【NLP 35、序列标注任务】
天,怎么还没变
念,不过两三年
—— 25.3.9
一、什么是序列标注任务
NLP中输入的每一句话都可以看作一个序列,其中的每一个字(单独的输入)都可以看作序列中的一个时间步
预测的结果是一个和输入等长的序列,对于序列中的每一个字(时间步)做分类,得到每个时间步的标签,预测出的标签与时间步等长
对于输入:X1X2X3X4…Xn
预测输出:Y1Y2Y3Y4…Yn
NLP中的应用场景: 分词,词性标注,句法分析,命名实体识别等
二、中文分词任务 —— 基于序列标注
对于每一个字,我们想判断它是不是一个词的边界

1.序列标注方式 — 四分类:
① B:词的左边界
② E:词的右边界
③ M:词的内部
④ S:单字
例:
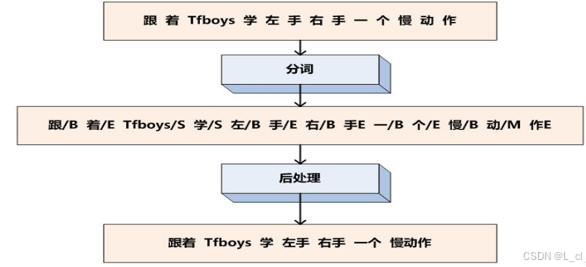
优点:
规律明显,学习更加容易
2.序列标注方式 —— 二分类
对于每一个字,我们想判断它是不是一个词的边界:0 表示不是隔断句,1 表示是隔断

优点
二分类的学习比四分类更加简单,需要的计算资源更少
3.序列标注应用场景 —— 命名实体识别 NER
对于每个字做十分类,输入一段文本,输出一个与文本长度等长的序列,只要序列结果正确就可以找到各个正确实体的位置
BA:地址左边界 BO:机构左边界 BP:人名左边界 O:无关字(命名实体外的字)
MA:地址内部 MO:机构内部 MP:人名内部
EA:地址右边界 EO:机构右边界 EP:人名右边界
例:
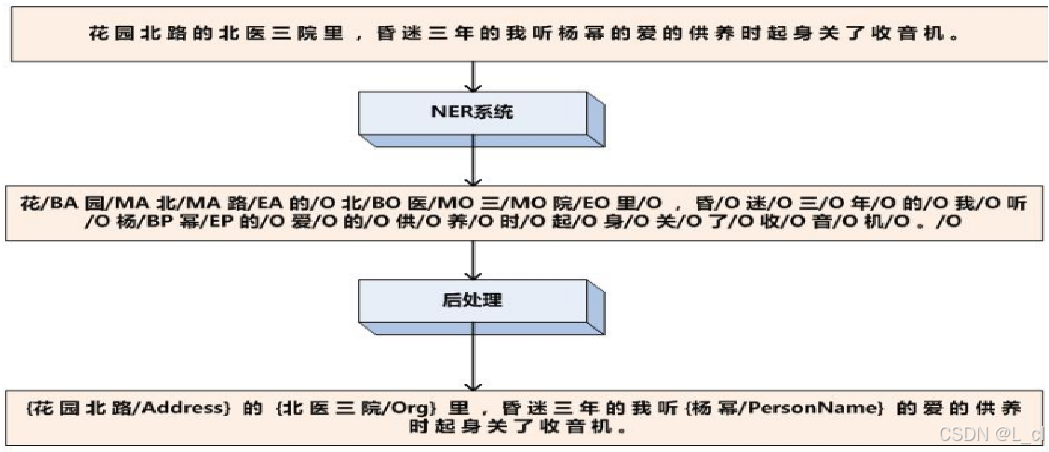
需要人工标注正确的序列
三、中文分词 —— 基于深度学习 🚀
通过神经网络将每个 token 向量化,预测其分类标签
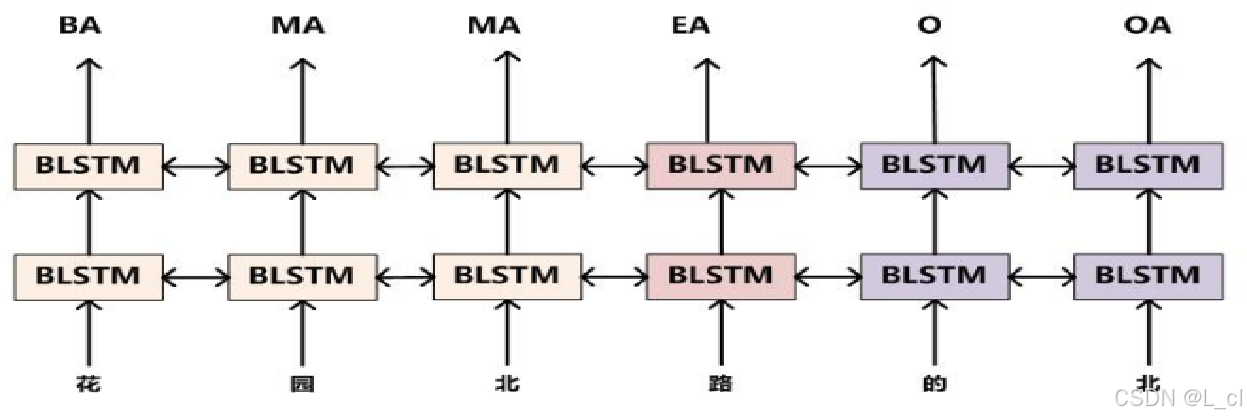
对于输入的每个字(token)向量化,得到每个字对应的向量,经过网络层后输出每个字预测的分类标签输出
1.模型初始化
代码运行流程
TorchModel (继承自nn.Module)
├── 1. 初始化方法 __init__()
│ ├── 1.1 嵌入层: nn.Embedding
│ │ ├── 参数: vocab_size=len(vocab)+1
│ │ └── 参数: input_dim=词向量维度
│ ├── 1.2 RNN层: nn.RNN
│ │ ├── input_size=嵌入层输出维度
│ │ ├── hidden_size=隐层维度
│ │ ├── num_layers=堆叠层数
│ │ ├── nonlinearity="relu" (激活函数)
│ │ └── dropout=0.1 (层间丢弃率)
│ ├── 1.3 分类层: nn.Linear
│ │ ├── in_features=隐层维度
│ │ └── out_features=2 (二分类输出)
│ └── 1.4 损失函数: nn.CrossEntropyLoss
│ └── ignore_index=-100 (忽略特定标签)
│
└── 2. 前向传播流程
├── 输入序列 → 嵌入层 → RNN层 → 分类层
└── 输出 → 损失计算(需配合标签)input_dim:词嵌入的向量维度(需与预训练词向量匹配)。
hidden_size:RNN 隐藏层神经元数量(影响模型容量)。
num_rnn_layers:RNN 堆叠层数(层数越多,模型越深)。
vocab:词汇表大小(决定 embedding 输出维度)。
nn.Embedding():将词索引(整数)映射为稠密向量(词嵌入),用于处理离散型文本数据。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
num_embeddings | int | None | 词汇表大小(即输入索引的最大值 + 1,例如 vocab_size=10000)。 |
embedding_dim | int | None | 嵌入向量的维度(如 128、256)。 |
padding_idx | int | -1 | 填充位置的索引(默认 -1,表示无填充)。用于忽略 [PAD] 标签。 |
scale_grad_by_freq | bool | False | 是否根据词频缩放梯度(减少高频词的梯度)。 |
device | str | None | 指定设备(如 "cuda" 或 "cpu")。 |
nn.RNN():实现循环神经网络(RNN)层,捕捉序列数据的时序依赖关系。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
input_size | int | None | 输入向量的维度(如词嵌入的输出维度)。 |
hidden_size | int | None | 隐藏层神经元的数量。 |
num_layers | int | 1 | RNN 的堆叠层数。 |
batch_first | bool | False | 输入数据形状是否为 (batch_size, sequence_length, input_size)。 |
bidirectional | bool | False | 是否为双向 RNN。 |
nonlinearity | str | "tanh" | 激活函数(如 "relu"、"sigmoid")。 |
dropout | float | 0.0 | Dropout 概率(防止过拟合)。 |
recurrent_dropout | float | 0.0 | RNN 层内部的 Dropout 概率。 |
bias | bool | True | 是否包含偏置项。 |
nn.Linear():全连接层,将输入线性映射到输出空间。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
in_features | int | None | 输入特征的数量。 |
out_features | int | None | 输出特征的数量。 |
bias | bool | True | 是否包含偏置项(默认为 True)。 |
nn.CrossEntropyLoss():计算交叉熵损失,常用于分类任务(如文本分类、NER)
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
ignore_index | int | -1 | 忽略标签的索引(如 [PAD] 标签设为 -1)。 |
weight | Tensor | None | 类别的权重(用于不平衡数据集)。 |
reduction | str | "mean" | 损失的缩减方式(如 "sum" 或 "mean")。 |
label_smoothing | float | 0.0 | 标签平滑系数(防止过拟合,如 0.1)。 |
def __init__(self, input_dim, hidden_size, num_rnn_layers, vocab):
super(TorchModel, self).__init__()
self.embedding = nn.Embedding(len(vocab) + 1, input_dim) #shape=(vocab_size, dim)
self.rnn_layer = nn.RNN(input_size=input_dim,
hidden_size=hidden_size,
batch_first=True,
bidirectional=False,
num_layers=num_rnn_layers,
nonlinearity="relu",
dropout=0.1)
self.classify = nn.Linear(hidden_size, 2)
self.loss_func = nn.CrossEntropyLoss(ignore_index=-100)2.前向传播
代码运行流程
forward 方法流程
├── 1. 输入处理
│ ├── 1.1 输入张量 x: (batch_size, sen_len)
│ └── 1.2 可选标签 y: (batch_size, sen_len)
│
├── 2. 嵌入层 (Embedding)
│ ├── 操作: self.embedding(x)
│ ├── 输出形状: (batch_size, sen_len, input_dim)
│ └── 作用: 将离散词索引映射为连续向量
│
├── 3. RNN层 (RNN Layer)
│ ├── 操作: self.rnn_layer(x)
│ ├── 输出形状: (batch_size, sen_len, hidden_size)
│ └── 作用: 提取时序特征,隐状态自动管理
│
├── 4. 分类层 (Classification)
│ ├── 操作: self.classify(x)
│ ├── 输出形状: (batch_size, sen_len, class_num=2)
│ └── 作用: 映射到二分类概率空间
│
├── 5. 分支逻辑 (根据标签存在性)
│ ├── 5.1 存在标签 y
│ │ ├── 操作: 计算交叉熵损失
│ │ ├── 维度变换: y_pred.view(-1, 2) → (batch_size*sen_len, 2)
│ │ ├── 标签展平: y.view(-1) → (batch_size*sen_len)
│ │ └── 返回: self.loss_func(预测值, 标签)
│ │
│ └── 5.2 无标签 y
│ └── 返回: 原始预测张量 y_pred
│
└── 6. 输出
├── 训练模式: 返回损失值(标量)
└── 推理模式: 返回预测概率张量input_dim:嵌入向量维度(需与 nn.Embedding 匹配)。
hidden_size:RNN 隐藏层大小。
class_num:分类任务类别数(如情感分析的正面/负面)。
loss_func.ignore_index: 忽略 [PAD] 标签的索引。
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #output shape:(batch_size, sen_len, input_dim)
x, _ = self.rnn_layer(x) #output shape:(batch_size, sen_len, hidden_size)
y_pred = self.classify(x) #input shape:(batch_size, sen_len, class_num)
if y is not None:
#(batch_size * sen_len, class_num), (batch_size * sen_len, 1)
return self.loss_func(y_pred.view(-1, 2), y.view(-1))
else:
return y_pred
3. 构建数据
Ⅰ、构建词汇表
代码运行流程
build_vocab 函数流程
├── 1. 初始化空字典
│ └── 操作: `vocab = {}`
│
├── 2. 读取词表文件
│ ├── 操作: `with open(vocab_path, "r", encoding="utf8") as f`
│ ├── 逐行处理: `for index, line in enumerate(f)`
│ └── 字符映射:
│ ├── 字符提取: `char = line.strip()`
│ └── 索引分配: `vocab[char] = index + 1` (索引从1开始递增)
│
├── 3. 处理未知词(unk)
│ └── 操作: `vocab['unk'] = len(vocab) + 1`
│ ├── 作用: 为未登录词预留唯一标识符
│ └── 逻辑: 确保所有字符(包括unk)的索引不重复
│
└── 4. 返回词表
└── 操作: `return vocab`open():打开文件并返回文件对象,用于读写文件内容。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
file_name | str | 无 | 文件路径(需包含扩展名) |
mode | str | 'r' | 文件打开模式: - 'r': 只读- 'w': 只写(覆盖原文件)- 'a': 追加写入- 'b': 二进制模式- 'x': 创建新文件(若存在则报错) |
buffering | int | None | 缓冲区大小(仅二进制模式有效) |
encoding | str | None | 文件编码(仅文本模式有效,如 'utf-8') |
newline | str | '\n' | 行结束符(仅文本模式有效) |
closefd | bool | True | 是否在文件关闭时自动关闭文件描述符 |
dir_fd | int | -1 | 文件描述符(高级用法,通常忽略) |
flags | int | 0 | Linux 系统下的额外标志位 |
mode | str | 无 | (重复参数,实际使用中只需指定 mode) |
enumerate():遍历可迭代对象,同时返回元素的索引和值,简化循环计数逻辑。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
iterable | iterable | 无 | 需要遍历的可迭代对象(如列表、字符串、字典等)。 |
start | int | 0 | 索引的起始值(默认从 0 开始)。 |
strip():去除字符串两端的空白字符(如空格、换行符、制表符)或指定字符。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
chars | str | None | 指定要去除的字符集合(如 " \t\n\r")。默认去除空白字符。 |
#加载字表
def build_vocab(vocab_path):
vocab = {}
with open(vocab_path, "r", encoding="utf8") as f:
for index, line in enumerate(f):
char = line.strip()
vocab[char] = index + 1 #每个字对应一个序号
vocab['unk'] = len(vocab) + 1
return vocabⅡ、初始化数据集
代码运行流程
__init__ 方法流程
├── 1. 初始化对象
│ └── 操作: `super().__init__()`(隐式继承父类)
│
├── 2. 参数赋值
│ ├── 2.1 语料路径存储
│ │ └── 操作: `self.corpus_path = corpus_path`
│ │ └── 作用: 存储原始语料文件路径,如`corpus.txt`
│ │
│ ├── 2.2 词表加载
│ │ └── 操作: `self.vocab = vocab`
│ │ └── 作用: 保存字符到索引的映射,支持词向量转换
│ │
│ └── 2.3 序列长度限制
│ └── 操作: `self.max_length = max_length`
│ └── 作用: 控制输入序列最大长度,防止内存溢出
└── 3. 数据加载触发
└── 操作: `self.load()`
└── 作用: 调用自定义方法实现语料加载
└── 预期功能: 读取`corpus_path`文件内容
vocab:从 build_vocab 返回的词汇表
corpus_path:语料库文件路径
max_length:序列的最大长度
self.load():调用类方法,加载数据
def __init__(self, corpus_path, vocab, max_length):
self.vocab = vocab
self.corpus_path = corpus_path
self.max_length = max_length
self.load()Ⅲ、文本转序列
代码运行流程
sentence_to_sequence 函数流程
├── 1. 初始化序列
│ └── 操作: `sequence = []`
│ └── 作用: 创建空列表存储字符索引
│
├── 2. 遍历句子字符
│ ├── 循环逻辑: `for char in sentence`
│ └── 操作细节:
│ ├── 2.1 字符查询词表: `vocab.get(char, vocab['unk'])`
│ │ ├── 存在字符: 返回对应索引值(如 `"的" → 1024`)
│ │ └── 未登录字符: 返回 `unk` 索引(如 `"𓀀" → vocab['unk']=10001`)
│ └── 2.2 索引追加: 将结果添加至 `sequence` 列表
│
├── 3. 处理未知词(unk)
│ └── 逻辑: 当字符不在词表中时,使用预定义的 `unk` 兜底
│ └── 应用场景: 兼容生僻字、特殊符号或拼写错误
│
└── 4. 返回数字序列
└── 输出形式: `return sequence`
├── 示例输入: `sentence="自然语言处理", vocab={'自':1, '然':2, 'unk':0}`
└── 示例输出: `[1, 2, 0, 0, 0]`(假设后续字符未在词表中)遍历句子中的每个字符,查表得到索引,未知字符用
vocab['unk']替代。
字典.get():获取字典中指定键的值,若键不存在则返回默认值(避免 KeyError)
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
key | 任意类型 | 无 | 要获取的键。 |
default | 任意类型 | None | 键不存在时返回的值(可选)。 |
#文本转化为数字序列,为embedding做准备
def sentence_to_sequence(sentence, vocab):
sequence = [vocab.get(char, vocab['unk']) for char in sentence]
return sequenceⅣ、生成标签
代码运行流程
sequence_to_label 函数流程
├── 1. 输入处理
│ └── 操作: 接收句子 `sentence` 作为输入
│
├── 2. 分词处理
│ └── 操作: `words = jieba.lcut(sentence)`
│ ├── 作用: 使用 `jieba.lcut` 对句子进行精确分词,返回分词列表
│ └── 输出: `words` 列表,包含分词结果(如 `["我们", "是", "小青蛙"]`)
│
├── 3. 初始化标签序列
│ └── 操作: `label = [0] * len(sentence)`
│ ├── 作用: 创建与句子长度相同的全零列表,用于存储标注结果
│ └── 输出: `label` 列表(如 `[0, 0, 0, 0, 0, 0, 0]`)
│
├── 4. 遍历分词结果
│ ├── 操作: `for word in words`
│ └── 处理逻辑:
│ ├── 4.1 更新指针: `pointer += len(word)`
│ │ └── 作用: 记录当前分词在句子中的结束位置
│ └── 4.2 标注分词结束位置: `label[pointer - 1] = 1`
│ └── 作用: 在 `label` 列表中将分词结束位置标记为 1
│
└── 5. 返回标注结果
└── 操作: `return label`
├── 输出: 标注后的 `label` 列表
└── 示例: 输入 `sentence="我们是小青蛙"`,输出 `[0, 1, 0, 1, 0, 1, 1]`
jieba.lcut():对中文文本进行分词,返回词语列表(支持全模式和精确模式)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
text | str | 无 | 需要分词的中文文本。 |
cut_all | bool | False | 是否启用全模式分词(True 切分更细)。 |
len():返回对象的长度或元素个数(字符串、列表、字典、元组等)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
obj | 任意类型 | 无 | 需要计算长度的对象(如 list、str)。 |
#基于结巴生成分级结果的标注
def sequence_to_label(sentence):
words = jieba.lcut(sentence)
label = [0] * len(sentence)
pointer = 0
for word in words:
pointer += len(word)
label[pointer - 1] = 1
return labelⅤ、对数据进行填充 / 截断
代码运行流程
padding 方法流程
├── 1. 输入处理
│ ├── 1.1 输入序列: `sequence`(如 `[1, 2, 3, 4]`)
│ └── 1.2 输入标签: `label`(如 `[0, 1, 0, 1]`)
│
├── 2. 序列截断
│ └── 操作: `sequence = sequence[:self.max_length]`
│ ├── 作用: 将序列截断至最大长度 `self.max_length`
│ └── 示例: 若 `self.max_length=3`,则 `[1, 2, 3, 4]` → `[1, 2, 3]`
│
├── 3. 序列填充
│ └── 操作: `sequence += [0] * (self.max_length - len(sequence))`
│ ├── 作用: 用 `0` 填充序列至最大长度 `self.max_length`
│ └── 示例: 若 `self.max_length=5`,则 `[1, 2, 3]` → `[1, 2, 3, 0, 0]`
│
├── 4. 标签截断
│ └── 操作: `label = label[:self.max_length]`
│ ├── 作用: 将标签截断至最大长度 `self.max_length`
│ └── 示例: 若 `self.max_length=3`,则 `[0, 1, 0, 1]` → `[0, 1, 0]`
│
├── 5. 标签填充
│ └── 操作: `label += [-100] * (self.max_length - len(label))`
│ ├── 作用: 用 `-100` 填充标签至最大长度 `self.max_length`
│ └── 示例: 若 `self.max_length=5`,则 `[0, 1, 0]` → `[0, 1, 0, -100, -100]`
│
└── 6. 返回结果
└── 操作: `return sequence, label`
├── 输出: 填充后的序列和标签
└── 示例: 输入 `sequence=[1, 2, 3, 4]`, `label=[0, 1, 0, 1]`, `self.max_length=5`
├── 输出序列: `[1, 2, 3, 4, 0]`
└── 输出标签: `[0, 1, 0, 1, -100]`序列填充:截断至
max_length,不足部分用0填充。标签填充:截断至
max_length,不足部分用-100填充(表示无效标签)。
len():返回对象的长度或元素个数(字符串、列表、字典、元组等)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
obj | 任意类型 | 无 | 需要计算长度的对象(如 list、str)。 |
def padding(self, sequence, label):
sequence = sequence[:self.max_length]
sequence += [0] * (self.max_length - len(sequence))
label = label[:self.max_length]
label += [-100] * (self.max_length - len(label))
return sequence, labelⅥ、加载数据
代码运行流程
load 方法流程
├── 1. 初始化数据列表
│ └── 操作: `self.data = []`
│ └── 作用: 创建一个空列表,用于存储处理后的数据
│
├── 2. 打开语料文件
│ └── 操作: `with open(self.corpus_path, encoding="utf8") as f`
│ ├── 作用: 以 UTF-8 编码打开语料文件
│ └── 文件句柄: `f`
│
├── 3. 逐行读取文件
│ ├── 操作: `for line in f`
│ └── 处理逻辑:
│ ├── 3.1 将句子转换为数字序列
│ │ └── 操作: `sequence = sentence_to_sequence(line, self.vocab)`
│ │ ├── 作用: 使用 `sentence_to_sequence` 函数将句子中的字符映射为数字序列
│ │ └── 输出: `sequence` 列表(如 `[1, 2, 3, 4]`)
│ │
│ ├── 3.2 生成标签序列
│ │ └── 操作: `label = sequence_to_label(line)`
│ │ ├── 作用: 使用 `sequence_to_label` 函数生成句子的标签序列
│ │ └── 输出: `label` 列表(如 `[0, 1, 0, 1]`)
│ │
│ ├── 3.3 填充序列和标签
│ │ └── 操作: `sequence, label = self.padding(sequence, label)`
│ │ ├── 作用: 使用 `padding` 方法将序列和标签填充至固定长度
│ │ └── 输出: 填充后的 `sequence` 和 `label` 列表(如 `[1, 2, 3, 0, 0]` 和 `[0, 1, 0, -100, -100]`)
│ │
│ ├── 3.4 转换为张量
│ │ ├── 操作: `sequence = torch.LongTensor(sequence)`
│ │ │ └── 作用: 将 `sequence` 列表转换为 PyTorch 的 `LongTensor`
│ │ └── 操作: `label = torch.LongTensor(label)`
│ │ └── 作用: 将 `label` 列表转换为 PyTorch 的 `LongTensor`
│ │
│ └── 3.5 添加到数据列表
│ └── 操作: `self.data.append([sequence, label])`
│ ├── 作用: 将处理后的序列和标签对添加到 `self.data` 列表中
│ └── 示例: `self.data = [[tensor([1, 2, 3, 0, 0]), tensor([0, 1, 0, -100, -100])], ...]`
│
├── 4. 数据量限制
│ └── 操作: `if len(self.data) > 10000: break`
│ ├── 作用: 如果 `self.data` 中的数据量超过 10000 条,则停止读取
│ └── 示例: 当 `len(self.data) == 10001` 时,退出循环
│
└── 5. 返回结果
└── 作用: `self.data` 列表中存储了所有处理后的数据,供后续使用open():打开文件并返回文件对象,用于读写文件内容。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
file_name | str | 无 | 文件路径(需包含扩展名) |
mode | str | 'r' | 文件打开模式: - 'r': 只读- 'w': 只写(覆盖原文件)- 'a': 追加写入- 'b': 二进制模式- 'x': 创建新文件(若存在则报错) |
buffering | int | None | 缓冲区大小(仅二进制模式有效) |
encoding | str | None | 文件编码(仅文本模式有效,如 'utf-8') |
newline | str | '\n' | 行结束符(仅文本模式有效) |
closefd | bool | True | 是否在文件关闭时自动关闭文件描述符 |
dir_fd | int | -1 | 文件描述符(高级用法,通常忽略) |
flags | int | 0 | Linux 系统下的额外标志位 |
mode | str | 无 | (重复参数,实际使用中只需指定 mode) |
torch.LongTensor():创建一个长整型张量,常用于 PyTorch 模型的输入或标签。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
data | list/tuple | 无 | 初始化数据(如 [1, 2, 3]) |
dtype | torch.dtype | torch.int64 | 数据类型(如 torch.long) |
device | str | None | 指定设备(如 "cuda:0") |
列表.append():向列表末尾添加单个元素
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
item | 任意类型 | 无 | 需要添加的元素。 |
def load(self):
self.data = []
with open(self.corpus_path, encoding="utf8") as f:
for line in f:
sequence = sentence_to_sequence(line, self.vocab)
label = sequence_to_label(line)
sequence, label = self.padding(sequence, label)
sequence = torch.LongTensor(sequence)
label = torch.LongTensor(label)
self.data.append([sequence, label])
if len(self.data) > 10000:
breakⅦ、构建数据加载器
代码运行流程
build_dataset 函数流程
├── 1. 输入参数
│ ├── 1.1 `corpus_path`: 语料文件路径
│ ├── 1.2 `vocab`: 词汇表,用于字符到索引的映射
│ ├── 1.3 `max_length`: 序列的最大长度
│ └── 1.4 `batch_size`: 每个批次的样本数量
│
├── 2. 创建自定义数据集
│ └── 操作: `dataset = Dataset(corpus_path, vocab, max_length)`
│ ├── 作用: 初始化自定义数据集对象
│ ├── 实现细节:
│ │ ├── 2.1 `__init__`: 初始化语料路径、词汇表和最大长度
│ │ ├── 2.2 `__len__`: 返回数据集的样本数量
│ │ └── 2.3 `__getitem__`: 根据索引返回处理后的序列和标签
│ └── 输出: `dataset` 对象
│
├── 3. 创建数据加载器
│ └── 操作: `data_loader = DataLoader(dataset, shuffle=True, batch_size=batch_size)`
│ ├── 作用: 将数据集包装为可迭代的数据加载器
│ ├── 参数说明:
│ │ ├── `shuffle=True`: 打乱数据顺序
│ │ └── `batch_size=batch_size`: 设置每个批次的样本数量
│ └── 输出: `data_loader` 对象
│
└── 4. 返回数据加载器
└── 操作: `return data_loader`
├── 作用: 返回可用于训练或推理的数据加载器
└── 示例: 输入 `corpus_path="data.txt"`, `vocab={"a":1, "b":2}`, `max_length=10`, `batch_size=32`
├── 输出: 一个 `DataLoader` 对象,支持按批次加载数据
└── 使用: `for batch in data_loader: ...`DataLoader():高效加载数据集,支持分批次、打乱顺序、多线程加载。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
dataset | Dataset | 无 | 自定义数据集对象。 |
batch_size | int | 1 | 每个批次的样本数量。 |
shuffle | bool | False | 是否在每个 epoch 开始时打乱数据。 |
num_workers | int | 0 | 使用多线程加载数据的工人数量。 |
#建立数据集
def build_dataset(corpus_path, vocab, max_length, batch_size):
dataset = Dataset(corpus_path, vocab, max_length) #diy __len__ __getitem__
data_loader = DataLoader(dataset, shuffle=True, batch_size=batch_size) #torch
return data_loader
4.模型训练 ⭐
代码运行流程
main 函数流程
├── 1. 初始化参数
│ ├── 1.1 `epoch_num = 10`:训练轮数
│ ├── 1.2 `batch_size = 20`:每次训练样本个数
│ ├── 1.3 `char_dim = 50`:每个字的维度
│ ├── 1.4 `hidden_size = 100`:隐含层维度
│ ├── 1.5 `num_rnn_layers = 3`:RNN 层数
│ ├── 1.6 `max_length = 20`:样本最大长度
│ ├── 1.7 `learning_rate = 1e-3`:学习率
│ ├── 1.8 `vocab_path = "chars.txt"`:字表文件路径
│ └── 1.9 `corpus_path = "corpus.txt"`:语料文件路径
│
├── 2. 建立字表
│ └── 操作: `vocab = build_vocab(vocab_path)`
│ ├── 作用: 从字表文件中构建词汇表
│ └── 输出: `vocab` 字典,包含字符到索引的映射
│
├── 3. 建立数据集
│ └── 操作: `data_loader = build_dataset(corpus_path, vocab, max_length, batch_size)`
│ ├── 作用: 从语料文件中构建数据集,并返回数据加载器
│ └── 输出: `data_loader` 对象,支持按批次加载数据
│
├── 4. 建立模型
│ └── 操作: `model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab)`
│ ├── 作用: 初始化模型,定义网络结构
│ └── 输出: `model` 对象,包含模型参数和计算逻辑
│
├── 5. 建立优化器
│ └── 操作: `optim = torch.optim.Adam(model.parameters(), lr=learning_rate)`
│ ├── 作用: 使用 Adam 优化器优化模型参数
│ └── 输出: `optim` 对象,包含优化逻辑
│
├── 6. 训练模型
│ ├── 6.1 训练轮数循环: `for epoch in range(epoch_num)`
│ └── 6.2 每轮训练逻辑:
│ ├── 6.2.1 设置模型为训练模式: `model.train()`
│ ├── 6.2.2 初始化损失列表: `watch_loss = []`
│ ├── 6.2.3 遍历数据加载器: `for x, y in data_loader`
│ │ ├── 6.2.3.1 梯度归零: `optim.zero_grad()`
│ │ ├── 6.2.3.2 计算损失: `loss = model(x, y)`
│ │ ├── 6.2.3.3 反向传播: `loss.backward()`
│ │ └── 6.2.3.4 更新权重: `optim.step()`
│ ├── 6.2.4 记录损失: `watch_loss.append(loss.item())`
│ └── 6.2.5 打印平均损失: `print("第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))`
│
├── 7. 保存模型
│ └── 操作: `torch.save(model.state_dict(), "model.pth")`
│ ├── 作用: 将模型参数保存到文件
│ └── 输出: 模型文件 `model.pth`
│
├── 8. 保存词表
│ └── 操作:
│ ├── 8.1 打开文件: `writer = open("vocab.json", "w", encoding="utf8")`
│ ├── 8.2 写入词表: `writer.write(json.dumps(vocab, ensure_ascii=False, indent=2))`
│ └── 8.3 关闭文件: `writer.close()`
│ └── 输出: 词表文件 `vocab.json`
│
└── 9. 返回
└── 操作: `return`
└── 作用: 结束函数执行① 参数配置
epoch_num:训练轮数
batch_size:每轮训练的样本个数
char_dim:每个字的维度
hidden_size:隐含层(中间层)维度
num_rnn_layer:循环神经网络rnn层数
max_length:样本的最大长度
learning_rate:学习率
vocab_path:字 / 词表文件路径
corpus_path:语料文件路径
epoch_num = 10 #训练轮数
batch_size = 20 #每次训练样本个数
char_dim = 50 #每个字的维度
hidden_size = 100 #隐含层维度
num_rnn_layers = 3 #rnn层数
max_length = 20 #样本最大长度
learning_rate = 1e-3 #学习率
vocab_path = "chars.txt" #字表文件路径
corpus_path = "corpus.txt" #语料文件路径② 构建词汇表
vocab:调用build_vocab函数建立字表
