线性回归与投影的关系
什么是投影?
向量上的投影
首先什么是投影,如下图
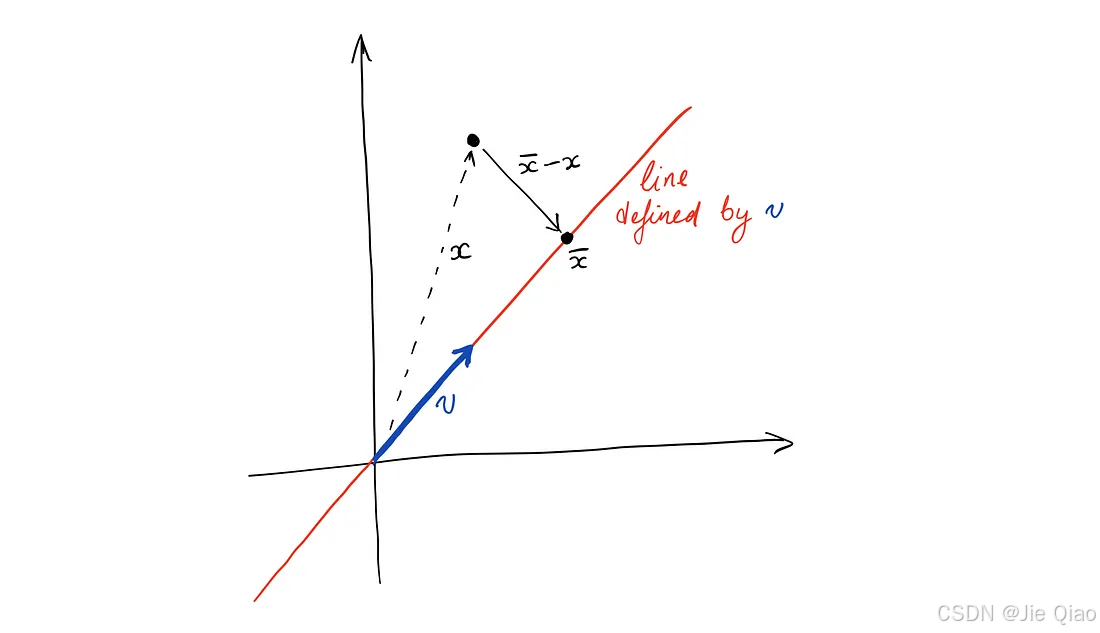
如果我们想将向量x投影到向量v上,那么这个投影
x
‾
\displaystyle \overline{x}
x应该还是在v这个方向上,但只是相差了一个常数倍:
x
‾
=
c
∗
v
\overline{x} =c^{*} v
x=c∗v
而投影点的一个性质就是这个点是在v的方向上,是到x最短的距离:
∥
x
‾
−
x
∥
⩽
∥
c
v
−
x
∥
⟹
∥
c
∗
v
−
x
∥
⩽
∥
c
v
−
x
∥
\| \overline{x} -x\| \leqslant \| cv-x\| \\ \Longrightarrow \| c^{*} v-x\| \leqslant \| cv-x\|
∥x−x∥⩽∥cv−x∥⟹∥c∗v−x∥⩽∥cv−x∥
因此,我们可以通过最优化这个c,来找到这个投影点:
arg
min
c
(
∥
x
‾
−
x
∥
)
=
arg
min
c
(
∑
i
(
x
‾
i
−
x
i
)
2
)
=
arg
min
c
(
∑
i
(
x
‾
i
−
x
i
)
2
)
=
arg
min
c
(
∑
i
(
c
v
i
−
x
i
)
2
)
this is quadratic in
c
,
so minimum lies when
d
d
c
∑
i
(
c
v
i
−
x
i
)
2
=
0
d
d
c
∑
i
(
c
v
i
−
x
i
)
2
=
∑
i
2
v
i
(
c
v
i
−
x
i
)
=
2
(
∑
i
c
v
i
2
−
∑
i
v
i
x
i
)
=
2
(
c
v
T
v
−
v
T
x
)
at minimum,
d
d
c
∑
i
=
2
(
c
v
T
v
−
v
T
x
)
=
0
⇒
v
T
c
∗
v
−
v
T
x
=
0
c
∗
v
T
v
=
v
T
x
c
∗
=
(
v
T
v
)
−
1
v
T
x
x
‾
=
v
c
∗
=
v
(
v
T
v
)
−
1
v
T
x
=
P
x
w
h
e
r
e
P
=
v
(
v
T
v
)
−
1
v
T
\begin{aligned} & \arg\min_{c}( \| \overline{x} -x\| )\\ & =\arg\min_{c}\left(\sqrt{\sum _{i}(\overline{x}_{i} -x_{i})^{2}}\right)\\ & =\arg\min_{c}\left(\sum _{i}(\overline{x}_{i} -x_{i})^{2}\right)\\ & =\arg\min_{c}\left(\sum _{i}( cv_{i} -x_{i})^{2}\right)\\ & \text{ this is quadratic in } c,\text{ so minimum lies when }\frac{d}{dc}\sum _{i}( cv_{i} -x_{i})^{2} =0\\ & \frac{d}{dc}\sum _{i}( cv_{i} -x_{i})^{2} =\sum _{i} 2v_{i}( cv_{i} -x_{i})\\ & =2\left(\sum _{i} cv_{i}^{2} -\sum _{i} v_{i} x_{i}\right)\\ & =2\left( cv^{T} v-v^{T} x\right)\\ & \text{ at minimum, }\frac{d}{dc}\sum _{i} =2\left( cv^{T} v-v^{T} x\right) =0\Rightarrow v^{T} c^{*} v-v^{T} x=0\\ & c^{*} v^{T} v=v^{T} x\\ & c^{*} =(v^{T} v)^{-1} v^{T} x\\ & \overline{x} =vc^{*} =v(v^{T} v)^{-1} v^{T} x=Px\ \mathrm{where} \ P=v(v^{T} v)^{-1} v^{T} \end{aligned}
argcmin(∥x−x∥)=argcmin
i∑(xi−xi)2
