Uni-Mol:一个通用的三维分子表征学习框架
UNI-MOL: A UNIVERSAL 3D MOLECULAR REPRESENTATION LEARNING FRAMEWORK
Uni-Mol,首个通用三维分子预训练框架,可直接将三维位置作为输入和输出。它由三部分组成:
- 主干网络:基于 Transformer,捕捉三维信息并预测位置。
- 预训练:用 2.09 亿分子构象和 300 万候选蛋白质口袋数据集,分别预训练分子和口袋模型,通过三维位置恢复和掩码原子预测任务学习三维空间表征。
- 微调:针对下游任务制定多种微调策略,如分子性质预测中使用预训练分子模型、蛋白质 - 配体结合构象预测中结合两个预训练模型。
主干网络
在分子表征学习(MRL)中,图神经网络(GNN)[22; 23; 12] 和 Transformer [24; 11] 是两种知名的主干模型。以 GNN 为主干时,为提高效率常用局部连接图表示分子,但它难以捕捉原子间的长程相互作用,而长程相互作用在 MRL 中很重要。因此,Uni-Mol 选择 Transformer 为主干,因其能全连接节点 / 原子,学习长程相互作用。基于带 Pre-LayerNorm 的标准 Transformer [32],进行了必要高效的修改,使其能以三维位置作为输入和输出。
架构概述:
Uni-Mol 主干是基于 Transformer 的模型,输入为原子类型和原子坐标,模型中保留原子和成对两种表征。原子表征由嵌入层根据原子类型初始化,成对表征由基于原子坐标计算的不变空间位置编码初始化,且基于原子对欧氏距离,成对表征在全局旋转和平移下不变。两种表征在自注意力模块中交互。
三维位置编码:Transformer 具排列不变性,若无位置编码无法区分输入位置。三维空间中的位置(坐标)是连续值,与 NLP/CV 中的离散位置不同,且位置编码需在全局旋转和平移下不变。

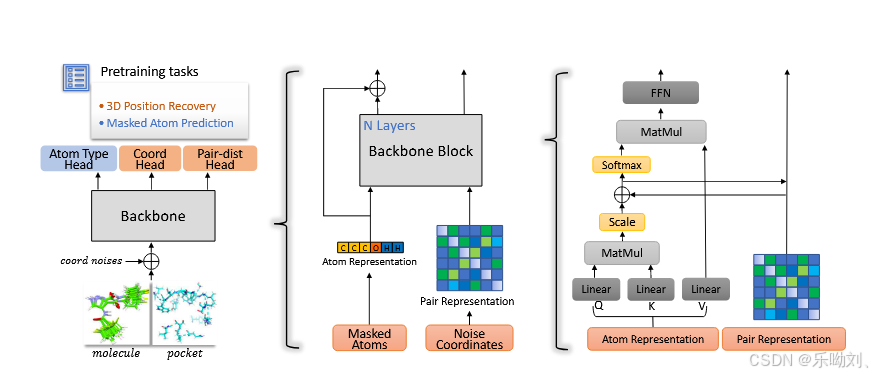
预训练策略:自监督任务对从大规模无标签数据中有效学习至关重要,如 BERT [4] 中的掩码词预测任务可促使模型学习上下文信息。在 Uni-Mol 中,希望模型在预训练时学习三维结构信息,因此设计了三维位置恢复自监督任务,即根据损坏的输入位置恢复正确的三维位置。直观方法是像 BERT 那样掩码位置,但位置是连续值,无法用特殊值表示掩码。

- 成对距离预测:基于成对表征,模型需预测损坏原子对的正确欧氏距离。
- 坐标预测:基于 SE (3) 等变坐标头,模型需预测损坏原子的正确坐标。