回溯算法经典题目
文章目录
- 一、题目合集
- 二、回溯题目套路总结
- 三、题目解析
- 1. 子集
- 2. 全排列
- 3. 全排列2
- 4. 组合
- 5. 组合总和
- 6. 组合总和2
- 7. 组合总和3
- 8. 复原ip地址
- 9. 划分为K个相等的子集
- 10. N皇后
一、题目合集
以下全是超链接、直接点击跳转就好。
子集
全排列
全排列2
组合
组合总和
组合总和2
组合总和3
复原IP地址
划分为K个相等的子集
N皇后
二、回溯题目套路总结
用于解决暴力枚举的场景,例如枚举组合、排列等。
一般常见套路就是弄俩全局变量,这样方便在递归的时候对数据进行操作。
dfs()一般上来显示设置递归出口,执行对应操作,然后是进行递归,递归前后处理好回溯。
更麻烦点的可能会涉及到去重,常见的可以通过排序+其它操作进行去重,具体操作见第三部分题目解析。
关于什么时候用visit数组什么时候i从pos开始,我的理解是看题目要不要求顺序,如果1,2和2,1算一种结果的话那就i=pos,如果算两种结果的话那就每次i=0,弄个vis数组记录元素有没有访问过。
vector<vector<int>> res;
vector<int> path;
void dfs(参数) {
if (满足递归结束) {
res.push_back(path);
return;
}
//递归方向
for (xxx) {
path.push_back(val);
dfs();
path.pop_back();
}
}
三、题目解析
1. 子集
子集
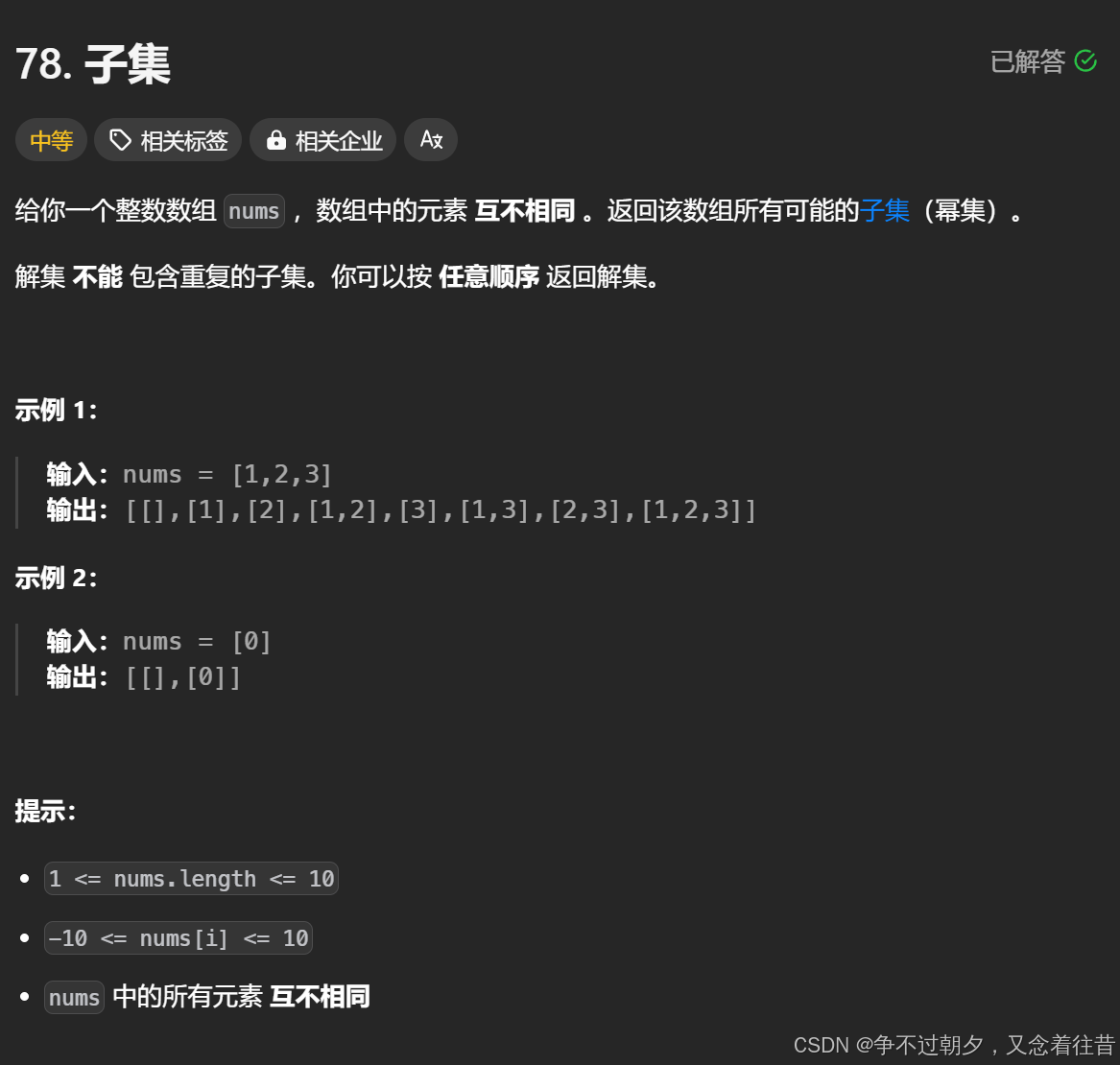
以1,2,3为例
每次选一个,第一次1,2,3都可以选,选了1之后,选过的元素就不能再选了,所以只能选2,3,依次类推。
当选过1之后,选2,选2之后就不能选1或者3了。而是只能选3,因为前面选1的时候已经选过12这个组合了,这里再选1就会有21这个组合,重复了。
所以在递归的时候我们可以让每次的for循环都从上一次循环的下一个位置开始,这样就避免重复了,具体代码表现为:
for(int i=pos;i<nums.size();i++)
具体代码:
class Solution {
public:
vector<vector<int>> ret;
vector<int> path;
vector<vector<int>> subsets(vector<int>& nums) {
dfs(nums,0);
return ret;