=argcmin(i∑(xi−xi)2)=argcmin(i∑(cvi−xi)2) this is quadratic in c, so minimum lies when dcdi∑(cvi−xi)2=0dcdi∑(cvi−xi)2=i∑2vi(cvi−xi)=2(i∑cvi2−i∑vixi)=2(cvTv−vTx) at minimum, dcdi∑=2(cvTv−vTx)=0⇒vTc∗v−vTx=0c∗vTv=vTxc∗=(vTv)−1vTxx=vc∗=v(vTv)−1vTx=Px where P=v(vTv)−1vT
从上面的推导我们可以看出,
x
‾
\displaystyle \overline{x}
x其实是可以通过对x作一个线性变换
P
\displaystyle P
P得到的:
x
‾
=
v
c
∗
=
v
(
v
T
v
)
−
1
v
T
x
=
P
x
w
h
e
r
e
P
=
v
(
v
T
v
)
−
1
v
T
\overline{x} =vc^{*} =v(v^{T} v)^{-1} v^{T} x=Px\ \mathrm{where} \ P=v(v^{T} v)^{-1} v^{T}
x=vc∗=v(vTv)−1vTx=Px where P=v(vTv)−1vT
这个P也称为投影矩阵,而且我们发现这个P跟x是无关的,也就是这个P可以对任意的x作变换从而找到对应的投影向量。
同时,这个投影矩阵还具有性质
P
P
=
v
(
v
T
v
)
−
1
v
T
v
(
v
T
v
)
−
1
v
T
=
v
(
v
T
v
)
−
1
(
v
T
v
)
(
v
T
v
)
−
1
v
T
=
v
(
v
T
v
)
−
1
v
T
=
P
\begin{aligned} PP & =v(v^{T} v)^{-1} v^{T} v(v^{T} v)^{-1} v^{T}\\ & =v(v^{T} v)^{-1}\left( v^{T} v\right) (v^{T} v)^{-1} v^{T}\\ & =v(v^{T} v)^{-1} v^{T} =P \end{aligned}
PP=v(vTv)−1vTv(vTv)−1vT=v(vTv)−1(vTv)(vTv)−1vT=v(vTv)−1vT=P
这意味着这个投影矩阵
P
n
=
P
\displaystyle P^{n} =P
Pn=P,因此他的特征值必然是1或者0。直觉上,为什么会有这个性质呢?其实很简单,因为P就是将x变成v上的投影,那经过一次变换后的向量就已经在v上了,再投影一次其实还是在原地,所以他必然满足
P
2
=
P
\displaystyle P^{2} =P
P2=P。
而且图1所示,向量
x
‾
−
x
\displaystyle \overline{x} -x
x−x与
v
\displaystyle v
v是成一个垂直关系的,因此
P
x
−
x
⊥
v
Px-x\bot v
Px−x⊥v
我们一般称
x
−
P
x
=
(
I
−
P
)
x
=
r
\displaystyle \mathbf{x} -P\mathbf{x} =( I-P)\mathbf{x} =r
x−Px=(I−P)x=r为残差,因此,
I
−
P
\displaystyle I-P
I−P也被称为residual maker matrix。
从垂直这个性质,我们可以用几何的方法来推出同样的P矩阵,首先因为他们垂直,我们有
v
T
(
P
x
−
x
)
=
0
v^{T} (Px-x)=0
vT(Px−x)=0
又因为,
P
x
=
c
v
\displaystyle Px=cv
Px=cv,所以
v
T
(
c
v
−
x
)
=
0
v^{T} (cv-x)=0
vT(cv−x)=0
于是
c
=
(
v
T
v
)
−
1
v
T
x
c=\left( v^{T} v\right)^{-1} v^{T} x
c=(vTv)−1vTx
因此,
P
x
=
v
(
v
T
v
)
−
1
v
T
x
Px=v\left( v^{T} v\right)^{-1} v^{T} x
Px=v(vTv)−1vTx
我们同样推出了P的形式。
子空间上的投影
更一般的,如果 v \displaystyle v v是一个子空间(或者平面),我们可以将问题推广到将向量 x x x 投影到子空间 V V V 上。设 V V V 是一个子空间,其基向量为 { v 1 , v 2 , … , v k } \{v_{1} ,v_{2} ,\dotsc ,v_{k} \} {v1,v2,…,vk},我们需要找到投影矩阵 P P P,使得 P x Px Px 是 x x x 在 V V V 上的投影,且 P x − x Px-x Px−x 与 V V V 中的任意向量垂直。
