定积分与不定积分在概率统计中的应用
前言
本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见《机器学习数学通关指南》
ima 知识库
知识库广场搜索:
| 知识库 | 创建人 |
|---|---|
| 机器学习 | @Shockang |
| 机器学习数学基础 | @Shockang |
| 深度学习 | @Shockang |
正文
📝 引言
在机器学习的数学基础中,概率论占据核心位置。而连续型随机变量的统计特性计算,主要依赖于积分运算。本文将深入探讨定积分与不定积分在计算概率密度函数的期望值、方差等统计量中的关系与应用,为机器学习中的概率模型打下坚实基础。
🔍 一、关键概念解析
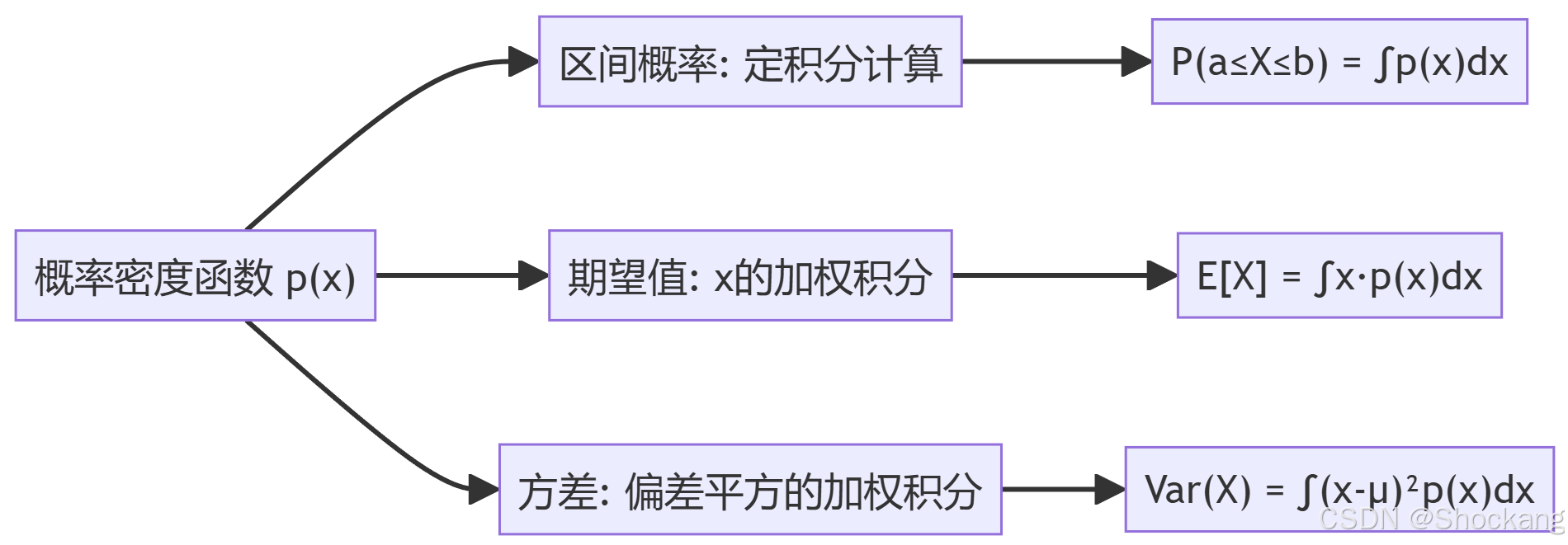
1.1 概率密度函数 (Probability Density Function, PDF)
连续型随机变量X的概率密度函数p(x)满足三个基本特性:
- 非负性:p(x) ≥ 0
- 归一性: ∫ − ∞ + ∞ p ( x ) d x = 1 \int_{-\infty}^{+\infty} p(x)dx = 1 ∫−∞+∞p(x)dx=1
- 区间概率: P ( a < X ≤ b ) = ∫ a b p ( x ) d x P(a < X \leq b) = \int_a^b p(x)dx P(a<X≤b)=∫abp(x)dx
区间概率的计算正是定积分的直接应用,表示概率密度曲线下方的面积。
1.2 数学期望 (Expectation)
连续型随机变量的期望定义为:
E [ X ] = ∫ − ∞ + ∞ x ⋅ p ( x ) d x E[X] = \int_{-\infty}^{+\infty} x \cdot p(x)dx E[X]=∫−∞+∞x⋅p(x)dx
这里使用定积分计算加权平均值,其中权重为概率密度。期望代表了随机变量的"平均位置"或"中心趋势"。
1.3 方差 (Variance)
方差度量随机变量围绕期望值的分散程度:
V a r ( X ) = E [ ( X − μ ) 2 ] = ∫ − ∞ + ∞ ( x − μ ) 2 p ( x ) d x Var(X) = E[(X-\mu)^2] = \int_{-\infty}^{+\infty} (x-\mu)^2 p(x)dx Var(X)=E[(X−μ)2]=∫−∞+∞(x−μ)2p(x)dx
其中μ=E[X]。方差也可以通过以下公式计算:
V a r ( X ) = E [ X 2 ] − ( E [ X ] ) 2 = ∫ − ∞ + ∞ x 2 p ( x ) d x − μ 2 Var(X) = E[X^2] - (E[X])^2 = \int_{-\infty}^{+\infty} x^2 p(x)dx - \mu^2 Var(X)=E[X2]−(E[X])2=∫−∞+∞x2p(x)dx−μ2
