在Linux系统安装Ollama两种方法:自动安装和手动安装,并配置自启动服务
目录
一、命令自动安装
(一)使用命令行安装
(二)配置环境变量
(三)重新加载systemd配置并重启服务
二、手动安装
(一)下载本地文件
(二)解压并安装
(三)配置环境变量
(四)创建服务文件
三、Ollama 常用命令
四、Ollama 可配置的环境变量
五、Ollama 参数设置
六、Ollama 模型配置最长上下文
七、导入huggingface的模型
一、命令自动安装
(一)使用命令行安装
1. 运行curl -fsSL https://ollama.com/install.sh | sh。
2. 如下图安装完成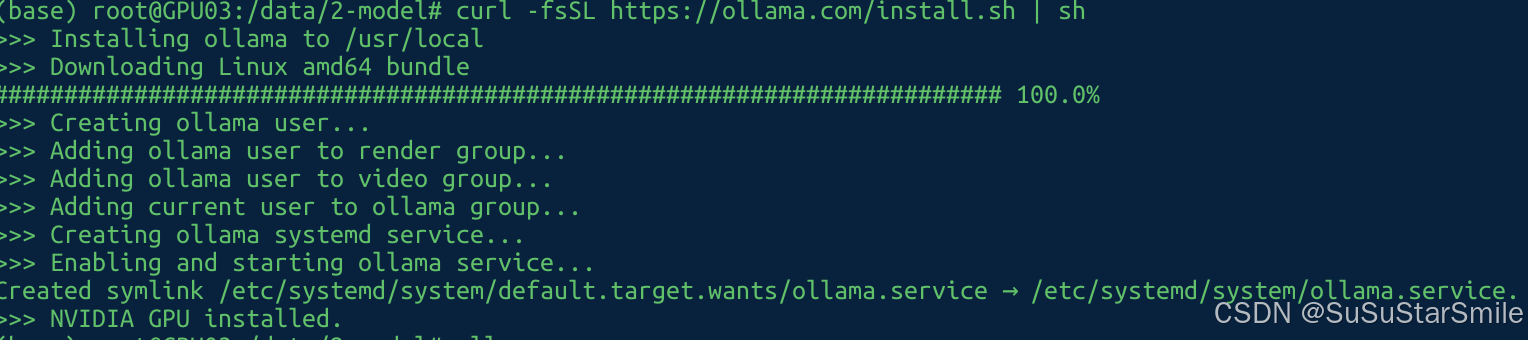
(二)配置环境变量
1. 打开默认建立的ollama.service文件
vim /etc/systemd/system/ollama.service2. 看到默认的一些设置
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/data/1-software/1-setup/1-miniconda/bin:/data/1-software/1-setup/1-miniconda/condabin:/data/1-software/1-setup/1-miniconda/bin:/usr/bin:/usr/local/bin:/usr/local/cuda/bin:/usr/bin/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin"
[Install]
WantedBy=default.target3.在 [Service]下面增加环境配置参数
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/data/1-software/1-setup/1-miniconda/bin:/data/1-software/1-setup/1-miniconda/condabin:/data/1-software/1-setup/1-miniconda/bin:/usr/bin:/usr/local/bin:/usr/local/cuda/bin:/usr/bin/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin"
Environment="OLLAMA_MODELS=/data/4-ollama-models"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_KEEP_ALIVE=24h"
Environment="OLLAMA_NUM_PARALLEL=100"
Environment="OLLAMA_MAX_LOADED_MODELS=4"
Environment="OLLAMA_SCHED_SPREAD=1"
Environment="OLLAMA_FLASH_ATTENTION=1"
Environment="OLLAMA_DEBUG=1"
Environment="OLLAMA_ACCELERATE=1"
[Install]