投影
P
x
Px
Px 应满足:
P
x
∈
V
Px\in V
Px∈V
即
P
x
Px
Px 可以表示为基向量的线性组合:
P
x
=
∑
i
=
1
k
c
i
v
i
Px=\sum _{i=1}^{k} c_{i} v_{i}
Px=i=1∑kcivi
根据垂直条件,
P
x
−
x
Px-x
Px−x 应与
V
V
V 中的任意向量垂直,即:
v
j
T
(
P
x
−
x
)
=
0
∀
j
=
1
,
2
,
…
,
k
v_{j}^{T} (Px-x)=0\ \ \forall j=1,2,\dotsc ,k
vjT(Px−x)=0 ∀j=1,2,…,k
将
P
x
=
∑
i
=
1
k
c
i
v
i
Px=\sum _{i=1}^{k} c_{i} v_{i}
Px=∑i=1kcivi 代入:
v
j
T
(
∑
i
=
1
k
c
i
v
i
−
x
)
=
0
v_{j}^{T}\left(\sum _{i=1}^{k} c_{i} v_{i} -x\right) =0
vjT(i=1∑kcivi−x)=0
展开后得到:
∑
i
=
1
k
c
i
(
v
j
T
v
i
)
−
v
j
T
x
=
0
\sum _{i=1}^{k} c_{i} (v_{j}^{T} v_{i} )-v_{j}^{T} x=0
i=1∑kci(vjTvi)−vjTx=0
列出所有的j,这可以写成矩阵形式:
A
T
A
c
=
A
T
x
A^{T} Ac=A^{T} x
ATAc=ATx
其中,
A
A
A 是子空间
V
V
V 的基向量组成的矩阵,
A
=
[
v
1
,
v
2
,
…
,
v
k
]
A=[v_{1} ,v_{2} ,\dotsc ,v_{k} ]
A=[v1,v2,…,vk],
c
c
c 是系数向量,
c
=
[
c
1
,
c
2
,
…
,
c
k
]
T
c=[c_{1} ,c_{2} ,\dotsc ,c_{k} ]^{T}
c=[c1,c2,…,ck]T。
通过解上述方程,可以得到系数向量
c
c
c:
c
=
(
A
T
A
)
−
1
A
T
x
c=(A^{T} A)^{-1} A^{T} x
c=(ATA)−1ATx
因此,投影
P
x
Px
Px 为:
P
x
=
A
c
=
A
(
A
T
A
)
−
1
A
T
x
Px=Ac=A(A^{T} A)^{-1} A^{T} x
Px=Ac=A(ATA)−1ATx
于是,投影矩阵
P
P
P 为:
P
=
A
(
A
T
A
)
−
1
A
T
P=A(A^{T} A)^{-1} A^{T}
P=A(ATA)−1AT
显然,如果
V
V
V 是单个向量
v
v
v那就会退化为之前的结果,
P
=
v
(
v
T
v
)
−
1
v
T
\displaystyle P=v\left( v^{T} v\right)^{-1} v^{T}
P=v(vTv)−1vT,而如果
V
V
V 是正交基组成的子空间,则
A
T
A
=
I
A^{T} A=I
ATA=I,投影矩阵简化为
P
=
A
A
T
\displaystyle P=AA^{T}
P=AAT。
Column space上的投影
对于更一般的情况,矩阵
A
\displaystyle A
A的每一列并不一定是由基向量组成,这时候,矩阵A的每一列会张成一个column space,此时,向量x在这个column space上的投影为:
P
x
=
A
c
Px=Ac
Px=Ac
这里P是投影矩阵,
A
=
[
v
1
,
v
2
,
…
,
v
k
]
\displaystyle A=[v_{1} ,v_{2} ,\dotsc ,v_{k} ]
A=[v1,v2,…,vk]是任意列组成的矩阵,
c
=
[
c
1
,
c
2
,
…
,
c
k
]
T
\displaystyle c=[c_{1} ,c_{2} ,\dotsc ,c_{k} ]^{T}
c=[c1,c2,…,ck]T是一个向量,
A
c
\displaystyle Ac
Ac表示这些列的任意线性组合,因此
A
c
∈
Column space
(
A
)
\displaystyle Ac\in \text{Column space}( A)
