关系数据库设计理论
目录
一、数据依赖——重点
(1)平凡依赖/非平凡函数依赖
(2)完全/部分函数依赖
(3)传递函数依赖
二、范式(NF)
(1)第一范式
(2)第二范式
(3)第三范式
(4)BC范式
三、关系模式的规范化
四、反规范化
关系模式中各个属性之间的相互关联,就是数据依赖
一、数据依赖——重点
函数依赖:通俗讲就是关系R中任意两个元组的X值相同时,Y值也相同,则称X函数决定Y,或者Y函数依赖于X,记为X→Y。(若Y不函数依赖于X,则记为X —//—>Y)。
注意:要是全部属性都相同。
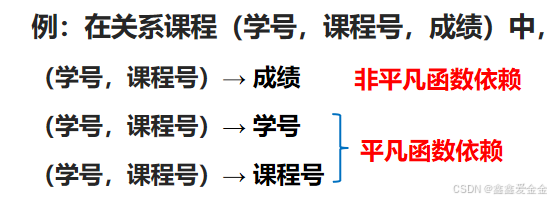
(1)平凡依赖/非平凡函数依赖
X →Y,但Y⊆X,则称X →Y是平凡函数依赖
X →Y,但Y⊈X,则称X →Y是非平凡函数依赖
(2)完全/部分函数依赖
如果X→Y,并且对于X的任何一个真子集Z,Z→Y都不成立,则称Y完全函数依赖于X
如果X→Y, 但对于X的某一个真子集Z, 有Z→Y成立, 则称Y部分函数依赖于X

(3)传递函数依赖
设X,Y,Z是关系R中互不相同的属性集合,如果X→Y,X不函数依赖于Y(Y —//—>X),Y→Z,则称Z传递函数依赖于X,记作X → Z。

函数依赖对关系模式的影响:含有部分函数依赖,传递函数依赖的关系模式不是一个好的模式。规范化理论正是用来改造关系模式,通过分解关系模式来消除其中不合适的数据依赖,以解决插入异常、删除异常、更新异常和数据冗余问题。
关系模式规范化的目的:解决关系模式中存在的数据冗余、插入和删除异常以及更新异常等问题。
基本思想:消除数据依赖中的不合适部分,即模式分解 关系数据库中的关系必须满足一定的规范化要求,对于不同的规范化程度可用范式来衡量。
二、范式(NF)
是符合某一种级别的关系模式的集合,是衡量关系模式规范化程度的标准,达到的关系才是规范化的。
(1)第一范式
如果一个关系模式R的所有属性都是不可分的基本数据项,则R ∈1NF。第一范式是对关系模式最起码的要求。不满足第一范式的数据库不能称为关系数据库。
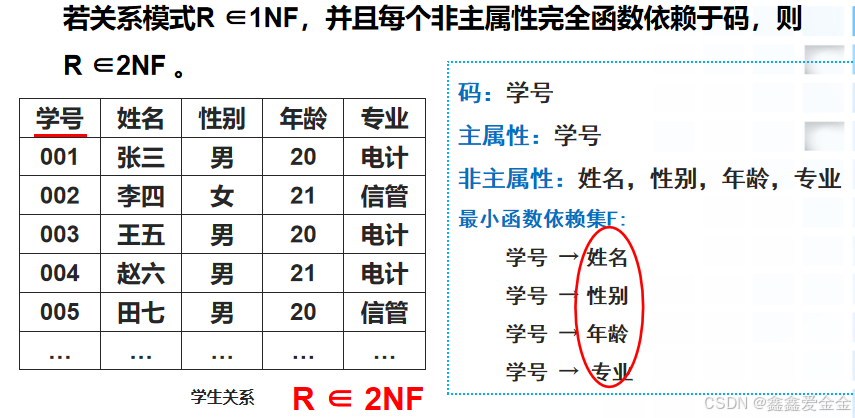
(2)第二范式
若关系模式R ∈1NF,并且每个非主属性完全函数依赖于码,则R ∈2NF 。
在一个关系中,包含在任何候选码中的属性都称为主属性;不包含在任何候选码中的属性称为非主属性。
最小函数依赖集:(1)F中任何一个函数依赖的右边仅含有一个属性(非主属性)。(2)F中的所有函数依赖的左边都没有冗余属性。(3)F中不存在冗余的函数依赖
(3)第三范式
如果关系模式R满足第二范式,并且不存在非主属性传递依赖于码,则称R满足第三范式,记为:R∈3NF。简而言之,第三范式就是属性不依赖于其它非主属性。
推论:(1)如果关系模式R∈1NF,且它的每一个非主属性既不部分依赖、 也不传递依赖于码 ,则R∈3NF。(2)不存在非主属性的关系模式一定为3NF。
注意:3NF只是规定了非主属性对码的依赖关系,而没有限制主属性对码的依赖关系。
(4)BC范式
设关系模式R∈1NF,如果对于R的任意一个函数依赖X→Y,X必为候选码,则R∈BCNF。
三、关系模式的规范化
一个低一级范式的关系模式,通过模式分解可以转换为若干个高一级范式的关系模式的集合,这个过程称为规范化。
优点:
(1)减少了冗余数据,节省了空间
(2)避免了不合理的插入、删除、修改等操作
(3)保持了数据的一致性
缺点:
信息放在不同表中,查询数据时有时需要把多个表连接在一起,增加了操作的难度,降低了查询效率
注意:关系模式的规范化程度并不是越高就越好
四、反规范化
数据库规范化后,为了提高数据检索效率,允许适当的数据冗余(增加冗余列,增加派生列,重新组合表),来降低规范化程度,称为反规范化。反规范化是一种受控的冗余。