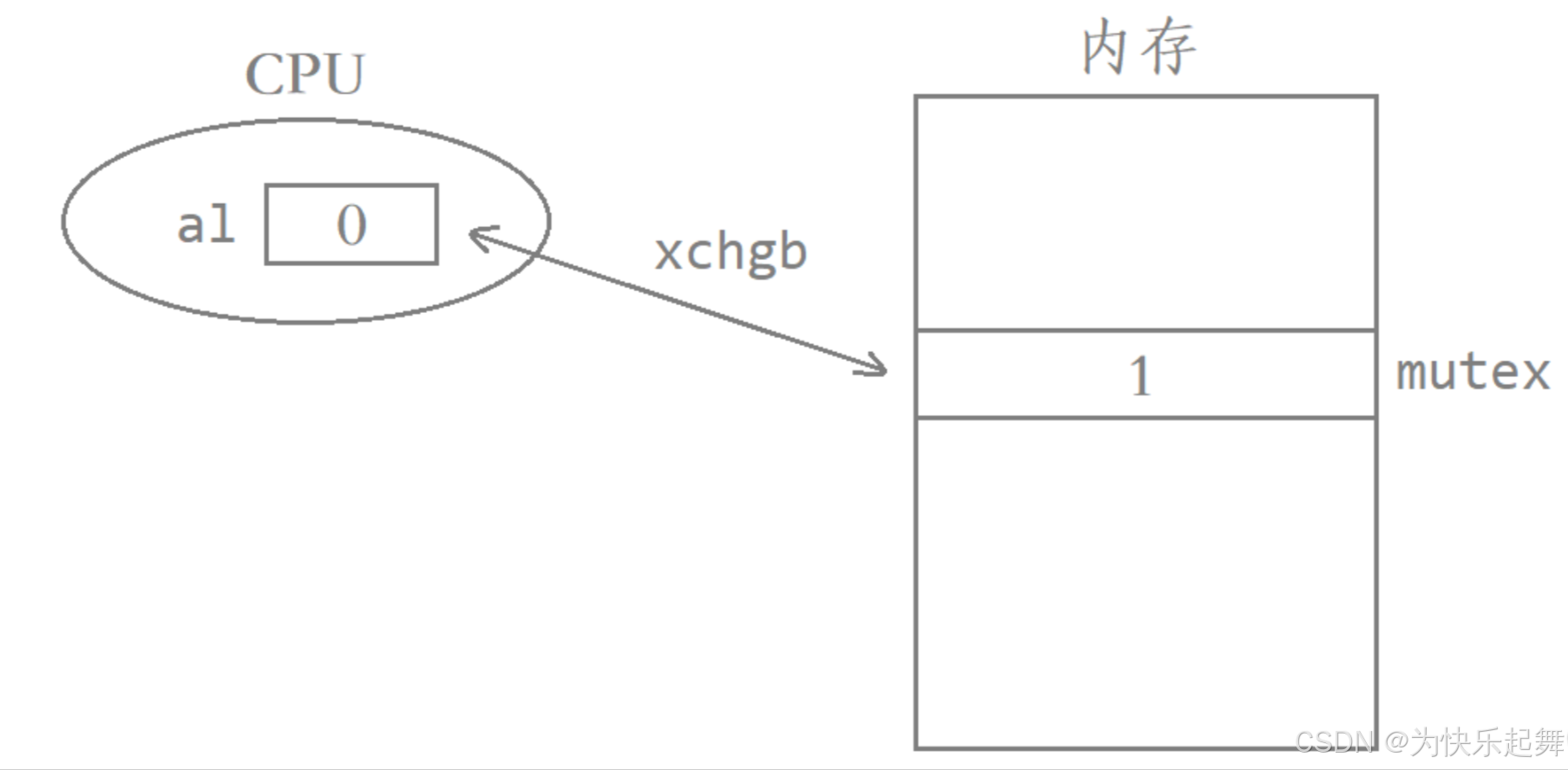
交换完成后检测该线程的al寄存器中的值为1,则该线程申请锁成功,可以进入临界区对临界资源进行访问。
而此后的线程若是再申请锁,与内存中的mutex交换得到的值就是0了,此时该线程申请锁失败,需要被挂起等待,直到锁被释放后再次竞争申请锁。
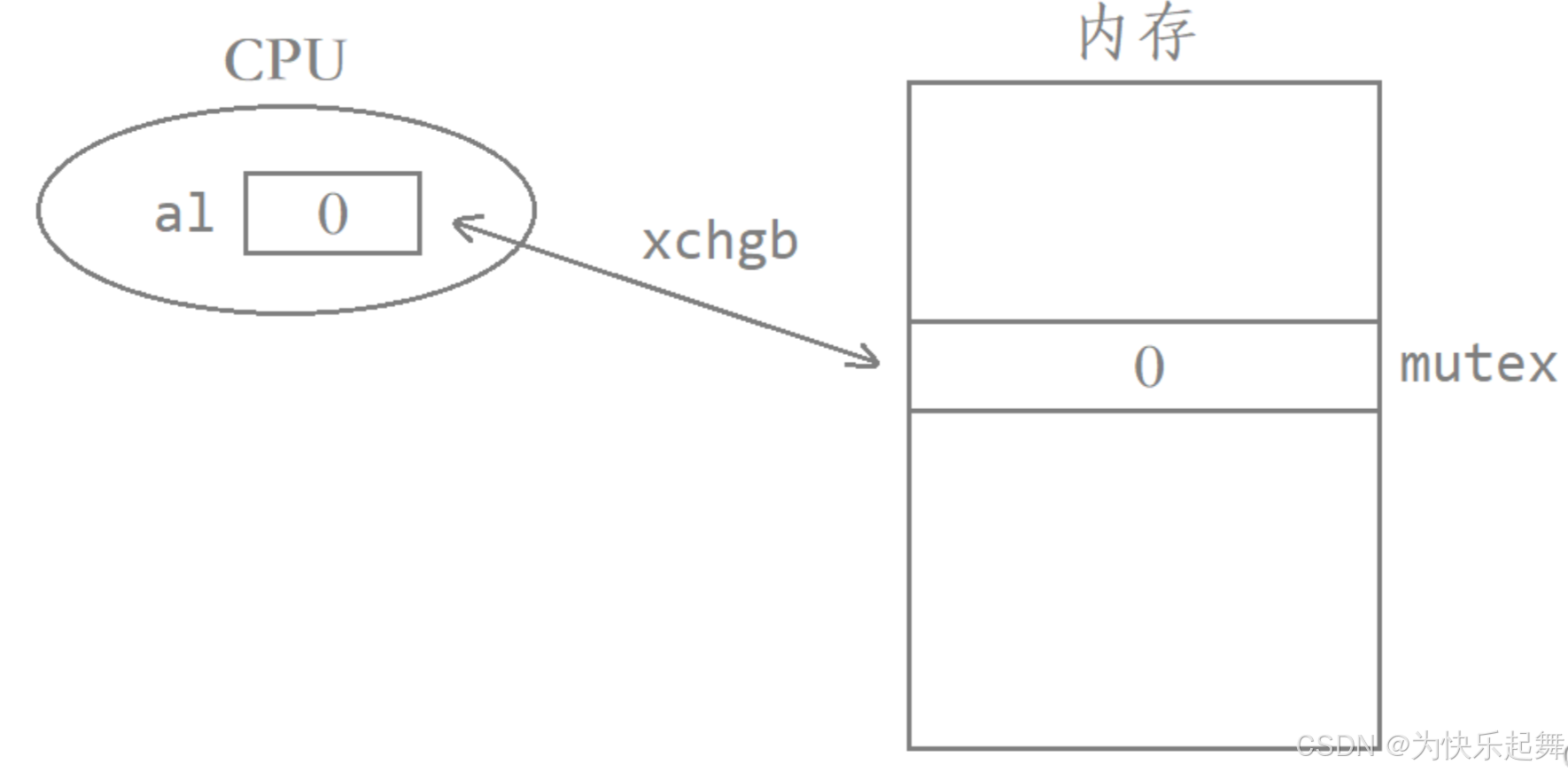
当线程释放锁时,需要执行以下步骤