Ac∈Column space(A)是列空间上的元素(因为是由列元素线性组合而成),于是,根据正交性质,
P
x
−
x
\displaystyle Px-x
Px−x应当与
A
\displaystyle A
A的每一列都垂直,因此
A
T
(
P
x
−
x
)
=
0
⟹
A
T
(
A
c
−
x
)
=
0
⟹
c
=
(
A
T
A
)
−
1
A
T
x
\begin{aligned} & A^{T} (Px-x)=0\\ \Longrightarrow & A^{T} (Ac-x)=0\\ \Longrightarrow & c=\left( A^{T} A\right)^{-1} A^{T} x \end{aligned}
⟹⟹AT(Px−x)=0AT(Ac−x)=0c=(ATA)−1ATx
于是,我们有
P
x
=
A
c
=
A
(
A
T
A
)
−
1
A
T
x
Px=Ac=A\left( A^{T} A\right)^{-1} A^{T} x
Px=Ac=A(ATA)−1ATx
因此,
P
=
A
(
A
T
A
)
−
1
A
T
\displaystyle P=A\left( A^{T} A\right)^{-1} A^{T}
P=A(ATA)−1AT,还是同一个东西。
投影性质
根据投影的性质,x在A上的投影到x的距离,一定是A的列空间中所有元素中离x最近的,因此我们有
∥
P
x
−
x
∥
=
∥
A
c
∗
−
x
∥
⩽
∥
A
c
−
x
∥
\| Px-x\| =\| Ac^{*} -x\| \leqslant \| Ac-x\|
∥Px−x∥=∥Ac∗−x∥⩽∥Ac−x∥
线性回归与投影的联系
令
A
=
[
x
1
,
.
.
.
,
x
k
]
∈
R
m
×
k
\mathbf{A} =[ x_{1} ,...,x_{k}] \in \mathbb{R}^{m\times k}
A=[x1,...,xk]∈Rm×k 表示自变量的设计矩阵,包含
m
m
m 个样本和
k
k
k 个特征,向量
y
∈
R
n
\mathbf{y} \in \mathbb{R}^{n}
y∈Rn 表示因变量。线性回归的目标是找到系数向量
w
∈
R
k
\mathbf{w} \in \mathbb{R}^{k}
w∈Rk,使得预测值
A
w
\mathbf{Aw}
Aw 尽可能接近真实值
y
\mathbf{y}
y:
min
w
∥
y
−
A
w
∥
2
.
\min_{\mathbf{w}} \ \| \mathbf{y} -A\mathbf{w} \| ^{2} .
wmin ∥y−Aw∥2.
看到这个式子,我们似乎想要找到一个最优的
w
∗
\displaystyle \mathbf{w}^{*}
w∗,使得
∥
y
−
A
w
∗
∥
2
⩽
∥
y
−
A
w
∥
2
\ \| \mathbf{y} -A\mathbf{w}^{*} \| ^{2} \leqslant \ \| \mathbf{y} -A\mathbf{w} \| ^{2}
∥y−Aw∗∥2⩽ ∥y−Aw∥2
有没有发现很熟悉,从投影的角度,我们其实就是在找
y
\displaystyle \mathbf{y}
y在
A
\displaystyle A
A上的投影,从而
∥
y
−
P
y
∥
2
=
∥
y
−
A
w
∗
∥
2
⩽
∥
y
−
A
w
∥
2
.
\| \mathbf{y} -P\mathbf{y} \| ^{2} =\| \mathbf{y} -A\mathbf{w}^{*} \| ^{2} \leqslant \| \mathbf{y} -A\mathbf{w} \| ^{2} .
∥y−Py∥2=∥y−Aw∗∥2⩽∥y−Aw∥2.
这里
A
w
\displaystyle A\mathbf{w}
Aw就是列空间A上的任意元素(投影必须落在这个空间上),于是,根据我们前面一节的推导,我们有
w
∗
=
(
A
T
A
)
−
1
A
T
y
\mathbf{w}^{*} =\left( A^{T} A\right)^{-1} A^{T}\mathbf{y}
w∗=(ATA)−1ATy
直觉上,如果A满秩,而且有足够多样本的话,那么A就形成了一个k维列空间,而我们目的就是要找到y在这个k维列空间上的投影,也就是找到这个空间上距离y最近的那个点,本质上就是在搜索最优的k维的w,使得残差最小。