SKAttention选择核注意力
标题:SKAttention
期刊:IEEE2019
简介:
- 动机:增大感受野来提升性能、多尺度信息聚合方式
- 解决的问题:自适应调整感受野大小
- 创新性:提出选择性内核(SK)卷积softmax来进行自适应选择
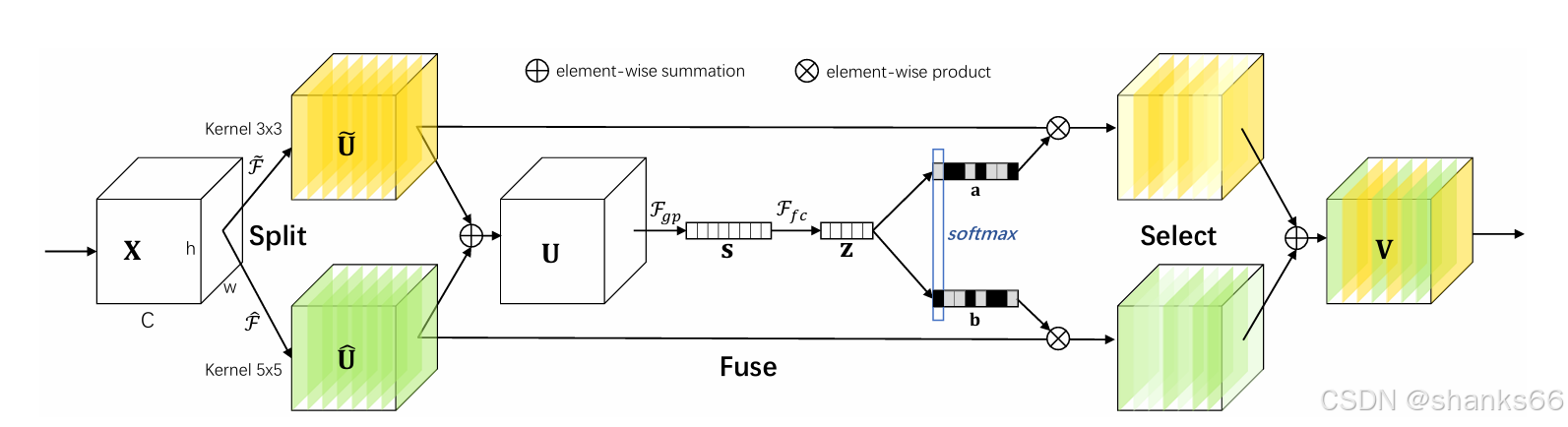
模型结构
模型代码
import numpy as np
import torch
from torch import nn
from torch.nn import init
from collections import OrderedDict
class SKAttention(nn.Module):
def __init__(self, channel=512, kernels=[1, 3, 5, 7], reduction=16, group=1, L=32):
super().__init__()
self.d = max(L, channel // reduction)
self.convs = nn.ModuleList([])
for k in kernels:
self.convs.append(
nn.Sequential(OrderedDict([
('conv', nn.Conv2d(channel, channel, kernel_size=k, padding=k // 2, groups=group)),
('bn', nn.BatchNorm2d(channel)),
('relu', nn.ReLU())
]))
)
self.fc = nn.Linear(channel, self.d)
self.fcs = nn.ModuleList([])
for i in range(len(kernels)):
self.fcs.append(nn.Linear(self.d, channel))
self.softmax = nn.Softmax(dim=0)
def forward(self, x):
bs, c, _, _ = x.size()
conv_outs = []
for conv in self.convs:
conv_outs.append(conv(x))
feats = torch.stack(conv_outs, 0)
U = sum(conv_outs)
S = U.mean(-1).mean(-1)
Z = self.fc(S)
weights = []
for fc in self.fcs:
weight = fc(Z)
weights.append(weight.view(bs, c, 1, 1))
attention_weughts = torch.stack(weights, 0)
attention_weughts = self.softmax(attention_weughts)
V = (attention_weughts * feats).sum(0)
return V
if __name__ == '__main__':
input = torch.rand(1,64,256,256).cuda()
model = SKAttention(channel=64, reduction=8).cuda()
output = model (input)
print('input_size:', input.size())
print('output_size:', output.size())
print("最大内存占用:", torch.cuda.max_memory_allocated() // 1024 // 1024, "MB")