前端常见面试题(不断更新版)
目录
一、HTTP/浏览器
(一)浏览器缓存机制——强缓存和协商缓存
1. 强缓存
2. 协商缓存
3. 强缓存和协商缓存的区别
4. 缓存机制的整体流程
(二)常见的HTTP状态码
1. 常见状态码总结
2. 状态码分类记忆
3. 实际应用场景
(三)前端优化
1. 降低请求量
2. 加快请求速度
3. 缓存
4. 渲染
5. 总结
二、 JS
(一)this的理解
(二)es6的新特性
1. 块级作用域变量声明:let 和 const
2. 箭头函数
3. 解构赋值
4. 扩展运算符和剩余参数
5. Promise 和异步编程
6. 新增数据结构:Map、Set、WeakMap 和 WeakSet
(三)深克隆和浅克隆
1. 浅克隆
2. 深克隆
3. 浅克隆 vs 深克隆
(四)= 和 == 和 === 区别
(五) forEach、for...in 、for...of三者的区别和使用
1. forEach
2. for...in
3. for...of
4. 总结
(六)delete属性回影响原型链吗,delete操作和把属性置空一样吗
1. delete 属性会影响原型链吗?
2. delete 操作和把属性置空一样吗?
3. 总结
一、HTTP/浏览器
(一)浏览器缓存机制——强缓存和协商缓存
1. 强缓存
强缓存是指浏览器在请求资源时,先检查本地缓存,如果缓存有效,则直接从缓存中获取资源,不会发送请求到服务器。
工作流程:
-
浏览器请求资源:
-
浏览器第一次请求资源时,服务器会返回资源,并在响应头中设置缓存相关的字段(如
Cache-Control或Expires)。
-
-
缓存资源:
-
浏览器将资源缓存到本地,并记录缓存的有效时间。
-
-
再次请求资源:
-
当浏览器再次请求该资源时,先检查本地缓存是否有效:
-
如果缓存未过期(在有效时间内),直接从缓存中获取资源,并返回状态码
200 (from cache)。 -
如果缓存已过期,则进入协商缓存流程。
-
-
-
不发送请求到服务器:
-
在强缓存生效期间,浏览器不会向服务器发送请求。
-
相关响应头:
Cache-Control:
常用值:
max-age=3600:缓存有效时间为 3600 秒(1 小时)。
no-cache:禁用强缓存,直接进入协商缓存。
no-store:禁止缓存,每次请求都从服务器获取资源。
Expires:
指定缓存的过期时间(绝对时间),例如
Expires: Wed, 21 Oct 2023 07:28:00 GMT。优先级低于
Cache-Control。
2. 协商缓存
协商缓存是指浏览器在请求资源时,先向服务器发送请求,由服务器判断缓存是否可用。如果缓存可用,服务器返回状态码 304 (Not Modified),浏览器从缓存中获取资源;如果缓存不可用,服务器返回新的资源。
工作流程:
-
浏览器请求资源:
-
浏览器第一次请求资源时,服务器返回资源,并在响应头中设置缓存标识(如
Last-Modified或ETag)。
-
-
缓存资源:
-
浏览器将资源缓存到本地,并记录缓存标识。
-
-
再次请求资源:
-
当浏览器再次请求该资源时,会向服务器发送请求,并在请求头中携带缓存标识:
-
If-Modified-Since:对应Last-Modified。 -
If-None-Match:对应ETag。
-
-
-
服务器验证缓存:
-
服务器根据请求头中的缓存标识,判断资源是否发生变化:
-
如果资源未变化,返回状态码
304 (Not Modified),浏览器从缓存中获取资源。 -
如果资源已变化,返回新的资源,并更新缓存标识。
-
-
相关响应头和请求头:
Last-Modified和If-Modified-Since:
Last-Modified:服务器返回的资源最后修改时间。
If-Modified-Since:浏览器再次请求时,携带上次收到的Last-Modified值。
ETag和If-None-Match:
ETag:服务器返回的资源唯一标识(通常是哈希值)。
If-None-Match:浏览器再次请求时,携带上次收到的ETag值。
3. 强缓存和协商缓存的区别
| 特性 | 强缓存 | 协商缓存 |
|---|---|---|
| 是否发送请求 | 否,直接从缓存获取 | 是,发送请求到服务器验证缓存 |
| 状态码 | 200 (from cache) | 304 (Not Modified) |
| 优先级 | 先检查强缓存,失效后再走协商缓存 | 强缓存失效后使用 |
| 响应头 | Cache-Control、Expires | Last-Modified、ETag |
| 请求头 | 无 | If-Modified-Since、If-None-Match |