- 将内存中的mutex置回1。使得下一个申请锁的线程在执行交换指令后能够得到1,形象地说就是“将锁的钥匙放回去”。
- 唤醒等待Mutex的线程。唤醒这些因为申请锁失败而被挂起的线程,让它们继续竞争申请锁。

二、常见的锁
1、死锁
死锁:指在一组进程中的各个进程均占有不会释放的资源,但因互相申请其它进程不会释放的资源而处于的一种永久等待状态
我简单举一个例子:
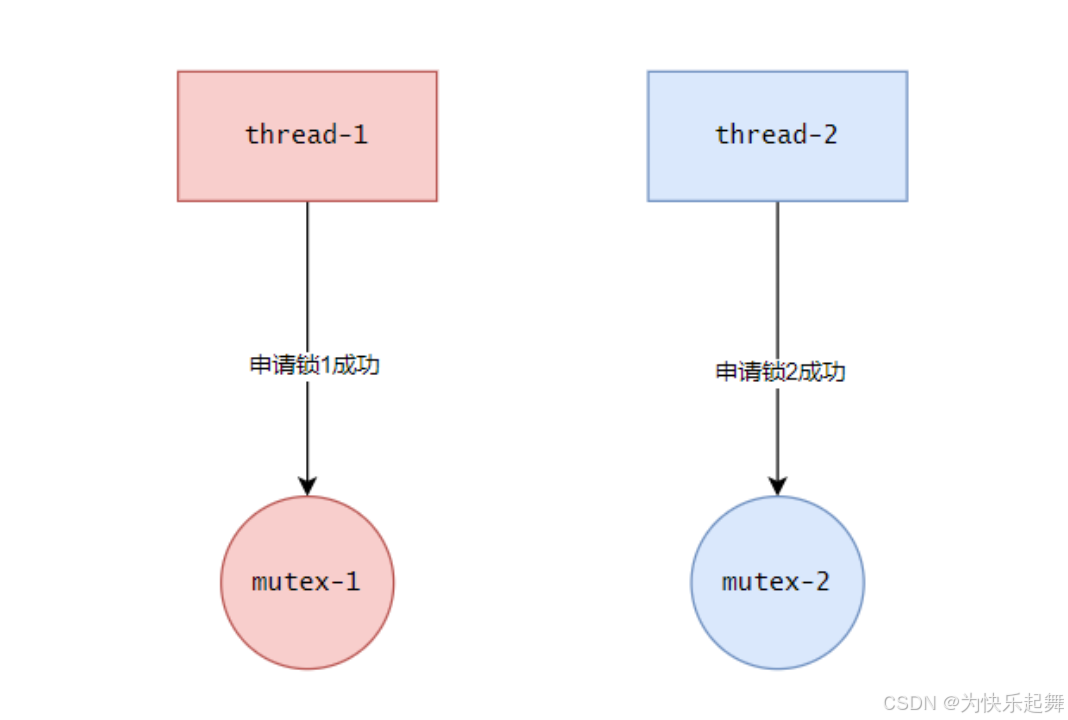
现在有两个线程thread-1和thread-2,以及两把互斥锁mutex-1,mutex-2:
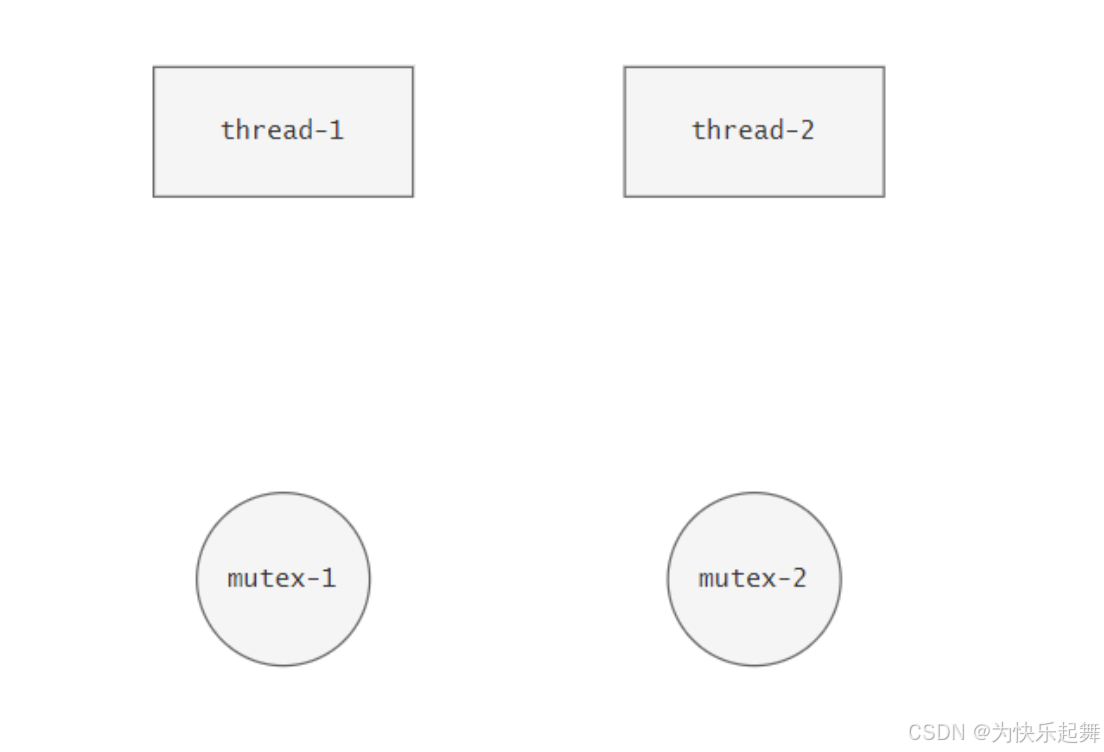
现在要求:一个线程想要访问临界资源,必须同时持有mutex-1和mutex-2。随后therad-1去申请了mutex-1,thread-2去申请了mutex-2:
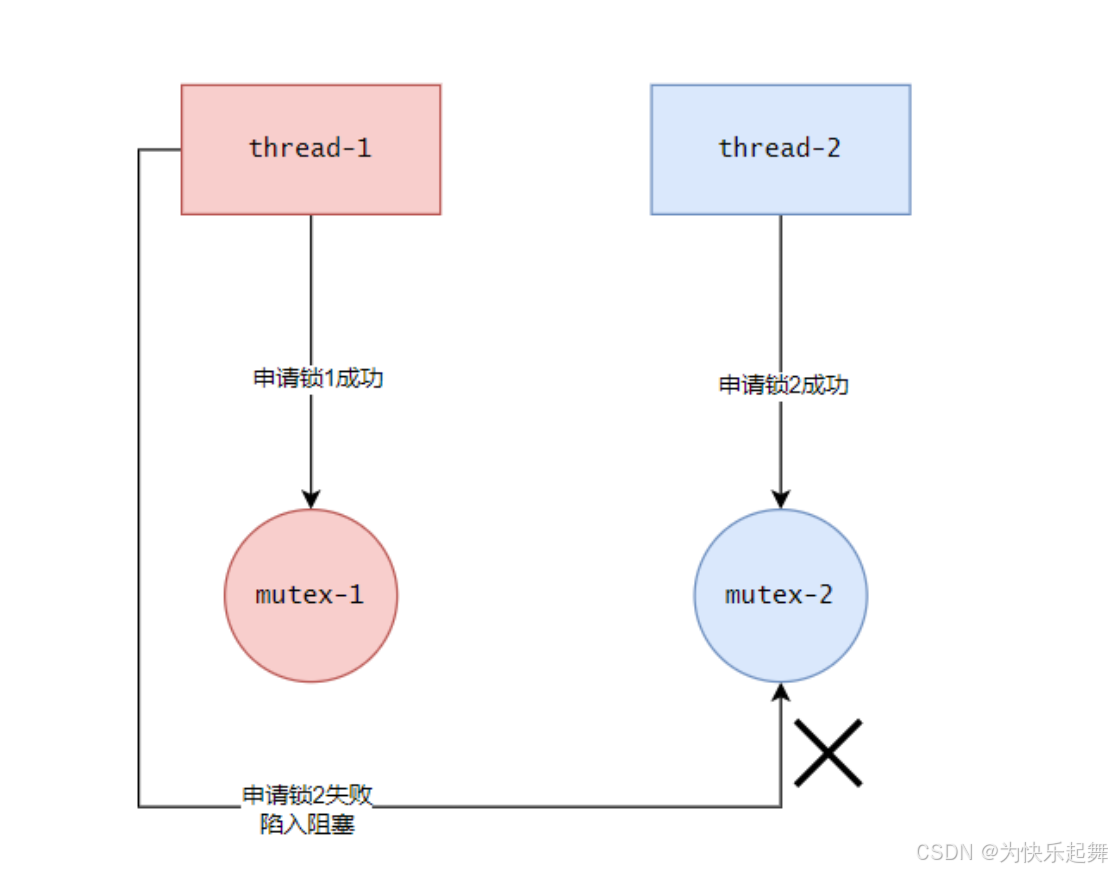
thread-1再去申请mutex-2,结果mutex-2已经被therad-2占用了,thread-1陷入阻塞:
thread-2再去申请mutex-1,结果mutex-1已经被therad-1占用了,thread-2陷入阻塞:
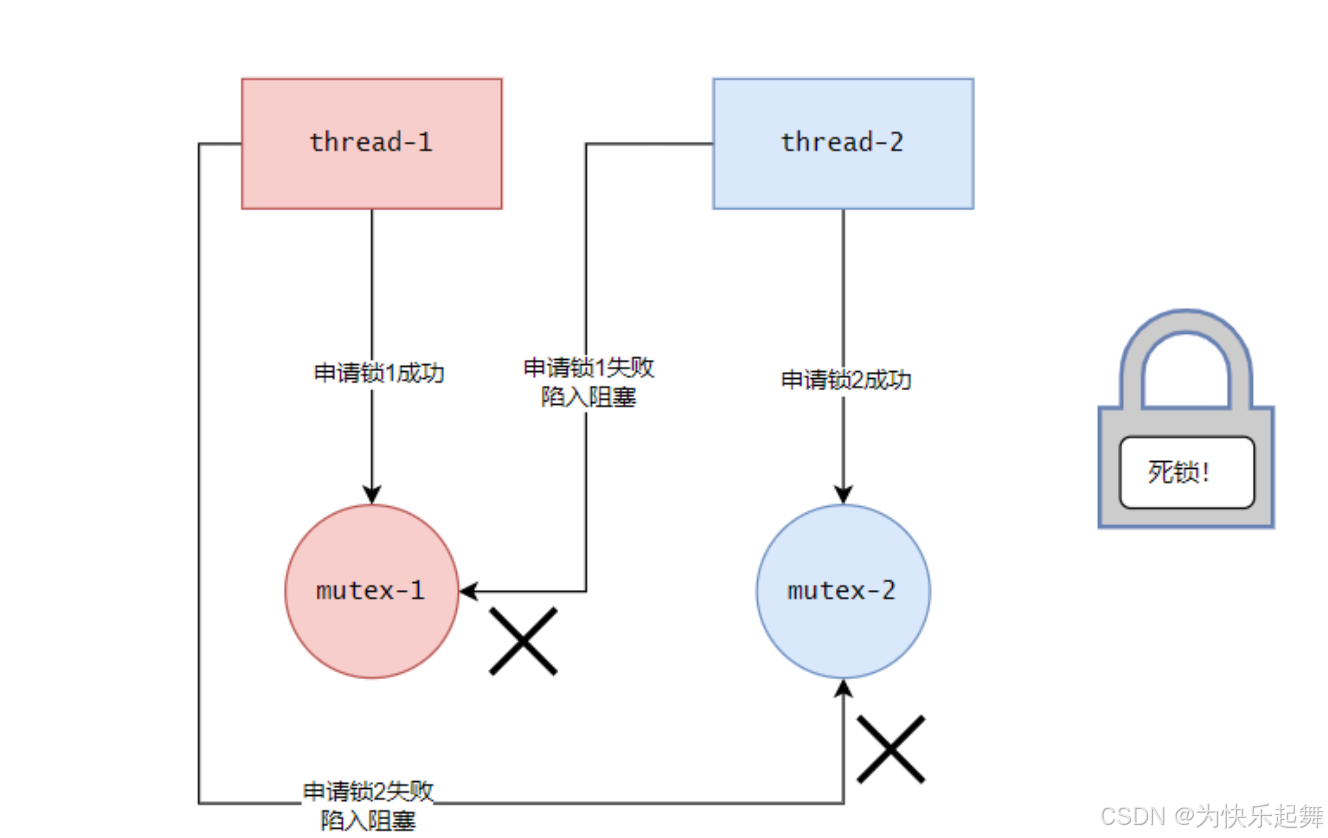
现在therad-1等待therad-2解锁mutex-2,thread-2等待thread-1解锁mutex-1,双方互相等待。由于唤醒thread-2需要therad-1,唤醒therad-1又需要therad-2,此时陷入永远的等待状态,这就是死锁。
想要造成死锁,有四个必要条件:

以上是比较正式的说法,接下来我从线程角度简单翻译翻译:

这四个条件都是必要条件,也就是说:
解决死锁,本质就是破坏一个或多个必要条件

2、自旋锁
我们先前讲的锁,其机制是这样的:
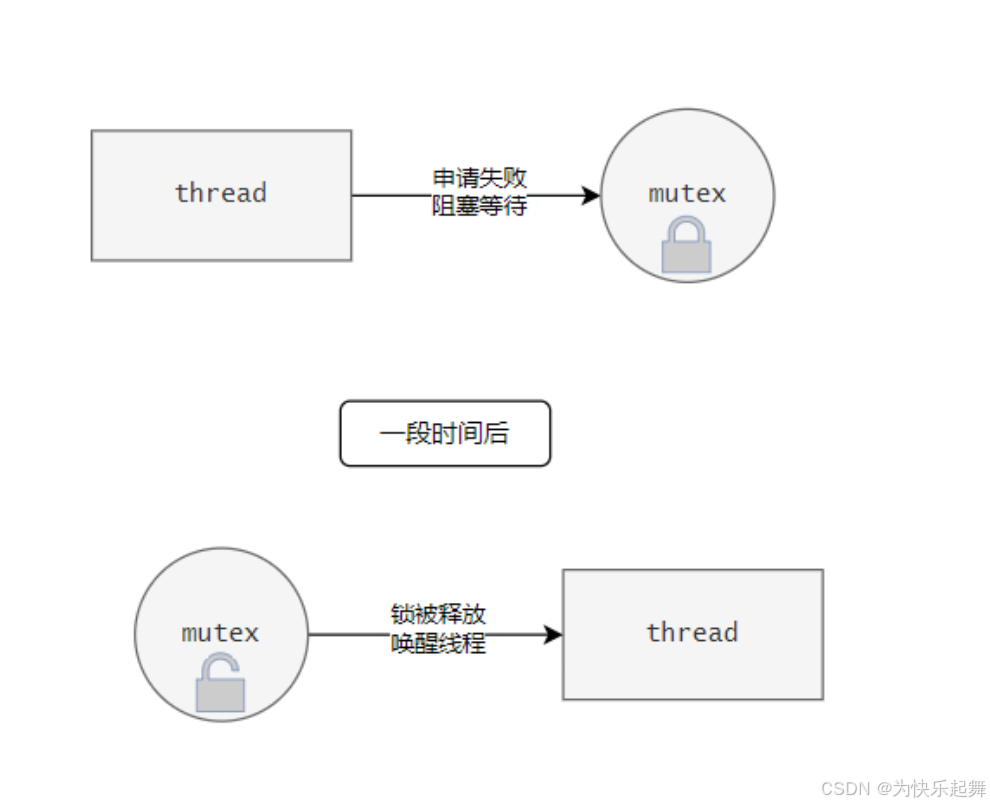
当线程申请一个锁失败,就会阻塞等待,当锁被使用完毕,唤醒所有等待该锁的线程。
其实锁还有一种不用阻塞等待的策略,而是反复检测的策略,就像这样:
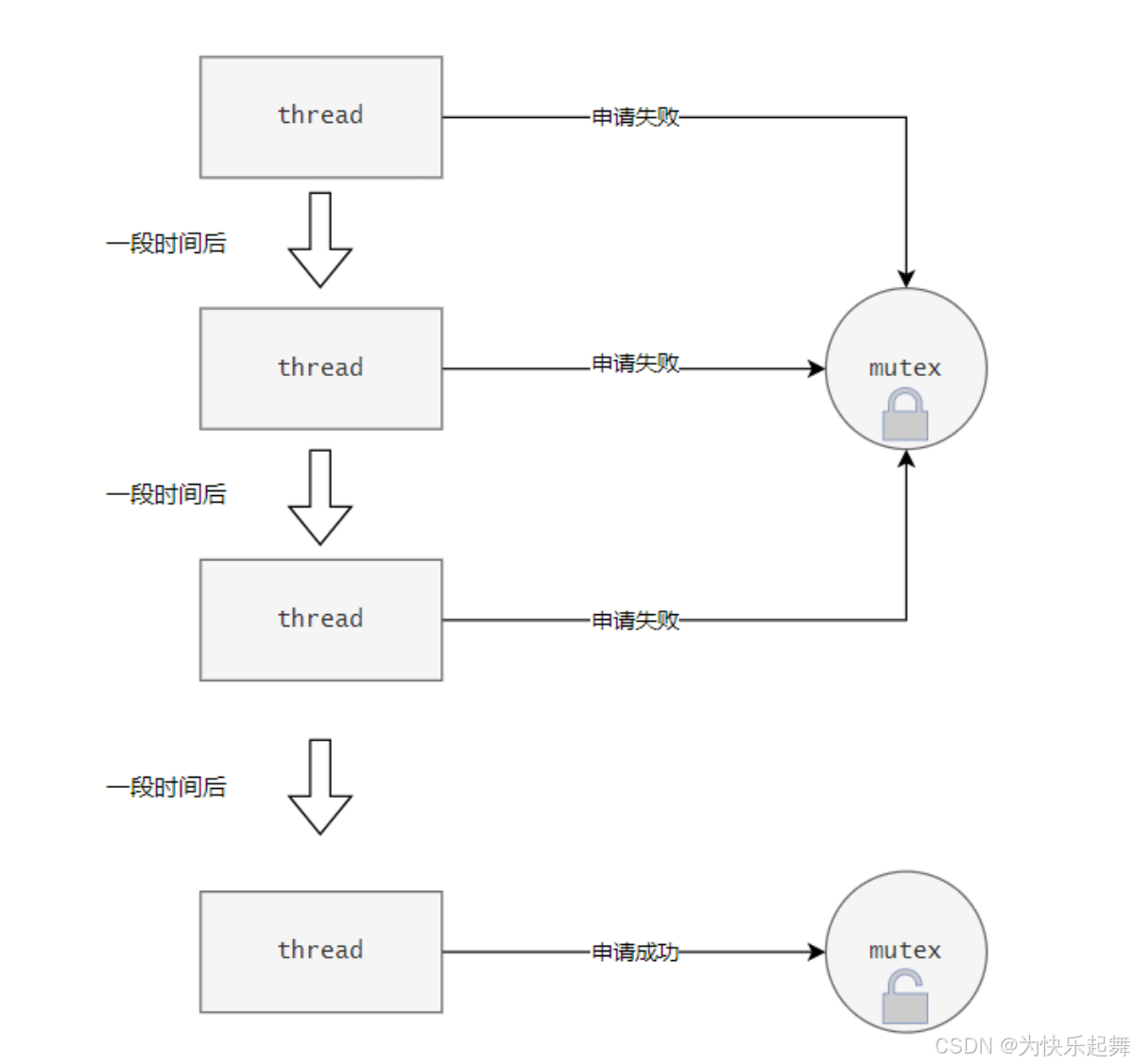
当线程没有申请到锁,一段时间后再次检测这个锁有没有被释放,一直反复申请这个锁,这个过程叫做自旋。基于这个策略来申请的锁,叫做自旋锁。
Linux自带了自旋锁spinlock,类型为pthread_spinlock_t,接口如下:
创建与销毁:
int pthread_spin_init(pthread_spinlock_t *lock, int pshared);
int pthread_spin_destroy(pthread_spinlock_t *lock);
加锁与解锁:
int pthread_spin_lock(pthread_spinlock_t *lock);
int pthread_spin_trylock(pthread_spinlock_t *lock);
int pthread_spin_unlock(pthread_spinlock_t *lock);
你会发现,这和mutex几乎一摸一样,所以接口也就不讲解了。
不过我这里要强调一点,pthread_spin_lock并不是申请失败就返回,而是在pthread_spin_lock内部以自旋的方式申请锁,我们无需手动模拟自旋的过程。
3、其他锁