vocab = build_vocab(vocab_path) #建立字表③ 构建数据集和数据加载器
data_loader:调用build_dataset数据加载器函数建立数据集
data_loader = build_dataset(corpus_path, vocab, max_length, batch_size) #建立数据集④ 初始化模型
model:调用TorchModel类建立模型
char_dim:每个字的维度 hidden_size:隐含层维度 num_rnn_layers:RNN网络层数
vocab:建立的字表
model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型⑤ 初始化优化器
optim:调用torch库函数建立优化器
torch.optim.Adam():创建 Adam 优化器,用于深度学习模型的参数优化。结合动量梯度下降和自适应学习率,提升训练稳定性。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
params | iterable | None | 需要优化的参数(如 model.parameters()) |
lr | float | 1e-3 | 学习率(如 0.001) |
betas | tuple | (0.9, 0.99) | 动量系数(β₁, β₂) |
eps | float | 1e-8 | 梯度裁剪的极小值(防止除零错误) |
weight_decay | float | 0 | 权重衰减系数(正则化) |
model.parameters():返回模型中所有可训练参数的迭代器,用于优化器绑定。
optim = torch.optim.Adam(model.parameters(), lr=learning_rate) #建立优化器⑥ 模型训练主流程
model.train():将模型切换为训练模式(启用 Dropout、BatchNorm 等训练专用层)。
optim.zero_grad():将优化器的梯度归零,为反向传播准备。
loss.backward():计算损失值对模型参数的梯度,沿计算图反向传播。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
retain_graph | bool | False | 是否保留计算图(需梯度多次更新时设为 True)。 |
create_graph | bool | False | 是否为梯度创建计算图(用于高阶导数)。 |
optim.step():根据梯度更新模型参数。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
closure | callable | None | 可选闭包函数,用于动态计算梯度。 |
列表.append():向列表末尾添加单个元素。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
item | 任意类型 | 无 | 需要添加的元素。 |
loss.item():将标量损失值转换为 Python 标量(如 float),用于计算平均值或记录日志。
np.mean():计算数组或可迭代对象的平均值。
#训练开始
for epoch in range(epoch_num):
model.train()
watch_loss = []
for x, y in data_loader:
optim.zero_grad() #梯度归零
loss = model(x, y) #计算loss
loss.backward() #计算梯度
optim.step() #更新权重
watch_loss.append(loss.item())
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))⑦ 模型保存
torch.save():保存模型参数到磁盘,支持自定义保存路径和文件名。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
obj | any | None | 需要保存的对象(如 model.state_dict())。 |
f | file_like | None | 文件句柄(若未提供,需指定 save_path 和 filename)。 |
save_path | str | None | 保存目录路径。 |
filename | str | None | 保存文件名(默认为 model.pth)。 |
tuple_to_numpy | bool | False | 是否将元组转换为 NumPy 数组。 |
open():打开文件并返回文件对象,用于读写操作。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
file_name | str | 无 | 文件路径(需包含扩展名)。 |
mode | str | 'r' | 文件打开模式(如 'w'、'a')。 |
buffering | int | None | 缓冲区大小(仅二进制模式有效)。 |
encoding | str | None | 文件编码(如 'utf-8')。 |
newline | str | '\n' | 行结束符。 |
write():向文件写入指定内容
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
content | str | None | 需要写入的字符串内容。 |
json.dumps(): 将 Python 对象序列化为格式化的 JSON 字符串,支持自定义编码规则、缩进、字符集等,常用于数据持久化或 API 交互。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
obj | any | None | 需要序列化的 Python 对象(如字典、列表、类实例等)。 |
indent | int/str | None | 缩进空格数(如 4)或缩进字符串(如 " "),美化 JSON 输出。 |
ensure_ascii | bool | True | 是否强制将非 ASCII 字符转义为 Unicode 码点(如 \\u4e2d)。设为 False 保留原始字符。 |
sort_keys | bool | False | 是否对字典的键进行排序。 |
default | callable | None | 自定义序列化函数,处理不可序列化对象(如 datetime)。 |
separators | tuple | (', ') | 分隔符元组(如 (',', ': ')),控制项间格式。 |
skipkeys | bool | False | 是否跳过字典中值为 None 的键。 |
cls | type | None | 自定义 JSON 编码器类(如 json.JSONEncoder 的子类)。 |
close():关闭文件对象,释放系统资源。
#保存模型
torch.save(model.state_dict(), "model.pth")
#保存词表
writer = open("vocab.json", "w", encoding="utf8")
writer.write(json.dumps(vocab, ensure_ascii=False, indent=2))
writer.close()5.调用模型预测
代码运行流程
predict 函数流程
├── 1. 初始化参数
│ ├── 1.1 `char_dim = 50`:每个字的维度
│ ├── 1.2 `hidden_size = 100`:隐含层维度
│ ├── 1.3 `num_rnn_layers = 3`:RNN 层数
│ ├── 1.4 `model_path`:模型权重文件路径
│ ├── 1.5 `vocab_path`:字表文件路径
│ └── 1.6 `input_strings`:待预测的字符串列表
│
├── 2. 建立字表
│ └── 操作: `vocab = build_vocab(vocab_path)`
│ ├── 作用: 从字表文件中构建词汇表
│ └── 输出: `vocab` 字典,包含字符到索引的映射
│
├── 3. 建立模型
│ └── 操作: `model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab)`
│ ├── 作用: 初始化模型,定义网络结构
│ └── 输出: `model` 对象,包含模型参数和计算逻辑
│
├── 4. 加载模型权重
│ └── 操作: `model.load_state_dict(torch.load(model_path))`
│ ├── 作用: 加载训练好的模型权重
│ └── 输出: 更新后的 `model` 对象,包含训练好的参数
│
├── 5. 设置模型为评估模式
│ └── 操作: `model.eval()`
│ ├── 作用: 关闭 dropout 和 batch normalization 等训练模式
│ └── 输出: 模型进入评估模式
│
├── 6. 逐条预测
│ ├── 6.1 遍历输入字符串列表: `for input_string in input_strings`
│ └── 6.2 每条字符串的处理逻辑:
│ ├── 6.2.1 将字符串转换为数字序列: `x = sentence_to_sequence(input_string, vocab)`
│ │ ├── 作用: 使用 `sentence_to_sequence` 函数将字符串映射为数字序列
│ │ └── 输出: `x` 列表,包含字符对应的索引(如 `[1, 2, 3, 4]`)
│ │
│ ├── 6.2.2 打印数字序列: `print(x)`
│ │ └── 作用: 输出数字序列,便于调试和观察
│ │
│ ├── 6.2.3 模型预测: `with torch.no_grad(): result = model.forward(torch.LongTensor([x]))[0]`
│ │ ├── 作用: 使用模型进行前向传播,生成预测结果
│ │ └── 输出: `result` 张量,包含模型输出的概率分布
│ │
│ ├── 6.2.4 获取预测标签: `result = torch.argmax(result, dim=-1)`
│ │ ├── 作用: 对概率分布取 argmax,生成预测的 01 序列
│ │ └── 输出: `result` 张量,包含预测的标签(如 `[0, 1, 0, 1]`)
│ │
│ ├── 6.2.5 打印预测标签: `print(result)`
│ │ └── 作用: 输出预测的 01 序列,便于调试和观察
│ │
│ └── 6.2.6 切分并打印文本: `for index, p in enumerate(result): ...`
│ ├── 作用: 根据预测的 01 序列切分文本,并在预测为 1 的地方添加空格
│ └── 输出: 切分后的文本(如 `"我 是 小青蛙"`)
│
└── 7. 返回
└── 操作: 结束函数执行① 参数配置
char_dim:每个字的维度
hidden_size:隐含层(中间层)维度
num_rnn_layer:循环神经网络rnn层数
② 构建词汇表
vocab:调用build_vocab函数建立字表
vocab = build_vocab(vocab_path) #建立字表④ 初始化模型
model:调用TorchModel类建立模型
char_dim:每个字的维度 hidden_size:隐含层维度 num_rnn_layers:RNN网络层数
vocab:建立的字表
model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型⑤ 加载模型权重
model.load_state_dict():加载预训练模型的权重到当前模型中,用于模型恢复或迁移学习。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
state_dict | dict | None | 包含模型参数的字典(如 torch.load("model.pth") 的输出)。 |
strict | bool | False | 是否严格匹配参数名称和形状(True 会报错不匹配项)。 |
torch.load():从磁盘加载保存的 PyTorch 模型、张量或优化器状态。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
file_path | str | None | 文件保存路径(如 "model.pth")。 |
map_location | callable | None | 自定义张量存储位置(如 lambda storage, loc: storage.load(loc))。 |
pickle_module | module | pickle | 自定义序列化模块(如 dill)。 |
model.load_state_dict(torch.load(model_path)) #加载训练好的模型权重
⑥ 设置模型为预测模式
model.eval():将模型切换为评估模式,关闭训练专用层(如 Dropout、BatchNorm)。
⑦ 预测主流程
序列转换:将输入字符串转换为模型可识别的索引序列。
#逐条预测
x = sentence_to_sequence(input_string, vocab)模型推理:加载预训练模型,输出每个时间步的类别概率。
torch.no_grad():在推理或评估时禁用梯度计算,节省内存和计算资源。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
disable_gradient | bool | True | 是否禁用梯度计算(仅影响 autograd 操作)。 |
torch.LongTensor():将数据转换为 PyTorch 的长整型张量。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
data | array_like | None | 输入数据(如列表、NumPy 数组)。 |
dtype | torch.dtype | torch.long | 数据类型(默认 torch.long)。 |
device | str | None | 指定设备(如 "cuda")。 |
torch.argmax():返回张量中最大值的索引。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
dim | int | None | 沿指定维度搜索最大值(如 dim=-1 表示最后一维)。 |
keepdim | bool | False | 是否保留原维度(True 返回形状相同的索引张量)。 |
out | Tensor | None | 输出结果存储的位置。 |
with torch.no_grad():
result = model.forward(torch.LongTensor([x]))[0]
result = torch.argmax(result, dim=-1) #预测出的01序列结果切分:根据预测标签为 1 的位置,对原始字符串进行实体分割。
格式化输出:在实体边界插入空格,打印分割结果。
enumerate():遍历可迭代对象,同时返回元素的索引和值。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
iterable | iterable | None | 需要遍历的可迭代对象(如列表、生成器)。 |
start | int | 0 | 索引的起始值(如 start=1)。 |
#在预测为1的地方切分,将切分后文本打印出来
for index, p in enumerate(result):
if p == 1:
print(input_string[index], end=" ")
else:
print(input_string[index], end="")完整代码
#coding:utf8
import torch
import torch.nn as nn
import jieba
import numpy as np
import random
import json
from torch.utils.data import DataLoader
"""
基于pytorch的网络编写一个分词模型
我们使用jieba分词的结果作为训练数据
看看是否可以得到一个效果接近的神经网络模型
"""
class TorchModel(nn.Module):
def __init__(self, input_dim, hidden_size, num_rnn_layers, vocab):
super(TorchModel, self).__init__()
self.embedding = nn.Embedding(len(vocab) + 1, input_dim) #shape=(vocab_size, dim)
self.rnn_layer = nn.RNN(input_size=input_dim,
hidden_size=hidden_size,
batch_first=True,
bidirectional=False,
num_layers=num_rnn_layers,
nonlinearity="relu",
dropout=0.1)
self.classify = nn.Linear(hidden_size, 2)
self.loss_func = nn.CrossEntropyLoss(ignore_index=-100)
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #output shape:(batch_size, sen_len, input_dim)
x, _ = self.rnn_layer(x) #output shape:(batch_size, sen_len, hidden_size)
y_pred = self.classify(x) #input shape:(batch_size, sen_len, class_num)
if y is not None:
#(batch_size * sen_len, class_num), (batch_size * sen_len, 1)
return self.loss_func(y_pred.view(-1, 2), y.view(-1))
else:
return y_pred
class Dataset:
def __init__(self, corpus_path, vocab, max_length):
self.vocab = vocab
self.corpus_path = corpus_path
self.max_length = max_length
self.load()
def load(self):
self.data = []
with open(self.corpus_path, encoding="utf8") as f:
for line in f:
sequence = sentence_to_sequence(line, self.vocab)
label = sequence_to_label(line)
sequence, label = self.padding(sequence, label)
sequence = torch.LongTensor(sequence)
label = torch.LongTensor(label)
self.data.append([sequence, label])
if len(self.data) > 10000:
break
def padding(self, sequence, label):
sequence = sequence[:self.max_length]
sequence += [0] * (self.max_length - len(sequence))
label = label[:self.max_length]
label += [-100] * (self.max_length - len(label))
return sequence, label
def __len__(self):
return len(self.data)
def __getitem__(self, item):
return self.data[item]
#文本转化为数字序列,为embedding做准备
def sentence_to_sequence(sentence, vocab):
sequence = [vocab.get(char, vocab['unk']) for char in sentence]
return sequence
#基于结巴生成分级结果的标注
def sequence_to_label(sentence):
words = jieba.lcut(sentence)
label = [0] * len(sentence)
pointer = 0
for word in words:
pointer += len(word)
label[pointer - 1] = 1
return label
#加载字表
def build_vocab(vocab_path):
vocab = {}
with open(vocab_path, "r", encoding="utf8") as f:
for index, line in enumerate(f):
char = line.strip()
vocab[char] = index + 1 #每个字对应一个序号
vocab['unk'] = len(vocab) + 1
return vocab
#建立数据集
def build_dataset(corpus_path, vocab, max_length, batch_size):
dataset = Dataset(corpus_path, vocab, max_length) #diy __len__ __getitem__
data_loader = DataLoader(dataset, shuffle=True, batch_size=batch_size) #torch
return data_loader
def main():
epoch_num = 10 #训练轮数
batch_size = 20 #每次训练样本个数
char_dim = 50 #每个字的维度
hidden_size = 100 #隐含层维度
num_rnn_layers = 3 #rnn层数
max_length = 20 #样本最大长度
learning_rate = 1e-3 #学习率
vocab_path = "chars.txt" #字表文件路径
corpus_path = "corpus.txt" #语料文件路径
vocab = build_vocab(vocab_path) #建立字表
data_loader = build_dataset(corpus_path, vocab, max_length, batch_size) #建立数据集
model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型
optim = torch.optim.Adam(model.parameters(), lr=learning_rate) #建立优化器
#训练开始
for epoch in range(epoch_num):
model.train()
watch_loss = []
for x, y in data_loader:
optim.zero_grad() #梯度归零
loss = model(x, y) #计算loss
loss.backward() #计算梯度
optim.step() #更新权重
watch_loss.append(loss.item())
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
#保存模型
torch.save(model.state_dict(), "model.pth")
#保存词表
writer = open("vocab.json", "w", encoding="utf8")
writer.write(json.dumps(vocab, ensure_ascii=False, indent=2))
writer.close()
return
#最终预测
def predict(model_path, vocab_path, input_strings):
#配置保持和训练时一致
char_dim = 50 # 每个字的维度
hidden_size = 100 # 隐含层维度
num_rnn_layers = 3 # rnn层数
vocab = build_vocab(vocab_path) #建立字表
model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型
model.load_state_dict(torch.load(model_path)) #加载训练好的模型权重
model.eval()
for input_string in input_strings:
#逐条预测
x = sentence_to_sequence(input_string, vocab)
print(x)
with torch.no_grad():
result = model.forward(torch.LongTensor([x]))[0]
result = torch.argmax(result, dim=-1) #预测出的01序列
print(result)
#在预测为1的地方切分,将切分后文本打印出来
for index, p in enumerate(result):
if p == 1:
print(input_string[index], end=" ")
else:
print(input_string[index], end="")
print()
if __name__ == "__main__":
main()
# print(jieba.lcut("今天天气不错我们去春游吧"))
# print(sequence_to_label("今天天气不错我们去春游吧"))
# print(sentence_to_sequence("今天天气不错我们去春游吧"))
# input_strings = ["同时国内有望出台新汽车刺激方案",
# "沪胶后市有望延续强势",
# "经过两个交易日的强势调整后",
# "昨日上海天然橡胶期货价格再度大幅上扬"]
# predict("model.pth", "chars.txt", input_strings)

四、CRF —— 条件随机场
CRF是为了解决,当预测某一个字为一种实体的左边界时,则其右边不可能是其余实体的内部或右边界,我们运用另一个矩阵控制序列前后转移的概率(相关性)
CRF的本质是在神经网络中加入一个CRF - 转移矩阵
1.CRF - 转移矩阵
CRF - 转移矩阵:标签数量 × 标签数量,本质上学习的是字和字之间两两标签转移的概率


START 和 END 可以看作两个特殊的符号,标记句子的开始和句子的结束
2.发射矩阵
发射矩阵:对于一句话中的每一个字进行四分类预测,判断其作为词的左右边界、词的内部、单字的概率。

3.结合发射矩阵和转移矩阵
CRF - 转移矩阵可以分别学习到某个类别的字转移到其他类别字的概率,然后与 发射矩阵学习到的输入向量过神经网络预测到的两字间的概率值相加,总和进行比较,对输入序列进行预测
CRF - 条件随机场输出的转移矩阵 可以与 向量经过神经网络后得出的发射矩阵结合使用,输出一个更优的预测结果

转移矩阵可以影响发射矩阵的结果,相当于在神经网络结构中加入一层神经网络
作用:规避一些不合理的序列输出
4.CRF —— Loss定义
① 输入序列 X,输出序列为 y的路径分数:A 为转移矩阵(代表前一个字向后一个字转移的概率),P 为发射矩阵(过神经网络的每个字对应的概率值),s(X, y) 代表任意一条路径的正确概率得分
s(X, y) = log(A * P) = logA + logP(这里的路径分数可以看作结合两矩阵,再做 log 运算后的)

② 输入序列X,预测输出序列为y的概率:对上式做softmax,对 步骤 ① 得到的所有路径分数做归一化

③ 对上式取log,目标为最大化该值(方便计算,与 p(y | X) 成正比):

依然希望这个 log (p(y | X)) 路径分数是最大的
④ 对上式取相反数做loss,目标为最小化该值:

其他路径的总概率得分之和的 log 值 - 正确路径的总概率得分
CRF会明显拖慢训练速度,以效率的角度考虑可以不使用CRF
序列标注任务需要位置对应
而如果使用Bert模型,则做序列标注任务时,label标签在前后都需要加一个占位符,将Bert模型的CLS和SCP标识符包括
文本分类任务与序列标注任务模型结构的主要区别:pooling 归一化层
5.CRF —— 源码解读
博主文章:【NLP 36、CRF条件随机场 —— 源码解读】-CSDN博客
五、解码方式
1.篱笆墙解码【动态规划问题】
篱笆墙问题最简单的解法 —— 暴力求解,计算所有路径和所有节点的概率值,找到最好的路径
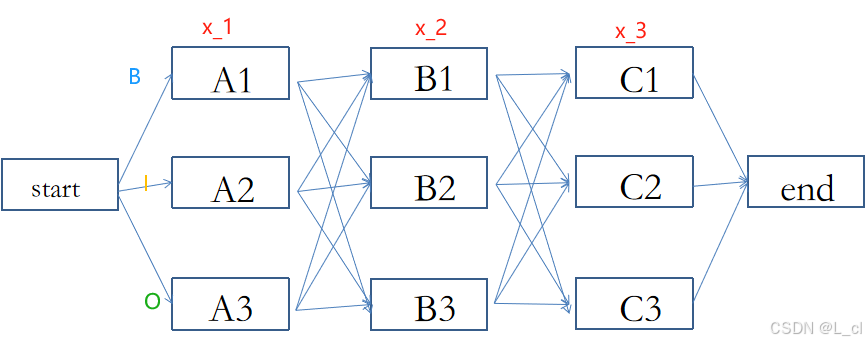
计算次数:D ^ n (D为每一层的节点数,n为计算层数)
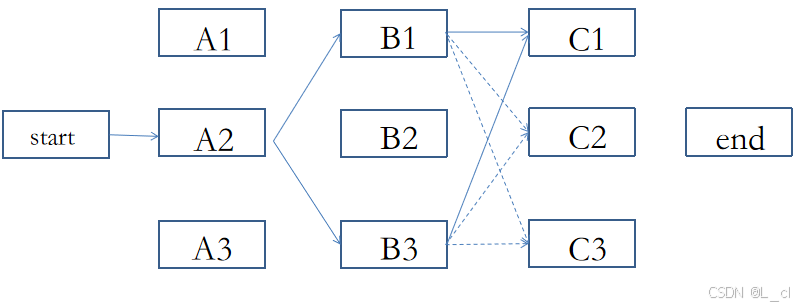
2.篱笆墙解码优化方式 ① Beam Search解码
首先定义一个 Beam Size,代表保留路径的最大数目;剪枝操作,将每一段的路径分别算出,然后计算每一小段路径的概率,将概率由高到低进行pa保留 Beam SIze 数目,这样每次剪枝,保留Beam Size数目路径,最终计算次数为:n * Beam Size * D,D为每一层的节点个数,n为路径的长度(计算层数 / 时间步的数目)
特例:Greedy Search 贪婪解码
将Beam Search设置为1,相当于每一步只保留结果最好的数,然后在下一层进行判断
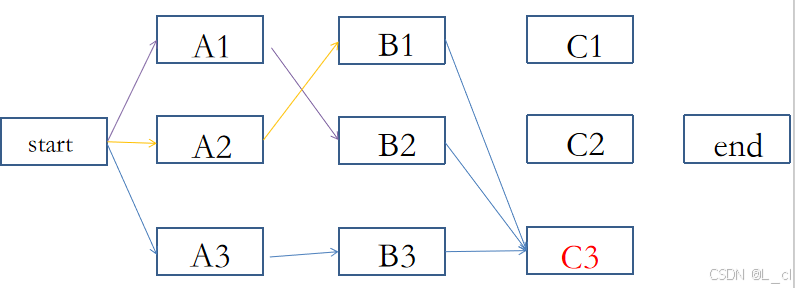
3.篱笆墙解码优化方式 ② 维特比解码
对每一层的各个节点,分别计算对下一层的所有节点的概率值,然后每个结点保留概率值最高的一条路径,然后再对下一层的每个节点进行计算,最终计算次数为:n * D * D,D为每一层的节点个数,n为路径的长度(计算层数 / 时间步的数目)
4.效率对比
假设共有 n 组(列)节点,每一组节点平均数量为 D
穷举路径计算复杂度为:D ^ n
维特比解码复杂度为:n * D ^ 2
Beam Search解码复杂度为:n * D * B,B为BeamSize ,可以允许 B 超过 D
维特比解码 和 Beam Search解码复杂度主要比较 D 和 B 的大小关系 D为每一层的结点个数,等同于词表大小,n为路径的长度(计算层数 / 时间步的数目)
在序列标注任务上,用维特比编码的形式会多一点, 主要因为序列标注任务上,每一层结点数 D 不会过大
在生成式任务上,用Beam Search编码的形式多一点,因为生成式任务的节点数量 D 等同于词表大小
若序列标注任务中使用了CRF,则一般与维特比编码一起使用
若不使用CRF - 条件随机场,则不会出现篱笆墙解码问题
5.应用场景
Ⅰ、信息抽取与知识图谱构建
① 结构化数据生成:
从非结构化文本(如新闻、论文)中提取人名、地名、机构名等实体,生成结构化数据。例如,在新闻“苹果公司2024年发布新款手机”中提取“苹果公司”(机构名)和“2024年”(时间)
在生物医学领域,从科研文献中提取基因、蛋白质、疾病等实体,支持药物研发和医学研究
② 知识图谱构建:
通过实体间的关联(如“姚明→中国篮协”),构建实体关系网络,支持语义搜索和智能问答。例如,将企业收购事件中的“主体-行为-对象”三元组结构化存储
Ⅱ、智能交互与内容理解
① 问答对话系统
识别用户问题中的关键实体(如“北京今天天气”中的“北京”和“今天”),精准匹配知识库中的答案
在客服场景中,通过识别用户咨询中的产品名称、故障类型等实体,自动路由到对应服务模块
② 机器翻译
保留专有名词的语义一致性。例如,将“Apple Inc.”正确翻译为“苹果公司”而非字面翻译,避免歧义
Ⅲ、行业垂直应用
① 金融与法律分析
在财报中提取公司名、财务指标(如“净利润增长20%”),辅助投资决策
法律文书中识别案件相关人、时间、地点,加速案件检索与证据链构建
② 医疗健康
从电子病历中提取疾病名称(如“糖尿病”)、药物剂量,支持临床诊断和个性化治疗
③ 社交媒体与舆情监控
分析微博、评论中的品牌名、产品名,统计热点事件传播路径。例如,追踪“某品牌新品发布”的提及量和情感倾向
Ⅳ、内容生成与优化
① 自动摘要与推荐系统
从长文本中提取核心实体(如新闻中的关键人物和事件),生成简洁摘要
根据用户历史行为中的实体偏好(如“科幻电影”),优化推荐内容
② 广告与营销
识别用户搜索词中的产品类目(如“运动鞋”),定向推送相关广告
Ⅴ、科研与安全领域
① 情报分析
从公开报告中提取军事设施、技术术语等敏感实体,支持风险预警
② 学术研究
在论文中标注化学物质、实验方法,构建学科知识库
6.评价指标
序列标注准确率 ≠ 实体挖掘准确率
实体需要完整命中才能算正确
对于标注序列要进行解码

准确率: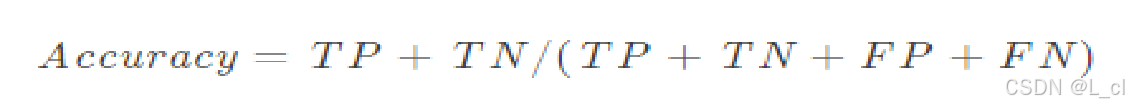
精确率:![]()
召回率:![]()
F1score:F1 Score 是精确率(Precision)和召回率(Recall)的调和平均数,它是信息检索、机器学习和统计分类中常用的一种评估指标,旨在综合考虑精确率和召回率,用于衡量分类模型的性能。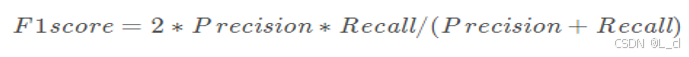
Macro - F1(宏观):对每个类别分别计算 F1 Score,然后取平均值。对于多分类问题,如果有 N个类别,先计算每个类别的精确率Precision和召回率Recall,并得到每个类别的 F1Score ,然后计算它们的平均值,公式: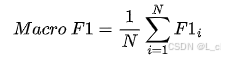
Micro - F1(微观):将所有类别的样本合并计算准确率和召回率,之后计算F1;将所有类别的真阳性(True Positives)、假阳性(False Positives)和假阴性(False Negatives)分别累加,然后根据这些累加值计算出一个总体的精确率和召回率,再计算 F1Score
公式: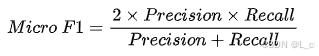
区别在于是否考虑类别样本数量的均衡
Macro - F1 和 Micro - F1 选择策略
① 样本均衡且类别重要性相同:优先使用Macro-F1
② 样本不均衡但需关注全局:选择Micro-F1,或结合Weighted-F1(按样本量加权)
③ 多维度评估:同时计算Macro和Micro指标,全面分析模型性能
实例说明
-
案例1(Macro-F1):
在癌症病理图像分类中,10个类别(如肺癌、乳腺癌)的样本量差异大,但每个类别的误诊代价相同。此时Macro-F1能平等反映模型对各类的识别能力 -
案例2(Micro-F1):
在电商评论情感分析中,90%的评论为“好评”,10%为“差评”。若业务更关注整体准确率,Micro-F1更适合;若需确保差评召回率,则需补充Macro-F1
| 维度 | Macro-F1 | Micro-F1 |
|---|---|---|
| 核心思想 | 类别平等,关注每个类的独立表现 | 样本平等,关注整体预测效果 |
| 适用数据 | 样本均衡或类别重要性均等 | 样本不均衡或需综合评估整体性能 |
| 敏感对象 | 对少数类敏感 | 对多数类敏感 |
| 典型场景 | 医学多疾病分类、多情感分析 | 搜索引擎排序、大规模推荐系统 |
六、基于规则的命名实体识别
① 常使用正则表达式来匹配特定句式、词表
② 原则上,规则能处理的好的情况下,尽量不用模型
③ 使用规则的方式同样可以计算准确率和召回率
④ 规则的顺序有时会影响结果,调试时需注意
⑤ 规则的编写,一般会使用正则表达式来编写
七、正则表达式⭐
正则表达式(regular expression):描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
pattern:ab 检查pattern是否在字符串中出现
string 1: babb re.search(pattern, string) True
string 2: bbba re.search(pattern, string) None
string 3: baaa re.search(pattern, string) None
string 4: abb re.search(pattern, string) True
检查pattern是否在字符串开头出现
string 1: babb re.match(pattern, string) None
string 2: bbba re.match(pattern, string) None
string 3: baaa re.match(pattern, string) None
string 4: abb re.match(pattern, string) True
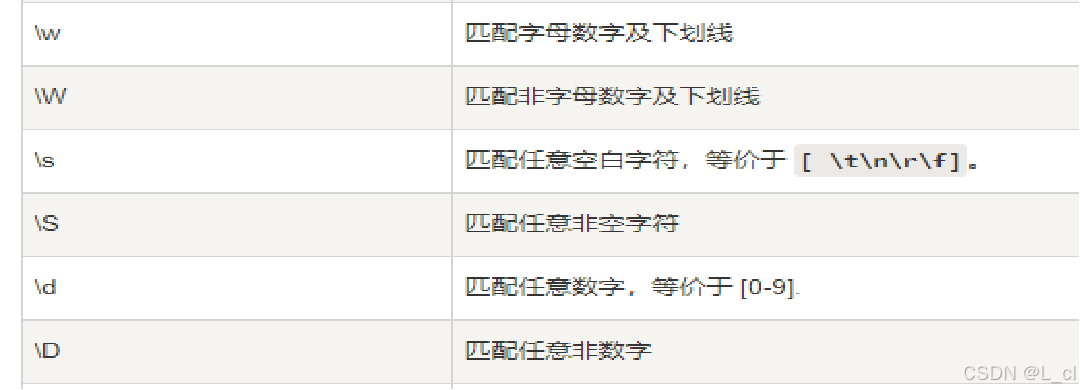
1.元字符
匹配任意数字或字母
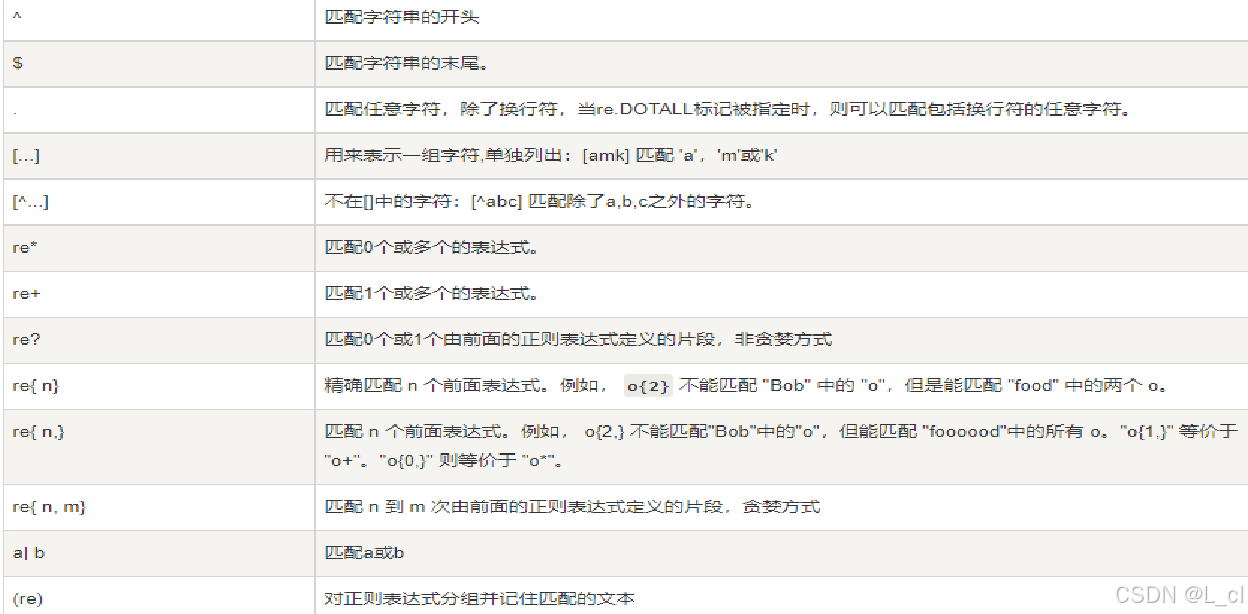
2.特殊符号
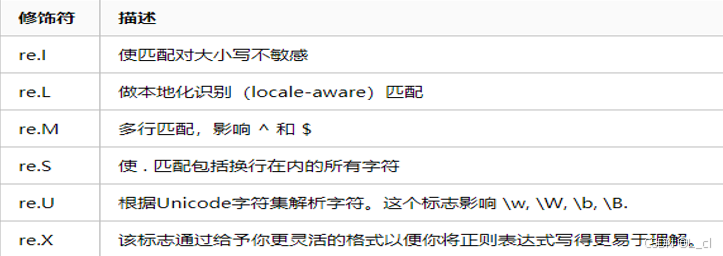
3.修饰符
4.贪婪模式
贪婪模式是正则表达式的一种匹配方式,在这种模式下,正则表达式会尽可能多地匹配字符。它会尝试匹配满足模式的最长字符串
示例:
贪婪模式:
import re
string = "aabab"
pattern = "a.*b"
result = re.search(pattern, string)
print(result.group()) # 输出:aabab非贪婪模式:
import re
string = "aabab"
pattern = "a.*?b"
result = re.search(pattern, string)
print(result.group()) # 输出:aab常见的贪婪量词及其非贪婪形式
-
*(贪婪):匹配零次或多次,尽可能多地匹配。- 非贪婪形式:
*?