WantedBy=default.target4. 按esc,输入“:wq”,退出文件编辑
(三)重新加载systemd配置并重启服务
1.重新加载systemd
sudo systemctl daemon-reload2.启动服务
sudo systemctl start ollama3.查看状态
sudo systemctl status ollama 如图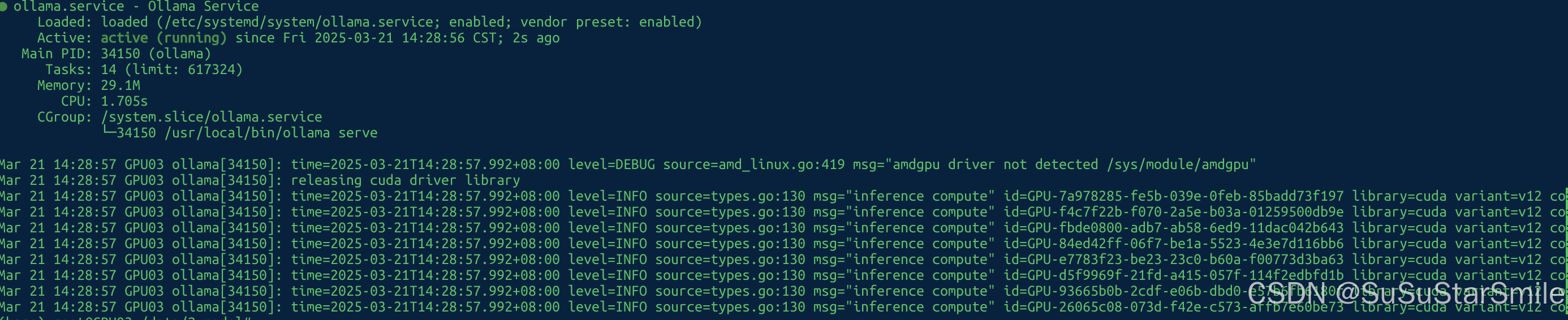
4. 若想停止服务
sudo systemctl stop ollama5. 设置开机自启动
sudo systemctl enable ollama6. 若想停止开机自启动
sudo systemctl disable ollama二、手动安装
(一)下载本地文件
1. 从GitHub仓库下载ollama-linux-amd64.tgz并上传到服务器。
2. Github地址:https://github.com/ollama/ollama
3.选择版本,下载到本地。
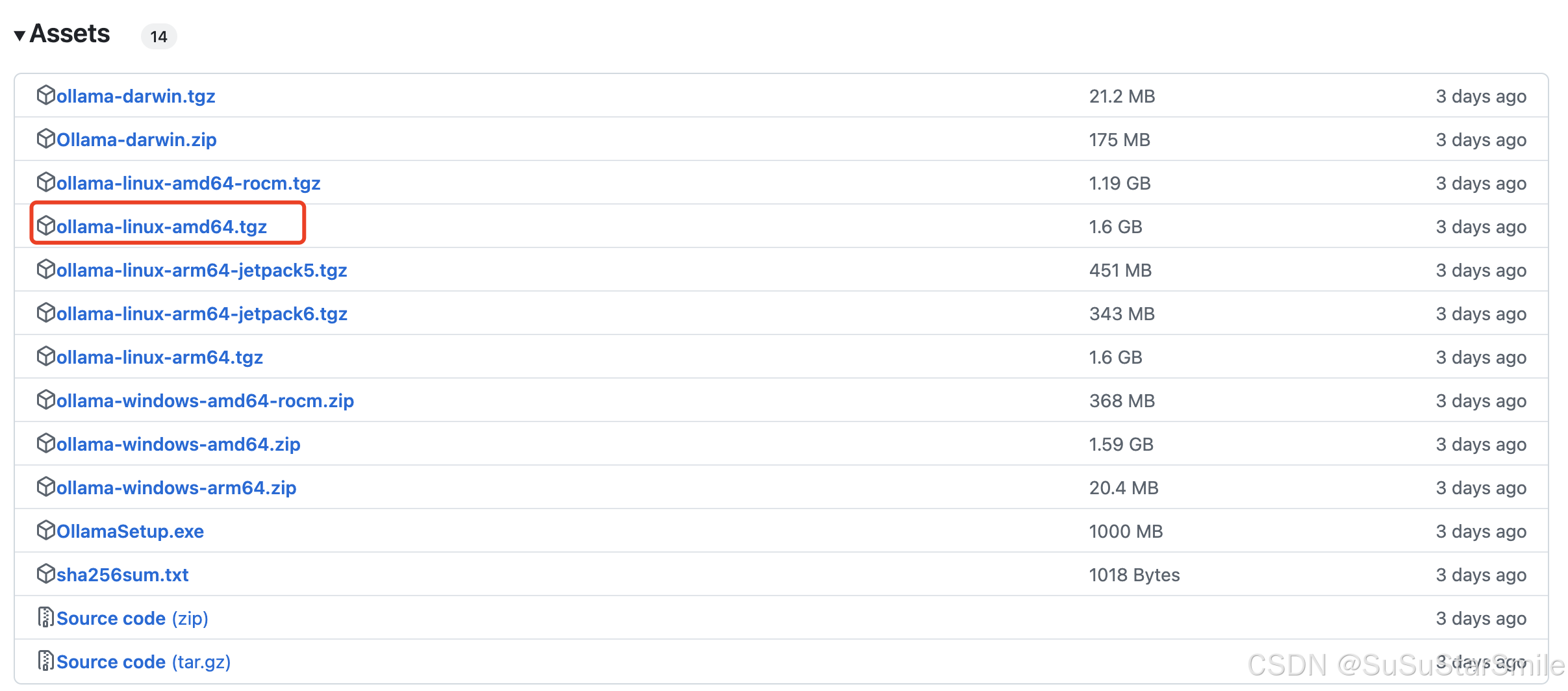
4. 将下载好的文件上传到服务器
(二)解压并安装
tar -zxf ollama-linux-amd64.tgz -C /usr/local(三)配置环境变量
编辑\~/.bashrc,添加环境变量等,export OLLAMA_HOST=http://[服务器IP地址]:11434。
export OLLAMA_MODELS=/data/ollama-models
export OLLAMA_HOST=0.0.0.0
export OLLAMA_KEEP_ALIVE=24h
export OLLAMA_NUM_PARALLEL=100
export OLLAMA_MAX_LOADED_MODELS=4
export OLLAMA_SCHED_SPREAD=1
export OLLAMA_FLASH_ATTENTION=1
export OLLAMA_DEBUG=1
export OLLAMA_ACCELERATE=1(四)创建服务文件
如果还想设置自启动服务,可参考以上(二)配置环境变量:在/etc/systemd/system/ollama.service中配置服务并启动。
三、Ollama 常用命令
ollama serve # 启动ollama
ollama create # 从模型文件创建模型
ollama show # 显示模型信息
ollama run # 运行模型
ollama pull # 从注册仓库中拉取模型
ollama push # 将模型推送到注册仓库
ollama list # 列出已下载模型
ollama cp # 复制模型
ollama rm # 删除模型
ollama help # 获取有关任何命令的帮助信息
ollama ps #查看运行中的模型四、Ollama 可配置的环境变量
Ollama 提供了多种环境变量以供配置:
OLLAMA_DEBUG:是否开启调试模式,默认为 false。
OLLAMA_FLASH_ATTENTION:是否闪烁注意力,默认为 true。
OLLAMA_HOST:Ollama 服务器的主机地址,默认为空。
OLLAMA_KEEP_ALIVE:保持连接的时间,默认为 5m。
OLLAMA_LLM_LIBRARY:LLM 库,默认为空。