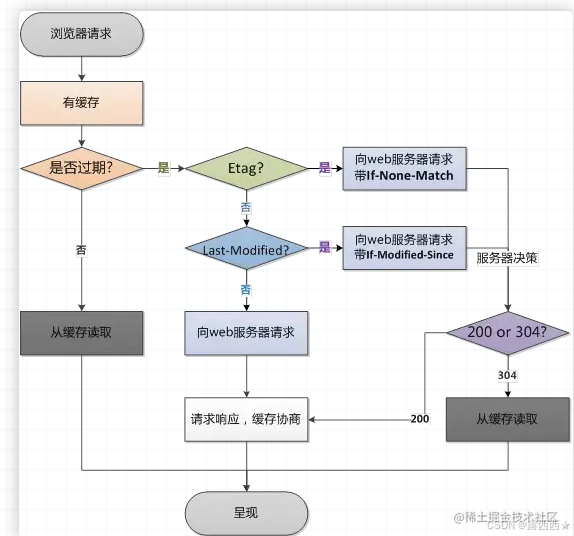
4. 缓存机制的整体流程
-
浏览器请求资源时,先检查强缓存:
-
如果强缓存有效,直接返回
200 (from cache)。 -
如果强缓存失效,进入协商缓存流程。
-
-
浏览器向服务器发送请求,携带缓存标识:
-
如果资源未变化,返回
304 (Not Modified),浏览器从缓存中获取资源。 -
如果资源已变化,返回新的资源,并更新缓存。
-
(二)常见的HTTP状态码
-
100 Continue:客户端应继续发送请求的剩余部分。通常用于 POST 或 PUT 请求,客户端先发送请求头,服务器确认后再发送请求体。
-
101 Switching Protocols:服务器同意客户端请求,切换协议(例如,从 HTTP 切换到 WebSocket)。
-
200 OK:请求成功,服务器返回请求的资源。最常见的状态码。
-
201 Created:请求成功,并且服务器创建了新资源(例如,POST 请求创建了新资源)。
-
301 Moved Permanently:请求的资源已永久移动到新位置,客户端应使用新的 URL。
-
302 Found:请求的资源临时移动到新位置,客户端应使用新的 URL。
-
304 Not Modified:资源未修改,客户端可以使用缓存的版本(协商缓存)。
-
400 Bad Request:请求语法错误或参数无效,服务器无法理解。
-
401 Unauthorized:请求需要身份验证,客户端未提供有效的身份凭证。
-
403 Forbidden:服务器拒绝请求,客户端没有访问权限。
-
404 Not Found:请求的资源未找到,URL 可能错误或资源已被删除。
-
500 Internal Server Error:服务器内部错误,无法完成请求(例如,代码异常)。
-
502 Bad Gateway:服务器作为网关或代理时,从上游服务器收到无效响应。
-
503 Service Unavailable:服务器暂时不可用(例如,服务器过载或维护)。
-
504 Gateway Timeout:服务器作为网关或代理时,未能及时从上游服务器收到响应。
1. 常见状态码总结
| 状态码 | 类别 | 含义 |
|---|---|---|
| 200 | 成功 | 请求成功 |
| 301 | 重定向 | 资源永久移动 |
| 302 | 重定向 | 资源临时移动 |
| 304 | 缓存 | 资源未修改,使用缓存 |
| 400 | 客户端错误 | 请求语法错误 |
| 401 | 客户端错误 | 未授权 |
| 403 | 客户端错误 | 禁止访问 |
| 404 | 客户端错误 | 资源未找到 |
| 500 | 服务器错误 | 服务器内部错误 |
| 502 | 服务器错误 | 网关错误 |
| 503 | 服务器错误 | 服务不可用 |
| 504 | 服务器错误 | 网关超时 |
2. 状态码分类记忆
-
1xx:信息性状态码(继续处理)。
-
2xx:成功状态码(请求成功)。
-
3xx:重定向状态码(需要进一步操作)。
-
4xx:客户端错误状态码(请求有误)。
-
5xx:服务器错误状态码(服务器处理失败)。
3. 实际应用场景
-
200 OK:
-
用户访问一个页面,服务器成功返回页面内容。
-
-
301 Moved Permanently:
-
网站更换域名,旧域名永久重定向到新域名。
-
-
404 Not Found:
-
用户访问一个不存在的页面,服务器返回 404。
-
-
500 Internal Server Error:
-
服务器代码出现未捕获的异常,返回 500。
-
-
503 Service Unavailable:
-
服务器因维护或过载暂时不可用,返回 503。
-
(三)前端优化
1. 降低请求量
减少 HTTP 请求数是前端优化的核心目标之一,因为每个请求都会增加延迟和带宽消耗。
(1) 合并资源
-
方法:将多个小文件合并为一个文件。将多个 CSS 文件合并为一个
styles.css。将多个 JS 文件合并为一个scripts.js。 -
工具:Webpack、Gulp 等构建工具支持文件合并。
(2) 减少 HTTP 请求数
-
方法:使用 CSS Sprites 将多个小图标合并为一张大图,通过
background-position显示特定部分。使用图标字体(如 Font Awesome)代替图片图标。内联小资源(如 Base64 编码的小图片)。 -
优点:减少请求数,降低延迟。
(3) Minify / Gzip 压缩
-
Minify:
-
删除代码中的空格、注释和换行,减小文件体积。