- 非贪婪形式:
-
+(贪婪):匹配一次或多次,尽可能多地匹配。- 非贪婪形式:
+?
- 非贪婪形式:
-
?(贪婪):匹配零次或一次,尽可能多地匹配。- 非贪婪形式:
??
- 非贪婪形式:
-
{m,n}(贪婪):匹配m到n次,尽可能多地匹配。- 非贪婪形式:
{m,n}?
- 非贪婪形式:
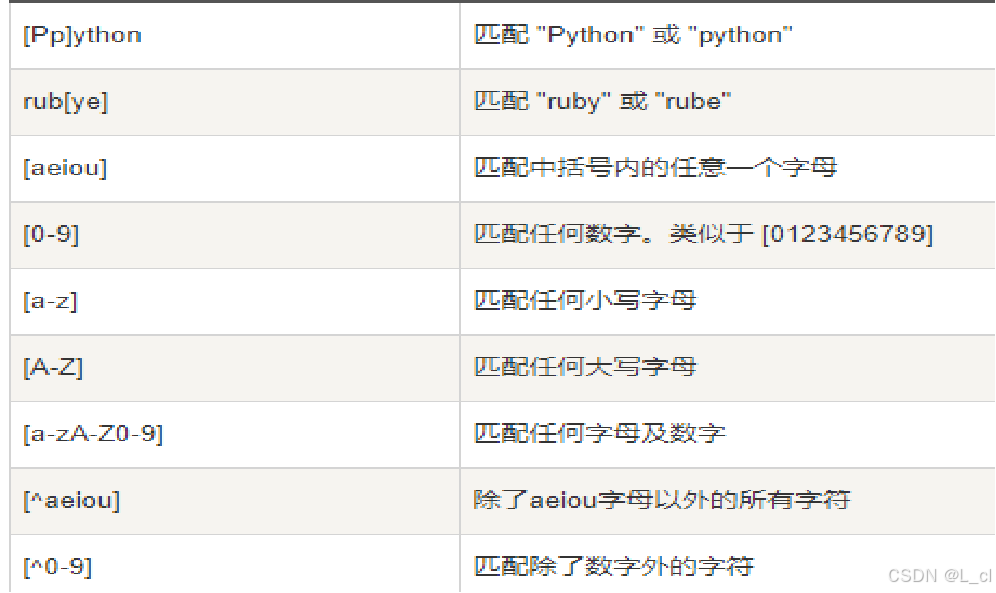
5.常见pattern写法
6.主要函数
re.search(pattern, string):在 string 中搜索第一个匹配 pattern 的子串,如果找到则返回一个 Match 对象,否则返回 None
re.match(pattern, string):从 string 的开始位置尝试匹配 pattern,如果匹配成功返回一个 Match 对象,否则返回 None
re.findall(pattern, string):在 string 中查找所有匹配 pattern 的子串,以列表形式返回
re.sub(pattern, repl, string):在 string 中搜索匹配 pattern 的子串,并用 repl 替换它们,返回替换后的新字符串
re.split(pattern, string):按照 pattern 将 string 分割成多个子串,返回一个列表
re.fulmatch():用于检查整个字符串是否完全匹配给定的正则表达式。如果整个字符串与正则表达式匹配成功,则返回一个匹配对象(Match);否则返回 None。
7.代码示例
import re
import random
import time
"""
介绍正则表达式的常用操作
"""
# re.match(pattern, string) 验证字符串起始位置是否与pattern匹配
print(re.match('北医[一二三]院', '北医三院怎么走')) # 在起始位置匹配
print(re.match('www', 'www.runoob.com')) # 不在起始位置匹配
# # re.search(pattern, string) 验证字符串中是否与有片段与pattern匹配
print(re.search('www', 'www.runoob.com')) # 在起始位置匹配
print(re.search('run', 'www.runoob.com')) # 不在起始位置匹配
print("————————————————————————————————————————————")
#pattern中加括号,可以实现多个pattern的抽取
line = "Cats are smarter than dogs"
matchObj = re.match(r'(.*) are (.*?) .*', line)
if matchObj:
print("matchObj.group() : ", matchObj.group())
print("matchObj.group(1) : ", matchObj.group(1))
print("matchObj.group(2) : ", matchObj.group(2))
else:
print("No match!!")
##########################################
print("————————————————————————————————————————————")
# re.sub(pattern, repl, string, count=0) 利用正则替换文本
# 将string中匹配到pattern的部分,替换为repl
phone = "2004-959-559#这是一个国外电话号码"
# 删除字符串中的 # 后注释
num = re.sub('#.*$', "", phone)
print("电话号码是: ", num)
# 删除非数字(-)的字符串 \D 代表非数字 \d 代表数字 脱敏
num = re.sub('\d', "*", phone)
print("电话号码是 : ", num)
print("————————————————————————————————————————————")
# repl 参数可以是一个函数,要注意传入的参数不是值本身,是match对象
# 将匹配的数字乘以 2
def double(matched):
return str(int(matched.group()) * 2)
string = 'A23G4HFD567'
print(re.sub('\d', double, string))
# count参数决定替换几次,默认是全部替换
string = "00000"
print(re.sub("0", "1", string, count=2))
############################
print("————————————————————————————————————————————")
# re.findall(string[, pos[, endpos]])
# 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表
pattern = re.compile('\d+') # 查找数字
result1 = pattern.findall('runoob 123 google 456')
result2 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)
print(re.findall("北京|上海|广东", "我从北京去上海"))
################################
print("————————————————————————————————————————————")
# re.split(pattern, string[, maxsplit=0]) 照能够匹配的子串将字符串分割后返回列表
string = "1、不评价别人; 2、不给别人建议; 3、没有共同利益,不必追求共识"
print(re.split("\d、", string))
print(re.split(";|、", string))
##############################
print("————————————————————————————————————————————")
# 匹配汉字 汉字unicode编码范围[\u4e00-\u9fa5]
print(re.findall("[\u4e00-\u9fa5]", "ad噶是的12范德萨发432文"))
print("————————————————————————————————————————————")
##############################
# 如果需要匹配,在正则表达式中有特殊含义的符号,需做转义
print(re.search("(图)", "贾玲成中国影史票房最高女导演(图)").group())
print(re.search("\(图\)", "贾玲成中国影史票房最高女导演(图)").group())
print(re.sub("(图)", "", "贾玲成中国影史票房最高女导演(图)"))
print(re.sub("\(图\)", "", "贾玲成中国影史票房最高女导演(图)"))
print("————————————————————————————————————————————")
###############################
pattern = "\d12\w"
re_pattern = re.compile(pattern)
print(re.search(pattern, "432312d"))
print("————————————————————————————————————————————")
# # 效率
import time
import random
chars = list("abcdefghijklmnopqrstuvwxyz")
#随机生成长度为n的字母组成的字符串
string = "".join([random.choice(chars) for i in range(100)])
pattern = "".join([random.choice(chars) for i in range(4)])
re_pattern = re.compile(pattern)
start_time = time.time()
for i in range(50000):
# pattern = "".join([random.choice(chars) for i in range(3)])
# re.search(pattern, string)
re.search(re_pattern, string)
print("正则查找耗时:", time.time() - start_time)
start_time = time.time()
for i in range(50000):
# pattern = "".join([random.choice(chars) for i in range(3)])
pattern in string
print("python in查找耗时:", time.time() - start_time)
8.正则表达式常用练习
Ⅰ、基础匹配练习
① 手机号验证
匹配大陆手机号
r‘ ’ 是原始字符串的表示方式,能够避免对反斜杠的转义。
正则表达式的具体构成:
^ 表示字符串的开始。
1 表示手机号码必须以数字 1 开头。
[3-9] 表示第二位只能是 3 到 9 之间的数字,这符合中国手机号的格式。
\d{9} 表示接下来的 9 位可以是任意数字(0-9),\d 是数字的通用表示,{9} 表示匹配 9 次。
$ 表示字符串的结束。
re.match(pattern, string):从 string 的开始位置尝试匹配 pattern,如果匹配成功返回一个 Match 对象,否则返回 None
import re
# 1.手机号验证
def isPhoneNum(phone):
pattern = r'^1[3-9]\d{9}$'
'''
r'' 是原始字符串的表示方式,能够避免对反斜杠的转义。
^ 表示字符串的开始。
1 表示手机号码必须以数字 1 开头。
[3-9] 表示第二位只能是 3 到 9 之间的数字,这符合中国手机号的格式。
\d{9} 表示接下来的 9 位可以是任意数字(0-9),\d 是数字的通用表示,{9} 表示匹配 9 次。
$ 表示字符串的结束。
'''
return bool(re.match(pattern, phone))
print(isPhoneNum("15500600904"))
print(isPhoneNum("1234567890123456"))
print(isPhoneNum("1234568"))
② 邮箱地址提取
匹配符合以下格式的电子邮件地址:
- 用户名部分:由字母、数字、点号
.或短横线-组成,至少一个字符。- 域名部分:由字母、数字、点号
.或短横线-组成,至少一个字符。- 顶级域名:由字母、数字或下划线组成,至少一个字符。
[\w\.-]+
\w:匹配字母、数字或下划线(等价于[a-zA-Z0-9_])。\.:匹配点号.(需要转义,因为.在正则中是特殊字符)。-:匹配短横线-。[]:字符集,表示匹配其中任意一个字符。+:表示前面的字符集至少出现一次。
这部分匹配电子邮件地址的用户名部分,例如user.name或user-name。
@
- 匹配电子邮件地址中的
@符号,分隔用户名和域名。
[\w\.-]+
- 与第一部分类似,匹配域名部分,例如
example或sub.domain。
\.\w+
\.:匹配点号.。\w+:匹配至少一个字母、数字或下划线,表示顶级域名,例如.com或.org。
re.findall(pattern, string):在 string 中查找所有匹配 pattern 的子串,以列表形式返回
# 2.邮箱地址提取
def getEmail(text):
pattern = r'[\w\.-]+@[\w\.-]+\.\w+'
'''
[\w\.-]+ 表示匹配一个或多个字符,这些字符可以是字母、数字、下划线(\w),也可以是点(.)或连字符(-)。这是匹配邮箱的用户名部分,即 @ 符号前面的部分。
@ 表示匹配字符 @,这是邮箱地址中固定的符号。
[\w\.-]+ 表示匹配一个或多个字符,这些字符可以是字母、数字、下划线(\w),也可以是点(.)或连字符(-)。这是匹配域名部分。
\.\w+ 表示匹配一个点(.)后跟一个或多个字母、数字或下划线(\w)。这是匹配顶级域名部分,如 .com、.cn 等。
'''
return bool(re.findall(pattern, text))
print(getEmail(" "))
print(getEmail("hello world"))
print(getEmail("www.baidu.@qq.com"))③ 中文姓名匹配
^ 表示字符串的开始。
[\u4e00-\u9fa5] 表示匹配一个中文字符,其中 \u4e00 表示中文字符的起始范围,\u9fa5 表示中文字符的结束范围。
{2,5} 表示匹配 2 到 5 个连续的中文字符。
$ 表示字符串的结束。
re.fulmatch():用于检查整个字符串是否完全匹配给定的正则表达式。如果整个字符串与正则表达式匹配成功,则返回一个匹配对象(Match);否则返回 None。
# 3.中文姓名匹配
def isChineseName(name):
pattern = r'^[\u4e00-\u9fa5]{2,4}$'
'''
^ 表示字符串的开始。
[\u4e00-\u9fa5] 表示匹配一个中文字符,其中 \u4e00 表示中文字符的起始范围,\u9fa5 表示中文字符的结束范围。
{2,5} 表示匹配 2 到 5 个连续的中文字符。
$ 表示字符串的结束。
'''
return bool(re.fullmatch(pattern, name))
print(isChineseName("张三"))
print(isChineseName("张三丰"))
print(isChineseName("张"))
Ⅱ、综合练习 —— 身份证号验证与信息提取
^ 表示字符串的开始,确保所有的匹配从字符串的开始位置开始。
(\d{6}) 是一个捕获组,用于匹配身份证号码的地址码部分,即开头的6位数字。
(\d{4}) 是一个捕获组,用于匹配身份证号码的出生年份部分,即接下来的4位数字。
(\d{2}) 是一个捕获组,用于匹配身份证号码的出生月份部分,再接下来的2位数字。
(\d{2}) 是一个捕获组,用于匹配身份证号码的出生日期部分,再接下来的2位数字。
\d{2} 用于匹配顺序码部分,即接下来的2位数字。
(\d) 是一个捕获组,用于匹配性别码部分,单数表示男性,双数表示女性。
(?:\d|X|x) 是一个非捕获组,用于匹配校验码部分,它既可以是数字0-9,也可以是大写的X或者小写的x。
$ 表示字符串的结束,确保所有的匹配到字符串的末尾位置结束。
# 身份证号验证和信息提取
def parse_id_card(id_card):
pattern = r'^(\d{6})(\d{4})(\d{2})(\d{2})\d{2}(\d)(?:\d|X|x)$'
'''
^ 表示字符串的开始,确保所有的匹配从字符串的开始位置开始。
(\d{6}) 是一个捕获组,用于匹配身份证号码的地址码部分,即开头的6位数字。
(\d{4}) 是一个捕获组,用于匹配身份证号码的出生年份部分,即接下来的4位数字。
(\d{2}) 是一个捕获组,用于匹配身份证号码的出生月份部分,再接下来的2位数字。
(\d{2}) 是一个捕获组,用于匹配身份证号码的出生日期部分,再接下来的2位数字。
\d{2} 用于匹配顺序码部分,即接下来的2位数字。
(\d) 是一个捕获组,用于匹配性别码部分,单数表示男性,双数表示女性。
(?:\d|X|x) 是一个非捕获组,用于匹配校验码部分,它既可以是数字0-9,也可以是大写的X或者小写的x。
$ 表示字符串的结束,确保所有的匹配到字符串的末尾位置结束。
'''
match = re.match(pattern, id_card)
if match:
birthday = f"{match.group(2)}-{match.group(3)}-{match.group(4)}"
sex = "男" if int(match.group(5)) % 2 == 1 else "女"
return {"address": match.group(1), "birthday": birthday, "sex": sex}
print(parse_id_card("11010119900101001X"))![]()
9.正则表达式实用技巧总结
Ⅰ、基础语法核心
① 元字符优先级
. 匹配任意非换行字符,\d 等价于 [0-9],\w 包含字母、数字和下划线
使用 [] 定义字符集,如 [a-z] 匹配小写字母,[^c] 表示排除字符c量
② 词控制次数
*(0次或多次),+(至少1次),?(0或1次),{n,m}(n到m次)
Ⅱ、高频场景公式
① 手机号:^1[3-9]\d{9}$(严格匹配11位中国大陆手机号)
② 邮箱:[\w.-]+@[\w.-]+\.\w+(支持带点/短横线的用户名和域名)
③ 密码强度:
基础:^[a-zA-Z]\w{5,17}$(字母开头,6-18位字母数字下划线)
增强:(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(必须包含大小写字母和数字)
Ⅲ、避坑小技巧
① 转义字符:特殊字符如 " . " 、 " * "需要使用 \ 转义,但在[]内无需转义符号
② 性能优化:避免嵌套量词,如(a+)+,优先使用具体字符集替代宽泛的
八、文本加标点任务 🚀
经过语音识别,或机器翻译,可能会得到没有标点符号的文本。此时进行自动文本打标有助于增强文本可读性
是一种粗粒度的分词
对传入文本中的每个字多分类,划定每个字应该属于的类别(类别:不加标点、加各类标点符号)
1.配置文件 config.py
model_path:保存训练好的模型权重文件路径。
schema_path:标签定义文件路径,定义实体类型与整数ID的映射关系。
train_data_path:训练数据文件路径,通常为分词后的序列标注格式。
valid_data_path:验证数据文件路径,用于模型性能评估。
vocab_path:词汇表文件路径,将字符映射到整数索引。
max_length:输入序列的最大长度,超过部分截断,不足部分填充。
hidden_size:隐藏层维度,决定模型记忆能力。
epoch:训练轮数,即数据集遍历次数。
batch_size:每次梯度更新使用的样本数量。
optimizer:选择优化算法
learning_rate:优化器的学习率,控制参数更新幅度。
use_crf:是否使用条件随机场(CRF)进行序列标注解码。
class_num:标签类别总数
# -*- coding: utf-8 -*-
"""
配置参数信息
"""
Config = {
"model_path": "model_output",
"schema_path": "data/schema.json",
"train_data_path": "data/train_corpus.txt",
"valid_data_path": "data/valid_corpus.txt",
"vocab_path":"chars.txt",
"max_length": 50,
"hidden_size": 128,
"epoch": 10,
"batch_size": 128,
"optimizer": "adam",
"learning_rate": 1e-3,
"use_crf": False,
"class_num": None
}2.模型文件 model.py
Ⅰ、模型初始化
代码运行流程
__init__ 方法流程
├── 1. 调用父类初始化
│ └── 操作: `super(TorchModel, self).__init__()`
│ └── 作用: 调用父类的初始化方法,确保继承的属性和方法正确初始化
│
├── 2. 从配置中获取参数
│ ├── 2.1 获取隐藏层大小: `hidden_size = config["hidden_size"]`
│ ├── 2.2 获取词汇表大小: `vocab_size = config["vocab_size"] + 1`
│ └── 2.3 获取类别数量: `class_num = config["class_num"]`
│
├── 3. 初始化嵌入层
│ └── 操作: `self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)`
│ ├── 作用: 将离散的词汇索引映射到连续的稠密向量空间
│ ├── 参数说明:
│ │ ├── `vocab_size`: 词汇表大小
│ │ ├── `hidden_size`: 嵌入向量的维度
│ │ └── `padding_idx=0`: 指定索引 0 用于填充,不更新其梯度
│ └── 输出: `self.embedding` 对象
│
├── 4. 初始化 LSTM 层
│ └── 操作: `self.layer = nn.LSTM(hidden_size, hidden_size, batch_first=True, bidirectional=True, num_layers=1)`
│ ├── 作用: 定义 LSTM 层,用于处理序列数据
│ ├── 参数说明:
│ │ ├── `hidden_size`: 隐藏层大小
│ │ ├── `batch_first=True`: 输入和输出的第一维度为批次大小
│ │ ├── `bidirectional=True`: 使用双向 LSTM
│ │ └── `num_layers=1`: LSTM 层数为 1
│ └── 输出: `self.layer` 对象
│
├── 5. 初始化分类层
│ └── 操作: `self.classify = nn.Linear(hidden_size * 2, class_num)`
│ ├── 作用: 将 LSTM 的输出映射到类别数量
│ ├── 参数说明:
│ │ ├── `hidden_size * 2`: 输入维度(双向 LSTM 的输出维度为隐藏层大小的两倍)
│ │ └── `class_num`: 输出维度(类别数量)
│ └── 输出: `self.classify` 对象
│
├── 6. 初始化 CRF 层
│ └── 操作: `self.crf_layer = CRF(class_num, batch_first=True)`
│ ├── 作用: 定义 CRF 层,用于序列标注任务
│ ├── 参数说明:
│ │ ├── `class_num`: 类别数量
│ │ └── `batch_first=True`: 输入和输出的第一维度为批次大小
│ └── 输出: `self.crf_layer` 对象
│
├── 7. 设置是否使用 CRF
│ └── 操作: `self.use_crf = config["use_crf"]`
│ └── 作用: 从配置中获取是否使用 CRF 的标志
│
└── 8. 初始化损失函数
└── 操作: `self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1)`
├── 作用: 定义交叉熵损失函数,忽略索引为 -1 的标签
└── 输出: `self.loss` 对象hidden_size:RNN/LSTM/GRU隐藏层维度,决定模型记忆能力。
vocab_size:词汇表大小
class_num:标签类别总数
use_crf:是否使用条件随机场(CRF)进行序列标注解码。
nn.Embedding():将离散的词索引映射为稠密的向量表示(词嵌入),常用于 NLP 任务的输入层。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
num_embeddings | int | None | 词汇表大小(输入维度,如 vocab_size)。 |
embedding_dim | int | None | 嵌入向量的维度(输出维度,如 char_dim=50)。 |
max_length | int | None | 序列的最大长度(用于动态 padding)。 |
padding_idx | int | None | 填充标记的索引(如 [PAD]=0,默认 None 不启用)。 |
sparse | bool | False | 是否使用稀疏矩阵存储(仅当 num_embeddings 很大时有用)。 |
_weight | Tensor | None | 预训练的嵌入权重(可选)。 |
nn.LSTM():实现长短期记忆网络(LSTM),处理序列数据并捕捉长期依赖。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
input_size | int | None | 单个时间步的输入特征维度(如词嵌入维度 char_dim=50)。 |
hidden_size | int | None | LSTM 单元的隐藏层维度。 |
num_layers | int | 1 | LSTM 层的数量。 |
batch_first | bool | False | 是否将 (batch_size, seq_len, features) 作为输入格式(默认为 (seq_len, batch_size, features))。 |
dropout | float | 0.0 | 在 LSTM 层后添加 dropout(防止过拟合)。 |
bidirectional | bool | False | 是否启用双向 LSTM(输出为两倍隐藏层维度)。 |
cell_class | Type[nn.RNNCell] | None | 自定义 RNN 单元类(默认为 nn.LSTMCell)。 |
initializer | Callable | None | 权重初始化方法。 |
nn.Linear():全连接层,将输入线性映射到输出。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
in_features | int | None | 输入特征数。 |
out_features | int | None | 输出特征数。 |
bias | bool | True | 是否启用偏置项。 |
device | str/int | None | 指定权重存储设备(如 "cuda")。 |
CRF():条件随机场(Conditional Random Field),用于序列标注任务,通过维特比算法解码最优标签序列。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
input_size | int | None | 单个时间步的输入特征维度(如 LSTM 输出维度)。 |
hidden_size | int | None | CRF 隐藏层维度。 |
num_tags | int | None | 标签类别总数。 |
transition_matrix | Tensor | None | 标签转移矩阵(num_tags x num_tags,默认随机初始化)。 |
mask | bool | False | 是否启用输入掩码(处理变长序列)。 |
torch.nn.CrossEntropyLoss():计算交叉熵损失,常用于分类任务。输入为 logits(未归一化的概率),无需手动 softmax。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
input_size | int | None | 输入特征数(即 logits 的维度)。 |
num_classes | int | None | 类别总数。 |
ignore_index | int | -100 | 忽略的标签索引(如 [PAD]=0)。 |
weight | Tensor | None | 类别权重(用于不平衡数据)。 |
reduction | str | "mean" | 损失计算的缩减方式(如 "sum" 或 "mean")。 |
label_smoothing | float | 0.0 | 标签平滑系数(防止过拟合)。 |
def __init__(self, config):
super(TorchModel, self).__init__()
hidden_size = config["hidden_size"]
vocab_size = config["vocab_size"] + 1
class_num = config["class_num"]
self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)
self.layer = nn.LSTM(hidden_size, hidden_size, batch_first=True, bidirectional=True, num_layers=1)
self.classify = nn.Linear(hidden_size * 2, class_num)
self.crf_layer = CRF(class_num, batch_first=True)
self.use_crf = config["use_crf"]
self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) #loss采用交叉熵损失Ⅱ、前向传播
代码运行流程
forward 方法流程
├── 1. 输入参数
│ ├── 1.1 `x`: 输入数据,形状为 `(batch_size, sen_len)`
│ └── 1.2 `target`: 真实标签(可选),形状为 `(batch_size, sen_len)`
│
├── 2. 嵌入层处理
│ └── 操作: `x = self.embedding(x)`
│ ├── 作用: 将输入的离散索引映射为稠密向量
│ └── 输出: `x` 张量,形状为 `(batch_size, sen_len, hidden_size)`
│
├── 3. LSTM 层处理
│ └── 操作: `x, _ = self.layer(x)`
│ ├── 作用: 使用 LSTM 层处理序列数据,捕捉上下文信息
│ └── 输出: `x` 张量,形状为 `(batch_size, sen_len, hidden_size * 2)`(双向 LSTM)
│
├── 4. 分类层处理
│ └── 操作: `predict = self.classify(x)`
│ ├── 作用: 将 LSTM 的输出映射到类别数量
│ └── 输出: `predict` 张量,形状为 `(batch_size, sen_len, class_num)`
│
├── 5. 判断是否有真实标签
│ ├── 5.1 如果有真实标签 (`target is not None`):
│ │ ├── 5.1.1 判断是否使用 CRF:
│ │ │ ├── 5.1.1.1 如果使用 CRF (`self.use_crf`):
│ │ │ │ ├── 操作: `mask = target.gt(-1)`
│ │ │ │ │ └── 作用: 生成掩码,标记有效标签(非 -1)
│ │ │ │ └── 操作: `return self.crf_layer(predict, target, mask, reduction="mean")`
│ │ │ │ └── 作用: 使用 CRF 层计算损失
│ │ │ └── 5.1.1.2 如果不使用 CRF:
│ │ │ └── 操作: `return self.loss(predict.view(-1, predict.shape[-1]), target.view(-1))`
│ │ │ └── 作用: 使用交叉熵损失计算损失
│ │ └── 5.1.2 返回损失值
│ └── 5.2 如果没有真实标签:
│ ├── 5.2.1 判断是否使用 CRF:
│ │ ├── 5.2.1.1 如果使用 CRF (`self.use_crf`):
│ │ │ └── 操作: `return self.crf_layer.viterbi_decode(predict)`
│ │ │ └── 作用: 使用 CRF 层进行 Viterbi 解码,返回预测标签序列
│ │ └── 5.2.1.2 如果不使用 CRF:
│ │ └── 操作: `return predict`
│ │ └── 作用: 直接返回分类层的预测结果
│ └── 5.2.2 返回预测值
│
└── 6. 返回结果
├── 如果有真实标签: 返回损失值
└── 如果没有真实标签: 返回预测值x:输入数据,形状为 (batch_size, sen_len),其中 batch_size 是批次大小,sen_len 是序列长度
target:真实标签,形状与 x 相同。如果为 None,表示没有提供真实标签,仅返回预测值。
predict:模型的预测输出,形状为 (batch_size, sen_len, num_classes),其中 num_classes 是类别数。
mask: 掩码张量,用于标识有效标签的位置。target.gt(-1) 表示 target 中大于 -1 的位置为有效标签
use_crf:标记是否使用crf条件随机场
.shape:用于描述张量的维度结构,即张量在每个维度上的大小。它是一个由整数组成的元组(tuple),每个整数表示对应维度的大小。
view():改变张量的形状(类似 reshape),返回新视图(不复制数据)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| new_shape | tuple | None | 新的形状(如 (batch_size, sen_len))。支持 -1 自动推断维度。 |
| dtype | torch.dtype | None | 数据类型(如 torch.float32)。默认与原张量一致。 |
gt():逐元素比较,返回布尔张量(True 表示左操作数大于右操作数)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| other | Tensor | None | 右操作数(张量或标量)。例如 x.gt(0)。 |
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, target=None):
x = self.embedding(x) #input shape:(batch_size, sen_len)
x, _ = self.layer(x) #input shape:(batch_size, sen_len, input_dim)
predict = self.classify(x)
if target is not None:
if self.use_crf:
mask = target.gt(-1)
return self.crf_layer(predict, target, mask, reduction="mean")
else:
return self.loss(predict.view(-1, predict.shape[-1]), target.view(-1))
else:
if self.use_crf:
return self.crf_layer.viterbi_decode(predict)
else:
return predictⅢ、选择优化器
代码运行流程
choose_optimizer 函数流程
├── 1. 输入参数
│ ├── 1.1 `config`: 配置字典,包含优化器类型和学习率
│ └── 1.2 `model`: 模型对象,包含需要优化的参数
│
├── 2. 从配置中获取优化器类型
│ └── 操作: `optimizer = config["optimizer"]`
│ └── 作用: 获取配置中指定的优化器类型(如 "adam" 或 "sgd")
│
├── 3. 从配置中获取学习率
│ └── 操作: `learning_rate = config["learning_rate"]`
│ └── 作用: 获取配置中指定的学习率
│
├── 4. 判断优化器类型
│ ├── 4.1 如果优化器是 "adam":
│ │ └── 操作: `return Adam(model.parameters(), lr=learning_rate)`
│ │ ├── 作用: 使用 Adam 优化器初始化并返回
│ │ └── 输出: Adam 优化器对象
│ └── 4.2 如果优化器是 "sgd":
│ └── 操作: `return SGD(model.parameters(), lr=learning_rate)`
│ ├── 作用: 使用 SGD 优化器初始化并返回
│ └── 输出: SGD 优化器对象
│
└── 5. 返回优化器对象
└── 作用: 返回根据配置选择的优化器对象config:配置字典,包含优化器的名称和学习率等超参数
model:待训练的模型,其参数将由优化器更新
optimizer:优化器的名称,例如 "adam" 或 "sgd",用于选择具体的优化算法
learning_rate:学习率,控制每次参数更新的步长大小
lr: 优化器的学习率参数,控制参数更新的步长
Adam():自适应矩估计优化器(Adaptive Moment Estimation),结合动量和 RMSProp 的优点。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| lr | float | 1e-3 | 学习率。 |
| betas | tuple | (0.9, 0.999) | 动量系数(β₁, β₂)。 |
| eps | float | 1e-8 | 防止除零误差。 |
| weight_decay | float | 0 | 权重衰减率。 |
| amsgrad | bool | False | 是否启用 AMSGrad 优化。 |
| foreach | bool | False | 是否为每个参数单独计算梯度。 |
SGD():随机梯度下降优化器(Stochastic Gradient Descent)
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| lr | float | 1e-3 | 学习率。 |
| momentum | float | 0 | 动量系数(如 momentum=0.9)。 |
| weight_decay | float | 0 | 权重衰减率。 |
| dampening | float | 0 | 动力衰减系数(用于 SGD with Momentum)。 |
| nesterov | bool | False | 是否启用 Nesterov 动量。 |
| foreach | bool | False | 是否为每个参数单独计算梯度。 |
parameters():返回模型所有可训练参数的迭代器,常用于参数初始化或梯度清零。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| filter | callable | None | 过滤条件函数(如 lambda p: p.requires_grad)。默认返回所有参数。 |
def choose_optimizer(config, model):
optimizer = config["optimizer"]
learning_rate = config["learning_rate"]
if optimizer == "adam":
return Adam(model.parameters(), lr=learning_rate)
elif optimizer == "sgd":
return SGD(model.parameters(), lr=learning_rate)Ⅳ、建立网络模型结构 & 完整代码