这种计算方式往往更为便捷。
🔄 二、定积分与不定积分在统计量计算中的关系
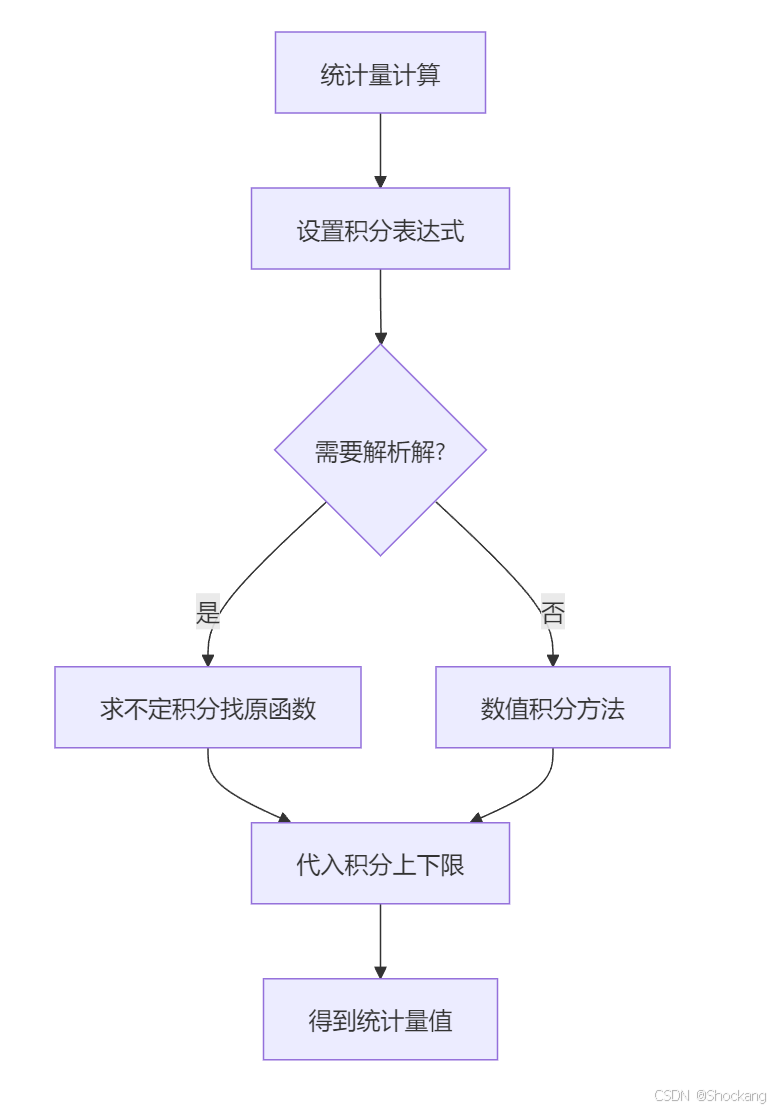
2.1 作用区分
- 定积分:直接计算统计量的数值结果,如期望、方差等
- 不定积分:寻找原函数,为定积分计算提供工具
2.2 计算过程中的配合
在计算概率统计量时,我们通常需要:
- 使用不定积分找到原函数 F ( x ) = ∫ f ( x ) d x F(x) = \int f(x)dx F(x)=∫f(x)dx
- 应用定积分公式 ∫ a b f ( x ) d x = F ( b ) − F ( a ) \int_a^b f(x)dx = F(b) - F(a) ∫abf(x)dx=F(b)−F(a) 得到最终结果
📈 三、典型概率分布的统计量计算
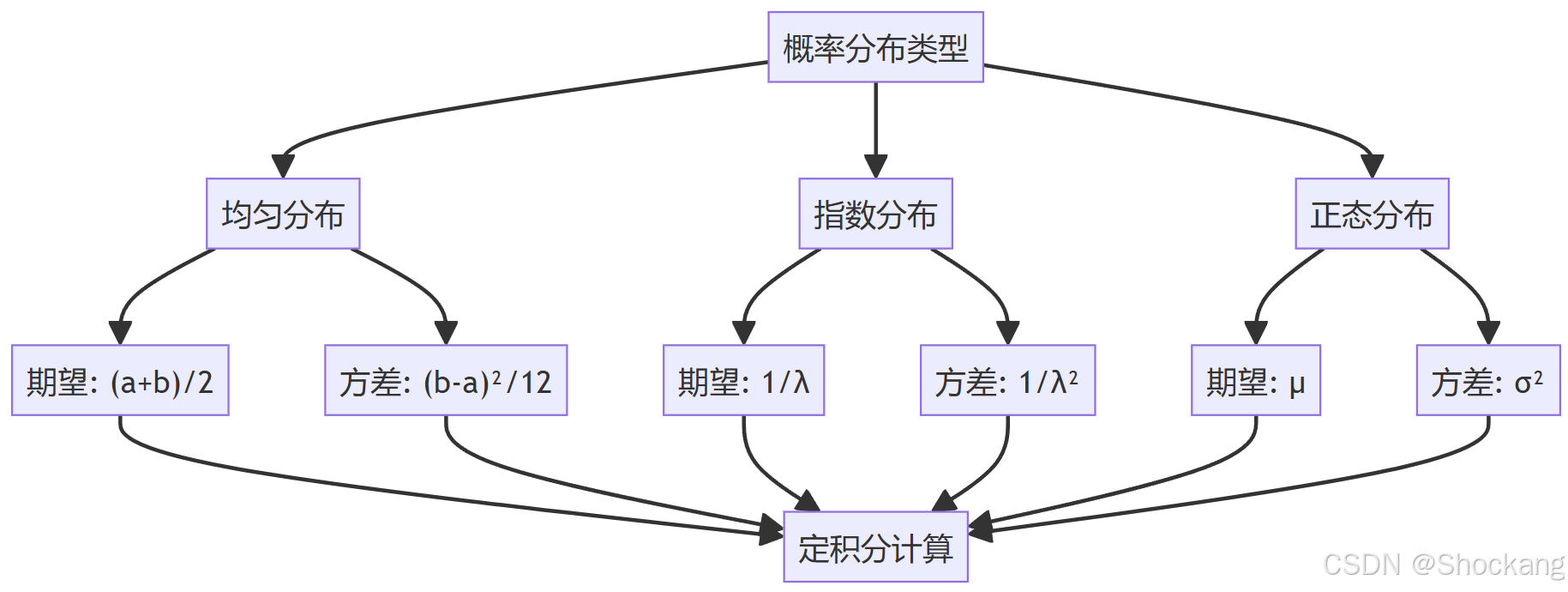
3.1 均匀分布 U(a,b)
密度函数: p ( x ) = 1 b − a , a ≤ x ≤ b p(x) = \frac{1}{b-a}, a \leq x \leq b p(x)=b−a1,a≤x≤b
期望计算:
E
[
X
]
=
∫
a
b
x
⋅
1
b
−
a
d
x
=
1
b
−
a
⋅
x
2
2
∣
a
b
=
a
+
b
2
E[X] = \int_a^b x \cdot \frac{1}{b-a}dx = \frac{1}{b-a} \cdot \left. \frac{x^2}{2} \right|_a^b = \frac{a+b}{2}
E[X]=∫abx⋅b−a1dx=b−a1⋅2x2
ab=2a+b
方差计算:
V
a
r
(
X
)
=
∫
a
b
x
2
⋅
1
b
−
a
d
x
−
(
a
+
b
2
)
2
=
(
b
−
a
)
2
12
Var(X) = \int_a^b x^2 \cdot \frac{1}{b-a}dx - \left( \frac{a+b}{2} \right)^2 = \frac{(b-a)^2}{12}
Var(X)=∫abx2⋅b−a1dx−(2a+b)2=12(b−a)2
均匀分布的统计量计算展示了定积分的直接应用。
3.2 指数分布 Exp(λ)
密度函数: p ( x ) = λ e − λ x , x ≥ 0 p(x) = \lambda e^{-\lambda x}, x \geq 0 p(x)=λe−λx,x≥0
期望计算:
E
[
X
]
=
∫
0
∞
x
⋅
λ
e
−
λ
x
d
x
E[X] = \int_0^{\infty} x \cdot \lambda e^{-\lambda x}dx
E[X]=∫0∞x⋅λe−λxdx