-
示例:将
var x = 1; // comment压缩为var x=1;。 -
工具:UglifyJS(JS)、CSSNano(CSS)。
-
-
Gzip 压缩:
-
服务器启用 Gzip 压缩,减小传输体积。
-
示例:将 100KB 的文件压缩为 30KB。
-
配置:Nginx 或 Apache 中启用 Gzip。
-
(4) 使用 WebP 图片格式
(5) LazyLoad(懒加载)
-
方法:延迟加载非首屏资源(如图片、视频)。
-
实现:
-
使用
IntersectionObserverAPI 监听元素是否进入视口。 -
图片懒加载示例:
<img data-src="image.jpg" class="lazyload" /> <script> document.addEventListener("DOMContentLoaded", function() { const images = document.querySelectorAll(".lazyload"); images.forEach(img => { img.src = img.dataset.src; }); }); </script>
-
-
优点:减少首屏加载时间,提升用户体验。
2. 加快请求速度
优化请求速度可以减少用户等待时间,提升页面加载性能。
(1) 预解析 DNS
方法:使用
<link rel="dns-prefetch">提前解析域名。减少 DNS 解析时间。(2) 减少域名数
方法:减少页面中使用的域名数量。
原因:每个域名都需要进行 DNS 解析和 TCP 连接,增加延迟。可以将静态资源放在同一个域名下。
(3) 并行加载
方法:利用浏览器多线程特性,同时加载多个资源。使用 HTTP/2 协议,支持多路复用。
(4) CDN 分发
方法:使用 CDN(内容分发网络)加速静态资源加载。将资源分发到离用户更近的节点,减少延迟。减轻服务器负载。
3. 缓存
合理使用缓存可以减少重复请求,提升页面加载速度。
(1) HTTP 协议缓存,强缓存和协商缓存
(2) 离线缓存 Manifest
方法:使用 HTML5 的
Application Cache或 Service Worker 实现离线缓存。<html manifest="app.manifest">(3) 离线数据缓存 localStorage
4. 渲染
优化渲染性能可以提升页面的响应速度和用户体验。
(1) JS/CSS 优化
CSS:将关键 CSS 内联到
<style>标签中,减少首屏渲染时间。避免使用@import,因为它会阻塞渲染。JS:将 JS 放在页面底部,或使用
defer/async属性异步加载。<script src="script.js" defer></script>(2) 加载顺序
方法:优先加载关键资源(如首屏内容),延迟加载非关键资源。
工具:使用 Webpack 的代码分割(Code Splitting)功能。
(3) 服务端渲染(SSR)
方法:在服务器端生成 HTML,直接返回给客户端。提升首屏加载速度。改善 SEO。
框架:Next.js(React)、Nuxt.js(Vue)。
(4) Pipeline
方法:利用 HTTP/2 的多路复用特性,并行传输多个资源。减少延迟,提升加载速度。
5. 总结
降低请求量:合并资源、压缩文件、使用 WebP、懒加载。
加快请求速度:预解析 DNS、减少域名、使用 CDN。
缓存:HTTP 缓存、离线缓存、localStorage。
渲染:优化 JS/CSS、服务端渲染、利用 HTTP/2。
二、 JS
(一)this的理解
this表示当前对象,this的指向是根据调用的上下文来决定的,默认指向window对象,指向window对象时可以省略不写。
全局环境: this始终指向的是window对象。
局部环境: 在全局作用域下直接调用函数,this指向window 对象函数调用,哪个对象调用就指向哪个对象 使用new实例化对象,在构造函数中的this指向实例化对象。使用call或apply可以改变this的指向。
总结:this始终指向最后一个调用它的函数的对象。
this的值取决于函数的调用方式。- 普通函数调用时,
this通常是全局对象(严格模式下是undefined)。- 对象方法调用时,
this指向调用该方法的对象。- 构造函数调用时,
this指向正在创建的对象。- 箭头函数不会创建自己的
this,而是继承自定义它的上下文中的this。- 可以使用
call、apply和bind显式设置this的值。
(二)es6的新特性
1. 块级作用域变量声明:let 和 const