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
from torch.optim import Adam, SGD
from torchcrf import CRF
"""
建立网络模型结构
"""
class TorchModel(nn.Module):
def __init__(self, config):
super(TorchModel, self).__init__()
hidden_size = config["hidden_size"]
vocab_size = config["vocab_size"] + 1
class_num = config["class_num"]
self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)
self.layer = nn.LSTM(hidden_size, hidden_size, batch_first=True, bidirectional=True, num_layers=1)
self.classify = nn.Linear(hidden_size * 2, class_num)
self.crf_layer = CRF(class_num, batch_first=True)
self.use_crf = config["use_crf"]
self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) #loss采用交叉熵损失
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, target=None):
x = self.embedding(x) #input shape:(batch_size, sen_len)
x, _ = self.layer(x) #input shape:(batch_size, sen_len, input_dim)
predict = self.classify(x)
if target is not None:
if self.use_crf:
mask = target.gt(-1)
return self.crf_layer(predict, target, mask, reduction="mean")
else:
return self.loss(predict.view(-1, predict.shape[-1]), target.view(-1))
else:
if self.use_crf:
return self.crf_layer.viterbi_decode(predict)
else:
return predict
def choose_optimizer(config, model):
optimizer = config["optimizer"]
learning_rate = config["learning_rate"]
if optimizer == "adam":
return Adam(model.parameters(), lr=learning_rate)
elif optimizer == "sgd":
return SGD(model.parameters(), lr=learning_rate)
if __name__ == "__main__":
from config import Config
model = TorchModel(Config)3.数据加载 loader.py
代码运行流程
DataGenerator.__init__(self, data_path, config)
├── 初始化 self.config = config
├── 初始化 self.path = data_path
├── 加载词汇表:self.vocab = load_vocab(config["vocab_path"])
├── 更新配置:self.config["vocab_size"] = len(self.vocab)
├── 初始化 self.sentences = []
├── 加载 schema:self.schema = self.load_schema(config["schema_path"])
├── 更新配置:self.config["class_num"] = len(self.schema)
├── 初始化 self.max_length = config["max_length"]
└── 调用 self.load() 方法
DataGenerator.load(self)
├── 初始化 self.data = []
├── 打开文件:with open(self.path, encoding="utf8") as f
│ ├── 逐行读取文件:for line in f
│ │ ├── 判断行长度是否超过最大长度:if len(line) > self.max_length
│ │ │ ├── 分段处理行:for i in range(len(line) // self.max_length)
│ │ │ │ ├── 处理句子:input_id, label = self.process_sentence(line[i * self.max_length:(i+1) * self.max_length])
│ │ │ │ └── 将结果存入 self.data:self.data.append([torch.LongTensor(input_id), torch.LongTensor(label)])
│ │ │ └── 处理剩余部分:input_id, label = self.process_sentence(line)
│ │ │ └── 将结果存入 self.data:self.data.append([torch.LongTensor(input_id), torch.LongTensor(label)])
│ │ └── 处理整行:input_id, label = self.process_sentence(line)
│ │ └── 将结果存入 self.data:self.data.append([torch.LongTensor(input_id), torch.LongTensor(label)])
└── 返回
DataGenerator.process_sentence(self, line)
├── 初始化 sentence_without_sign = []
├── 初始化 label = []
├── 遍历句子中的每个字符:for index, char in enumerate(line[:-1])
│ ├── 跳过标点字符:if char in self.schema
│ │ └── continue
│ ├── 将字符加入 sentence_without_sign:sentence_without_sign.append(char)
│ ├── 获取下一个字符:next_char = line[index + 1]
│ ├── 判断下一个字符是否为标点:if next_char in self.schema
│ │ └── 将标点对应的标签加入 label:label.append(self.schema[next_char])
│ └── 否则加入默认标签:label.append(0)
├── 断言 sentence_without_sign 和 label 长度一致:assert len(sentence_without_sign) == len(label)
├── 编码句子:encode_sentence = self.encode_sentence(sentence_without_sign)
├── 补齐标签:label = self.padding(label, -1)
├── 断言 encode_sentence 和 label 长度一致:assert len(encode_sentence) == len(label)
├── 将句子加入 self.sentences:self.sentences.append("".join(sentence_without_sign))
└── 返回 encode_sentence, label
DataGenerator.encode_sentence(self, text, padding=True)
├── 初始化 input_id = []
├── 判断词汇表类型:if self.config["vocab_path"] == "words.txt"
│ └── 使用 jieba 分词并编码:for word in jieba.cut(text)
│ └── input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))
├── 否则按字符编码:for char in text
│ └── input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
├── 判断是否需要补齐:if padding
│ └── 补齐 input_id:input_id = self.padding(input_id)
└── 返回 input_id
DataGenerator.padding(self, input_id, pad_token=0)
├── 截断 input_id:input_id = input_id[:self.config["max_length"]]
├── 补齐 input_id:input_id += [pad_token] * (self.config["max_length"] - len(input_id))
└── 返回 input_id
DataGenerator.__len__(self)
└── 返回 self.data 的长度:return len(self.data)
DataGenerator.__getitem__(self, index)
└── 返回 self.data 中的指定项:return self.data[index]
DataGenerator.load_schema(self, path)
├── 打开文件:with open(path, encoding="utf8") as f
└── 返回 JSON 数据:return json.load(f)
load_vocab(vocab_path)
├── 初始化 token_dict = {}
├── 打开文件:with open(vocab_path, encoding="utf8") as f
│ ├── 逐行读取文件:for index, line in enumerate(f)
│ │ ├── 去除空白字符:token = line.strip()
│ │ └── 将 token 和索引存入 token_dict:token_dict[token] = index + 1
└── 返回 token_dict
load_data(data_path, config, shuffle=True)
├── 初始化 DataGenerator:dg = DataGenerator(data_path, config)
├── 初始化 DataLoader:dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
└── 返回 DataLoader:return dl
if __name__ == "__main__":
├── 导入 Config:from config import Config
└── 初始化 DataGenerator:dg = DataGenerator("/NLP/Day9_序列标注问题/demo1_ner/ner_data/train", Config)
Ⅰ、类初始化与配置加载
代码运行流程
__init__ 方法流程
├── 1. 输入参数
│ ├── 1.1 `data_path`: 原始数据文件路径
│ └── 1.2 `config`: 全局配置参数(如模型超参、路径信息等)
│
├── 2. 初始化实例变量
│ ├── 2.1 `self.config = config`
│ │ └── 作用: 将传入的配置字典赋值给实例变量 `self.config`
│ ├── 2.2 `self.path = data_path`
│ │ └── 作用: 将传入的数据路径赋值给实例变量 `self.path`
│ ├── 2.3 `self.vocab = load_vocab(config["vocab_path"])`
│ │ └── 作用: 加载词汇表,并将结果赋值给实例变量 `self.vocab`
│ ├── 2.4 `self.config["vocab_size"] = len(self.vocab)`
│ │ └── 作用: 计算词汇表大小,并更新 `self.config` 中的 `vocab_size`
│ ├── 2.5 `self.sentences = []`
│ │ └── 作用: 初始化一个空列表,用于存储处理后的句子
│ ├── 2.6 `self.schema = self.load_schema(config["schema_path"])`
│ │ └── 作用: 加载模式(schema),并将结果赋值给实例变量 `self.schema`
│ ├── 2.7 `self.config["class_num"] = len(self.schema)`
│ │ └── 作用: 计算模式中的类别数量,并更新 `self.config` 中的 `class_num`
│ └── 2.8 `self.max_length = config["max_length"]`
│ └── 作用: 将配置中的最大长度赋值给实例变量 `self.max_length`
│
├── 3. 调用 `load` 方法
│ └── 操作: `self.load()`
│ └── 作用: 调用 `load` 方法加载数据
│
└── 4. 初始化完成
└── 作用: 类实例化完成,实例变量已初始化并准备好使用config:存储全局配置参数(如模型超参、路径信息等)
data_path:记录原始数据文件路径,用于后续数据读取
vocab_size:词汇表大小,决定模型嵌入层的输入维度
# -*- coding: utf-8 -*-
import json
import re
import os
import torch
import random
import jieba
import numpy as np
from torch.utils.data import Dataset, DataLoader
"""
数据加载
"""
class DataGenerator:
def __init__(self, data_path, config):
self.config = config
self.path = data_path
self.vocab = load_vocab(config["vocab_path"])
self.config["vocab_size"] = len(self.vocab)
self.sentences = []
self.schema = self.load_schema(config["schema_path"])
self.config["class_num"] = len(self.schema)
self.max_length = config["max_length"]
self.load()Ⅱ、加载字表 / 词表
代码运行流程
load_vocab 函数流程
├── 1. 初始化空字典
│ └── 操作: `token_dict = {}`
│ └── 作用: 创建一个空字典,用于存储词汇及其对应的索引
│
├── 2. 打开词汇表文件
│ └── 操作: `with open(vocab_path, encoding="utf8") as f:`
│ └── 作用: 以 UTF-8 编码打开词汇表文件,确保文件读取后自动关闭
│
├── 3. 逐行读取文件
│ └── 操作: `for index, line in enumerate(f):`
│ └── 作用: 遍历文件的每一行,`index` 为行号(从 0 开始),`line` 为当前行的内容
│
├── 4. 处理每一行
│ ├── 4.1 去除行首尾空白字符
│ │ └── 操作: `token = line.strip()`
│ │ └── 作用: 去除行首尾的空白字符(如换行符、空格等),得到词汇
│ │
│ └── 4.2 将词汇及其索引存入字典
│ └── 操作: `token_dict[token] = index + 1`
│ ├── 作用: 将词汇及其对应的索引存入字典,索引从 1 开始(0 留给 padding 位置)
│ └── 输出: 更新后的 `token_dict` 字典
│
└── 5. 返回词汇字典
└── 操作: `return token_dict`
└── 作用: 返回包含词汇及其索引的字典vocab_path:词汇表文件的路径
token_dict:存储词汇项到索引的映射关系的字典
f:文件对象,打开的词汇表文件句柄(通过with语句自动管理资源)
index:索引,行号计数器
line:当前读取的文件行内容
token:去除首尾空白后的词汇项文本
open():Python 内置函数,用于打开文件并返回文件对象,支持文本模式和二进制模式操作
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
filename | str | 文件路径(含绝对/相对路径) | - |
mode | str | 文件打开模式(如 'r'、'w'、'a'、'b' 等) | 'r' |
encoding | str | 文件编码格式(文本模式必需,二进制模式忽略) | None |
errors | str | 编码错误处理方式(如 'ignore'、'replace') | None |
newline | str | 控制换行符转换行为(如 None、'\n') | None |
closefd | bool | 是否在关闭文件对象时关闭文件描述符 | True |
enumerate():将可迭代对象与索引组合,返回包含索引和元素的枚举对象,常用于循环中同时获取元素及其位置
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
iterable | 可迭代对象 | 要遍历的列表、元组、字符串等 | - |
start | int | 索引起始值(默认从 0 开始) | 0 |
strip():字符串方法,用于去除字符串首尾指定字符(默认为空白字符如空格、换行符)
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
chars | str | 需要去除的字符集合(如 '#'),若省略则默认去除空白字符 | None |
#加载字表或词表
def load_vocab(vocab_path):
token_dict = {}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
token = line.strip()
token_dict[token] = index + 1 #0留给padding位置,所以从1开始
return token_dictⅢ、输入文本预处理
① 补齐或截断
代码运行流程
padding 方法流程
├── 1. 输入参数
│ ├── 1.1 `input_id`: 输入的序列,通常是一个列表或张量
│ └── 1.2 `pad_token`: 用于填充的标记,默认为 0
│
├── 2. 截断序列
│ └── 操作: `input_id = input_id[:self.config["max_length"]]`
│ ├── 作用: 将输入序列截断为配置中指定的最大长度 `max_length`
│ └── 输出: 截断后的序列
│
├── 3. 计算填充长度
│ └── 操作: `self.config["max_length"] - len(input_id)`
│ ├── 作用: 计算需要填充的长度
│ └── 输出: 填充长度(整数)
│
├── 4. 填充序列
│ └── 操作: `input_id += [pad_token] * (self.config["max_length"] - len(input_id))`
│ ├── 作用: 在序列末尾添加 `pad_token`,直到序列长度达到 `max_length`
│ └── 输出: 填充后的序列
│
└── 5. 返回结果
└── 操作: `return input_id`
└── 作用: 返回补齐或截断后的序列input_id:输入的原始token ID
pad_token:填充时使用的token ID(默认0,通常对应词汇表中的<PAD>标记)
self.config:字典,模型配置参数
self.config["max_length"]:序列允许的最大长度,用于控制一个batch内的序列统一性
len(): Python 内置函数,用于返回对象(如字符串、列表、元组、字典等)的长度或元素个数,是处理序列类型的核心工具
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
object | object | 需要计算长度的对象,支持字符串、列表、元组、字典、集合等序列或集合类型 | - |
#补齐或截断输入的序列,使其可以在一个batch内运算
def padding(self, input_id, pad_token=0):
input_id = input_id[:self.config["max_length"]]
input_id += [pad_token] * (self.config["max_length"] - len(input_id))
return input_id② 文本转编码
代码运行流程
encode_sentence 方法流程
├── 1. 输入参数
│ ├── 1.1 `text`: 输入的文本字符串
│ └── 1.2 `padding`: 是否对输入序列进行填充,默认为 True
│
├── 2. 初始化空列表
│ └── 操作: `input_id = []`
│ └── 作用: 创建一个空列表,用于存储编码后的序列
│
├── 3. 判断词汇表类型
│ ├── 3.1 如果词汇表路径为 "words.txt":
│ │ ├── 操作: `for word in jieba.cut(text):`
│ │ │ └── 作用: 使用 jieba 分词对文本进行分词
│ │ ├── 操作: `input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))`
│ │ │ └── 作用: 将每个分词映射为词汇表中的索引,若未找到则使用 "[UNK]" 的索引
│ │ └── 输出: 分词后的编码序列
│ └── 3.2 否则:
│ ├── 操作: `for char in text:`
│ │ └── 作用: 对文本逐字符处理
│ ├── 操作: `input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))`
│ │ └── 作用: 将每个字符映射为词汇表中的索引,若未找到则使用 "[UNK]" 的索引
│ └── 输出: 字符级的编码序列
│
├── 4. 判断是否填充
│ └── 操作: `if padding:`
│ ├── 作用: 如果 `padding` 为 True,则对编码序列进行填充
│ ├── 操作: `input_id = self.padding(input_id)`
│ │ └── 作用: 调用 `padding` 方法对序列进行补齐或截断
│ └── 输出: 填充后的编码序列
│
└── 5. 返回结果
└── 操作: `return input_id`
└── 作用: 返回编码后的序列(可能经过填充)text:输入的文本,需要被编码为模型可处理的格式
padding: 是否对输入进行填充(padding),默认为 True。填充通常用于使输入长度一致。
input_id:存储编码后的token ID序列
self.config:字典,模型配置参数
jieba.cut():结巴分词库的核心分词函数,支持三种分词模式(精确模式/全模式/搜索引擎模式),用于将中文文本切分成词语序列
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
sentence | str | 需要分词的中文字符串 | - |
cut_all | bool | 是否采用全模式分词(True为全模式,False为精确模式,默认False) | False |
HMM | bool | 是否启用隐马尔可夫模型处理未登录词(True启用,默认True) | True |
列表.append():用于在列表末尾添加一个元素,属于原地修改操作,无返回值
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
obj | object | 需要添加到列表末尾的元素(支持任意类型,包括列表/元组/字符串等) | - |
字典.get():安全获取字典中指定键的值,键不存在时返回默认值(默认为None),避免KeyError异常
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
key | hashable | 需要查询的键 | - |
default | optional | 键不存在时返回的默认值(可选参数,不提供则返回None) | None |
def encode_sentence(self, text, padding=True):
input_id = []
if self.config["vocab_path"] == "words.txt":
for word in jieba.cut(text):
input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))
else:
for char in text:
input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
if padding:
input_id = self.padding(input_id)
return input_idⅣ、类内魔术方法
① len()方法重写
实现对象长度获取功能,当调用内置函数 len(obj) 时自动触发
def __len__(self):
return len(self.data)② getitem()方法重写
支持通过索引访问对象元素,使对象可被切片或逐项遍历
def __getitem__(self, index):
return self.data[index]③ load_schema()方法
从指定路径加载 JSON 文件并返回解析后的数据
open(): Python 内置函数,用于打开文件并返回文件对象,支持文本模式('r'、'w'、'a' 等)和二进制模式('rb'、'wb' 等)
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
file | str | 文件路径(支持相对/绝对路径) | - |
mode | str | 打开模式(如 'r' 只读、'w' 覆盖写入、'a' 追加) | 'r' |
encoding | str | 文件编码(如 'utf-8'),文本模式时必填 | None |
buffering | int | 缓冲策略(0 无缓冲、1 行缓冲、>1 缓冲区大小) | None |
json.load():用于将 JSON 格式的文件内容解析为 Python 对象(如字典、列表)
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
fp | 文件对象 | 支持 read() 方法的文件对象(如通过 open() 返回的文件对象) | - |
cls | type | 自定义解码类(可选) | None |
object_hook | function | 自定义转换函数(可选) |
def load_schema(self, path):
with open(path, encoding="utf8") as f:
return json.load(f)Ⅴ、预处理与标签生成
代码运行流程
process_sentence 方法流程
├── 1. 输入参数
│ └── 1.1 `line`: 输入的文本行
│
├── 2. 初始化空列表
│ ├── 2.1 `sentence_without_sign = []`
│ │ └── 作用: 用于存储去除标点后的字符序列
│ └── 2.2 `label = []`
│ └── 作用: 用于存储每个字符对应的标签
│
├── 3. 遍历字符序列
│ └── 操作: `for index, char in enumerate(line[:-1]):`
│ ├── 3.1 检查当前字符是否为标点
│ │ └── 操作: `if char in self.schema:`
│ │ └── 作用: 如果当前字符是标点,则跳过处理
│ ├── 3.2 将非标点字符加入 `sentence_without_sign`
│ │ └── 操作: `sentence_without_sign.append(char)`
│ ├── 3.3 检查下一个字符是否为标点
│ │ ├── 操作: `next_char = line[index + 1]`
│ │ └── 操作: `if next_char in self.schema:`
│ │ ├── 作用: 如果下一个字符是标点,则将其对应的标签加入 `label`
│ │ └── 操作: `label.append(self.schema[next_char])`
│ │ └── 否则:
│ │ └── 操作: `label.append(0)`
│ │ └── 作用: 如果下一个字符不是标点,则标签为 0
│ └── 输出: 更新后的 `sentence_without_sign` 和 `label`
│
├── 4. 检查长度一致性
│ └── 操作: `assert len(sentence_without_sign) == len(label)`
│ └── 作用: 确保 `sentence_without_sign` 和 `label` 长度一致
│
├── 5. 编码字符序列
│ └── 操作: `encode_sentence = self.encode_sentence(sentence_without_sign)`
│ └── 作用: 调用 `encode_sentence` 方法将字符序列编码为数值序列
│
├── 6. 填充标签序列
│ └── 操作: `label = self.padding(label, -1)`
│ └── 作用: 调用 `padding` 方法对标签序列进行填充,填充值为 -1
│
├── 7. 检查长度一致性
│ └── 操作: `assert len(encode_sentence) == len(label)`
│ └── 作用: 确保编码后的序列和标签序列长度一致
│
├── 8. 存储处理后的句子
│ └── 操作: `self.sentences.append("".join(sentence_without_sign))`
│ └── 作用: 将去除标点后的句子加入 `self.sentences` 列表
│
└── 9. 返回结果
└── 操作: `return encode_sentence, label`
└── 作用: 返回编码后的序列和标签序列sentence_without_sign:字符串列表,存储过滤后不含标点的纯文本字符序列
self.schema:字典,存储文本到索引的映射关系
self.sentences:字符串列表,存储所有处理后的句子
encode_sentence:文本编码后的数值序列
lable:整数列表,存储每个字符对应的标签(预测下一个字符是否是标点)
line:输入的原始文本字符串
index:当前字符在文本中的位置索引
char:当前处理的字符
enumerate():将可迭代对象(如列表、字符串)转换为索引-值元组序列,常用于for循环中同时获取元素及其位置
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
iterable | 可迭代对象 | 需要枚举的列表、字符串等对象 | - |
start | int | 索引起始值,默认为0 | 0 |
列表.append():在列表末尾添加一个元素,属于原地修改操作,无返回值
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
obj | object | 需要添加到列表末尾的元素(支持任意类型,包括列表/元组/字符串等) | - |
assert:在调试阶段检查条件是否为真,若为假则抛出AssertionError异常并终止程序
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
expression | bool | 需判断的表达式,若为False则触发异常 | - |
message | str | 可选参数,自定义错误提示信息 | None |
join():将可迭代对象(如列表、元组)中的元素按指定分隔符合并为字符
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
iterable | 可迭代对象 | 需连接的元素序列(元素需为字符串类型) | - |
sep | str | 分隔符字符串,默认为空字符串"" | "" |
def process_sentence(self, line):
sentence_without_sign = []
label = []
for index, char in enumerate(line[:-1]):
if char in self.schema: #准备加的标点,在训练数据中不应该存在
continue
sentence_without_sign.append(char)
next_char = line[index + 1]
if next_char in self.schema: #下一个字符是标点,计入对应label
label.append(self.schema[next_char])
else:
label.append(0)
assert len(sentence_without_sign) == len(label)
encode_sentence = self.encode_sentence(sentence_without_sign)
label = self.padding(label, -1)
assert len(encode_sentence) == len(label)
self.sentences.append("".join(sentence_without_sign))
return encode_sentence, labelⅥ、数据加载和封装
① 数据加载
代码运行流程
load 方法流程
├── 1. 初始化空列表
│ └── 操作: `self.data = []`
│ └── 作用: 创建一个空列表,用于存储处理后的数据
│
├── 2. 打开文件
│ └── 操作: `with open(self.path, encoding="utf8") as f:`
│ └── 作用: 以 UTF-8 编码打开文件,确保文件读取后自动关闭
│
├── 3. 逐行读取文件
│ └── 操作: `for line in f:`
│ └── 作用: 遍历文件的每一行
│
├── 4. 判断行长度
│ ├── 4.1 如果行长度超过 `max_length`:
│ │ ├── 操作: `for i in range(len(line) // self.max_length):`
│ │ │ └── 作用: 将行分割为多个子序列,每个子序列长度为 `max_length`
│ │ ├── 操作: `input_id, label = self.process_sentence(line[i * self.max_length:(i+1) * self.max_length])`
│ │ │ └── 作用: 对每个子序列调用 `process_sentence` 方法进行处理
│ │ └── 操作: `self.data.append([torch.LongTensor(input_id), torch.LongTensor(label)])`
│ │ └── 作用: 将处理后的子序列及其标签转换为 `LongTensor` 并加入 `self.data`
│ └── 4.2 否则:
│ ├── 操作: `input_id, label = self.process_sentence(line)`
│ │ └── 作用: 对整行调用 `process_sentence` 方法进行处理
│ └── 操作: `self.data.append([torch.LongTensor(input_id), torch.LongTensor(label)])`
│ └── 作用: 将处理后的整行及其标签转换为 `LongTensor` 并加入 `self.data`
│
└── 5. 返回结果
└── 操作: `return`
└── 作用: 方法执行完毕,返回 `None`self.data:用于存储最终处理结果,每个元素包含两个张量:输入ID序列和标签序列
self.max_length:单条数据允许的最大长度
self.path:文件路径,表示需要加载的数据文件
f:文件对象,用于读取文件内容
line:当前处理的每一行文本
input_id:经过编码转换的字符ID序列
lable:标签序列(如预测下一个字符是否是标点)
open():用于打开文件并返回文件对象,支持文本模式和二进制模式操作
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
file | str | 文件路径(支持相对/绝对路径) | - |
mode | str | 打开模式(如 'r' 只读、'w' 覆盖写入、'a' 追加) | 'r' |
encoding | str | 文件编码(如 'utf-8'),文本模式时必填 | None |
buffering | int | 缓冲策略(0 无缓冲、1 行缓冲、>1 缓冲区大小) | None |
errors | str | 编码错误处理方式(如 'strict'、'ignore') | 'strict' |
newline | str | 控制换行符解析(仅文本模式有效) | None |
列表.append():在列表末尾添加一个元素,属于原地修改操作,无返回值
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
obj | object | 需要添加到列表末尾的元素(支持任意类型,包括列表/元组/字符串等) | - |
torch.LongTensor():将输入数据转换为 PyTorch 的 64 位整数张量类型(torch.int64)
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
data | Iterable | 输入数据(支持列表、元组、NumPy 数组等) |
def load(self):
self.data = []
with open(self.path, encoding="utf8") as f:
for line in f:
if len(line) > self.max_length:
for i in range(len(line) // self.max_length):
input_id, label = self.process_sentence(line[i * self.max_length:(i+1) * self.max_length])