OLLAMA_MAX_LOADED_MODELS:最大加载模型数,默认为 1。
OLLAMA_MAX_QUEUE:最大队列数,默认为空。
OLLAMA_MAX_VRAM:最大虚拟内存,默认为空。
OLLAMA_MODELS:模型目录,默认为空。
OLLAMA_NOHISTORY:是否保存历史记录,默认为 false。
OLLAMA_NOPRUNE:是否启用剪枝,默认为 false。
OLLAMA_NUM_PARALLEL:并行数,默认为 1。
OLLAMA_ORIGINS:允许的来源,默认为空。
OLLAMA_RUNNERS_DIR:运行器目录,默认为空。
OLLAMA_SCHED_SPREAD:调度分布,默认为空。
OLLAMA_TMPDIR:临时文件目录,默认为空。Here is the optimized list in the desired format:
OLLAMA_DEBUG:是否开启调试模式,默认为 false。
OLLAMA_FLASH_ATTENTION:是否闪烁注意力,默认为 true。
OLLAMA_HOST:Ollama 服务器的主机地址,默认为空。
OLLAMA_KEEP_ALIVE:保持连接的时间,默认为 5m。
OLLAMA_LLM_LIBRARY:LLM 库,默认为空。
OLLAMA_MAX_LOADED_MODELS:最大加载模型数,默认为 1。
OLLAMA_MAX_QUEUE:最大队列数,默认为空。
OLLAMA_MAX_VRAM:最大虚拟内存,默认为空。
OLLAMA_MODELS:模型目录,默认为空。
OLLAMA_NOHISTORY:是否保存历史记录,默认为 false。
OLLAMA_NOPRUNE:是否启用剪枝,默认为 false。
OLLAMA_NUM_PARALLEL:并行数,默认为 1。
OLLAMA_ORIGINS:允许的来源,默认为空。
OLLAMA_RUNNERS_DIR:运行器目录,默认为空。
OLLAMA_SCHED_SPREAD:调度分布,默认为空。
OLLAMA_TMPDIR:临时文件目录,默认为空。五、Ollama 参数设置
使用/set parameter设置参数命令:
/set parameter seed <int> Random number seed #设置随机种子
/set parameter num_predict <int> Max number of tokens to predict #设置预测token数
/set parameter top_k <int> Pick from top k num of tokens
/set parameter top_p <float> Pick token based on sum of probabilities
/set parameter min_p <float> Pick token based on top token probability * min_p
/set parameter num_ctx <int> Set the context size #设置回答最大token数---第一次设就可以,或者默认,如果每次调用api时设置,改变的值会让模型重新卸载再加载,时间变长。
/set parameter temperature <float> Set creativity level #设置模型温度(回答随机度)