应用分部积分法:令 u = x , d v = λ e − λ x d x u = x, dv = \lambda e^{-\lambda x}dx u=x,dv=λe−λxdx
得到: E [ X ] = − x e − λ x ∣ 0 ∞ + ∫ 0 ∞ e − λ x d x = 0 + 1 λ = 1 λ E[X] = \left. -xe^{-\lambda x} \right|_0^{\infty} + \int_0^{\infty} e^{-\lambda x}dx = 0 + \frac{1}{\lambda} = \frac{1}{\lambda} E[X]=−xe−λx 0∞+∫0∞e−λxdx=0+λ1=λ1
方差计算:
V
a
r
(
X
)
=
E
[
X
2
]
−
(
E
[
X
]
)
2
=
2
λ
2
−
1
λ
2
=
1
λ
2
Var(X) = E[X^2] - (E[X])^2 = \frac{2}{\lambda^2} - \frac{1}{\lambda^2} = \frac{1}{\lambda^2}
Var(X)=E[X2]−(E[X])2=λ22−λ21=λ21
指数分布的计算展示了处理无穷积分区间的技巧。
3.3 正态分布 N(μ,σ²)
密度函数: p ( x ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 p(x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}} p(x)=σ2π1e−2σ2(x−μ)2
期望计算:
E
[
X
]
=
∫
−
∞
∞
x
⋅
1
σ
2
π
e
−
(
x
−
μ
)
2
2
σ
2
d
x
E[X] = \int_{-\infty}^{\infty} x \cdot \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}dx
E[X]=∫−∞∞x⋅σ2π1e−2σ2(x−μ)2dx
通过变量替换 z = x − μ σ z = \frac{x-\mu}{\sigma} z=σx−μ,可证明 E [ X ] = μ E[X] = \mu E[X]=μ
方差计算:
利用特殊积分公式和变量替换,可证明
V
a
r
(
X
)
=
σ
2
Var(X) = \sigma^2
Var(X)=σ2
正态分布的计算展示了变量替换和对称性在积分中的应用。
🔄 四、离散与连续随机变量的统计量计算比较
4.1 计算方式对比
| 概念 | 离散随机变量 | 连续随机变量 | 积分类型 |
|---|---|---|---|
| 概率度量 | P(X=xᵢ) | p(x)dx | - |
| 期望计算 | ∑ xᵢP(xᵢ) | ∫ x·p(x)dx | 定积分 |