self.data.append([torch.LongTensor(input_id), torch.LongTensor(label)])
else:
input_id, label = self.process_sentence(line)
self.data.append([torch.LongTensor(input_id), torch.LongTensor(label)])
return② 数据封装
代码运行流程
load_data 方法流程
├── 1. 输入参数
│ ├── 1.1 `data_path`: 数据文件的路径
│ ├── 1.2 `config`: 配置字典,包含 `batch_size` 等参数
│ └── 1.3 `shuffle`: 是否打乱数据,默认为 True
│
├── 2. 创建 DataGenerator 实例
│ └── 操作: `dg = DataGenerator(data_path, config)`
│ └── 作用: 使用 `data_path` 和 `config` 初始化 `DataGenerator` 对象
│
├── 3. 创建 DataLoader 实例
│ └── 操作: `dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)`
│ ├── 3.1 设置 `batch_size`: 从 `config` 中获取 `batch_size` 参数
│ ├── 3.2 设置 `shuffle`: 根据输入参数决定是否打乱数据
│ └── 作用: 使用 `DataGenerator` 对象和配置参数创建 `DataLoader` 对象
│
└── 4. 返回 DataLoader 实例
└── 操作: `return dl`
└── 作用: 返回封装好的 `DataLoader` 对象,用于后续数据加载和迭代dg:DataGenerator 类的实例,用于生成数据
dl: DataLoader 类的实例,用于从 DataGenerator 中按批次加载数据。它封装了数据的批量加载、打乱顺序等功能。
data_path:数据文件路径,用于初始化DataGenerator
config:配置参数字典
batch_size:传递给 DataLoader 的参数,表示每个批次的大小
shuffle:是否在每个epoch开始时打乱数据顺序
DataLoader():PyTorch 中用于高效加载、处理和批量管理数据集的核心工具
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
dataset | Dataset | 需要加载的数据集对象(需实现 __len__ 和 __getitem__ 方法) | - |
batch_size | int | 每个批次包含的样本数量 | 1 |
shuffle | bool | 是否在每个 epoch 开始时打乱数据顺序 | False |
sampler | Sampler | 自定义数据采样策略(如随机采样、顺序采样),与 shuffle 互斥 | None |
num_workers | int | 使用的子进程数(0 表示主进程加载) | 0 |
collate_fn | callable | 自定义批次合并逻辑(如填充、截断),默认使用 default_collate | None |
pin_memory | bool | 是否将数据存储到固定内存区(加速 GPU 传输) | False |
drop_last | bool | 是否丢弃最后一个不足 batch_size 的批次 | False |
timeout | float | 子进程加载数据超时时间(秒),超时则抛出异常 | 0 |
worker_init_fn | callable | 每个子进程初始化函数(用于设置随机种子等) | None |
prefetch_factor | int | 每个 worker 预取的批次数量(PyTorch 1.7+ 新增) | 2 |
persistent_workers | bool | 是否复用 worker 进程(减少启动开销,PyTorch 1.7+ 新增) | False |
#用torch自带的DataLoader类封装数据
def load_data(data_path, config, shuffle=True):
dg = DataGenerator(data_path, config)
dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
return dl
Ⅶ、完整代码
# -*- coding: utf-8 -*-
import json
import re
import os
import torch
import random
import jieba
import numpy as np
from torch.utils.data import Dataset, DataLoader
"""
数据加载
"""
class DataGenerator:
def __init__(self, data_path, config):
self.config = config
self.path = data_path
self.vocab = load_vocab(config["vocab_path"])
self.config["vocab_size"] = len(self.vocab)
self.sentences = []
self.schema = self.load_schema(config["schema_path"])
self.config["class_num"] = len(self.schema)
self.max_length = config["max_length"]
self.load()
def load(self):
self.data = []
with open(self.path, encoding="utf8") as f:
for line in f:
if len(line) > self.max_length:
for i in range(len(line) // self.max_length):
input_id, label = self.process_sentence(line[i * self.max_length:(i+1) * self.max_length])
self.data.append([torch.LongTensor(input_id), torch.LongTensor(label)])
else:
input_id, label = self.process_sentence(line)
self.data.append([torch.LongTensor(input_id), torch.LongTensor(label)])
return
def process_sentence(self, line):
sentence_without_sign = []
label = []
for index, char in enumerate(line[:-1]):
if char in self.schema: #准备加的标点,在训练数据中不应该存在
continue
sentence_without_sign.append(char)
next_char = line[index + 1]
if next_char in self.schema: #下一个字符是标点,计入对应label
label.append(self.schema[next_char])
else:
label.append(0)
assert len(sentence_without_sign) == len(label)
encode_sentence = self.encode_sentence(sentence_without_sign)
label = self.padding(label, -1)
assert len(encode_sentence) == len(label)
self.sentences.append("".join(sentence_without_sign))
return encode_sentence, label
def encode_sentence(self, text, padding=True):
input_id = []
if self.config["vocab_path"] == "words.txt":
for word in jieba.cut(text):
input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))
else:
for char in text:
input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
if padding:
input_id = self.padding(input_id)
return input_id
#补齐或截断输入的序列,使其可以在一个batch内运算
def padding(self, input_id, pad_token=0):
input_id = input_id[:self.config["max_length"]]
input_id += [pad_token] * (self.config["max_length"] - len(input_id))
return input_id
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
def load_schema(self, path):
with open(path, encoding="utf8") as f:
return json.load(f)
#加载字表或词表
def load_vocab(vocab_path):
token_dict = {}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
token = line.strip()
token_dict[token] = index + 1 #0留给padding位置,所以从1开始
return token_dict
#用torch自带的DataLoader类封装数据
def load_data(data_path, config, shuffle=True):
dg = DataGenerator(data_path, config)
dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
return dl
if __name__ == "__main__":
from config import Config
dg = DataGenerator("/NLP/Day9_序列标注问题/demo1_ner/ner_data/train", Config)
4.模型效果评估 evaluate.py
Ⅰ、评估类初始化
代码运行流程
__init__ 方法流程
├── 1. 输入参数
│ ├── 1.1 `config`: 全局配置参数
│ ├── 1.2 `model`: 模型对象
│ └── 1.3 `logger`: 日志记录器对象
│
├── 2. 初始化实例变量
│ ├── 2.1 `self.config = config`
│ │ └── 作用: 将传入的配置字典赋值给实例变量 `self.config`
│ ├── 2.2 `self.model = model`
│ │ └── 作用: 将传入的模型对象赋值给实例变量 `self.model`
│ ├── 2.3 `self.logger = logger`
│ │ └── 作用: 将传入的日志记录器对象赋值给实例变量 `self.logger`
│ ├── 2.4 `self.valid_data = load_data(config["valid_data_path"], config, shuffle=False)`
│ │ └── 作用: 调用 `load_data` 方法加载验证数据,并将结果赋值给实例变量 `self.valid_data`
│ ├── 2.5 `self.schema = self.valid_data.dataset.schema`
│ │ └── 作用: 从验证数据集中提取模式(schema),并赋值给实例变量 `self.schema`
│ └── 2.6 `self.index_to_label = dict((y, x) for x, y in self.schema.items())`
│ └── 作用: 将模式中的键值对反转,生成 `index_to_label` 字典,并赋值给实例变量 `self.index_to_label`
│
└── 3. 初始化完成
└── 作用: 类实例化完成,实例变量已初始化并准备好使用x:表示标签(如 "cat" 或 "dog")
y: 表示标签对应的索引(如 0 或 1)
config:包含数据路径、批处理大小等配置参数的字典
model:需要训练或验证的模型实例
logger:用于记录训练 / 验证过程的日志工具
valid_data:加载的验证数据集,支持批量迭代
schema:数据集的标签映射表,键为标签名称,值为对应索引
index_to_lable:索引到标签的反向映射表,用于将模型输出索引转换为实际标签
dict():Python 中用于创建字典的内置函数
| 参数形式 | 类型 | 作用描述 | 示例 |
|---|---|---|---|
| 关键字参数 | key=value | 通过键值对创建字典 | dict(a=1, b=2) |
| 映射对象 | Mapping | 从映射对象(如另一个字典)复制键值对 | dict({"a":1, "b":2}) |
| 可迭代对象 | Iterable | 从可迭代对象(如元组列表)创建键值对,元素需为键值对元组 | dict([("a",1), ("b",2)]) |
item():返回键值对视图对象,支持迭代
| 对象类型 | 作用描述 | 示例代码 |
|---|---|---|
| 字典 | 无 item() 方法,需通过 [] 或 get() 访问值 | value = my_dict["key"] |
| 集合类对象 | 返回集合中的当前项(如 NodeList、HTMLCollection) | element = paragraphs.item(0) |
| VBA 字典 | 通过键获取或修改值 | item = dict.Item("key") |
字典推导式:字典推导式是一种简洁创建字典的方式,语法如下:
{key_expr:value_expr for item in iterable if condition}
| 参数名称 | 类型 | 作用描述 | 示例代码 |
|---|---|---|---|
key_expression | 表达式 | 用于生成字典的键 | {x: x**2 for x in range(6)} |
value_expression | 表达式 | 用于生成字典的值 | {x: x**2 if x%2==0 else x*3 for x in range(6)} |
iterable | 可迭代对象 | 提供数据源(如列表、元组、集合) | {k: v for k,v in zip(keys, values)} |
condition | 布尔表达式 | 可选过滤条件,仅当条件为 True 时保留元素 | {x: x**2 for x in range(6) if x%2==0} |
def __init__(self, config, model, logger):
self.config = config
self.model = model
self.logger = logger
self.valid_data = load_data(config["valid_data_path"], config, shuffle=False)
self.schema = self.valid_data.dataset.schema
self.index_to_label = dict((y, x) for x, y in self.schema.items())Ⅱ、统计模型效果并展示
① 计算统计预测效果
代码运行流程
write_stats 方法流程
├── 1. 输入参数
│ ├── 1.1 `labels`: 真实标签序列
│ ├── 1.2 `pred_results`: 预测结果序列
│ └── 1.3 `sentences`: 原始句子序列
│
├── 2. 检查输入长度一致性
│ └── 操作: `assert len(labels) == len(pred_results) == len(sentences)`
│ └── 作用: 确保 `labels`、`pred_results` 和 `sentences` 的长度一致
│
├── 3. 判断是否使用 CRF
│ ├── 3.1 如果不使用 CRF:
│ │ └── 操作: `pred_results = torch.argmax(pred_results, dim=-1)`
│ │ └── 作用: 对预测结果取 argmax,生成预测标签序列
│ └── 3.2 如果使用 CRF:
│ └── 操作: 跳过,直接使用预测结果序列
│
├── 4. 遍历标签、预测结果和句子
│ └── 操作: `for true_label, pred_label, sentence in zip(labels, pred_results, sentences):`
│ ├── 4.1 如果不使用 CRF:
│ │ └── 操作: `pred_label = pred_label.cpu().detach().tolist()[:len(sentence)]`
│ │ └── 作用: 将预测标签序列转换为列表,并截断为句子长度
│ ├── 4.2 处理真实标签:
│ │ └── 操作: `true_label = true_label.cpu().detach().tolist()[:len(sentence)]`
│ │ └── 作用: 将真实标签序列转换为列表,并截断为句子长度
│ ├── 4.3 遍历预测标签和真实标签:
│ │ └── 操作: `for pred, gold in zip(pred_label, true_label):`
│ │ ├── 4.3.1 获取类别名称:
│ │ │ └── 操作: `key = self.index_to_label[gold]`
│ │ │ └── 作用: 根据真实标签的索引获取类别名称
│ │ ├── 4.3.2 更新统计信息:
│ │ │ ├── 操作: `self.stats_dict[key]["correct"] += 1 if pred == gold else 0`
│ │ │ │ └── 作用: 如果预测标签与真实标签一致,则增加正确计数
│ │ │ └── 操作: `self.stats_dict[key]["total"] += 1`
│ │ │ └── 作用: 增加总计数
│ └── 输出: 更新后的 `self.stats_dict`
│
└── 5. 返回结果
└── 操作: `return`
└── 作用: 方法执行完毕,返回 `None`labels:真实标签序列,表示每个句子中每个词的真实类别。
pred_results:模型预测的结果序列,表示每个句子中每个词的预测类别。
sentences:原始句子序列,表示输入的文本数据。
sentence:当前句子,表示输入的文本数据
pred_lable:当前句子的预测标签序列
true_label:当前句子的真实标签序列
key:根据真实标签的索引获取类别名称
use_crf:是否使用crf标记
pred:当前词的预测标签
gold:当前词的真实标签
len():返回对象的长度(元素个数)
| 参数 | 类型 | 描述 |
|---|---|---|
obj | 可迭代对象(如列表、字符串、张量等) | 需要计算长度的对象 |
torch.argmax():返回张量中指定维度上最大值的索引。
| 参数 | 类型 | 描述 |
|---|---|---|
input | torch.Tensor | 输入张量 |
dim | int | 指定维度,默认为 None(返回全局最大值的索引) |
keepdim | bool | 是否保持输出张量的维度,默认为 False |
zip():将多个可迭代对象打包成一个元组序列
| 参数 | 类型 | 描述 |
|---|---|---|
*iterables | 可迭代对象(如列表、元组等) | 需要打包的可迭代对象 |
cpu():将张量从 GPU 移动到 CPU
| 参数 | 类型 | 描述 |
|---|---|---|
self | torch.Tensor | 需要移动的张量 |
detach():返回一个新的张量,从当前计算图中分离,且不会计算梯度。
| 参数 | 类型 | 描述 |
|---|---|---|
self | torch.Tensor | 需要分离的张量 |
tolist():将张量转换为 Python 列表。
| 参数 | 类型 | 描述 |
|---|---|---|
self | torch.Tensor | 需要转换的张量 |
def write_stats(self, labels, pred_results, sentences):
assert len(labels) == len(pred_results) == len(sentences), print(len(labels), len(pred_results), len(sentences))
if not self.config["use_crf"]:
pred_results = torch.argmax(pred_results, dim=-1)
for true_label, pred_label, sentence in zip(labels, pred_results, sentences):
if not self.config["use_crf"]:
pred_label = pred_label.cpu().detach().tolist()[:len(sentence)]
true_label = true_label.cpu().detach().tolist()[:len(sentence)]
for pred, gold in zip(pred_label, true_label):
key = self.index_to_label[gold]
self.stats_dict[key]["correct"] += 1 if pred == gold else 0
self.stats_dict[key]["total"] += 1
return② 展示预测效果和准确率
代码运行流程
show_stats 方法流程
├── 1. 初始化空列表
│ └── 操作: `total = []`
│ └── 作用: 创建一个空列表,用于存储每个类别的准确率
│
├── 2. 遍历模式中的每个类别
│ └── 操作: `for key in self.schema:`
│ ├── 2.1 计算当前类别的准确率
│ │ └── 操作: `acc = self.stats_dict[key]["correct"] / (1e-5 + self.stats_dict[key]["total"])`
│ │ ├── 作用: 计算当前类别的准确率,避免除零错误
│ │ └── 输出: `acc`,当前类别的准确率
│ ├── 2.2 记录准确率到日志
│ │ └── 操作: `self.logger.info("符号%s预测准确率:%f"%(key, acc))`
│ │ └── 作用: 将当前类别的准确率记录到日志中
│ └── 2.3 将准确率加入列表
│ └── 操作: `total.append(acc)`
│ └── 作用: 将当前类别的准确率加入 `total` 列表
│
├── 3. 计算平均准确率
│ └── 操作: `self.logger.info("平均acc:%f" % np.mean(total))`
│ ├── 作用: 计算所有类别的平均准确率
│ └── 输出: 将平均准确率记录到日志中
│
├── 4. 记录分隔线
│ └── 操作: `self.logger.info("--------------------")`
│ └── 作用: 在日志中记录分隔线,便于阅读
│
└── 5. 返回结果
└── 操作: `return`
└── 作用: 方法执行完毕,返回 `None`total:用于存储每个类别的准确率
acc:当前类别的准确率
self.schema:模式字典,包含所有类别及其对应的索引
self.stats_dict:统计字典,记录每个类别的预测正确次数和总次数
key:模式中的类别名称,如 "B-PER"、"I-LOC" 等
logger.info():用于记录信息级别的日志,通常用于输出程序运行状态、关键事件或其他需要跟踪的信息
| 参数 | 类型 | 描述 |
|---|---|---|
msg | str | 日志消息字符串,可以是格式化字符串 |
*args | 可变参数 | 用于格式化 msg 的参数 |
**kwargs | 关键字参数 | 可选参数,如 exc_info(是否记录异常信息) |
np.mean():计算数组元素的平均值,可以沿指定轴计算
| 参数 | 类型 | 描述 |
|---|---|---|
a | array_like | 需要计算平均值的数组 |
axis | int 或 tuple | 指定计算平均值的轴,默认为 None(计算展平数组的平均值) |
dtype | data-type | 输出平均值的数据类型,默认为 float64 |
out | ndarray | 可选,用于存储结果的输出数组 |
keepdims | bool | 是否保留缩减的轴,默认为 False |
where | array_like | 可选,指定包含在计算中的元素 |
列表.append():将元素添加到列表的末尾,修改原列表而不返回新列表
| 参数 | 类型 | 描述 |
|---|---|---|
element | 任意类型 | 要添加到列表末尾的元素 |
def show_stats(self):
total = []
for key in self.schema:
acc = self.stats_dict[key]["correct"] / (1e-5 + self.stats_dict[key]["total"])
self.logger.info("符号%s预测准确率:%f"%(key, acc))
total.append(acc)
self.logger.info("平均acc:%f" % np.mean(total))
self.logger.info("--------------------")
return
Ⅲ、模型效果测试
代码运行流程
eval 方法流程
├── 1. 记录日志,开始测试
│ └── 操作: `self.logger.info("开始测试第%d轮模型效果:" % epoch)`
│ └── 作用: 记录当前测试轮次的日志信息
│
├── 2. 初始化统计字典
│ └── 操作: `self.stats_dict = dict(zip(self.schema.keys(), [defaultdict(int) for i in range(len(self.schema))]))`
│ └── 作用: 初始化 `self.stats_dict`,用于存储每个类别的统计信息
│
├── 3. 设置模型为评估模式
│ └── 操作: `self.model.eval()`
│ └── 作用: 将模型设置为评估模式,禁用 dropout 和 batch normalization 等训练相关操作
│
├── 4. 遍历验证数据
│ └── 操作: `for index, batch_data in enumerate(self.valid_data):`
│ ├── 4.1 获取当前批次的句子
│ │ └── 操作: `sentences = self.valid_data.dataset.sentences[index * self.config["batch_size"]: (index+1) * self.config["batch_size"]]`
│ │ └── 作用: 从数据集中获取当前批次的句子
│ ├── 4.2 将数据移动到 GPU(如果可用)
│ │ └── 操作: `if torch.cuda.is_available(): batch_data = [d.cuda() for d in batch_data]`
│ │ └── 作用: 如果 GPU 可用,则将数据移动到 GPU
│ ├── 4.3 解包输入数据和标签
│ │ └── 操作: `input_id, labels = batch_data`
│ │ └── 作用: 解包当前批次的输入数据和标签
│ ├── 4.4 使用模型进行预测
│ │ └── 操作: `with torch.no_grad(): pred_results = self.model(input_id)`
│ │ └── 作用: 在禁用梯度计算的情况下,使用模型进行预测
│ └── 4.5 记录统计信息
│ └── 操作: `self.write_stats(labels, pred_results, sentences)`
│ └── 作用: 将当前批次的预测结果和真实标签记录到统计字典中
│
├── 5. 显示统计结果
│ └── 操作: `self.show_stats()`
│ └── 作用: 计算并显示当前轮次的统计结果,如准确率等
│
└── 6. 返回结果
└── 操作: `return`
└── 作用: 方法执行完毕,返回 `None`self.logger:日志记录器,用于记录测试过程中的信息
self.stats_dict:存储测试结果的统计信息
self.schema: 标签映射字典,表示标签与其索引的对应关系。例如,{"cat": 0, "dog": 1}。
index:当前批次的索引,用于遍历 self.valid_data
sentences:当前批次的原始句子数据,从 self.valid_data.dataset.sentences 中提取
epoch:当前训练轮次,用于标识模型版本或记录阶段性评估结果
self.valid_data:验证数据集加载器,提供批次化的验证数据
self.config[batch_size]:批次大小,控制单词处理的样本数量
input_id:模型的输入数据,通常是经过编码的文本数据
labels:真实标签张量,与模型输出对比以计算损失或评估指标
pred_results:模型的预测结果,通过 self.model(input_id) 计算得到
logger.info():记录信息级别的日志,用于输出程序状态或调试信息
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
msg | str | 日志消息内容(可含占位符 {}) | - |
*args | Any | 动态替换 msg 中的占位符(数量需与占位符匹配) | - |
**kwargs | Any | 扩展参数(如 exc_info=True 记录异常堆栈) | - |
dict():创建字典对象,支持多种参数形式
| 参数形式 | 类型 | 作用描述 | 示例 |
|---|---|---|---|
| 关键字参数 | key=value | 通过键值对直接构造字典 | dict(a=1, b=2) |
| 映射对象 | Mapping | 从其他字典或映射对象复制键值对 | dict({"a":1, "b":2}) |
| 可迭代对象 | Iterable | 从元组列表等可迭代对象生成键值对(元素需为 (key, value) 格式) |
字典.keys():返回字典所有键的视图对象(dict_keys 类型),用于遍历或检查键的存在性
defaultdict():创建默认值字典,当访问不存在的键时自动生成默认值
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
default_factory | Callable | 默认值生成函数(如 int、list) | None |
**kwargs | Any | 其他键值对(直接初始化字典内容) | - |
model.eval():将 PyTorch 模型切换为评估模式(禁用 Dropout 和 BatchNorm 的更新)
enumerate():为可迭代对象生成索引序列,常用于遍历时同时获取元素及其位置
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
iterable | Iterable | 需要遍历的数据源(如列表、元组) | - |
start | int | 索引起始值 | 0 |
torch.cuda.is_available():检查当前系统是否支持 CUDA(即 GPU 是否可用)
cuda():将 PyTorch 张量移动到 GPU 上以加速计算
| 参数名称 | 类型 | 作用描述 | 默认值 |
|---|---|---|---|
device | torch.device | 指定目标设备(如 cuda:0) | 当前 GPU |
torch.no_grad():上下文管理器,禁用梯度计算以节省内存并加速推理
def eval(self, epoch):
self.logger.info("开始测试第%d轮模型效果:" % epoch)
self.stats_dict = dict(zip(self.schema.keys(), [defaultdict(int) for i in range(len(self.schema))]))
self.model.eval()
for index, batch_data in enumerate(self.valid_data):
sentences = self.valid_data.dataset.sentences[index * self.config["batch_size"]: (index+1) * self.config["batch_size"]]
if torch.cuda.is_available():
batch_data = [d.cuda() for d in batch_data]
input_id, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
with torch.no_grad():
pred_results = self.model(input_id) #不输入labels,使用模型当前参数进行预测
self.write_stats(labels, pred_results, sentences)
self.show_stats()
returnⅣ、完整代码
# -*- coding: utf-8 -*-
import torch
import re
import numpy as np
from collections import defaultdict
from loader import load_data
"""
模型效果测试
"""
class Evaluator:
def __init__(self, config, model, logger):
self.config = config
self.model = model
self.logger = logger
self.valid_data = load_data(config["valid_data_path"], config, shuffle=False)
self.schema = self.valid_data.dataset.schema
self.index_to_label = dict((y, x) for x, y in self.schema.items())
def eval(self, epoch):
self.logger.info("开始测试第%d轮模型效果:" % epoch)
self.stats_dict = dict(zip(self.schema.keys(), [defaultdict(int) for i in range(len(self.schema))]))
self.model.eval()
for index, batch_data in enumerate(self.valid_data):
sentences = self.valid_data.dataset.sentences[index * self.config["batch_size"]: (index+1) * self.config["batch_size"]]
if torch.cuda.is_available():
batch_data = [d.cuda() for d in batch_data]
input_id, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
with torch.no_grad():
pred_results = self.model(input_id) #不输入labels,使用模型当前参数进行预测
self.write_stats(labels, pred_results, sentences)
self.show_stats()
return
def write_stats(self, labels, pred_results, sentences):
assert len(labels) == len(pred_results) == len(sentences), print(len(labels), len(pred_results), len(sentences))
if not self.config["use_crf"]:
pred_results = torch.argmax(pred_results, dim=-1)
for true_label, pred_label, sentence in zip(labels, pred_results, sentences):
if not self.config["use_crf"]:
pred_label = pred_label.cpu().detach().tolist()[:len(sentence)]
true_label = true_label.cpu().detach().tolist()[:len(sentence)]
for pred, gold in zip(pred_label, true_label):
key = self.index_to_label[gold]
self.stats_dict[key]["correct"] += 1 if pred == gold else 0
self.stats_dict[key]["total"] += 1
return
def show_stats(self):
total = []
for key in self.schema:
acc = self.stats_dict[key]["correct"] / (1e-5 + self.stats_dict[key]["total"])
self.logger.info("符号%s预测准确率:%f"%(key, acc))
total.append(acc)
self.logger.info("平均acc:%f" % np.mean(total))
self.logger.info("--------------------")
return
5.模型训练 main.py
代码运行流程
开始
├── 导入必要的库
├── 配置日志记录器
├── 定义主函数 main(config)
│ ├── 创建保存模型的目录
│ ├── 加载训练数据
│ ├── 加载模型
│ ├── 检查并启用 GPU
│ ├── 加载优化器
│ ├── 加载效果测试类
│ ├── 训练循环