/set parameter repeat_penalty <float> How strongly to penalize repetitions #设置重复回答时的惩罚力度
/set parameter repeat_last_n <int> Set how far back to look for repetitions
/set parameter num_gpu <int> The number of layers to send to the GPU
/set parameter stop <string> <string> ... Set the stop parameters
/set parameter top_p 0.7
/set parameter temperature 0.9
/set parameter num_predict 4096
/set parameter num_ctx 32768
/set parameter stop exit六、Ollama 模型配置最长上下文
由于ollama默认限制上下文的长度是2048,如果我们用ollama作为知识库基准模型,上下文超过2048直接会被阻断,提出内容不会根据上下文来回答。官方提出一个解决方案那就是通过设置num_ctx的大小来设置上下文,但是如果把会话改成ollama支持的openAI的方式这个属性就无效了。所以要通过修改配置文件来实现,然后生成新的模型,用ollama加载新模型。
1.获取配置文件
ollama show --modelfile qwen2.5:14b > qwen2.5_14b_Modelfile2.编辑配置文件
vim qwen2.5_14b_Modelfile3. 添加上下文长度参数 PARAMETER num_ctx 32768 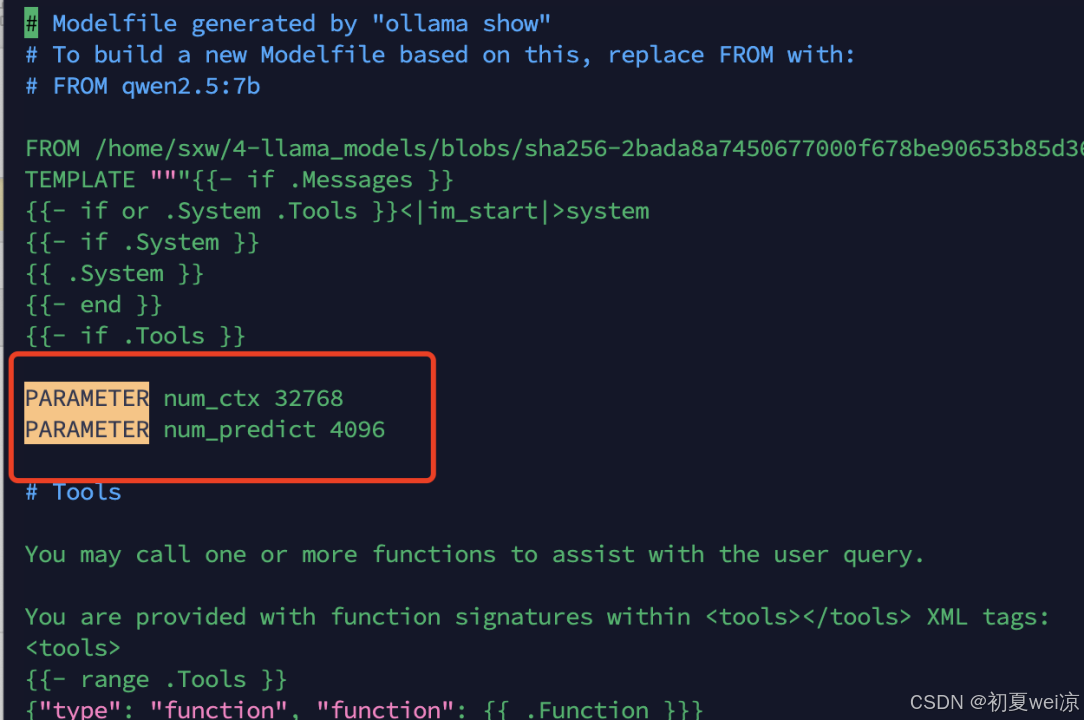
4. 重新生成新的模型,模型名称可以自己起名
ollama create -f qwen2.5_14b_Modelfile 新模型名称5.显示新模型的参数
ollama show 新模型名称七、导入huggingface的模型
Ollama支持从Huggingface Hub上直接拉取各种模型,包括社区创建的GGUF量化模型。用户可以通过简单的命令行指令快速运行这些模型,可以使用如下命令:
ollama run hf.co/{username}/{repository}
要选择不同的量化方案,只需在命令中添加一个标签:
ollama run hf.co/{username}/{repository}:{quantization}
例如:量化名称不区分大小写
ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:IQ3_M
ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0
还可以直接使用完整的文件名作为标签:
ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Llama-3.2-3B-Instruct-IQ3_M.gguf参考: Ollama 服务配置-常用环境变量_ollama环境变量配置-CSDN博客