| 方差计算 | ∑ (xᵢ-μ)²P(xᵢ) | ∫ (x-μ)²p(x)dx | 定积分 |
| 主要工具 | 求和 | 积分 | 定积分 |
离散随机变量使用求和计算统计量,而连续随机变量则需要积分。积分可以理解为连续情况下的"无穷细分求和"。
4.2 从离散到连续的过渡
当离散点无限增多、间距趋于零时,求和转变为积分:
lim n → ∞ ∑ i = 1 n f ( x i ) Δ x = ∫ a b f ( x ) d x \lim_{n \to \infty} \sum_{i=1}^{n} f(x_i)\Delta x = \int_a^b f(x)dx limn→∞∑i=1nf(xi)Δx=∫abf(x)dx
这一过渡解释了为何连续随机变量的统计量计算需要使用积分。

🛠️ 五、积分技巧在概率统计计算中的应用
5.1 常用积分技巧
-
分部积分法: ∫ u ( x ) v ′ ( x ) d x = u ( x ) v ( x ) − ∫ u ′ ( x ) v ( x ) d x \int u(x)v'(x)dx = u(x)v(x) - \int u'(x)v(x)dx ∫u(x)v′(x)dx=u(x)v(x)−∫u′(x)v(x)dx
- 适用:计算形如 ∫ x n e a x d x \int x^n e^{ax}dx ∫xneaxdx 的积分
-
换元法:设 u = g ( x ) u = g(x) u=g(x),则 ∫ f ( g ( x ) ) g ′ ( x ) d x = ∫ f ( u ) d u \int f(g(x))g'(x)dx = \int f(u)du ∫f(g(x))g′(x)dx=∫f(u)du
- 适用:简化复杂表达式,如正态分布中 z = x − μ σ z = \frac{x-\mu}{\sigma} z=σx−μ
-
对称性利用:
- 奇函数在对称区间的积分为零
- 偶函数在对称区间积分等于两倍的半区间积分
-
特殊函数应用:
- Gamma函数: Γ ( α ) = ∫ 0 ∞ x α − 1 e − x d x \Gamma(\alpha) = \int_0^{\infty} x^{\alpha-1}e^{-x}dx Γ(α)=∫0∞xα−1e−xdx
- 应用于计算多种分布的矩
这些技巧极大简化了统计量的计算过程。
5.2 常见积分公式在概率论中的应用
-
高斯积分: ∫ − ∞ ∞ e − x 2 d x = π \int_{-\infty}^{\infty} e^{-x^2}dx = \sqrt{\pi} ∫−∞∞e−x2dx=π
- 用于正态分布的归一化常数计算
-
随机变量函数的期望: E [ g ( X ) ] = ∫ − ∞ ∞ g ( x ) p ( x ) d x E[g(X)] = \int_{-\infty}^{\infty} g(x)p(x)dx E[g(X)]=∫−∞∞g(x)p(x)dx