let:用于声明块级作用域的变量,解决了var的变量提升和作用域问题。const:用于声明块级作用域的常量,一旦赋值就不能再改变。
let定义块级作用域变量 没有变量的提升,必须先声明后使用 let声明的变量,不能与前面的let,var,conset声明的变量重名。
const 定义只读变量。const声明变量的同时必须赋值,const声明的变量必须初始化,一旦初始化完毕就不允许修改 const声明变量也是一个块级作用域变量,没有“变量的提升”,必须先声明后,使用const声明的变量不能与前面的变量重名。 const定义的对象\数组中的属性值可以修改,基础数据类型不可以。
2. 箭头函数
- 箭头函数提供了更简洁的函数表达式语法,并且不会创建自己的
this,而是继承自定义它的上下文中的this。
箭头函数的特点:箭头函数相当于匿名函数,是不能作为构造函数的,不能被new。
箭头函数没有arguments实参集合,取而代之用...剩余运算符解决,箭头函数没有自己的this。他的this是继承当前上下文中的this。
箭头函数没有函数原型,箭头函数不能当做Generator函数,不能使用yield关键字,不能使用call、apply、bind改变箭头函数中this指向。
3. 解构赋值
- 允许从数组或对象中提取值,并将其赋给变量。
// 数组解构
const [a, b] = [1, 2];
console.log(a); // 输出 1
console.log(b); // 输出 2
// 对象解构
const obj = { x: 10, y: 20 };
const { x, y } = obj;
console.log(x); // 输出 10
console.log(y); // 输出 204. 扩展运算符和剩余参数
- 扩展运算符:用于展开数组或对象。
- 剩余参数:用于将多个参数收集到一个数组中。
// 扩展运算符
const arr1 = [1, 2, 3];
const arr2 = [...arr1, 4, 5];
console.log(arr2); // 输出 [1, 2, 3, 4, 5]
// 剩余参数
function sum(...numbers) {
return numbers.reduce((acc, curr) => acc + curr, 0);
}
console.log(sum(1, 2, 3, 4)); // 输出 105. Promise 和异步编程
Promise对象用于表示异步操作的最终完成(或失败)及其结果值。
6. 新增数据结构:Map、Set、WeakMap 和 WeakSet
Map:键值对的集合,键可以是任意类型。Set:值的集合,值不重复。WeakMap和WeakSet:弱引用版本的Map和Set,键(对于WeakMap)或值(对于WeakSet)是弱引用的,不会阻止垃圾回收。
(三)深克隆和浅克隆
1. 浅克隆
浅克隆会创建一个新对象,但新对象中的属性只是对原对象属性的引用。如果属性是基本数据类型(如数字、字符串、布尔值等),则直接复制其值;如果属性是引用数据类型(如对象、数组等),则复制的是引用,而不是实际的对象。
特点:
- 浅克隆只复制对象的第一层属性。
- 嵌套对象(如对象的属性是另一个对象)仍然指向原对象中的嵌套对象。
实现方式:
- Object.assign()(用于对象)
- Array.prototype.slice() 或 Array.from()(用于数组)
- 扩展运算符(Spread Operator)
{ ...obj }或[ ...arr ]
// 使用 Object.assign() 实现浅克隆
const original = { a: 1, b: { c: 2 } };
const shallowClone = Object.assign({}, original);
console.log(shallowClone); // 输出: { a: 1, b: { c: 2 } }
console.log(shallowClone.b === original.b); // 输出: true(共享同一个引用)
// 修改原对象的嵌套对象
original.b.c = 42;
console.log(shallowClone.b.c); // 输出: 42(浅克隆的对象也受到影响)
// 使用扩展运算符实现浅克隆
const arr = [1, 2, { a: 3 }];
const shallowCloneArr = [ ...arr ];
console.log(shallowCloneArr); // 输出: [1, 2, { a: 3 }]
console.log(shallowCloneArr[2] === arr[2]); // 输出: true(共享同一个引用)