}
void dfs(vector<int> &nums,int pos){
ret.push_back(path);
for(int i=pos;i<nums.size();i++){
path.push_back(nums[i]);
dfs(nums,i+1);
path.pop_back();
}
}
};
2. 全排列
全排列
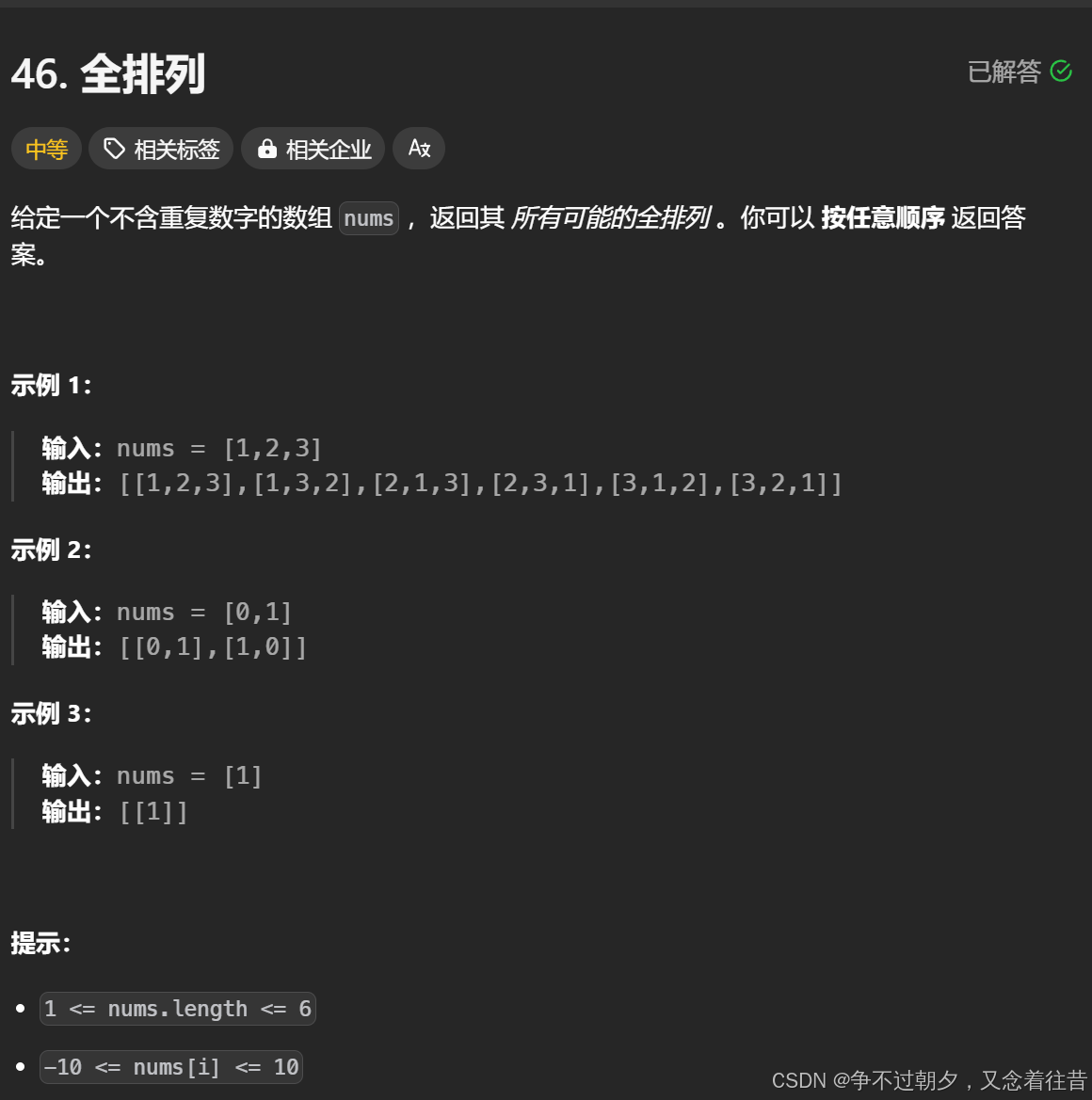
这个题所有数字必须全部都得选一遍,所以不需要和上一题的pos一样控制位置,但每次都是枚举数组中的所有数据,所以要弄一个vis数组,来记录某个元素是否被访问过。
比如以数组1,2,3为例,你已经选了1,2之后,下一层循环还是for(int i=0;i<3;i++),当i=0或1的时候,显然这俩已经被访问过了,就不能再访问了,直接访问3就好了。
class Solution {
public:
vector<vector<int>> ret;
bool vis[7];
vector<int> path;
vector<vector<int>> permute(vector<int>& nums) {
dfs(nums);
return ret;
}
void dfs(vector<int> &nums){
if(nums.size()==path.size()){
ret.push_back(path);
return;
}
for(int i=0;i<nums.size();i++){
if(vis[i]==false){
vis[i]=true;
path.push_back(nums[i]);
dfs(nums);
vis[i]=false;
path.pop_back();
}
}
}
};
3. 全排列2
全排列2
这里和全排列的区别是有重复数字,所以在操作中需要进行去重操作
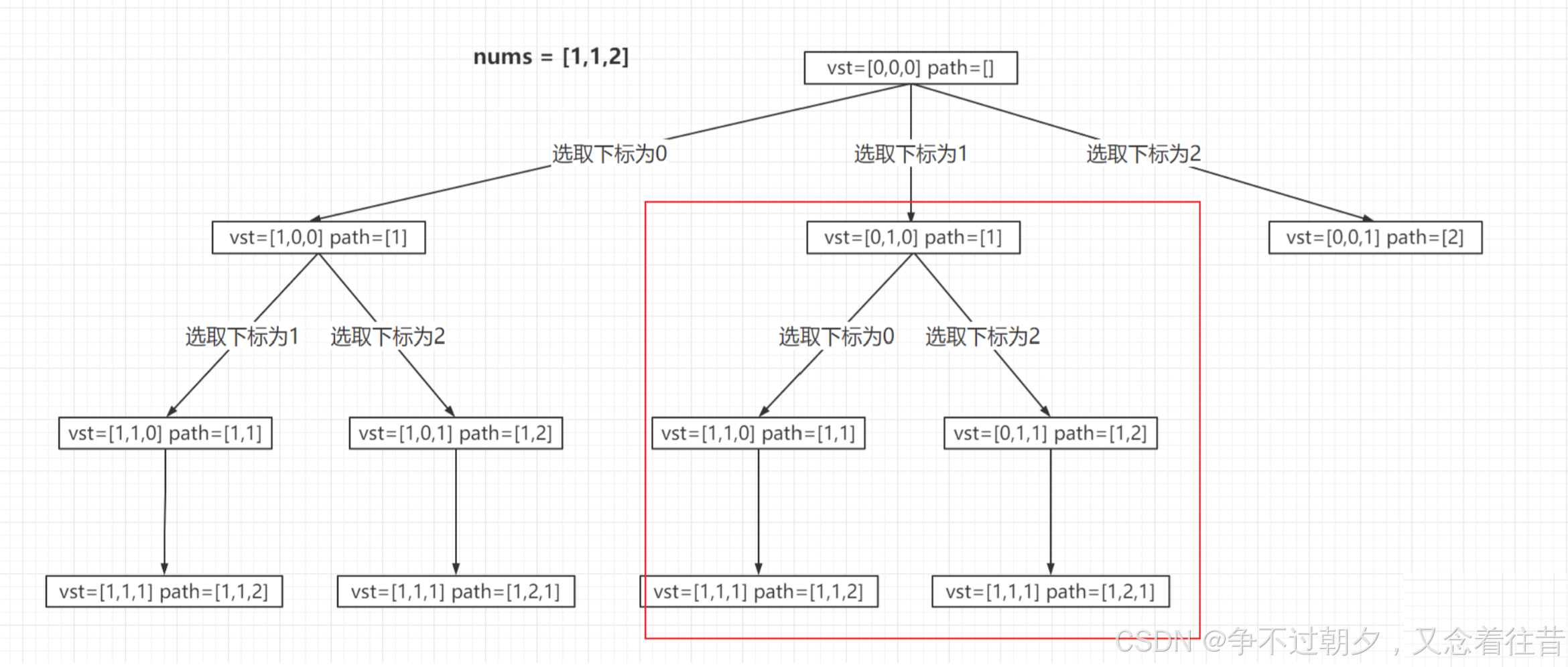
以1,1,2为例,第一次选的是下标为0的1,第二次选下表为1的1,第三次选2,最后的结果是112,如果第一次选的是下表为1的1,第二次选下标为0的1,第三次选2,结果还是112,显然重复。
要进行去重的话,我们可以当当前元素没有被访问过时,再次进行如下判断,i>0,目的是保证i-1数组不越界,当i>0且,相邻俩元素相等,且前一个元素没有被访问过时,跳出这次循环即可。
思路重点是,同一层的for循环不能选取同样的元素,同一层的数据,前面所有层的结果是相同的,如果这一层的数据也相同,那么后面层的也会一样,所以会造成重复。