- 用于计算高阶矩、变换后的随机变量统计特性
-
条件期望的计算:通过联合密度和边缘密度的积分比值确定
🔬 六、机器学习中的实际应用
6.1 最大似然估计中的积分
在最大似然估计中,对数似然函数的极值点往往需要计算积分。例如,正态分布参数估计时:
∂ ∂ μ ∑ i = 1 n ln ( 1 σ 2 π e − ( x i − μ ) 2 2 σ 2 ) = 0 \frac{\partial}{\partial \mu} \sum_{i=1}^n \ln\left(\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{(x_i-\mu)^2}{2\sigma^2}}\right) = 0 ∂μ∂∑i=1nln(σ2π1e−2σ2(xi−μ)2)=0
这一过程中,定积分和不定积分的概念与技巧直接应用于参数估计。
6.2 贝叶斯推断与积分
贝叶斯统计中,后验分布的计算需要:
p ( θ ∣ x ) = p ( x ∣ θ ) p ( θ ) ∫ p ( x ∣ θ ) p ( θ ) d θ p(\theta|x) = \frac{p(x|\theta)p(\theta)}{\int p(x|\theta)p(\theta)d\theta} p(θ∣x)=∫p(x∣θ)p(θ)dθp(x∣θ)p(θ)
分母中的积分(边缘似然)计算是贝叶斯方法的核心,通常需要数值积分方法如MCMC。
6.3 信息熵与KL散度
信息熵定义: H ( X ) = − ∫ p ( x ) ln p ( x ) d x H(X) = -\int p(x)\ln p(x)dx H(X)=−∫p(x)lnp(x)dx
KL散度: D K L ( p ∣ ∣ q ) = ∫ p ( x ) ln p ( x ) q ( x ) d x D_{KL}(p||q) = \int p(x)\ln\frac{p(x)}{q(x)}dx DKL(p∣∣q)=∫p(x)lnq(x)p(x)dx
这些信息论指标在深度学习中常用作损失函数,其计算依赖于定积分概念。
🧩 七、从理论到实践:Python实现
7.1 使用SciPy计算统计量
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
# 均匀分布
a, b = 0, 1 # 分布参数
uniform_dist = stats.uniform(loc=a, scale=b-a)
# 理论值
theoretical_mean = (a + b) / 2
theoretical_var = (b - a)**2 / 12
# 数值积分验证
x = np.linspace(a, b, 1000)
pdf = uniform_dist.pdf(x)
dx = x - x[0]
numerical_mean = np.sum(x * pdf * dx)