│ │ ├── 设置模型为训练模式
│ │ ├── 遍历训练数据批次
│ │ │ ├── 清零梯度
│ │ │ ├── 将数据移至 GPU(如果可用)
│ │ │ ├── 获取输入数据和标签
│ │ │ ├── 计算损失
│ │ │ ├── 反向传播
│ │ │ ├── 更新模型参数
│ │ │ ├── 记录损失
│ │ │ └── 定期打印批次损失
│ │ └── 计算并打印平均损失
│ ├── 调用效果测试类进行验证
│ └── 保存模型
└── 调用主函数开始训练Ⅰ、导入文件
torch:深度学习框架,用于构建神经网络
os:操作系统接入模块,处理文件路径
random:生成伪随机数,用于设置随机数种子保证实验可复现
numpy:科学计算库,用于数组操作和数学运算
logging:日志记录模块,记录训练过程信息
Config:项目配置文件
TorchModel:模型架构
choose_optimizer:优化器选择器
Evaluator:模型评估工具类,计算准确率 / F1等指标
load_data:数据加载器,实现数据预处理和批量化
CRF:CRF层,用于序列标注任务的概率建模
# -*- coding: utf-8 -*-
import torch
import os
import random
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
from torchcrf import CRFⅡ、日志配置
logging:Python 的标准库,用于记录日志信息
logging.basicConfig():配置日志系统的基础设置(如日志级别、输出格式、输出位置等),仅需在程序启动时调用一次。若未显式调用,系统会使用默认配置(如输出到控制台、级别为 WARNING)
| 参数名 | 类型/可选值 | 作用描述 | 示例 |
|---|---|---|---|
level | int 或 str | 设置日志记录的最低级别(低于此级别的日志将被忽略) | logging.DEBUG 或 "DEBUG" |
format | str | 定义日志输出的格式(使用 % 占位符动态插入信息) | '%(asctime)s - %(message)s' |
datefmt | str | 定义时间戳的格式(需与 time.strftime 兼容) | '%Y-%m-%d %H:%M:%S' |
filename | str | 指定日志输出的文件名(若设置,日志将写入文件而非控制台) | 'app.log' |
filemode | 'a' 或 'w' | 定义文件写入模式('a' 追加,'w' 覆盖) | 'a'(默认值) |
stream | IO 对象 | 指定日志输出流(如 sys.stdout),与 filename 冲突时以 filename 优先 | sys.stderr(默认) |
handlers | list[Handler] | 指定自定义的处理器列表(覆盖默认的 StreamHandler) |
logging.getLogger():获取或创建指定名称的日志记录器(Logger 对象),用于模块化日志管理。若未指定名称,返回根记录器。
| 参数名 | 类型/可选值 | 作用描述 | 示例 |
|---|---|---|---|
name | str(可选) | 日志记录器的名称(层级结构用 . 分隔),默认返回根记录器 | __name__(模块名)或 'app' |
logging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
Ⅲ、主函数 main
代码运行流程
main 方法流程
├── 1. 创建保存模型的目录
│ └── 操作: `if not os.path.isdir(config["model_path"]): os.mkdir(config["model_path"])`
│ └── 作用: 检查并创建保存模型的目录
│
├── 2. 加载训练数据
│ └── 操作: `train_data = load_data(config["train_data_path"], config)`
│ └── 作用: 从指定路径加载训练数据
│
├── 3. 加载模型
│ └── 操作: `model = TorchModel(config)`
│ └── 作用: 根据配置初始化模型
│
├── 4. 检查并迁移模型至 GPU
│ └── 操作: `if cuda_flag: model = model.cuda()`
│ └── 作用: 如果 GPU 可用,则将模型迁移至 GPU
│
├── 5. 加载优化器
│ └── 操作: `optimizer = choose_optimizer(config, model)`
│ └── 作用: 根据配置和模型选择优化器
│
├── 6. 加载效果测试类
│ └── 操作: `evaluator = Evaluator(config, model, logger)`
│ └── 作用: 初始化效果测试类,用于模型评估
│
├── 7. 训练模型
│ └── 操作: `for epoch in range(config["epoch"]):`
│ ├── 7.1 设置模型为训练模式
│ │ └── 操作: `model.train()`
│ │ └── 作用: 将模型设置为训练模式
│ ├── 7.2 初始化训练损失列表
│ │ └── 操作: `train_loss = []`
│ │ └── 作用: 用于存储每个批次的损失
│ ├── 7.3 遍历训练数据
│ │ └── 操作: `for index, batch_data in enumerate(train_data):`
│ │ ├── 7.3.1 清空梯度
│ │ │ └── 操作: `optimizer.zero_grad()`
│ │ │ └── 作用: 清空优化器的梯度
│ │ ├── 7.3.2 将数据迁移至 GPU(如果可用)
│ │ │ └── 操作: `if cuda_flag: batch_data = [d.cuda() for d in batch_data]`
│ │ │ └── 作用: 如果 GPU 可用,则将数据迁移至 GPU
│ │ ├── 7.3.3 解包输入数据和标签
│ │ │ └── 操作: `input_id, labels = batch_data`
│ │ │ └── 作用: 解包当前批次的输入数据和标签
│ │ ├── 7.3.4 计算损失
│ │ │ └── 操作: `loss = model(input_id, labels)`
│ │ │ └── 作用: 使用模型计算损失
│ │ ├── 7.3.5 反向传播
│ │ │ └── 操作: `loss.backward()`
│ │ │ └── 作用: 计算梯度
│ │ ├── 7.3.6 更新模型参数
│ │ │ └── 操作: `optimizer.step()`
│ │ │ └── 作用: 更新模型参数
│ │ ├── 7.3.7 记录损失
│ │ │ └── 操作: `train_loss.append(loss.item())`
│ │ │ └── 作用: 将当前批次的损失加入列表
│ │ └── 7.3.8 记录批次损失
│ │ └── 操作: `if index % int(len(train_data) / 2) == 0: logger.info("batch loss %f" % loss)`
│ │ └── 作用: 每隔一定批次记录损失
│ ├── 7.4 计算并记录平均损失
│ │ └── 操作: `logger.info("epoch average loss: %f" % np.mean(train_loss))`
│ │ └── 作用: 计算并记录当前轮次的平均损失
│ └── 7.5 评估模型
│ └── 操作: `evaluator.eval(epoch)`
│ └── 作用: 使用验证集评估模型性能
│
├── 8. 保存模型
│ └── 操作: `torch.save(model.state_dict(), model_path)`
│ └── 作用: 将训练好的模型保存到指定路径
│
└── 9. 返回结果
└── 操作: `return model, train_data`
└── 作用: 返回训练好的模型和训练数据① 创建模型保存目录
config:传递给 main 函数的配置字典,包含模型训练的超参数和路径设置。
os.path.isdir():检查指定路径是否为存在的目录。返回布尔值(True/False)
| 参数名称 | 类型 | 描述 | 示例 |
|---|---|---|---|
path | str | 需要检查的路径(必须为绝对路径或相对于当前工作目录的有效路径) | os.path.isdir("/home/user") |
os.mkdir():创建单层目录。若父目录不存在或路径已存在,会抛出 FileExistsError 或 OSError
| 参数名 | 类型/可选值 | 描述 | 示例 |
|---|---|---|---|
path | str | 目录路径 | os.mkdir('new_dir') |
mode | int(八进制权限) | 目录权限(Linux 有效,Windows 可能忽略) | mode=0o755 |
dir_fd | int(文件描述符) | 父目录的文件句柄(高级用法,通常无需设置) | dir_fd=parent_fd |
#创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])② 加载训练数据
load_data():从 loader 模块中导入 load_data 函数,用于加载数据集
train_data:从配置文件中加载训练数据
#加载训练数据
train_data = load_data(config["train_data_path"], config)③ 加载模型
TorchModel():从model模块中导入网络模型类
model:TorchModel 类的实例,表示定义的神经网络模型
model = TorchModel(config)④ 检查GPU并迁移模型
cuda_flag:布尔值,表示是否可以使用 GPU 进行训练
model:TorchModel 类的实例,表示定义的神经网络模型
logger:日志记录模块,记录训练过程信息
torch.cuda.is_available():检测当前环境是否支持 CUDA(即 GPU 是否可用)
logging.info():配置日志系统的基础参数,如输出格式、文件路径等。仅需在程序初始化时调用一次
| 参数名 | 类型/可选值 | 描述 | 示例 |
|---|---|---|---|
filename | str | 日志文件路径(若设置,日志会写入文件而非控制台) | filename='app.log' |
filemode | 'a'(追加)或 'w'(覆盖) | 文件写入模式(默认 'a') | filemode='w' |
format | str | 日志格式字符串,支持占位符如 %(asctime)s、%(levelname)s | format='%(asctime)s - %(message)s' |
datefmt | str | 时间戳格式(需兼容 time.strftime) | datefmt='%Y-%m-%d %H:%M:%S' |
level | int 或 str | 日志记录的最低级别(如 logging.INFO) | level=logging.DEBUG |
stream | IO 对象 | 指定日志输出流(如 sys.stdout,与 filename 冲突时后者优先) | stream=sys.stderr |
model.cuda():将 PyTorch 模型迁移至 GPU 显存,启用 GPU 加速计算
| 参数名 | 类型/可选值 | 描述 | 示例 |
|---|---|---|---|
device | int 或 torch.device | 目标 GPU 设备编号(如 0 表示第一块 GPU) | model.cuda(device=0) |
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
model = model.cuda()⑤ 加载优化器
config:传递给 main 函数的配置字典,包含模型训练的超参数和路径设置
choose_optimizer:从 model 模块中导入 choose_optimizer 函数,根据配置文件选择优化器
model:TorchModel 类的实例,表示定义的神经网络模型
#加载优化器
optimizer = choose_optimizer(config, model)⑥ 加载评估器
config:传递给 main 函数的配置字典,包含模型训练的超参数和路径设置
model:TorchModel 类的实例,表示定义的神经网络模型
logger:日志记录模块,记录训练过程信息
Evaluator():从 evaluate 模块中导入 Evaluator 类,用于模型评估
#加载效果测试类
evaluator = Evaluator(config, model, logger)Ⅳ、模型训练
① Epoch循环控制
epoch:当前训练的轮次,从 0 开始,每次循环递增
range():Python 内置函数,用于生成一个不可变的整数序列,核心功能是为循环控制提供高效的数值迭代支持
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
start | 整数 | 0 | 序列起始值(包含)。若省略,则默认从 0 开始。例如 range(3) 等价于 range(0,3)。 |
stop | 整数 | 必填 | 序列结束值(不包含)。例如 range(2, 5) 生成 2,3,4 |
step | 整数 | 1 | 步长(正/负): - 正步长需满足 start < stop,否则无输出(如 range(5, 2) 无效)。- 负步长需满足 start > stop,例如 range(5, 0, -1) 生成 5,4,3,2,1**不能为 0**(否则触发 ValueError) |
for epoch in range(config["epoch"]):
epoch += 1② 模型设置训练模式
logger:日志记录模块,记录训练过程信息
model:TorchModel 类的实例,表示定义的神经网络模型
train_loss:计算当前批次的损失值,通常结合损失函数(如交叉熵、均方误差)使用
model.train():设置模型为训练模式,启用Dropout、BatchNorm等层的训练行为
| 参数 | 类型 | 默认值 | 说明 | 示例 |
|---|---|---|---|---|
mode | bool | True | 是否启用训练模式(True)或评估模式(False) | model.train(True) |
logger.info():记录日志信息,输出训练过程中的关键状态
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
msg | str | 是 | 日志消息(支持格式化字符串) | logger.info("Epoch: %d", epoch) |
*args | Any | 否 | 格式化参数(用于%占位符) |
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []③ Batch数据遍历
index:当前批次的索引值,从 0 开始,依次递增
batch_data:当前批次的数据,通常包含输入和标签
train_data:返回的训练数据,通常是一个数据加载器(DataLoader)对象
enumerate():遍历可迭代对象时返回索引和元素,支持自定义起始索引
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
iterable | Iterable | 是 | 可迭代对象(如列表、生成器) | enumerate(["a", "b"]) |
start | int | 否 | 索引起始值(默认0) | enumerate(data, start=1) |
for index, batch_data in enumerate(train_data):④ 梯度清零与设备切换
optimizer:优化器对象,用于更新模型参数以最小化损失函数
cuda_flag:布尔值,表示是否可以使用 GPU 进行训练
batch_data:当前批次的数据,通常包含输入和标签
optimizer.zero_grad():清空模型参数的梯度,防止梯度累积
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
set_to_none | bool | 否 | 是否将梯度置为None(高效但危险) | optimizer.zero_grad(True) |
cuda():将张量或模型移动到GPU显存,加速计算
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
device | int/str | 否 | 指定GPU设备(如0或"cuda:0") | tensor.cuda(device=0) |
non_blocking | bool | 否 | 是否异步传输数据(默认False) | tensor.cuda(non_blocking=True) |
optimizer.zero_grad()
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]⑤ 前向传播与损失计算
input_id:当前批次的输入数据,通常是经过编码的文本或其他特征
labels:当前批次的标签数据,表示模型需要预测的目标
batch_data:当前批次的数据,通常包含输入和标签
loss:当前批次的损失值,通过模型的前向传播和损失函数计算得到
input_id, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
loss = model(input_id, labels)⑥ 反向传播与参数更新
loss:当前批次的损失值,通过模型的前向传播和损失函数计算得到
optimizer:优化器对象,用于更新模型参数以最小化损失函数。
loss.backward():反向传播计算梯度,基于损失值更新模型参数的.grad属性
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
retain_graph | bool | 否 | 是否保留计算图(用于多次反向传播) | loss.backward(retain_graph=True) |
optimizer.step():根据梯度更新模型参数,执行优化算法(如SGD、Adam)
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
closure | Callable | 否 | 重新计算损失的闭包函数(如LBFGS) | optimizer.step(closure) |
loss.backward()
optimizer.step()⑦ 损失记录与日志输出
train_loss:列表,用于存储每个批次的损失值
index:当前批次的索引值,从 0 开始,依次递增
train_data:返回的训练数据,通常是一个数据加载器(DataLoader)对象
logger:日志记录器,用于输出训练过程中的日志信息
loss:当前批次的损失值,通过模型的前向传播和损失函数计算得到
列表.append():在列表末尾添加元素,直接修改原列表
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
object | Any | 是 | 要添加到列表末尾的元素 | train_loss.append(loss.item()) |
int():将字符串或浮点数转换为整数,支持进制转换
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
x | str/float | 是 | 待转换的值(如字符串或浮点数) | int("10", base=2)(输出2进制10=2) |
base | int | 否 | 进制(默认10) |
len():返回对象(如列表、字符串)的长度或元素个数
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
obj | Sequence/Collection | 是 | 可计算长度的对象(如列表、字符串) | len([1, 2, 3])(返回3) |
logger.info():记录日志信息,输出训练过程中的关键状态
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
msg | str | 是 | 日志消息(支持格式化字符串) | logger.info("Epoch: %d", epoch) |
*args | Any | 否 | 格式化参数(用于%占位符) |
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)⑧ Epoch评估与日志
logger:日志记录器,用于输出训练过程中的日志信息
evaluator:Evaluator 类的实例,用于评估模型在验证集上的性能。
train_loss:列表,用于存储每个批次的损失值
epoch:当前训练的轮次,从 0 开始,每次循环递增
logger.info():记录日志信息,输出训练过程中的关键状态
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
msg | str | 是 | 日志消息(支持格式化字符串) | logger.info("Epoch: %d", epoch) |
*args | Any | 否 | 格式化参数(用于%占位符) |
logger.info("epoch average loss: %f" % np.mean(train_loss))
evaluator.eval(epoch)⑨ 完整训练代码
#训练
for epoch in range(config["epoch"]):
epoch += 1
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):
optimizer.zero_grad()
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
input_id, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
loss = model(input_id, labels)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)
logger.info("epoch average loss: %f" % np.mean(train_loss))
evaluator.eval(epoch)Ⅴ、调用模型预测
# -*- coding: utf-8 -*-
import torch
import os
import random
import os
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
from torchcrf import CRF
logging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
"""
模型训练主程序
"""
def main(config):
#创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])
#加载训练数据
train_data = load_data(config["train_data_path"], config)
#加载模型
model = TorchModel(config)
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
model = model.cuda()
#加载优化器
optimizer = choose_optimizer(config, model)
#加载效果测试类
evaluator = Evaluator(config, model, logger)
#训练
for epoch in range(config["epoch"]):
epoch += 1
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):
optimizer.zero_grad()
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
input_id, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
loss = model(input_id, labels)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)
logger.info("epoch average loss: %f" % np.mean(train_loss))
evaluator.eval(epoch)
model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)
torch.save(model.state_dict(), model_path)
return model, train_data
if __name__ == "__main__":
model, train_data = main(Config)
6.模型预测文件 predict.py
初始化加载:加载标签映射表、词汇表和训练好的PyTorch模型
文本编码:将输入句子逐字符转换为词汇表索引(未登录词用[UNK]替代),形成数值序列。
模型推理:将编码后的序列输入神经网络,输出每个字符位置的标签概率分布,取最大概率对应的标签索引。
标签转换:根据索引到符号的映射表,将数字标签转换为实际符号(如标点或实体标记)。结果拼接:将字符与对应标签符号逐位拼接,生成带标注的最终字符串输
Ⅰ、初始化
config:一个字典,包含模型的配置参数,例如 schema_path 和 vocab_path
model_path:字符串,表示预训练模型的路径
self.config:将传入的 config 字典保存为类的属性,供其他方法使用
self.schema:通过调用 self.load_schema(config["schema_path"]) 加载的 schema 数据,通常是一个字典,表示标签或类别的映射关系。
self.index_to_sign:一个字典,将 self.schema 中的键值对反转,用于通过索引查找对应的标签或符号。
self.vocab:通过调用 self.load_vocab(config["vocab_path"]) 加载的词汇表,通常是一个字典,表示词汇到索引的映射。
self.model:TorchModel 类的实例,表示定义的神经网络模型。
def __init__(self, config, model_path):
self.config = config
self.schema = self.load_schema(config["schema_path"])
self.index_to_sign = dict((y, x) for x, y in self.schema.items())
self.vocab = self.load_vocab(config["vocab_path"])
self.model = TorchModel(config)
self.model.load_state_dict(torch.load(model_path))
self.model.eval()
print("模型加载完毕!")Ⅱ、加载映射关系表
代码运行流程
load_schema(self, path)
├── 打开文件:with open(path, encoding="utf8") as f
├── 加载 JSON 数据:schema = json.load(f)
├── 更新配置:self.config["class_num"] = len(schema)
└── 返回 schemapath:字符串,表示 JSON 文件的路径,该文件包含 schema 数据
f:文件对象,用于读取文件内容
schema:从 JSON 文件中加载的数据,通常是一个字典或列表,表示 schema 的结构。
class_num:schema 的长度(即类别数量)
open():用于打开文件并返回文件对象,支持读取、写入和追加等操作
| 参数名 | 类型 | 说明 |
|---|---|---|
filename | 字符串 | 文件路径,可以是绝对路径或相对路径。 |
mode | 字符串 | 文件打开模式,默认为 'r'(只读)。常见模式:'r'、'w'、'a' 等。 |
buffering | 整数 | 设置缓冲策略,0 表示无缓冲,1 表示行缓冲,大于 1 表示缓冲区大小。 |
encoding | 字符串 | 文件编码格式,如 'utf-8'。 |
errors | 字符串 | 指定编码错误的处理方式,如 'strict'、'ignore'。 |
newline | 字符串 | 控制换行符的处理方式,如 None、'\n'。 |
closefd | 布尔值 | 是否在文件关闭时关闭文件描述符,默认为 True。 |
opener | 可调用对象 | 自定义文件打开器。 |
json.load():用于从文件对象中读取 JSON 数据并解析为 Python 对象(如字典或列表)
| 参数名 | 类型 | 说明 |
|---|---|---|
fp | 文件对象 | 包含 JSON 数据的文件对象。 |
cls | 类 | 自定义 JSON 解码器类,默认为 None。 |
object_hook | 可调用对象 | 用于将 JSON 对象转换为自定义 Python 对象的函数。 |
parse_float | 可调用对象 | 用于将 JSON 中的浮点数转换为自定义类型的函数。 |
parse_int | 可调用对象 | 用于将 JSON 中的整数转换为自定义类型的函数。 |
parse_constant | 可调用对象 | 用于处理 JSON 中的常量(如 Infinity、NaN)的函数。 |
object_pairs_hook | 可调用对象 | 用于处理 JSON 对象中的键值对的函数。 |
len():用于返回对象的长度或元素个数,支持字符串、列表、元组、字典等。
| 参数名 | 类型 | 说明 |
|---|---|---|
object | 可迭代对象 | 需要计算长度的对象,如字符串、列表、元组、字典等。 |
def load_schema(self, path):
with open(path, encoding="utf8") as f:
schema = json.load(f)
self.config["class_num"] = len(schema)
return schema
Ⅲ、加载字 / 词表
代码运行流程
load_vocab(self, vocab_path)
├── 初始化 token_dict = {}
├── 打开文件:with open(vocab_path, encoding="utf8") as f
│ ├── 逐行读取文件:for index, line in enumerate(f)
│ │ ├── 去除空白字符:token = line.strip()
│ │ └── 将 token 和索引存入字典:token_dict[token] = index + 1
├── 更新配置:self.config["vocab_size"] = len(token_dict)
└── 返回 token_dicttoken_dict:字典,用于存储词汇表中的 token 及其对应的索引
vocab_path:字符串,表示词汇表文件的路径。
f:文件对象,用于读取词汇表文件
token:字符串,表示去除空白字符后的 token
index:整数,表示当前行的索引(从 0 开始)
line:字符串,表示文件中的一行内容
vocab_size:词汇表的大小(即 token 的数量)
enumerate():Python 的一个内置函数,用于将一个可迭代对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标。它通常用于需要同时访问元素及其索引的场景。
| 参数名 | 类型 | 说明 |
|---|---|---|
iterable | 可迭代对象 | 需要枚举的对象,如列表、元组或字符串。 |
start | 整数 | 可选参数,指定索引的起始值,默认为 0。 |
open(): Python 的一个内置函数,用于打开文件并返回文件对象,支持读取、写入和追加等操作。
| 参数名 | 类型 | 说明 |
|---|---|---|
filename | 字符串 | 文件路径,可以是绝对路径或相对路径。 |
mode | 字符串 | 文件打开模式,默认为 'r'(只读)。常见模式:'r'、'w'、'a' 等。 |
buffering | 整数 | 设置缓冲策略,0 表示无缓冲,1 表示行缓冲,大于 1 表示缓冲区大小。 |
encoding | 字符串 | 文件编码格式,如 'utf-8'。 |
errors | 字符串 | 指定编码错误的处理方式,如 'strict'、'ignore'。 |
newline | 字符串 | 控制换行符的处理方式,如 None、'\n'。 |
closefd | 布尔值 | 是否在文件关闭时关闭文件描述符,默认为 True。 |
opener | 可调用对象 | 自定义文件打开器。 |
# 加载字表或词表
def load_vocab(self, vocab_path):
token_dict = {}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
token = line.strip()
token_dict[token] = index + 1 # 0留给padding位置,所以从1开始
self.config["vocab_size"] = len(token_dict)
return token_dictⅣ、预测函数
代码运行流程
predict(self, sentence)
├── 初始化 input_id = []
├── 遍历句子中的每个字符:for char in sentence
│ └── 将字符转换为索引并存入 input_id:input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
├── 禁用梯度计算:with torch.no_grad()
│ ├── 将 input_id 转换为张量并输入模型:res = self.model(torch.LongTensor([input_id]))[0]
│ └── 获取预测结果的最大值索引:res = torch.argmax(res, dim=-1)
├── 初始化 labeled_sentence = ""
├── 遍历句子和预测结果:for char, label_index in zip(sentence, res)
│ └── 将字符和标签拼接成结果:labeled_sentence += char + self.index_to_sign[int(label_index)]
└── 返回 labeled_sentencesentence:字符串,表示输入的句子。
input_id:列表,用于存储句子中每个字符对应的索引
char:字符串,表示句子中的单个字符
self.model:PyTorch 模型,用于对输入数据进行预测
labeled_sentence:字符串,表示带有标签的句子
label_index:整数,表示预测结果的标签索引
res:张量,表示模型的输出结果。
self.index_to_sign: 字典,将索引映射到标签或符号
列表.append():append() 是 Python 列表的一个方法,用于在列表末尾添加一个新元素
| 参数名 | 类型 | 说明 |
|---|---|---|
element | 任意类型 | 要添加到列表末尾的元素,可以是整数、字符串、列表、元组等任意类型。 |
torch.no_grad():PyTorch 中的一个上下文管理器,用于禁用梯度计算。通常在模型推理(测试)阶段使用,以减少内存消耗并加速计算
torch.argmax():返回张量中最大值的索引。可以指定维度(dim)来沿特定维度计算最大值的索引。
| 参数名 | 类型 | 说明 |
|---|---|---|
input | 张量 | 输入张量,可以是任意维度的张量。 |
dim | 整数 | 可选参数,指定沿哪个维度计算最大值的索引。默认为 None,表示将张量展平后计算。 |
keepdim | 布尔值 | 可选参数,是否保持输出张量的维度。默认为 False。 |
zip():Python 的内置函数,用于将多个可迭代对象(如列表、元组等)的元素配对,返回一个由元组组成的迭代器。
| 参数名 | 类型 | 说明 |
|---|---|---|
iterables | 可迭代对象 | 任意数量的可迭代对象,如列表、元组、字符串等。 |
int():Python 的内置函数,用于将数字或字符串转换为整数。可以指定进制(base)来将特定进制的字符串转换为十进制整数。
| 参数名 | 类型 | 说明 |
|---|---|---|
x | 数字或字符串 | 要转换为整数的对象,可以是数字、字符串等。 |
base | 整数 | 可选参数,指定 x 的进制。默认为 10,表示十进制。 |
def predict(self, sentence):
input_id = []
for char in sentence:
input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
with torch.no_grad():
res = self.model(torch.LongTensor([input_id]))[0]
res = torch.argmax(res, dim=-1)
labeled_sentence = ""
for char, label_index in zip(sentence, res):
labeled_sentence += char + self.index_to_sign[int(label_index)]
return labeled_sentenceⅤ、模型预测
# -*- coding: utf-8 -*-
import torch
import re
import json
import numpy as np
from collections import defaultdict
from config import Config
from model import TorchModel
"""
模型效果测试
"""
class SentenceLabel:
def __init__(self, config, model_path):
self.config = config
self.schema = self.load_schema(config["schema_path"])
self.index_to_sign = dict((y, x) for x, y in self.schema.items())
self.vocab = self.load_vocab(config["vocab_path"])
self.model = TorchModel(config)
self.model.load_state_dict(torch.load(model_path))
self.model.eval()
print("模型加载完毕!")