如何判断是不是同一层?如果同一层for循环中,俩相同的元素都是false,都没被访问过,那就是同一层的,如果前一个是true,说明它是被上一次设置过的,所以不是同一层的。
if (i > 0 && nums[i] == nums[i - 1] && vis[i - 1] == false)
continue;
class Solution {
public:
vector<vector<int>> ret;
vector<int> path;
vector<bool> vis;
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(), nums.end());
vis = vector<bool>(nums.size(), false);
dfs(nums);
return ret;
}
void dfs(vector<int>& nums) {
if (path.size() == nums.size())
return ret.push_back(path);
for (int i = 0; i < nums.size(); i++) {
if (vis[i] == false) {
if (i > 0 && nums[i] == nums[i - 1] && vis[i - 1] == false)
continue;
vis[i] = true;
path.push_back(nums[i]);
dfs(nums);
path.pop_back();
vis[i] = false;
}
}
}
};
4. 组合
组合
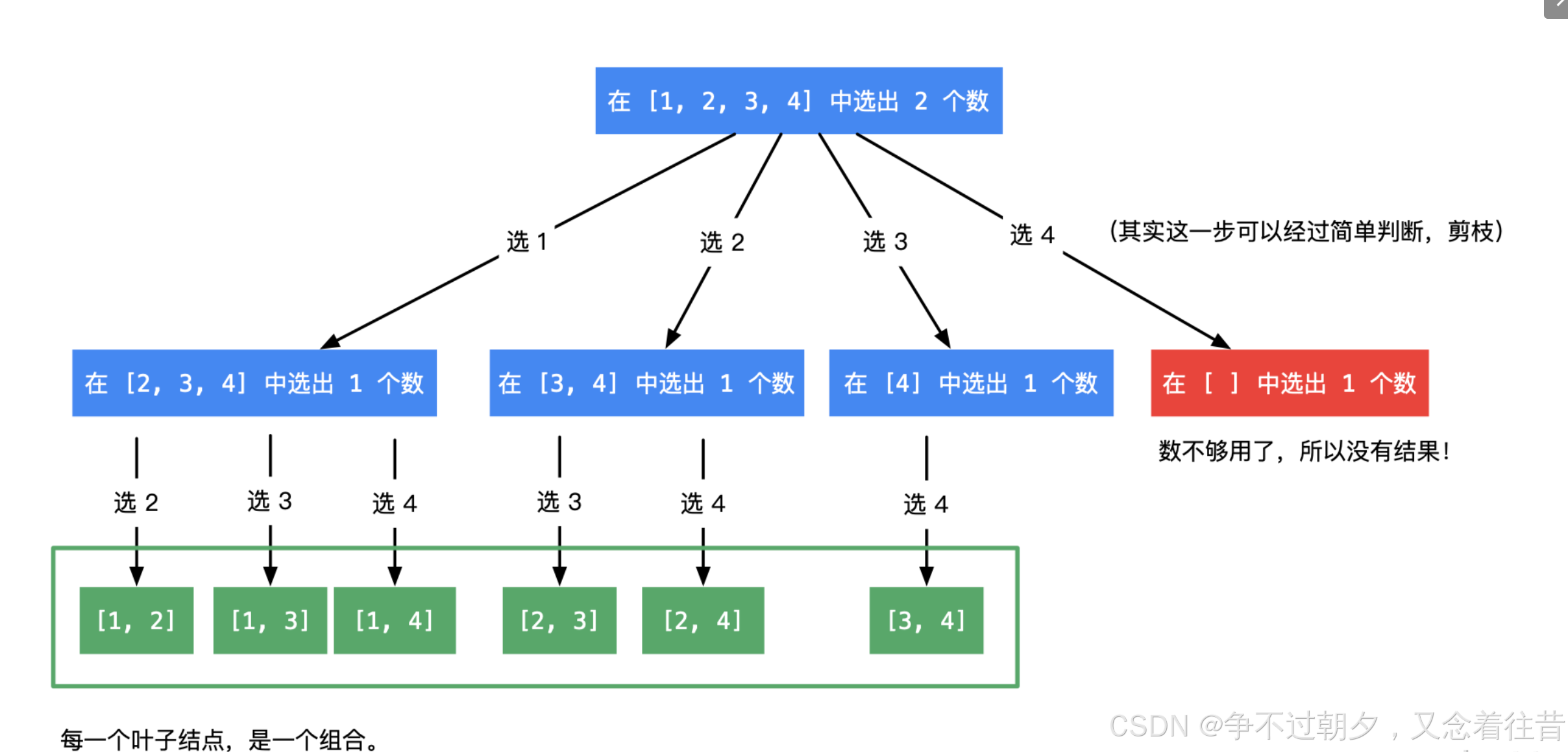
这个题其实和第一题子集类似,以1,2,3为例,子集是把0个数的组合,一个数的组合,两个数的组合,三个数的组合全列出来即:[]、[1]、[2]、[3]、[1,2]、[1,3]、[2,3]、[1,2,3]。组合的话就是要特定个数的组合,比如要2个数的组合,那就是[1,2]、[1,3]、[2,3]
所以在递归结束条件加个这个就好了,其他代码和子集几乎一样。
if(path.size()==k){
ret.push_back(path);
return;
}
class Solution {
public:
vector<vector<int>> ret;
vector<int> path;
int n=0,k=0;