numerical_var = np.sum((x - numerical_mean)**2 * pdf * dx)
print(f"均匀分布 U({a},{b}):")
print(f"理论期望: {theoretical_mean}, 数值计算: {numerical_mean}")
print(f"理论方差: {theoretical_var}, 数值计算: {numerical_var}")
这段代码展示了如何使用数值方法验证理论结果。
7.2 蒙特卡洛方法估计统计量
对于难以直接积分的复杂分布,可使用蒙特卡洛方法:
import numpy as np
# 假设有复杂分布的随机样本
def complex_pdf_samples(n_samples=10000):
# 这里可以是任何复杂分布的采样方法
return np.random.gamma(shape=2, scale=3, size=n_samples)
samples = complex_pdf_samples()
monte_carlo_mean = np.mean(samples)
monte_carlo_var = np.var(samples)
# 理论值(伽马分布)
theoretical_mean = 2 * 3 # shape * scale
theoretical_var = 2 * 3**2 # shape * scale^2
print(f"蒙特卡洛估计结果:")
print(f"样本期望: {monte_carlo_mean}, 理论期望: {theoretical_mean}")
print(f"样本方差: {monte_carlo_var}, 理论方差: {theoretical_var}")
蒙特卡洛方法展示了从理论积分到实践应用的桥梁。
📝 八、总结与拓展
8.1 关键要点
- 定积分是连续随机变量统计量计算的基础工具,提供了最终数值结果
- 不定积分在求解过程中提供原函数,是计算定积分的中间步骤
- 积分技巧(分部积分、换元法、对称性等)对简化统计量计算至关重要
- 从离散到连续的过渡说明了积分如何替代求和成为统计量计算工具
- 机器学习中的许多高级算法(如最大似然估计、贝叶斯方法)依赖于积分概念
8.2 拓展思考
- 多维随机变量:统计量计算需要多重积分,计算复杂度大幅提高
- 数值积分方法:对于无解析解的复杂分布,需应用梯形法则、Simpson法则等
- 随机过程:概率密度函数随时间变化,需结合偏微分方程处理
- 变量变换:通过适当变换简化积分计算,是统计推断的重要技巧
理解积分在概率统计中的应用不仅有助于掌握机器学习的数学基础,还能提升对算法内部工作机制的认识,为构建更有效的模型提供理论指导。
希望这篇文章能帮助你更好地理解定积分与不定积分在概率统计量计算中的应用。如有问题,欢迎讨论! 😊