// 修改原数组的嵌套对象
arr[2].a = 42;
console.log(shallowCloneArr[2].a); // 输出: 42(浅克隆的数组也受到影响)2. 深克隆
深克隆会创建一个新对象,并递归地复制所有层级的属性。新对象与原对象完全独立,修改新对象不会影响原对象,反之亦然。
特点:
- 深克隆会复制对象的所有层级。
- 嵌套对象也会被递归地克隆,确保新对象与原对象完全独立。
实现方式:
- 手动递归复制
- JSON 序列化和反序列化(适用于纯 JSON 数据,不支持函数、
undefined、Symbol等) - 第三方库(如 Lodash 的
_.cloneDeep方法) - 结构化克隆算法(如
structuredClone,现代浏览器支持)
function deepClone(obj) {
if (obj === null || typeof obj !== 'object') {
return obj; // 基本类型直接返回
}
if (Array.isArray(obj)) {
return obj.map(deepClone); // 递归克隆数组
}
const clone = {};
for (const key in obj) {
if (obj.hasOwnProperty(key)) {
clone[key] = deepClone(obj[key]); // 递归克隆对象
}
}
return clone;
}
const original = { a: 1, b: { c: 2 } };
const deepCloned = deepClone(original);
console.log(deepCloned); // 输出: { a: 1, b: { c: 2 } }
console.log(deepCloned.b === original.b); // 输出: false(不同的引用)
// 使用 JSON 序列化和反序列化
const original = { a: 1, b: { c: 2 } };
const deepCloned = JSON.parse(JSON.stringify(original));
console.log(deepCloned); // 输出: { a: 1, b: { c: 2 } }
console.log(deepCloned.b === original.b); // 输出: false(不同的引用)
// 使用结构化克隆算法
const original = { a: 1, b: { c: 2 } };
const deepCloned = structuredClone(original);
console.log(deepCloned); // 输出: { a: 1, b: { c: 2 } }
console.log(deepCloned.b === original.b); // 输出: false(不同的引用)
注意:
1,JSON 方法有以下限制:
- 无法克隆函数、
undefined、Symbol。- 无法处理循环引用(会抛出错误)。
- 日期对象会被转换为字符串。
2,structuredClone是现代浏览器和 Node.js 17+ 支持的原生方法,能够处理循环引用和更多数据类型。
3. 浅克隆 vs 深克隆
| 特性 | 浅克隆 | 深克隆 |
|---|---|---|
| 复制深度 | 仅复制第一层属性 | 递归复制所有层级 |
| 性能 | 较快,适合浅层对象 | 较慢,适合深层嵌套对象 |
| 引用共享 | 嵌套对象共享引用 | 嵌套对象完全独立 |
| 使用场景 | 对象结构简单,无嵌套或无需修改嵌套对象 | 对象结构复杂,需要完全独立的副本 |
(四)= 和 == 和 === 区别
=(赋值操作符)
==(相等操作符,抽象相等比较):==返回一个布尔值;相等返回true,不相等返回false。
- 作用:比较两个值是否相等,在比较前会进行类型转换(Type Coercion)。
- 用法:用于检查两个值是否相等,但不要求类型相同。如果是对象数据类型的比较,比较的是空间地址。
===(严格相等操作符,严格相等比较):
- 作用:比较两个值是否相等,不进行类型转换。
- 用法:用于检查两个值是否相等,且类型必须相同。当使用严格相等操作符
===比较两个对象(包括数组、函数等引用数据类型)时,比较的是它们在内存中的引用地址。
(五) forEach、for...in 、for...of三者的区别和使用
1. forEach
- 专门用于遍历数组。
- 不能中断循环(即没有
break或continue的功能)。 - 不返回新数组,只是对每个元素执行提供的函数。