vector<vector<int>> combine(int _n, int _k) {
n=_n;
k=_k;
dfs(1);
return ret;
}
void dfs(int pos){
if(path.size()==k){
ret.push_back(path);
return;
}
for(int i=pos;i<=n;i++){
path.push_back(i);
dfs(i+1);
path.pop_back();
}
}
};
5. 组合总和
组合总和
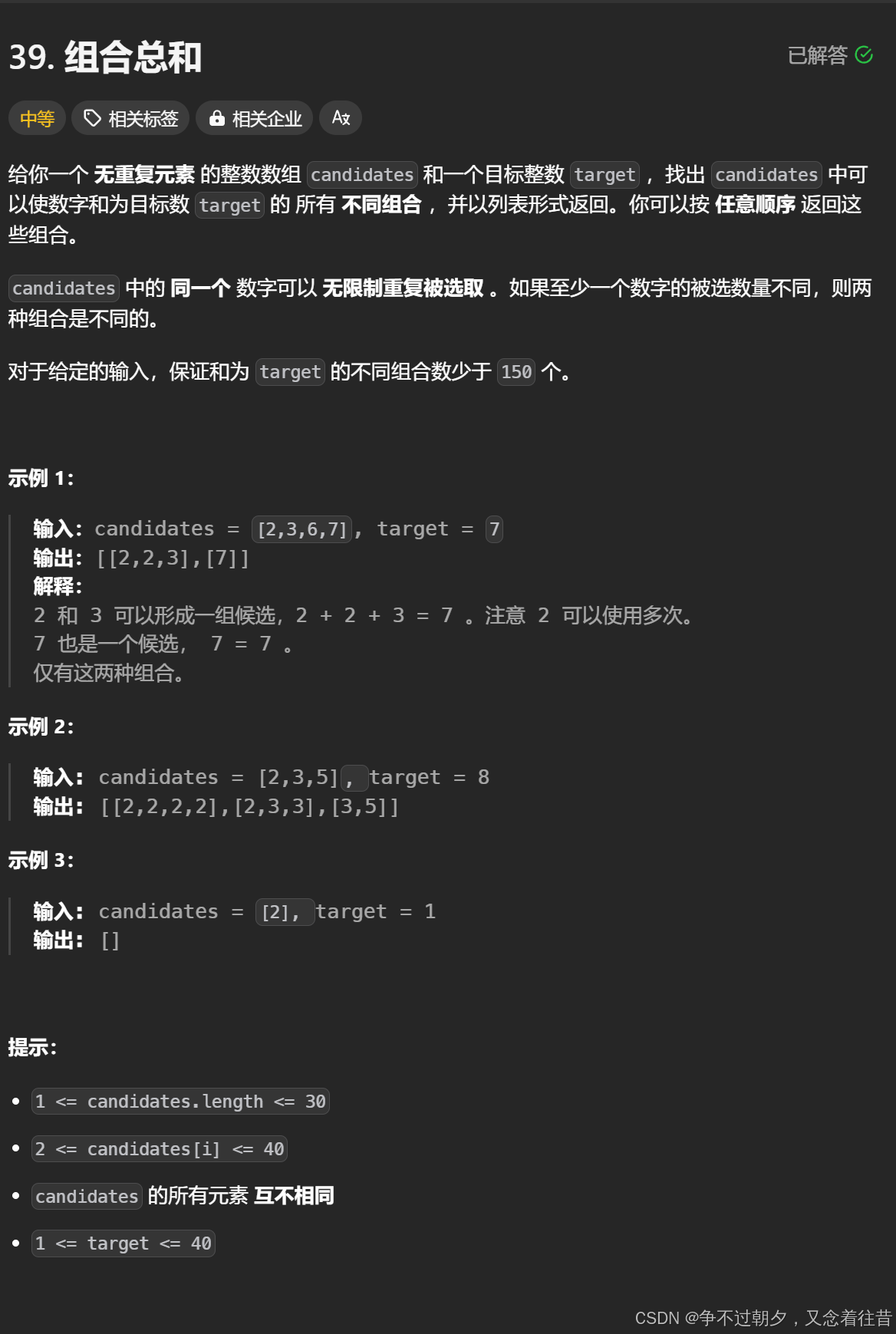
和为target,所以结束条件就是sum==target
if (sum == target) {
ret.push_back(path);
return;
}
而且此处同一个元素可以重复选择,所以每次递归是dfs(candidates, i, target);
而不是dfs(candidates, i+1, target);
class Solution {
public:
vector<vector<int>> ret;
int n = 0;
vector<int> path;
int sum = 0;
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
n = candidates.size();
dfs(candidates, 0, target);
return ret;
}
void dfs(vector<int>& candidates, int pos, int target) {
if (sum == target) {
ret.push_back(path);
return;
}
if (sum > target)
return;
for (int i = pos; i < n; i++) {
sum += candidates[i];
path.push_back(candidates[i]);
dfs(candidates, i, target);
sum -= candidates[i];
path.pop_back();
}
}
};
6. 组合总和2
组合总和2
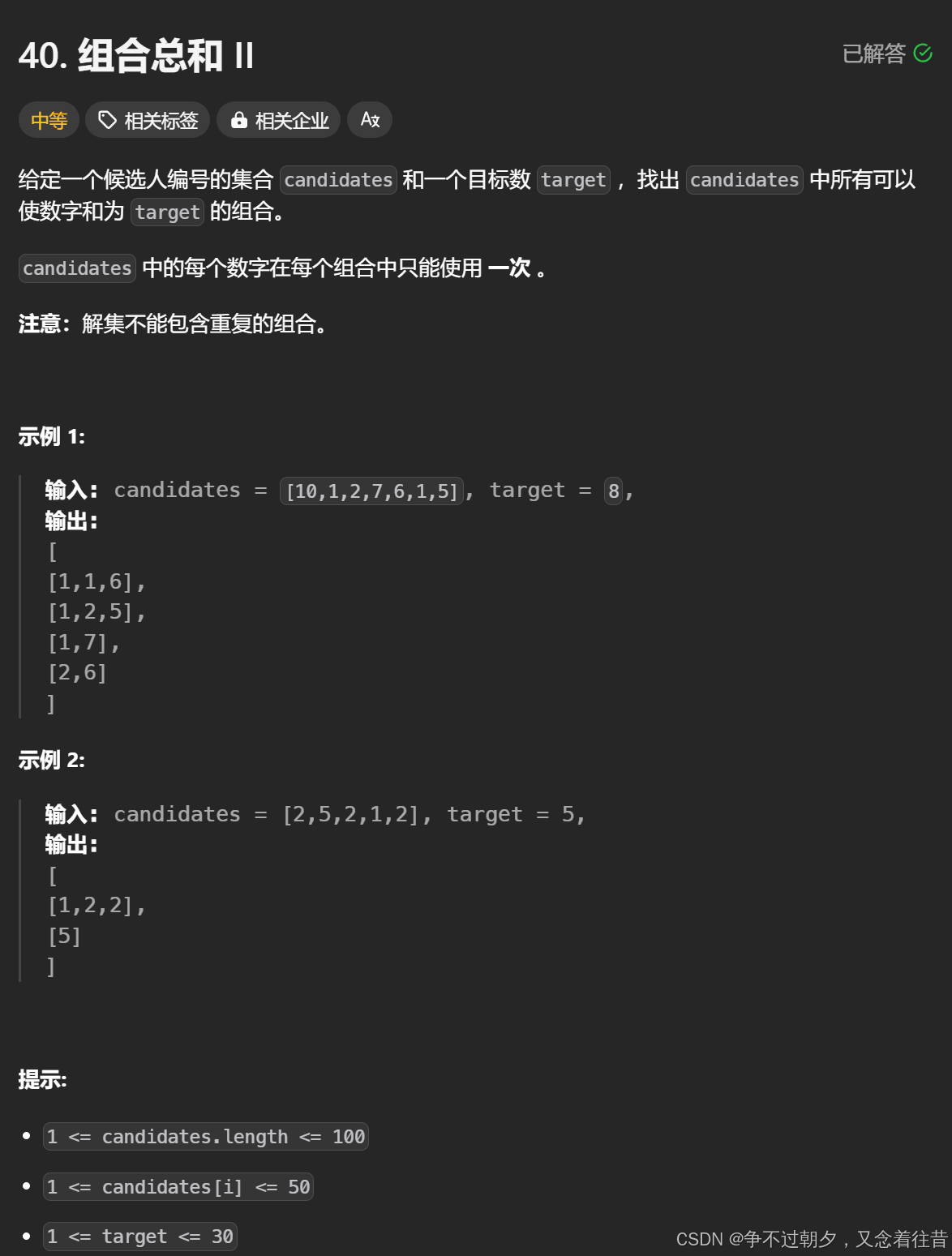