def load_schema(self, path):
with open(path, encoding="utf8") as f:
schema = json.load(f)
self.config["class_num"] = len(schema)
return schema
# 加载字表或词表
def load_vocab(self, vocab_path):
token_dict = {}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
token = line.strip()
token_dict[token] = index + 1 # 0留给padding位置,所以从1开始
self.config["vocab_size"] = len(token_dict)
return token_dict
def predict(self, sentence):
input_id = []
for char in sentence:
input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
with torch.no_grad():
res = self.model(torch.LongTensor([input_id]))[0]
res = torch.argmax(res, dim=-1)
labeled_sentence = ""
for char, label_index in zip(sentence, res):
labeled_sentence += char + self.index_to_sign[int(label_index)]
return labeled_sentence
if __name__ == "__main__":
sl = SentenceLabel(Config, "model_output/epoch_10.pth")
sentence = "客厅的颜色比较稳重但不沉重相反很好的表现了欧式的感觉给人高雅的味道"
res = sl.predict(sentence)
print(res)
sentence = "双子座的健康运势也呈上升的趋势但下半月有所回落"
res = sl.predict(sentence)
print(res)
sentence = "我漫步在花海之中花朵的芬芳萦绕身旁五彩斑斓的色彩令人陶醉微风拂过花瓣轻轻飘落宛如梦幻的画卷心中满是宁静与喜悦"
res = sl.predict(sentence)
print(res)
sentence = "男孩怀揣梦想踏上旅程穿越山川河流历经风雨洗礼在陌生城市里他努力奋斗从底层做起凭借坚定信念和不懈努力终于在事业上取得成功收获了属于自己的荣耀"
res = sl.predict(sentence)
print(res)
九、句子级别的序列标注🚀
对于一个大段落中抽取多句话,对每句话进行分类
paragraph -> sentence -> token:序列标注可以从段落去做,也可以在一句文本中对于token去做
将每句话进行向量化,之后仅需进行序列标注
从文献的回复中抽取审稿人的意见
1.配置文件 config.py
model_path:模型存储路径,需要提前创建目录
pretrain_model_path:预训练模型路径
max_length:序列最大长度
epoch:训练轮数
batch_size:批次大小
optimizer:优化器选择
learning_rate:学习率设置
seed:随机数种子
num_lables:标签类别总数
recurrent:循环层类型(支持LSTM / gru)
max_sentence:单个句子的最大长度
os.envion:Python 标准库 os 模块中的一个字典对象,用于读取、设置和删除操作系统环境变量。
train_data_path:训练数据的路径
valid_data_path:验证数据的路径
split():将字符串或列表按照分隔符分割成子列表。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| sep | str | None | 分隔符(如 " " 或 ",")。 |
| maxsplit | int | -1 | 最大分割次数(默认不限制)。 |
| keepends | bool | False | 是否保留分隔符(如 True 保留 .)。 |
# -*- coding: utf-8 -*-
"""
配置参数信息
"""
import os
import torch
Config = {
"model_path": "output",
"pretrain_model_path":r"F:\人工智能NLP/NLP资料\week6 语言模型/bert-base-chinese",
"max_length": 50,
"epoch": 10,
"batch_size": 10,
"optimizer": "adam",
"learning_rate":1e-5,
"seed":42,
"num_labels": 3,
"recurrent":"gru",
"max_sentence": 50
}
if "CUDA_VISIBLE_DEVICES" in os.environ:
Config["num_gpus"] = len(os.environ["CUDA_VISIBLE_DEVICES"].split(","))
else:
Config["num_gpus"] = 0
Config["train_data_path"] = "data/train.txt"
Config["valid_data_path"] = "data/test.txt"
2.数据加载文件 loader.py
代码运行流程
DataGenerator
├── __init__(self, data_path, config, logger)
│ ├── 初始化配置:self.config, self.logger, self.path, self.max_length
│ ├── 初始化tokenizer:self.tokenizer = AutoTokenizer.from_pretrained(config["pretrain_model_path"])
│ ├── 初始化label_map:self.label_map = {"B":0, "I":1, "O":2}
│ └── 调用self.load()加载数据
├── load(self)
│ ├── 初始化self.data = []
│ ├── 打开文件并逐段读取数据
│ └── 对每段数据调用self.prepare_data(segment)
├── prepare_data(self, segment)
│ ├── 初始化segment_input_ids, segment_attention_mask, labels
│ ├── 逐行处理segment中的每行数据
│ │ ├── 提取sentence, label, role
│ │ ├── 检查role和label的有效性
│ │ ├── 使用tokenizer.encode_plus编码sentence
│ │ ├── 提取input_ids, attention_mask
│ │ ├── 将input_ids, attention_mask, label添加到对应列表
│ │ └── 如果labels长度超过max_sentence,则跳出循环
│ └── 将处理后的数据封装为tensor并添加到self.data
├── __len__(self)
│ └── 返回self.data的长度
└── __getitem__(self, index)
└── 返回self.data[index]
load_data(data_path, config, logger, shuffle=True)
├── 创建DataGenerator对象:dg = DataGenerator(data_path, config, logger)
└── 返回dgⅠ、类初始化与配置加载
self.config:存储传入的配置信息,通常是一个字典,包含模型和数据处理的参数
self.logger:日志记录器,用于记录程序运行过程中的信息
self.path:数据文件的路径,指向需要加载的数据文件
self.max_length:从 config 中获取的最大长度参数,用于限制输入序列的长度
self.tokenizer:使用 AutoTokenizer.from_pretrained() 方法加载的预训练模型的分词器,用于将文本转换为模型可接受的输入格式
self.label_map:标签映射字典,将标签(如 "B"、"I"、"O")映射为整数索引,方便模型处理。
self.load():类的方法,用于加载数据并进行预处理
# -*- coding: utf-8 -*-
import json
import re
import os
import torch
import random
import jieba
import numpy as np
from torch.utils.data import Dataset, DataLoader
from collections import defaultdict
from transformers import BertTokenizer
"""
数据加载
"""
class DataGenerator:
def __init__(self, data_path, config):
self.config = config
self.path = data_path
self.tokenizer = load_vocab(config["bert_path"])
self.sentences = []
self.schema = self.load_schema(config["schema_path"])
self.load()Ⅱ、加载字 / 词表
代码运行流程
self.data:列表,用于存储处理后的数据。
f:文件对象,用于读取文件内容。
self.path:字符串,表示数据文件的路径。
segment:字符串,表示从文件中读取的每一段内容。
self.prepare_data():类的方法,用于处理每一段数据
文件对象.read():从文件中读取指定字节数的内容。如果未指定字节数或为负数,则读取整个文件内容。
| 参数名 | 类型 | 说明 |
|---|---|---|
size | 整数 | 可选参数,指定读取的字节数。如果未指定或为负数,则读取整个文件内容。 |
字符串.split():将字符串按照指定的分隔符分割成多个子字符串,并返回一个列表。
| 参数名 | 类型 | 说明 |
|---|---|---|
separator | 字符串 | 可选参数,指定分隔符。如果未指定,默认使用空格作为分隔符。 |
maxsplit | 整数 | 可选参数,指定最大分割次数。如果未指定或为负数,则表示不限制分割次数。 |
字符串.strip():移除字符串头尾的指定字符或字符序列(默认为移除空格或换行符等)。
| 参数名 | 类型 | 说明 |
|---|---|---|
chars | 字符串 | 可选参数,指定要移除的字符或字符序列。如果未指定,默认移除空格或换行符等。 |
open():打开一个文件,并返回文件对象。用于对文件进行读写操作。
| 参数名 | 类型 | 说明 |
|---|---|---|
file | 字符串 | 必需参数,指定要打开的文件路径(相对或绝对路径)。 |
mode | 字符串 | 可选参数,指定文件打开模式,默认为 'r'(只读模式)。 |
buffering | 整数 | 可选参数,设置缓冲策略。默认为 -1,表示使用系统默认缓冲机制。 |
encoding | 字符串 | 可选参数,指定文件的编码方式,默认为 None。 |
errors | 字符串 | 可选参数,指定编码错误的处理方式,默认为 None。 |
newline | 字符串 | 可选参数,控制换行符的处理方式,默认为 None。 |
closefd | 布尔值 | 可选参数,控制文件描述符的关闭行为,默认为 True。 |
opener | 函数 | 可选参数,设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。 |
def load(self):
self.data = []
with open(self.path, encoding="utf8") as f:
segments = f.read().split("\n\n")
for segment in segments:
sentenece = []
labels = [8] # cls_token
for line in segment.split("\n"):
if line.strip() == "":
continue
char, label = line.split()
sentenece.append(char)
labels.append(self.schema[label])
sentence = "".join(sentenece)
self.sentences.append(sentence)
input_ids = self.encode_sentence(sentenece)
labels = self.padding(labels, -1)
# print(self.decode(sentence, labels))
# input()
self.data.append([torch.LongTensor(input_ids), torch.LongTensor(labels)])
returnⅢ、数据预处理
代码运行流程
prepare_data(self, segment)
├── 初始化 segment_input_ids = []
├── 初始化 segment_attention_mask = []
├── 初始化 labels = []
├── 逐行处理 segment:for line in segment.split("\n")
│ ├── 跳过空行:if line.strip() == ""
│ │ └── continue
│ ├── 提取句子:sentence = line.split("\t")[0]
│ ├── 提取标签:label = line.split("\t")[1][0]
│ ├── 提取角色:role = line.split("\t")[3]
│ ├── 检查角色是否合法:assert role in ["Reply", "Review"]
│ ├── 检查标签是否合法:assert label in self.label_map
│ ├── 将标签映射为索引:label = self.label_map[label]
│ ├── 编码句子:encode = self.tokenizer.encode_plus(sentence, max_length=self.max_length, pad_to_max_length=True, add_special_tokens=True)
│ ├── 提取 input_ids:input_ids = encode["input_ids"]
│ ├── 提取 attention_mask:attention_mask = encode["attention_mask"]
│ ├── 将 input_ids 加入 segment_input_ids:segment_input_ids.append(input_ids)
│ ├── 将 attention_mask 加入 segment_attention_mask:segment_attention_mask.append(attention_mask)
│ ├── 将标签加入 labels:labels.append(label)
│ ├── 检查标签数量是否超过最大句子数:if len(labels) > self.config["max_sentence"]
│ │ └── 跳出循环:break
├── 将数据加入 self.data:self.data.append([torch.LongTensor(segment_input_ids), torch.LongTensor(segment_attention_mask), torch.LongTensor(labels)])
└── 返回segment:字符串,表示从文件中读取的一段数据,通常包含多行句子
segment_input_ids:列表,用于存储每行句子的 input_ids(编码后的输入序列)
segment_attention_mask:列表,用于存储每行句子的 attention_mask(注意力掩码)
line:字符串,表示 segment 中的一行数据
sentence:字符串,表示从 line 中提取的句子
labels:列表,用于存储每行句子的标签
label:列表,用于存储每行句子的标签
role:字符串,表示从 line 中提取的角色(如 "Reply" 或 "Review")
self.label_map:字典,将标签(如 "B"、"I"、"O")映射为整数索引
encode:字典,表示使用分词器对句子进行编码后的结果,包含 input_ids、attention_mask 等。
input_ids:列表,表示句子编码后的输入序列
attention_mask:列表,表示句子的注意力掩码
maxlength:整数,表示每段数据中允许的最大句子数
self.data:列表,用于存储处理后的数据,每个元素是一个包含 segment_input_ids、segment_attention_mask 和 labels 的列表
字符串.split():将字符串按照指定的分隔符分割成多个子字符串,并返回一个列表。
| 参数名 | 类型 | 说明 |
|---|---|---|
separator | 字符串 | 可选参数,指定分隔符。如果未指定,默认使用空格作为分隔符。 |
maxsplit | 整数 | 可选参数,指定最大分割次数。如果未指定或为负数,则表示不限制分割次数。 |
字符串.strip():移除字符串头尾的指定字符或字符序列(默认为移除空格或换行符等)。
| 参数名 | 类型 | 说明 |
|---|---|---|
chars | 字符串 | 可选参数,指定要移除的字符或字符序列。如果未指定,默认移除空格或换行符等。 |
tokenizer.encode_plus():将文本编码为模型可接受的输入格式,返回包含 input_ids、attention_mask 等信息的字典。常用于自然语言处理任务中,如 BERT 等模型的输入处理
| 参数名 | 类型 | 说明 |
|---|---|---|
text | str 或 List[str] | 要编码的文本或文本列表。 |
text_pair | str 或 List[str] | 可选,第二个文本或文本列表,用于处理句子对任务。 |
add_special_tokens | bool | 是否添加特殊 token(如 [CLS] 和 [SEP]),默认为 True。 |
padding | bool 或 str | 是否补齐序列,可选值:True、'max_length'、False 等。 |
truncation | bool 或 str | 是否截断序列,可选值:True、'longest_first'、'only_first' 等。 |
max_length | int | 序列的最大长度,默认为 None。 |
return_tensors | str | 返回的张量类型,可选值:'pt'(PyTorch)、'tf'(TensorFlow)等。 |
return_token_type_ids | bool | 是否返回 token_type_ids,默认为 None。 |
return_attention_mask | bool | 是否返回 attention_mask,默认为 None。 |
列表.append():在列表末尾添加一个元素,修改原列表但不返回任何值
| 参数名 | 类型 | 说明 |
|---|---|---|
element | 任意 | 要添加到列表末尾的元素,可以是任意类型。 |
torch.LongTensor():将输入数据转换为 PyTorch 的长整型张量(torch.LongTensor),常用于处理索引或标签数据
| 参数名 | 类型 | 说明 |
|---|---|---|
data | list 或 numpy.ndarray | 输入数据,可以是列表或 NumPy 数组。 |
def prepare_data(self, segment):
segment_input_ids = []
segment_attention_mask = []
labels = []
for line in segment.split("\n"):
if line.strip() == "":
continue
sentence = line.split("\t")[0]
label = line.split("\t")[1][0]
role = line.split("\t")[3]
assert role in ["Reply", "Review"]
assert label in self.label_map, label
label = self.label_map[label]
encode = self.tokenizer.encode_plus(sentence,
max_length=self.max_length,
pad_to_max_length=True,
add_special_tokens=True)
input_ids = encode["input_ids"]
attention_mask = encode["attention_mask"]
#token_type_ids = encode["token_type_ids"]
segment_input_ids.append(input_ids)
segment_attention_mask.append(attention_mask)
#segment_token_type_ids.append(token_type_ids)
labels.append(label)
if len(labels) > self.config["max_sentence"]:
break
self.data.append([torch.LongTensor(segment_input_ids),
torch.LongTensor(segment_attention_mask),
#torch.LongTensor(segment_token_type_ids),
torch.LongTensor(labels)])
returnⅣ、类内魔术方法
① __len__方法重写
len():函数用于返回一个容器(如字符串、列表、元组、字典等)中元素的个数或长度。它可以应用于多种数据类型
| 参数名 | 类型 | 说明 |
|---|---|---|
object | 任意容器类型 | 必需参数,表示要计算长度的容器对象。 |
def __len__(self):
return len(self.data)② __getitem__方法重写
def __getitem__(self, index):
return self.data[index]Ⅴ、数据封装
代码运行流程
load_data(data_path, config, logger, shuffle=True)
├── 创建 DataGenerator 实例:dg = DataGenerator(data_path, config, logger)
└── 返回 DataGenerator 实例:return dgdata_path:字符串,表示数据文件的路径
config:字典或对象,包含数据加载和处理的配置参数,例如 batch_size、max_length 等。
logger:日志记录器对象,用于记录数据加载过程中的日志信息
shuffle:布尔值,表示是否在加载数据时打乱顺序,默认为 True
dg:DataGenerator 类的实例,用于生成数据加载器
#用torch自带的DataLoader类封装数据
def load_data(data_path, config, logger, shuffle=True):
dg = DataGenerator(data_path, config, logger)
# dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
return dgⅥ、验证数据加载函数
代码运行流程
if __name__ == "__main__":
├── 导入 Config 类:from config import Config
├── 导入 logging 模块:import logging
├── 配置日志记录:logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
└── 创建日志记录器:logger = logging.getLogger(__name__)logging.basicConfig():用于配置日志系统的基本行为,包括日志的输出格式、日志级别、输出位置等。它通常在程序的入口处调用一次,用于设置全局的日志配置
| 参数名 | 类型 | 说明 |
|---|---|---|
filename | str | 指定日志输出的文件名。如果配置了此参数,日志会被存储在指定的文件中。 |
filemode | str | 日志文件的打开模式,默认为 'a'(追加模式),还可指定为 'w'。 |
format | str | 指定日志输出的格式。常用占位符包括 %(asctime)s、%(levelname)s 等。 |
datefmt | str | 指定 asctime 的输出格式。 |
level | int | 设置日志的输出级别,默认为 logging.WARNING。 |
stream | stream | 指定日志输出的流对象,默认为 sys.stderr。 |
logging.getLogger():创建或获取一个日志记录器(Logger)对象。日志记录器是分层次组织的,可以通过名称来获取或创建特定的日志记录器
| 参数名 | 类型 | 说明 |
|---|---|---|
name | str | 日志记录器的名称,通常用模块名或自定义字符串命名。默认为 ""(根日志记录器)。 |
if __name__ == "__main__":
from config import Config
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
Ⅶ、完整代码
# -*- coding: utf-8 -*-
import json
import re
import os
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
from transformers import AutoTokenizer, BertTokenizer
from collections import defaultdict
"""
数据加载
"""
class DataGenerator:
def __init__(self, data_path, config, logger):
if 'add_special_tokens' in config:
del config['add_special_tokens'] # 移除冲突的键
self.config = config
self.logger = logger
self.path = data_path
self.max_length = config["max_length"]
self.tokenizer = AutoTokenizer.from_pretrained(config["pretrain_model_path"])
# ,
#use_fast=True,
# add_special_tokens=True)
#{'I-Reply', 'I-Review', 'B-Reply', 'B-Review', 'O'}
self.label_map = {"B":0, "I":1, "O":2}
self.load()
def load(self):
self.data = []
with open(self.path, encoding="utf8") as f:
for segment in f.read().split("\n\n"):
if segment.strip() == "" or "\n" not in segment:
continue
self.prepare_data(segment)
return
def prepare_data(self, segment):
segment_input_ids = []
segment_attention_mask = []
labels = []
for line in segment.split("\n"):
if line.strip() == "":
continue
sentence = line.split("\t")[0]
label = line.split("\t")[1][0]
role = line.split("\t")[3]
assert role in ["Reply", "Review"]
assert label in self.label_map, label
label = self.label_map[label]
encode = self.tokenizer.encode_plus(sentence,
max_length=self.max_length,
pad_to_max_length=True,
add_special_tokens=True)
input_ids = encode["input_ids"]
attention_mask = encode["attention_mask"]
#token_type_ids = encode["token_type_ids"]
segment_input_ids.append(input_ids)
segment_attention_mask.append(attention_mask)
#segment_token_type_ids.append(token_type_ids)
labels.append(label)
if len(labels) > self.config["max_sentence"]:
break
self.data.append([torch.LongTensor(segment_input_ids),
torch.LongTensor(segment_attention_mask),
#torch.LongTensor(segment_token_type_ids),
torch.LongTensor(labels)])
return
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
#用torch自带的DataLoader类封装数据
def load_data(data_path, config, logger, shuffle=True):
dg = DataGenerator(data_path, config, logger)
# dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
return dg
if __name__ == "__main__":
from config import Config
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
3.模型文件 model.py
Ⅰ、模型初始化
self.bert_like:加载预训练的 BERT 模型
self.dropout:定义 Dropout 层,用于防止过拟合
self.num_labels:设置分类任务的标签数量
self.recurrent_layer:定义循环神经网络层(LSTM 或 GRU),用于处理序列数据
self.classifier:定义线性分类器,用于将 BERT 模型的输出映射到分类任务的标签空间
BertModel.from_pretrained():加载预训练的 BERT 模型(来自 Hugging Face Transformers 库)
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| model_name_or_path | str | None | 模型名称或本地路径(如 "bert-base-uncased")。 |
| cache_dir | str | None | 缓存目录(默认使用 ~/.cache/huggingface)。 |
| force_download | bool | False | 是否强制下载模型(即使已缓存)。 |
| num_layers | int | None | 模型层数(如 3 对应 BERT-Base)。 |
| hidden_size | int | None | 隐藏层维度(如 768 对应 BERT-Base)。 |
| attention_head_count | int | None | 注意力头数量(如 12 对应 BERT-Base)。 |
nn.Dropout():在神经网络中插入 dropout 层,随机失活部分神经元以防止过拟合。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| p | float | 0.5 | 丢弃概率(0~1)。 |
| inplace | bool | False | 是否原地操作(节省内存)。 |
nn.LSTM():实现长短期记忆网络(LSTM),处理序列数据并捕捉长期依赖。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| input_size | int | None | 输入特征维度(如词嵌入维度)。 |
| hidden_size | int | None | LSTM 单元隐藏层维度。 |
| num_layers | int | 1 | LSTM 层数量。 |
| batch_first | bool | False | 输入格式是否为 (batch, seq, features)。 |
| dropout | float | 0.0 | 丢弃概率(仅在多层 LSTM 中生效)。 |
| bidirectional | bool | False | 是否启用双向 LSTM。 |
| cell_class | Type[nn.RNNCell] | None | 自定义 RNN 单元类(默认 nn.LSTMCell)。 |
nn.GRU():实现门控循环单元(GRU),简化版的 LSTM,参数更少、计算更快。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| input_size | int | None | 输入特征维度。 |
| hidden_size | int | None | GRU 单元隐藏层维度。 |
| num_layers | int | 1 | GRU 层数量。 |
| batch_first | bool | False | 输入格式是否为 (batch, seq, features)。 |
| dropout | float | 0.0 | 丢弃概率(仅在多层 GRU 中生效)。 |
| bidirectional | bool | False | 是否启用双向 GRU。 |
| cell_class | Type[nn.GRUCell] | None | 自定义 GRU 单元类(默认 nn.GRUCell)。 |
assert:断言条件是否为真,用于调试和错误检查。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| condition | any | None | 需要验证的条件表达式。 |
| msg | str | None | 条件不满足时的错误提示信息。 |
| expr | any | None | Python 3.8+ 中已弃用,推荐使用 condition。 |
nn.Linear():全连接层,将输入线性映射到输出。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| in_features | int | None | 输入特征数。 |
| out_features | int | None | 输出特征数。 |
| bias | bool | True | 是否启用偏置项。 |
| device | str/int | None | 指定权重存储设备(如 "cuda")。 |
def __init__(self, config):
super(TorchModel, self).__init__()
self.bert_like = BertModel.from_pretrained(config["pretrain_model_path"])
self.dropout = nn.Dropout(self.bert_like.config.hidden_dropout_prob)
self.num_labels = config["num_labels"]
if config["recurrent"] == "lstm":
self.recurrent_layer = nn.LSTM(self.bert_like.config.hidden_size,
self.bert_like.config.hidden_size // 2,
batch_first=True,
bidirectional=True,
num_layers=1
)
elif config["recurrent"] == "gru":
self.recurrent_layer = nn.GRU(self.bert_like.config.hidden_size,
self.bert_like.config.hidden_size // 2,
batch_first=True,
bidirectional=True,
num_layers=1
)
else:
assert False
self.classifier = nn.Linear(self.bert_like.config.hidden_size, config["num_labels"])
self.classifier1 = nn.Linear(self.bert_like.config.hidden_size, config["num_labels"])
self.classifier2 = nn.Linear(self.bert_like.config.hidden_size, config["num_labels"])
self.classifier3 = nn.Linear(self.bert_like.config.hidden_size, config["num_labels"])
self.classifier4 = nn.Linear(self.bert_like.config.hidden_size, config["num_labels"])Ⅱ、前向计算
代码运行流程
开始
├── 获取输入数据
│ ├── `input_ids`:输入文本的 token ID 序列
│ └── `attention_mask`:注意力掩码
├── 通过 BERT-like 模型处理输入
│ ├── 获取隐藏状态和池化输出
│ └── 提取池化输出 `pooled_output`
├── 对池化输出进行 Dropout
├── 通过 RNN 层处理
│ ├── 将池化输出扩展维度
│ └── 获取 RNN 输出 `recurrent_output`
├── 通过分类器生成最终输出 `output`
├── 判断是否有标签 `labels`
│ ├── 如果有标签,计算损失 `loss` 并返回
│ └── 如果没有标签,返回预测结果 `output`
└── 结束input_ids:输入文本的 token ID 序列,形状为 (num_sentence, sentence_length),其中 num_sentence 是句子数量,sentence_length 是每个句子的长度。
attention_mask:注意力掩码,用于指示哪些 token 是实际输入,哪些是填充部分。形状与 input_ids 相同。
labels:真实标签,用于计算损失。如果为 None,则只返回模型的预测结果
outputs:BERT-like 模型的输出,通常包含最后一层的隐藏状态和池化输出
pooled_output:BERT-like 模型的池化输出,形状为 (num_sentence, vector_size=768),表示每个句子的语义向量。
recurrent_output:经过 RNN 层(如 LSTM 或 GRU)处理后的输出,形状为 (1, num_sentence, LSTM_HIDDEN_SIZE * 2)
output:模型的最终预测结果,形状为 (num_sentence, num_labels),其中 num_labels 是类别数量
loss_func:交叉熵损失函数,用于计算预测结果与真实标签之间的损失
loss: 计算得到的损失值
CrossEntropyLoss():计算交叉熵损失,常用于分类任务。输入为 logits(未归一化概率)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| input_size | int | None | 输入特征数(logits 的维度)。 |
| num_classes | int | None | 类别总数。 |
| ignore_index | int | -100 | 忽略的标签索引(如 [PAD]=0)。 |
| weight | Tensor | None | 类别权重(用于不平衡数据)。 |
| reduction | str | "mean" | 损失计算的缩减方式(如 "sum")。 |
| label_smoothing | float | 0.0 | 标签平滑系数(防止过拟合)。 |
view():改变张量的形状(类似 reshape),返回新视图(不复制数据)。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| new_shape | tuple | None | 新的形状(如 (batch, sen_len))。支持 -1 自动推断维度。 |
| dtype | torch.dtype | None | 数据类型(如 torch.float32)。默认与原张量一致。 |
squeeze():用于移除张量中所有大小为1的维度,从而降低张量的维度。若指定维度参数 dim,则仅移除该维度上大小为1的部分。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
input | Tensor | 必填 | 输入张量,需至少有一个维度大小为1。 |
dim | int | None | 可选参数,指定需压缩的维度索引。若未指定,则移除所有大小为1的维度。 |
def forward(self, input_ids=None,
attention_mask=None,
labels=None):
#(num_sentence, sentence_length)
outputs = self.bert_like(
input_ids,
attention_mask=attention_mask,
)
pooled_output = outputs[1]
#(num_sentence, vector_size=768)
pooled_output = self.dropout(pooled_output)
#(num_sentence, vector_size=768) -> (1, num_sentence, vector_size)
recurrent_output, _ = self.recurrent_layer(pooled_output.unsqueeze(0))
#(1, num_sentence, LSTM_HIDDEN_SIZE * 2)
output = self.classifier(recurrent_output.squeeze(0))
if labels is not None:
loss_func = CrossEntropyLoss()
loss = loss_func(output.view(-1, self.num_labels), labels.view(-1))
return loss
else:
return outputⅢ、选择优化器
代码运行流程
choose_optimizer 函数流程
├── 1. 输入参数
│ ├── 1.1 `config`: 配置字典,包含优化器类型和学习率
│ └── 1.2 `model`: 模型对象,包含需要优化的参数
│
├── 2. 从配置中获取优化器类型
│ └── 操作: `optimizer = config["optimizer"]`
│ └── 作用: 获取配置中指定的优化器类型(如 "adam" 或 "sgd")
│
├── 3. 从配置中获取学习率
│ └── 操作: `learning_rate = config["learning_rate"]`
│ └── 作用: 获取配置中指定的学习率
│
├── 4. 判断优化器类型
│ ├── 4.1 如果优化器是 "adam":
│ │ └── 操作: `return Adam(model.parameters(), lr=learning_rate)`
│ │ ├── 作用: 使用 Adam 优化器初始化并返回
│ │ └── 输出: Adam 优化器对象
│ └── 4.2 如果优化器是 "sgd":
│ └── 操作: `return SGD(model.parameters(), lr=learning_rate)`
│ ├── 作用: 使用 SGD 优化器初始化并返回
│ └── 输出: SGD 优化器对象
│
└── 5. 返回优化器对象
└── 作用: 返回根据配置选择的优化器对象config:配置字典,包含优化器的名称和学习率等超参数
model:待训练的模型,其参数将由优化器更新
optimizer:优化器的名称,例如 "adam" 或 "sgd",用于选择具体的优化算法
learning_rate:学习率,控制每次参数更新的步长大小
lr: 优化器的学习率参数,控制参数更新的步长
Adamw():自适应矩估计优化器(Adaptive Moment Estimation with Weight Decay),结合 Adam 和权重衰减,更适合深度学习。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| lr | float | 1e-3 | 学习率。 |
| betas | tuple | (0.9, 0.999) | 动量系数(β₁, β₂)。 |
| eps | float | 1e-8 | 防止除零误差。 |
| weight_decay | float | 0.0 | 权重衰减率。 |
| amsgrad | bool | False | 是否启用 AMSGrad 优化。 |
| foreach | bool | False | 是否为每个参数单独计算梯度。 |
| bias_correction | bool | True | 是否启用偏差修正(默认开启)。 |
torch.optim.Adam():创建 Adam 优化器,用于深度学习模型的参数优化。结合动量梯度下降和自适应学习率,提升训练稳定性。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
params | iterable | None | 需要优化的参数(如 model.parameters()) |
lr | float | 1e-3 | 学习率(如 0.001) |
betas | tuple | (0.9, 0.99) | 动量系数(β₁, β₂) |
eps | float | 1e-8 | 梯度裁剪的极小值(防止除零错误) |
weight_decay | float | 0 | 权重衰减系数(正则化) |
SGD():随机梯度下降优化器(Stochastic Gradient Descent)
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| lr | float | 1e-3 | 学习率。 |
| momentum | float | 0 | 动量系数(如 momentum=0.9)。 |
| weight_decay | float | 0 | 权重衰减率。 |
| dampening | float | 0 | 动力衰减系数(用于 SGD with Momentum)。 |
| nesterov | bool | False | 是否启用 Nesterov 动量。 |
| foreach | bool | False | 是否为每个参数单独计算梯度。 |
model.parameters():返回模型中所有可训练参数的迭代器,用于优化器绑定。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| filter | callable | None | 过滤条件函数(如 lambda p: p.requires_grad)。默认返回所有参数。 |
def choose_optimizer(config, model):
optimizer = config["optimizer"]
learning_rate = config["learning_rate"]
if optimizer == "adam":
return Adam(model.parameters(), lr=learning_rate)
elif optimizer == "sgd":
return SGD(model.parameters(), lr=learning_rate)
elif optimizer == "adamw":
return AdamW(model.parameters(), lr=learning_rate)Ⅳ、建立网络模型
torch.LongTensor():PyTorch 中用于创建64 位整数类型张量的函数,适用于需要存储整型数据的场景(如分类标签、索引操作等)