const numbers = [1, 2, 3, 4, 5];
numbers.forEach((number, index) => {
console.log(`Number at index ${index} is ${number}`);
});2. for...in
- 用于遍历对象的可枚举属性(包括原型链上的属性,除非使用
hasOwnProperty方法过滤)。 - 遍历的是属性名(字符串形式)。
- 主要用于对象,但也可以遍历数组(不推荐,因为会遍历数组的所有可枚举属性,包括索引和方法)。
const person = {
name: "John",
age: 30,
city: "New York"
};
for (const key in person) {
if (person.hasOwnProperty(key)) {
console.log(`${key}: ${person[key]}`);
}
}3. for...of
- 用于遍历可迭代对象(包括数组、字符串、Map、Set等)。
- 遍历的是对象的值。
- 可以直接中断循环(使用
break、continue和return)。
const numbers = [1, 2, 3, 4, 5];
for (const number of numbers) {
console.log(number);
}
const string = "Hello";
for (const char of string) {
console.log(char);
}4. 总结
forEach:适用于遍历数组,无法中断循环,且不能用于对象。for...in:适用于遍历对象的可枚举属性,包括原型链上的属性(需要hasOwnProperty来过滤),也可以遍历数组,但不推荐。for...of:适用于遍历所有可迭代对象(数组、字符串、Map、Set等),遍历的是值,可以中断循环。
(六)delete属性回影响原型链吗,delete操作和把属性置空一样吗
1. delete 属性会影响原型链吗?
-
delete操作符用于删除对象的自有属性(即对象自身定义的属性),而不会影响原型链上的属性。 -
如果对象自身没有该属性,而是从原型链上继承的,
delete操作不会对原型链上的属性产生任何影响。
const parent = { name: "Parent" };
const child = Object.create(parent); // child 继承自 parent
console.log(child.name); // 输出: "Parent" (来自原型链)
delete child.name; // 尝试删除 child 的 name 属性
console.log(child.name); // 输出: "Parent" (仍然来自原型链)-
在上面的例子中,
child对象本身没有name属性,name是从parent继承的。delete child.name不会影响parent的name属性。
2. delete 操作和把属性置空一样吗?
-
delete操作:-
完全删除对象的属性。
-
删除后,对象不再拥有该属性。
-
如果访问被删除的属性,会返回
undefined,但属性本身已不存在。
-
-
把属性置空:
-
将属性的值设置为
null或undefined,但属性仍然存在于对象中。 -
属性仍然可以被枚举(例如通过
for...in或Object.keys())。
-
const obj = { name: "Alice", age: 25 };
// 把属性置空
obj.name = null;
console.log(obj.name); // 输出: null
console.log("name" in obj); // 输出: true (属性仍然存在)
// 使用 delete 删除属性
delete obj.age;
console.log(obj.age); // 输出: undefined
console.log("age" in obj); // 输出: false (属性已被删除)-
在上面的例子中:
-
obj.name = null只是将name属性的值设置为null,但name属性仍然存在。 -
delete obj.age则完全删除了age属性,age不再存在于obj中。
-
3. 总结
| 操作 | 影响 | 示例 |
|---|---|---|
delete 操作 | 完全删除对象的自有属性,不影响原型链。删除后属性不存在。 | delete obj.name |
| 把属性置空 | 将属性值设置为 null 或 undefined,但属性仍然存在。 | obj.name = null |