这里和上一题的区别就是有重复元素,所以可以先排个序,然后进行同层去重就行if(i>pos&&candidates[i]==candidates[i-1]) continue;,这里和全排列里去重对比一下:if (i > 0 && nums[i] == nums[i - 1] && vis[i - 1] == false) continue; 因为本题每次都是从pos位置开始,所以i>pos与i>0对应,主要是防止i-1越界,且本题每次都会从pos位置重新开始,不会从0开始,所以不需要vis[i - 1] == false
class Solution {
public:
vector<vector<int>> ret;
vector<int> path;
int n=0,sum=0;
int t=0;
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
n=candidates.size();
t=target;
sort(candidates.begin(),candidates.end());
dfs(candidates,0);
return ret;
}
void dfs(vector<int> &candidates,int pos){
if(sum==t){
ret.push_back(path);
return;
}
if(sum>t) return;
for(int i=pos;i<n;i++){
//同层去重
if(i>pos&&candidates[i]==candidates[i-1]) continue;
sum+=candidates[i];
path.push_back(candidates[i]);
dfs(candidates,i+1);
sum-=candidates[i];
path.pop_back();
}
}
};
7. 组合总和3
组合总和3

递归条件修改一下就好,不多解释:
if(sum==n&&path.size()==k){
ret.push_back(path);
return;
}
class Solution {
public:
vector<vector<int>> ret;
vector<int> path;
int sum=0;
vector<vector<int>> combinationSum3(int k, int n) {
vector<int> arr(9,0);
for(int i=0;i<9;i++) arr[i]=i+1;
dfs(arr,n,k,0);
return ret;
}
