【LLMs篇】06:Encoder-Only vs Decoder-Only vs Encoder-Decoder
当前大多数大型语言模型 (LLM) 采用 Decoder-only 架构,主要是出于以下几个关键原因:
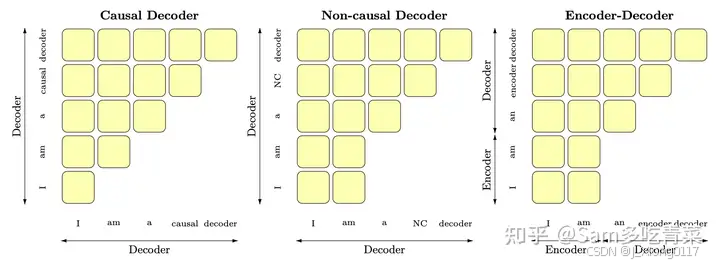
1. 训练效率和并行化:
- 自回归特性 (Autoregressive): Decoder-only 架构天然适合自回归生成。这意味着模型在生成文本时,每次预测下一个词都只依赖于之前生成的词(以及可选的输入提示)。 这种特性允许模型在训练时进行高度并行化的计算。
- Teacher Forcing: 在训练过程中,可以使用 “Teacher Forcing” 技术。 这意味着,模型在预测下一个词时,不是使用自己上一步生成的词,而是使用真实的、正确的下一个词作为输入。 这种方式可以加速训练,因为每个时间步的计算可以独立进行,不需要等待上一步的预测结果。 这使得模型可以在 GPU/TPU 上高效并行处理整个序列。
- 对比 Encoder-Decoder: Encoder-Decoder 架构(如最初的 Transformer)需要先对整个输入序列进行编码,然后再进行解码。这在训练长序列时效率较低,因为编码阶段无法并行化。
2. 文本生成任务的自然契合:
- 单向生成: 许多文本生成任务(如文本摘要、翻译、问答、对话等)本质上是单向的。 模型只需要根据前面的上下文生成后续文本,不需要对未来信息进行编码。 Decoder-only 架构完美契合这种单向生成的特性。
- 无需双向上下文 (在许多情况下): 虽然在某些情况下双向上下文可能有用,但在许多生成任务中,模型主要依赖于之前的上下文来生成连贯的文本。 Decoder-only 架构通过堆叠多层,已经能够捕获足够复杂的上下文信息。
3. 更简单的架构和实现:
- 组件更少: Decoder-only 架构比 Encoder-Decoder 架构更简单,因为它只需要 Decoder 部分。 这意味着参数更少,模型更容易训练和部署。
- 易于理解和调试: 较简单的架构也更容易理解和调试,有利于研究和开发。
4. 预训练和微调的灵活性:
- 统一的预训练和微调: Decoder-only 架构使得预训练和微调过程更加统一。 预训练阶段,模型在大规模文本数据上进行自回归训练。 微调阶段,模型在特定任务的数据上进行类似的自回归训练。 这简化了整个流程。
- 良好的零样本 (Zero-shot) 和少样本 (Few-shot) 学习能力: 经过大规模预训练的 Decoder-only 模型通常展现出强大的零样本和少样本学习能力。 这意味着模型可以在没有或只有少量特定任务数据的情况下,就能完成一些任务。
5. 与 Prompt Engineering 的协同作用:
- Prompt 作为输入: Decoder-only 模型非常适合与 Prompt Engineering 结合使用。 用户可以通过精心设计的 Prompt 来引导模型生成特定类型的文本。 Prompt 可以作为模型的输入,与模型已经生成的文本一起构成完整的上下文。
总结一下,Decoder-only架构的优势主要体现在:
- 训练效率高,易于并行化。
- 自然契合文本生成任务的单向性。
- 架构简单,易于实现和部署。
- 预训练和微调流程统一,具有良好的零样本/少样本学习能力。
- 非常适合Prompt Engineering。
需要注意的是,这并不意味着 Encoder-Decoder 架构没有用武之地。 在某些特定任务中,例如需要对输入和输出进行双向编码的任务(如文本改写、句子对分类等),Encoder-Decoder 架构可能仍然更具优势。 例如,T5模型就是一个Encoder-Decoder模型,它在某些任务上表现也很好。 但是,对于当前主流的大规模通用语言模型,Decoder-only 架构凭借其上述优势,成为了更受欢迎的选择。
知乎观点