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
data | 任意类型 | 必填 | 输入数据(支持列表、元组、NumPy 数组等),函数会根据数据自动推断类型。 |
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
from torch.optim import Adam, SGD, AdamW
from transformers import BertModel
from transformers import BertConfig
from torch.nn import CrossEntropyLoss, MSELoss
import torch.nn.functional as F
"""
建立网络模型结构
实现sentence level的序列标注
每次只跑一个段落
"""
class TorchModel(nn.Module):
def __init__(self, config):
super(TorchModel, self).__init__()
self.bert_like = BertModel.from_pretrained(config["pretrain_model_path"])
self.dropout = nn.Dropout(self.bert_like.config.hidden_dropout_prob)
self.num_labels = config["num_labels"]
if config["recurrent"] == "lstm":
self.recurrent_layer = nn.LSTM(self.bert_like.config.hidden_size,
self.bert_like.config.hidden_size // 2,
batch_first=True,
bidirectional=True,
num_layers=1
)
elif config["recurrent"] == "gru":
self.recurrent_layer = nn.GRU(self.bert_like.config.hidden_size,
self.bert_like.config.hidden_size // 2,
batch_first=True,
bidirectional=True,
num_layers=1
)
else:
assert False
self.classifier = nn.Linear(self.bert_like.config.hidden_size, config["num_labels"])
self.classifier1 = nn.Linear(self.bert_like.config.hidden_size, config["num_labels"])
self.classifier2 = nn.Linear(self.bert_like.config.hidden_size, config["num_labels"])
self.classifier3 = nn.Linear(self.bert_like.config.hidden_size, config["num_labels"])
self.classifier4 = nn.Linear(self.bert_like.config.hidden_size, config["num_labels"])
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, input_ids=None,
attention_mask=None,
labels=None):
#(num_sentence, sentence_length)
outputs = self.bert_like(
input_ids,
attention_mask=attention_mask,
)
pooled_output = outputs[1]
#(num_sentence, vector_size=768)
pooled_output = self.dropout(pooled_output)
#(num_sentence, vector_size=768) -> (1, num_sentence, vector_size)
recurrent_output, _ = self.recurrent_layer(pooled_output.unsqueeze(0))
#(1, num_sentence, LSTM_HIDDEN_SIZE * 2)
output = self.classifier(recurrent_output.squeeze(0))
if labels is not None:
loss_func = CrossEntropyLoss()
loss = loss_func(output.view(-1, self.num_labels), labels.view(-1))
return loss
else:
return output
def choose_optimizer(config, model):
optimizer = config["optimizer"]
learning_rate = config["learning_rate"]
if optimizer == "adam":
return Adam(model.parameters(), lr=learning_rate)
elif optimizer == "sgd":
return SGD(model.parameters(), lr=learning_rate)
elif optimizer == "adamw":
return AdamW(model.parameters(), lr=learning_rate)
if __name__ == "__main__":
from config import Config
Config["optimizer"] = "adamw"
model = TorchModel(Config)
input_ids = torch.LongTensor([[0,1,2,3,4,100,6,7,8], [0,4,3,2,1,100,8,7,6]])
labels = torch.LongTensor([[1], [0]])
print(model(input_ids, labels=labels))
4.模型效果评估文件 evaluate.py
代码运行流程
开始
├── 导入必要的库
├── 定义 `Evaluator` 类
│ ├── 初始化方法 `__init__`
│ │ ├── 加载配置 `self.config`
│ │ ├── 加载模型 `self.model`
│ │ ├── 加载日志记录器 `self.logger`
│ │ ├── 加载验证数据 `self.valid_data`
│ │ └── 加载分词器 `self.tokenizer`
│ ├── 测试方法 `eval`
│ │ ├── 设置模型为评估模式 `self.model.eval()`
│ │ ├── 初始化统计字典 `self.stats_dict`
│ │ ├── 遍历验证数据批次
│ │ │ ├── 将数据移至 GPU(如果可用)
│ │ │ ├── 获取输入数据 `input_ids` 和 `attention_mask`
│ │ │ ├── 获取真实标签 `label`
│ │ │ ├── 使用模型进行预测 `pred_label`
│ │ │ └── 调用 `write_stats` 记录预测结果
│ │ └── 调用 `show_stats` 显示统计结果
│ ├── 记录统计信息方法 `write_stats`
│ │ ├── 检查预测标签和真实标签的长度是否一致
│ │ ├── 将标签转换为整数列表
│ │ └── 调用 `chuck_acc_stats` 计算准确率
│ ├── 计算准确率方法 `chuck_acc_stats`
│ │ ├── 获取真实标签的块 `gold_spans`
│ │ ├── 获取预测标签的块 `pred_spans`
│ │ ├── 更新统计字典 `self.stats_dict`
│ │ └── 返回统计结果
│ ├── 获取块方法 `get_chucks`
│ │ ├── 初始化块列表 `chucks`
│ │ ├── 遍历标签列表,识别块的起始和结束位置
│ │ └── 返回块列表
│ └── 显示统计信息方法 `show_stats`
│ ├── 计算精确率 `precision_e2e`
│ ├── 计算召回率 `recall_e2e`
│ ├── 计算 F1 分数 `fscore_e2e`
│ └── 打印统计结果
└── 主程序
├── 定义标签列表 `label`
├── 打印标签及其索引
└── 调用 `get_chucks` 方法获取块并打印Ⅰ、评估类初始化
config:包含模型配置的字典(如数据路径、最大序列长度等)
model:预训练模型对象(如BERT、GPT等)
logger:日志记录器,用于跟踪训练过程
valid_data():验证数据集对象,包含处理后的输入张量和标签
tokenizer:分词器对象,用于将文本转换为模型输入格式(如input_ids)
def __init__(self, config, model, logger):
self.config = config
self.model = model
self.logger = logger
self.valid_data = load_data(config["valid_data_path"], config, logger, shuffle=False)
self.tokenizer = self.valid_data.tokenizerⅡ、统计模型效果并展示
① 计算统计预测效果
def write_stats(self, pred_label, label):
assert len(pred_label) == len(label), (pred_label.shape, label.shape)
label = label.squeeze()
pred_label = [int(x) for x in pred_label]
true_label = [int(x) for x in label]
self.chuck_acc_stats(pred_label, true_label)
return② 展示预测效果和准确率
def show_stats(self):
total_pred = self.stats_dict["total_pred"]
total_gold = self.stats_dict["total_gold"]
p = self.stats_dict["p"]
precision_e2e = p * 1.0 / total_pred * 100
recall_e2e = p * 1.0 / total_gold * 100
fscore_e2e = 2.0 * precision_e2e * recall_e2e / (precision_e2e + recall_e2e)
self.logger.info("Precision: %f\tRecall: %f\tF1 score: %f"%(precision_e2e, recall_e2e, fscore_e2e))
self.logger.info("--------------------")
return
Ⅲ、模型效果测试
write_stats():计算统计预测效果
show_stats():展示预测效果和准确率
logger.info():用于记录日志信息,通常用于调试或记录程序运行状态。
| 参数名 | 类型 | 说明 |
|---|---|---|
msg | str | 要记录的日志信息。 |
*args | tuple | 用于格式化日志信息的参数。 |
**kwargs | dict | 额外的关键字参数,如 exc_info、stack_info 等。 |
model.eval():将模型设置为评估模式,关闭 Dropout 和 BatchNorm 等训练时的特定行为
defaultdict():创建一个字典,当访问不存在的键时,返回一个默认值
| 参数名 | 类型 | 说明 |
|---|---|---|
default_factory | callable | 用于生成默认值的函数,如 list、int 等。 |
*args | tuple | 传递给字典构造函数的参数。 |
**kwargs | dict | 传递给字典构造函数的关键字参数。 |
enumerate():将一个可迭代对象组合为索引序列,返回索引和对应的值
| 参数名 | 类型 | 说明 |
|---|---|---|
iterable | iterable | 要遍历的可迭代对象。 |
start | int | 索引的起始值,默认为 0。 |
torch.cuda.is_available():检查当前是否有可用的 GPU
cuda():将张量或模型移动到 GPU 上
| 参数名 | 类型 | 说明 |
|---|---|---|
device | int 或 torch.device | 目标 GPU 设备编号或设备对象。 |
torch.no_grad():禁用梯度计算,减少内存消耗并加速计算
torch.argmax():返回指定维度上最大值的索引
| 参数名 | 类型 | 说明 |
|---|---|---|
input | Tensor | 输入张量。 |
dim | int | 指定的维度。 |
keepdim | bool | 是否保持输出张量的维度,默认为 False。 |
def eval(self, epoch):
self.logger.info("开始测试第%d轮模型效果:" % epoch)
self.model.eval()
self.stats_dict = defaultdict(int) # 用于存储测试结果
for index, batch_data in enumerate(self.valid_data):
if torch.cuda.is_available():
batch_data = [d.cuda() for d in batch_data]
input_ids, attention_mask, label = batch_data
with torch.no_grad():
pred_label = self.model(input_ids, attention_mask)
pred_label = torch.argmax(pred_label, -1)
self.write_stats(pred_label, label)
self.show_stats()
returnⅣ、完整代码
# -*- coding: utf-8 -*-
import torch
import collections
import io
import json
import six
import sys
import argparse
from loader import load_data
from collections import defaultdict, OrderedDict
"""
模型效果测试
"""
class Evaluator:
def __init__(self, config, model, logger):
self.config = config
self.model = model
self.logger = logger
self.valid_data = load_data(config["valid_data_path"], config, logger, shuffle=False)
self.tokenizer = self.valid_data.tokenizer
def eval(self, epoch):
self.logger.info("开始测试第%d轮模型效果:" % epoch)
self.model.eval()
self.stats_dict = defaultdict(int) # 用于存储测试结果
for index, batch_data in enumerate(self.valid_data):
if torch.cuda.is_available():
batch_data = [d.cuda() for d in batch_data]
input_ids, attention_mask, label = batch_data
with torch.no_grad():
pred_label = self.model(input_ids, attention_mask)
pred_label = torch.argmax(pred_label, -1)
self.write_stats(pred_label, label)
self.show_stats()
return
def write_stats(self, pred_label, label):
assert len(pred_label) == len(label), (pred_label.shape, label.shape)
label = label.squeeze()
pred_label = [int(x) for x in pred_label]
true_label = [int(x) for x in label]
self.chuck_acc_stats(pred_label, true_label)
return
def chuck_acc_stats(self, pred_label, true_label):
gold_spans = set(self.get_chucks(true_label))
pred_spans = set(self.get_chucks(pred_label))
self.stats_dict["total_gold"] += len(gold_spans)
self.stats_dict["total_pred"] += len(pred_spans)
self.stats_dict["p"] += len(pred_spans.intersection(gold_spans))
return
#@staticmethod
def get_chucks(self, true_label):
chucks = []
start, end = -1, -1
for index, label in enumerate(true_label):
#print(index, label)
if label == 0:
if start == -1:
start = index
end = start + 1
else:
chucks.append((start, end))
start = index
end = start + 1
elif label == 1:
end += 1
elif label == 2:
if end != -1:
chucks.append((start, end))
start, end = -1, -1
else:
assert False
if end != -1:
chucks.append((start, end))
return chucks
def show_stats(self):
total_pred = self.stats_dict["total_pred"]
total_gold = self.stats_dict["total_gold"]
p = self.stats_dict["p"]
precision_e2e = p * 1.0 / total_pred * 100
recall_e2e = p * 1.0 / total_gold * 100
fscore_e2e = 2.0 * precision_e2e * recall_e2e / (precision_e2e + recall_e2e)
self.logger.info("Precision: %f\tRecall: %f\tF1 score: %f"%(precision_e2e, recall_e2e, fscore_e2e))
self.logger.info("--------------------")
return
if __name__ == "__main__":
label = [2, 2, 2, 2, 0, 2, 2, 0, 0, 2, 2, 2, 2, 2, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 2, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 2, 2, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
print([(i, l) for i, l in enumerate(label)])
print(Evaluator.get_chucks(label))
5.模型训练 main.py
代码运行流程
开始
├── 导入必要的库
├── 配置日志记录器
├── 定义主函数 main(config)
│ ├── 创建保存模型的目录
│ ├── 加载模型
│ ├── 检查并启用 GPU
│ │ ├── 如果 GPU 可用,将模型移至 GPU
│ │ └── 如果有多张 GPU,启用多卡训练
│ ├── 加载优化器
│ ├── 加载训练数据
│ ├── 加载效果测试类
│ ├── 训练循环
│ │ ├── 设置模型为训练模式
│ │ ├── 遍历训练数据批次
│ │ │ ├── 将数据移至 GPU(如果可用)
│ │ │ ├── 计算批次损失
│ │ │ ├── 如果使用多卡训练,计算平均损失
│ │ │ ├── 记录损失
│ │ │ ├── 定期打印批次损失
│ │ │ ├── 反向传播
│ │ │ ├── 更新模型参数
│ │ │ └── 清零梯度
│ │ └── 计算并打印平均损失
│ ├── 调用效果测试类进行验证
│ └── 保存模型
└── 调用主函数开始训练
Ⅰ、导入文件
seed:设置随机数种子,确保实验的可重复性
random.seed():设置 Python 内置 random 模块的随机数种子,确保生成的随机数序列可复现
| 参数名 | 类型 | 说明 |
|---|---|---|
seed | int | 随机数种子值。如果未提供,默认使用系统时间作为种子。 |
np.random.seed():设置 NumPy 随机数生成器的种子,确保生成的随机数序列可复现
| 参数名 | 类型 | 说明 |
|---|---|---|
seed | int | 随机数种子值。如果未提供,默认使用系统时间作为种子。 |
torch.manual_seed():设置 PyTorch 中 CPU 的随机数种子,确保生成的随机数序列可复现
| 参数名 | 类型 | 说明 |
|---|---|---|
seed | int | 随机数种子值。取值范围为 [-0x8000000000000000, 0xffffffffffffffff] |
torch.cuda.manual_seed_alll():设置 PyTorch 中所有 GPU 的随机数种子,确保生成的随机数序列可复现
| 参数名 | 类型 | 说明 |
|---|---|---|
seed | int | 随机数种子值。取值范围为 [-0x8000000000000000, 0xffffffffffffffff]。 |
# -*- coding: utf-8 -*-
import torch
import os
import random
import os
import numpy as np
import time
import logging
import json
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
seed = Config["seed"]
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)Ⅱ、日志配置
logger:日志记录器,用于记录训练过程中的信息
log_path:日志文件的路径
handler:日志处理器,用于将日志输出到文件
logging.basicConfig():用于配置日志系统的基本行为,包括日志级别、输出格式、输出位置等。通常在程序入口处调用一次即可
| 参数名 | 类型 | 说明 |
|---|---|---|
filename | str | 指定日志输出的文件名。如果未指定,日志将输出到控制台。 |
filemode | str | 指定日志文件的打开模式,默认为 'a'(追加模式)。 |
format | str | 指定日志输出的格式。常用占位符:%(asctime)s(时间)、%(levelname)s(日志级别)、%(message)s(日志消息)等。 |
datefmt | str | 指定 asctime 的日期/时间格式,与 time.strftime() 的格式相同。 |
level | int | 设置日志的输出级别,默认为 logging.WARNING。 |
stream | IO | 指定日志输出的流对象(如 sys.stderr)。与 filename 互斥。 |
handlers | List[Handler] | 指定要添加到根日志记录器的处理器列表。与 filename 或 stream 互斥。 |
style | str | 指定格式字符串的风格,可选 '%'、'{' 或 '$',默认为 '%'。 |
logging.getLogger():创建或获取一个日志记录器(Logger)对象。日志记录器是分层次的,可以通过名称获取不同的记录器
| 参数名 | 类型 | 说明 |
|---|---|---|
name | str | 日志记录器的名称。如果未指定,返回根日志记录器(root logger) |
time.strftime():将时间元组或 struct_time 对象格式化为可读的字符串。用于自定义日期/时间的显示格式。
| 参数名 | 类型 | 说明 |
|---|---|---|
format | str | 指定日期/时间的格式字符串。常用占位符:%Y(年)、%m(月)、%d(日)、%H(小时)、%M(分钟)、%S(秒)等。 |
t | struct_time | 可选参数,表示要格式化的时间。如果未指定,使用当前时间。 |
logging.FileHandler():将日志记录输出到文件。是日志处理器的一种,用于持久化日志信息
| 参数名 | 类型 | 说明 |
|---|---|---|
filename | str | 日志文件的路径和文件名。 |
mode | str | 文件的打开模式,默认为 'a'(追加模式)。可选 'w'(写入模式)。 |
encoding | str | 文件的编码方式,默认为 None(使用系统默认编码)。 |
delay | bool | 是否延迟文件的创建。默认为 False,即立即创建文件。 |
logging.addHandler():将日志处理器(Handler)添加到日志记录器(Logger)中,使日志记录器能够将日志消息发送到指定的目标位置(如文件、控制台等)
| 参数名 | 类型 | 说明 |
|---|---|---|
handler | Handler | 要添加的日志处理器对象,如 FileHandler、StreamHandler 等。 |
logging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
log_path = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) + ".log"
handler = logging.FileHandler(log_path, encoding="utf-8", mode="w")
logger.addHandler(handler)Ⅲ、主函数 main ⭐
代码运行流程
开始
├── 训练循环
│ ├── 遍历每个 epoch
│ │ ├── 设置模型为训练模式
│ │ ├── 记录当前 epoch 开始
│ │ ├── 初始化损失列表
│ │ ├── 遍历训练数据批次
│ │ │ ├── 清零梯度
│ │ │ ├── 将数据移至 GPU(如果可用)
│ │ │ ├── 获取输入数据和标签
│ │ │ ├── 计算损失
│ │ │ ├── 反向传播
│ │ │ ├── 更新模型参数
│ │ │ ├── 记录批次损失
│ │ │ └── 定期打印批次损失
│ │ └── 计算并打印平均损失
│ └── 调用效果测试类进行验证
└── 结束① 创建模型保存目录
os.path.isdir():检查指定路径是否为存在的目录。返回布尔值(True/False)
| 参数名称 | 类型 | 描述 | 示例 |
|---|---|---|---|
path | str | 需要检查的路径(必须为绝对路径或相对于当前工作目录的有效路径) | os.path.isdir("/home/user") |
os.mkdir():创建单层目录。若父目录不存在或路径已存在,会抛出 FileExistsError 或 OSError
| 参数名 | 类型/可选值 | 描述 | 示例 |
|---|---|---|---|
path | str | 目录路径 | os.mkdir('new_dir') |
mode | int(八进制权限) | 目录权限(Linux 有效,Windows 可能忽略) | mode=0o755 |
dir_fd | int(文件描述符) | 父目录的文件句柄(高级用法,通常无需设置) | dir_fd=parent_fd |
#创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])② 加载训练数据
load_data():从 loader 模块中导入 load_data 函数,用于加载数据集
train_data:从配置文件中加载训练数据
#加载训练数据
train_data = load_data(config["train_data_path"], config)③ 加载模型
TorchModel():从model模块中导入网络模型类
model:根据配置文件加载网络模型
config:配置文件,包含模型训练的各种参数
#加载模型
model = TorchModel(config)④ 检查GPU并迁移模型
model:模型实例,定义模型的结构和参数,用于训练和推理
cuda_flag:标识是否可以使用 GPU
torch.cuda.is_available():检测当前环境是否支持 CUDA(即 GPU 是否可用)
logging.info():配置日志系统的基础参数,如输出格式、文件路径等。仅需在程序初始化时调用一次
| 参数名 | 类型/可选值 | 描述 | 示例 |
|---|---|---|---|
filename | str | 日志文件路径(若设置,日志会写入文件而非控制台) | filename='app.log' |
filemode | 'a'(追加)或 'w'(覆盖) | 文件写入模式(默认 'a') | filemode='w' |
format | str | 日志格式字符串,支持占位符如 %(asctime)s、%(levelname)s | format='%(asctime)s - %(message)s' |
datefmt | str | 时间戳格式(需兼容 time.strftime) | datefmt='%Y-%m-%d %H:%M:%S' |
level | int 或 str | 日志记录的最低级别(如 logging.INFO) | level=logging.DEBUG |
stream | IO 对象 | 指定日志输出流(如 sys.stdout,与 filename 冲突时后者优先) | stream=sys.stderr |
model.cuda():将 PyTorch 模型迁移至 GPU 显存,启用 GPU 加速计算
| 参数名 | 类型/可选值 | 描述 | 示例 |
|---|---|---|---|
device | int 或 torch.device | 目标 GPU 设备编号(如 0 表示第一块 GPU) | model.cuda(device=0) |
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
model = model.cuda()⑤ 加载优化器
optimizer:优化器,用于更新模型参数,根据损失函数的梯度调整模型参数,以最小化损失
choose_optimizer():从 model 模块中导入 choose_optimizer 函数,根据配置文件选择优化器
#加载优化器
optimizer = choose_optimizer(config, model)⑥ 加载评估器
evaluator:效果测试类,用于评估模型性能,在每个训练轮次结束后,评估模型在验证集或测试集上的表现
Evaluator():从 evaluate 模块中导入 Evaluator 类,用于模型评估
#加载效果测试类
evaluator = Evaluator(config, model, logger)⑦ 模型训练主流程
1.Epoch循环控制
epoch:训练轮次
range():Python 内置函数,用于生成一个不可变的整数序列,核心功能是为循环控制提供高效的数值迭代支持
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
start | 整数 | 0 | 序列起始值(包含)。若省略,则默认从 0 开始。例如 range(3) 等价于 range(0,3)。 |
stop | 整数 | 必填 | 序列结束值(不包含)。例如 range(2, 5) 生成 2,3,4 |
step | 整数 | 1 | 步长(正/负): - 正步长需满足 start < stop,否则无输出(如 range(5, 2) 无效)。- 负步长需满足 start > stop,例如 range(5, 0, -1) 生成 5,4,3,2,1**不能为 0**(否则触发 ValueError) |
for epoch in range(config["epoch"]):
epoch += 12.模型设置训练模式
train_loss:计算当前批次的损失值,通常结合损失函数(如交叉熵、均方误差)使用
model.train():设置模型为训练模式,启用Dropout、BatchNorm等层的训练行为
| 参数 | 类型 | 默认值 | 说明 | 示例 |
|---|---|---|---|---|
mode | bool | True | 是否启用训练模式(True)或评估模式(False) | model.train(True) |
logger.info():记录日志信息,输出训练过程中的关键状态
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
msg | str | 是 | 日志消息(支持格式化字符串) | logger.info("Epoch: %d", epoch) |
*args | Any | 否 | 格式化参数(用于%占位符) |
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []3.Batch数据遍历
batch_data:训练数据的一个批次,作为模型的输入,用于计算损失和更新参数
train_data:训练数据集
index:表示当前批次的索引值,从 0 开始,依次递增,直到遍历完所有批次。
enumerate():遍历可迭代对象时返回索引和元素,支持自定义起始索引
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
iterable | Iterable | 是 | 可迭代对象(如列表、生成器) | enumerate(["a", "b"]) |
start | int | 否 | 索引起始值(默认0) | enumerate(data, start=1) |
for index, batch_data in enumerate(train_data):4.梯度清零与设备切换
cuda_flag:标识是否可以使用 GPU
optimizer:优化器,用于更新模型参数,根据损失函数的梯度调整模型参数,以最小化损失
optimizer.zero_grad():清空模型参数的梯度,防止梯度累积
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
set_to_none | bool | 否 | 是否将梯度置为None(高效但危险) | optimizer.zero_grad(True) |
cuda():将张量或模型移动到GPU显存,加速计算
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
device | int/str | 否 | 指定GPU设备(如0或"cuda:0") | tensor.cuda(device=0) |
non_blocking | bool | 否 | 是否异步传输数据(默认False) | tensor.cuda(non_blocking=True) |
optimizer.zero_grad()
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]5.前向传播与损失计算
input_id:输入文本经过分词器(Tokenizer)处理后得到的词汇表中对应单词或子词的索引序列
labels:模型需要预测的目标输出,通常是输入文本对应的标签或目标序列
batch_data:训练数据的一个批次,作为模型的输入,用于计算损失和更新参数
input_id, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
loss = model(input_id, labels)6.反向传播与参数更新
loss.backward():反向传播计算梯度,基于损失值更新模型参数的.grad属性
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
retain_graph | bool | 否 | 是否保留计算图(用于多次反向传播) | loss.backward(retain_graph=True) |
optimizer.step():根据梯度更新模型参数,执行优化算法(如SGD、Adam)
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
closure | Callable | 否 | 重新计算损失的闭包函数(如LBFGS) | optimizer.step(closure) |
loss.backward()
optimizer.step()⑦ 损失记录与日志输出
index:表示当前批次的索引值,从 0 开始,依次递增,直到遍历完所有批次。
train_loss:当前训练轮次的损失值列表
logger:日志记录器,用于记录训练过程中的信息
evaluator:效果测试类,用于评估模型性能,在每个训练轮次结束后,评估模型在验证集或测试集上的表现
epoch:训练轮次
列表.append():在列表末尾添加元素,直接修改原列表
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
object | Any | 是 | 要添加到列表末尾的元素 | train_loss.append(loss.item()) |
item(): Python 中一个非内置但自定义实现的辅助函数,主要用于从可迭代对象(如列表、元组、字符串等)中按需提取元素
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
iterable | 可迭代对象 | 必填 | 需要提取元素的对象(如列表、元组、字符串等)。 |
index | 整数 | None | 可选参数,指定元素的索引位置。若未提供,默认返回第一个元素。 |
int():将字符串或浮点数转换为整数,支持进制转换
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
x | str/float | 是 | 待转换的值(如字符串或浮点数) | int("10", base=2)(输出2进制10=2) |
base | int | 否 | 进制(默认10) |
len():返回对象(如列表、字符串)的长度或元素个数
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
obj | Sequence/Collection | 是 | 可计算长度的对象(如列表、字符串) | len([1, 2, 3])(返回3) |
np.mean(): 计算数组或矩阵中元素的算术平均值。
| 参数名 | 类型 | 说明 |
|---|---|---|
a | array_like | 输入数组或矩阵,包含需要计算平均值的元素。 |
axis | int 或 tuple of int | 可选参数,指定沿哪个轴计算平均值。默认值为 None,表示计算所有元素的平均值。 |
dtype | data-type | 可选参数,指定计算平均值时使用的数据类型。默认值为 float64。 |
out | ndarray | 可选参数,指定输出数组,用于存储计算结果。默认值为 None。 |
keepdims | bool | 可选参数,如果为 True,则保留被缩减的维度。默认值为 False。 |
where | array_like | 可选参数,指定哪些元素参与计算。默认值为 None。 |
logger.info():记录日志信息,输出训练过程中的关键状态
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
msg | str | 是 | 日志消息(支持格式化字符串) | logger.info("Epoch: %d", epoch) |
*args | Any | 否 | 格式化参数(用于%占位符) |
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)
logger.info("epoch average loss: %f" % np.mean(train_loss))
evaluator.eval(epoch)⑧ 完整训练代码
#训练
for epoch in range(config["epoch"]):
epoch += 1
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):
optimizer.zero_grad()
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
input_id, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
loss = model(input_id, labels)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)
logger.info("epoch average loss: %f" % np.mean(train_loss))
evaluator.eval(epoch)⑨ 模型保存
model:训练好的模型对象
model_path:表示模型保存的文件路径
train_data:用于训练的数据集
epoch:当前的训练轮次
model.state_dict():返回一个包含模型所有参数的字典(state_dict)。这个字典保存了模型每一层的权重和偏置,但不包括模型的结构。
os.path.join(): Python 中用于跨平台路径拼接的核心函数
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
path | 字符串 | 必填 | 起始路径组件(可为相对或绝对路径)。示例:"data"。 |
*paths | 可变字符串参数 | 无 | 多个路径组件,按顺序拼接。若包含绝对路径,则重置起始点 |
torch.save():PyTorch 中用于保存模型、张量、字典等对象的函数。它将对象序列化并保存到文件中,以便后续加载和使用。
| 参数名 | 类型 | 说明 |
|---|---|---|
obj | object | 要保存的对象,可以是模型、张量、字典等。 |
f | Union[str, PathLike, BinaryIO, IO[bytes]] | 保存的目标文件路径或文件对象。可以是文件路径字符串、文件对象或 torch.ByteIO 对象。 |
pickle_module | Any | 用于序列化元数据和对象的模块,默认为 pickle。 |
pickle_protocol | int | 指定序列化协议版本,默认为 DEFAULT_PROTOCOL。 |
_use_new_zipfile_serialization | bool | 是否使用新的基于 zipfile 的文件格式,默认为 True。 |
model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)
torch.save(model.state_dict(), model_path)
return model, train_dataⅤ、调用模型预测
# -*- coding: utf-8 -*-
import torch
import os
import random
import os
import numpy as np
import time
import logging
import json
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
logging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
log_path = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) + ".log"
handler = logging.FileHandler(log_path, encoding="utf-8", mode="w")
logger.addHandler(handler)
"""
模型训练主程序
"""
seed = Config["seed"]
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def main(config):
#创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])
#加载模型
logger.info(json.dumps(config, ensure_ascii=False, indent=2))
model = TorchModel(config)
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
muti_gpu_flag = False
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
device_ids = list(range(config["num_gpus"]))
if len(device_ids) > 1:
logger.info("使用多卡gpu训练")
model = torch.nn.DataParallel(model, device_ids=device_ids)
muti_gpu_flag = True
model = model.cuda()
#加载优化器
optimizer = choose_optimizer(config, model)
# 加载训练数据
train_data = load_data(config["train_data_path"], config, logger)
#加载效果测试类
evaluator = Evaluator(config, model, logger)
#训练
for epoch in range(config["epoch"]):
epoch += 1
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
batch_loss = model(*batch_data)
if muti_gpu_flag:
batch_loss = torch.mean(batch_loss)
train_loss.append(float(batch_loss))
if index % int(len(train_data) / 2) == 0 and index != 0:
logger.info("batch loss %f" % batch_loss)
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
logger.info("epoch average loss: %f" % np.mean(train_loss))
evaluator.eval(epoch)
model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)
torch.save(model.state_dict(), model_path)
return
if __name__ == "__main__":
main(Config)
十、序列标注 —— 实体重叠问题
假如要抽取的实体有标签重叠如何处理?
我周末去了北京博物馆看展览
地点模型 B E
机构模型 B M M M E
句子中的【北京】既是一个地点,也是一个机构的一部分
解决方法一:训练多个模型,对于每种实体使用独立的模型
解决方法二:采用生成式模型做这个任务
十一、事件抽取
通常来讲,我们会定义出很多不同的事件,对于每种事件会有当前事件下的角色(属性)
一般解决事件抽取问题分为两步:先做分类,再做抽取
① 判断事件的类型(文本分类任务) ② 抽取事件的属性(命名实体识别)
十二、优化方式 —— 远程监督
构造更多的训练数据以得到更好的模型效果,对于命名实体识别任务,可以用以下流程构造训练数据
步骤
① 准备一些实体(词表)
② 爬取一份语料(爬取语料中携带了目标实体的语料)
③ 将带实体的语料看作一份标注语料
④ 将标注好的语料送给模型做训练
⑤ 训练好的模型在其他语料上预测出新的实体,然后新的实体迭代重复这个过程