void dfs(vector<int> &arr,int n,int k,int pos){
if(sum==n&&path.size()==k){
ret.push_back(path);
return;
}
if(sum>n||path.size()>k) return;
for(int i=pos;i<9;i++){
path.push_back(arr[i]);
sum+=arr[i];
dfs(arr,n,k,i+1);
sum-=arr[i];
path.pop_back();
}
}
};
8. 复原ip地址
复原IP地址

1.递归参数:dfs(int level,int index) //level表示当前的层级,index表示当前遍历字符的位置为index
2.递归出口:当此次递归的数字是一个以0开头但是不是0的字符串比如 “01”,这是非法的。或者超过了255,这个也是非法的。当然,当层级超过4的时候,也是需要截至的
3.递归的方向:每次选择1个或者2个或者3个数字来进行递归
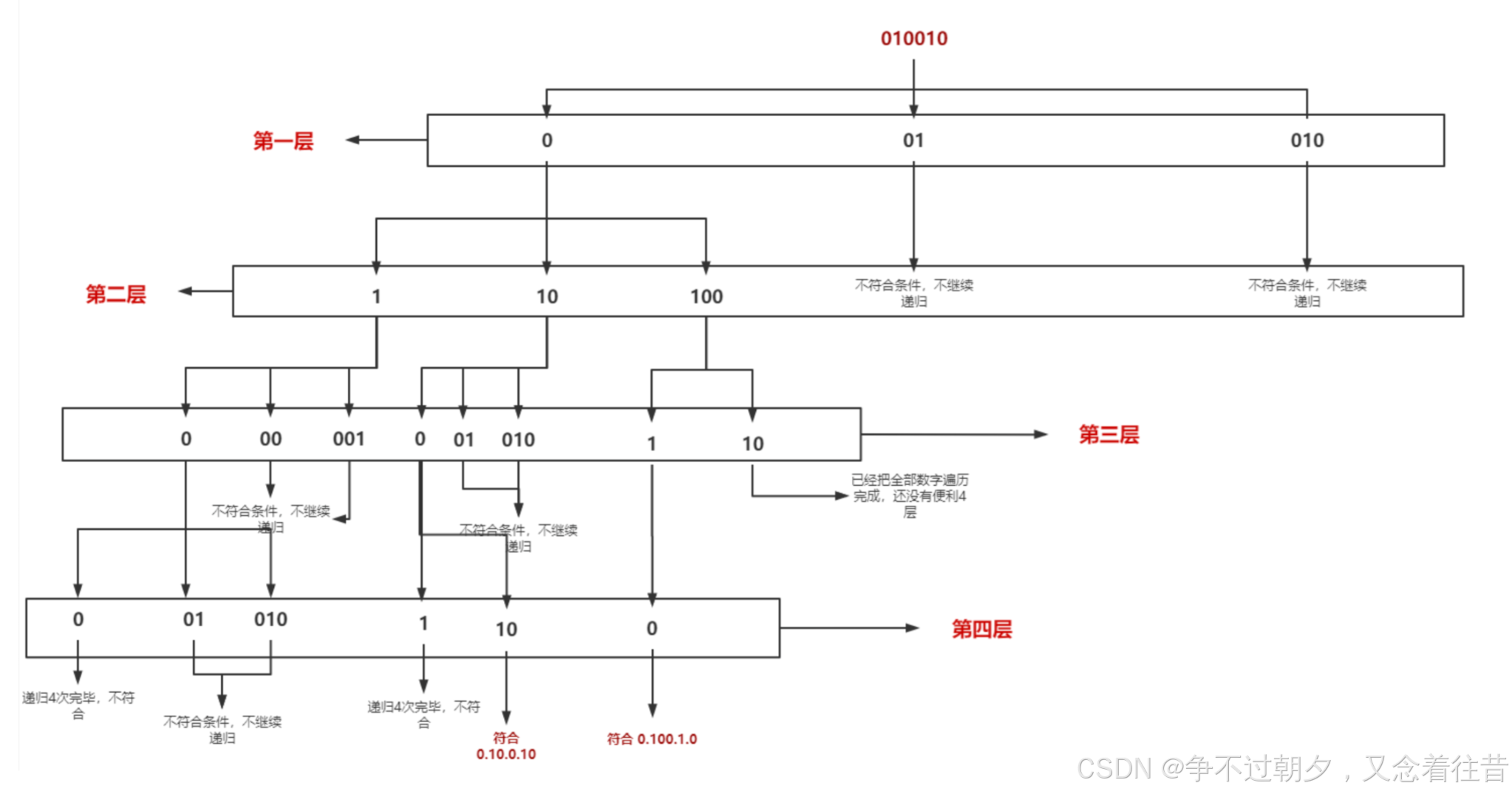
class Solution {
public:
vector<string> restoreIpAddresses(string s) {
vector<string> res;
string segments[4];
function<bool(string&)> check = [](string& s) {
return (s[0] != '0' || s == "0") && stoi(s) < 256;
};
function<void(int, int)> backtrack = [&](int idx, int segId) {
if (segId == 5 || idx == s.length()) {
if (segId == 5 && idx == s.length()) {
res.push_back(segments[0] + "." + segments[1] + "." +
segments[2] + "." + segments[3]);
}
return;
}
for (int i = 1; i <= 3; i++) {
if (idx + i > s.length())
return;
string sub = s.substr(idx, i);
if (check(sub)) {
segments[segId - 1] = sub;
backtrack(idx + i, segId + 1);
}
}
};
backtrack(0, 1);
return res;
}
};
9. 划分为K个相等的子集
划分为K个相等的子集

可以抽象为k个桶,每一个元素,每次都可以向这四个桶中任意一个放入,当所有元素全部遍历完毕之后看看,每个桶的元素是不是全是目标值就可以。
优化的地方是一开始先看看总和能不能除尽k,不能则直接return false
然后可以排个序,从大到小方,这样可以减少遍历次数
然后是如果某个桶加了某个元素大于目标值的话,那也就直接跳过,这种情况下不可能是正确结果
然后是如果某几个桶都是一样的,比如三个桶全是5,要放的元素是2,你把2放放在这三个桶中任意一个,结果都是一样的,所以放一个就行,另外俩桶就没必要再放一次了。
最后如果找到一种方法可以达到目的,那就直接return true就好了,剩下的没必要遍历了。
class Solution {
public:
bool canPartitionKSubsets(vector<int>& nums, int k) {
int sum = 0;
for (auto x : nums)
sum += x;
if (sum % k != 0)
return false;
int target = sum / k;
sort(nums.begin(), nums.end(), greater<int>());
vector<int> res(k, 0);
function<bool(int)> callback = [&](int pos) -> bool {
if (pos == nums.size()) {
return all_of(res.begin(), res.end(),
[&](int i) { return i == target; });
}
for (int i = 0; i < k; i++) {
if (res[i] + nums[pos] > target ||
(i > 0 && res[i] == res[i - 1]))
continue;
res[i] += nums[pos];
if (callback(pos + 1))
return true;
res[i] -= nums[pos];
}
return false;
};
return callback(0);
}
};
10. N皇后
N皇后

首先,我们在第一行放置第一个皇后,然后遍历棋盘的第二行,在可行的位置放置第二个皇后,然后再遍历第三行,在可行的位置放置第三个皇后,以此类推,直到放置了n个皇后为止。
我们需要用一个数组来记录每一行放置的皇后的列数。在每一行中,我们尝试放置一个皇后,并检查是否会和前面已经放置的皇后冲突。如果没有冲突,我们就继续递归地放置下一行的皇后,直到所有的皇后都放置完毕,然后把这个方案记录下来。
在检查皇后是否冲突时,我们可以用一个数组来记录每一列是否已经放置了皇后,并检查当前要放置的皇后是否会和已经放置的皇后冲突。对于对角线,我们可以用两个数组来记录从左上角到右下角的每一条对角线上是否已经放置了皇后,以及从右上角到左下角的每一条对角线上是否已经放置了皇后。
对于对角线是否冲突的判断可以通过以下流程解决:
- 从左上到右下:相同对角线的行列之差相同;
- 从右上到左下:相同对角线的行列之和相同。
因此,我们需要创建用于存储解决方案的二维字符串数组solutions,用于存储每个皇后的位置的一维整数数组queens,以及用于记录每一列和对角线上是否已经有皇后的布尔型数组columns、diagonals1和 diagonals2。
class Solution {
public:
bool check1[10], check2[20], check3[20];
vector<vector<string>> ret;
vector<string> path;
int n;
vector<vector<string>> solveNQueens(int _n) {
n = _n;
path.resize(n);
for (int i = 0; i < n; i++)
path[i].append(n, '.');
dfs(0);
return ret;
}
void dfs(int row) {
if (row == n)
ret.push_back(path);
for (int i = 0; i < n; i++) {
if (check1[i] == false && check2[row + i] == false &&
check3[row - i + n] == false) {
path[row][i] = 'Q';
check1[i] = check2[row + i] = check3[row - i + n] = true;
dfs(row + 1);
path[row][i] = '.';
check1[i] = check2[row + i] = check3[row - i + n] = false;
}
}
}
};