【TPAMI 2024】卷积调制空间自注意力SpatialAtt,轻量高效,即插即用!

一、论文信息
论文题目:Conv2Former: A Simple Transformer-Style ConvNet for Visual Recognition
中文题目:Conv2Former: 一种简单的视觉识别用的Transformer风格卷积网络
论文链接:https://arxiv.org/pdf/2211.11943
官方github:https://github.com/HVision-NKU/Conv2Former
所属机构:天津南开大学计算机科学学院,字节跳动(新加坡)
核心速览:本文提出了一种名为Conv2Former的简单Transformer风格的卷积神经网络(ConvNet),用于视觉识别任务。该网络通过简化自注意力机制,利用卷积调制操作来编码空间特征,展示了在图像分类、目标检测和语义分割等任务上优于现有流行ConvNets和视觉Transformer模型的性能。
二、论文概要
Highlight
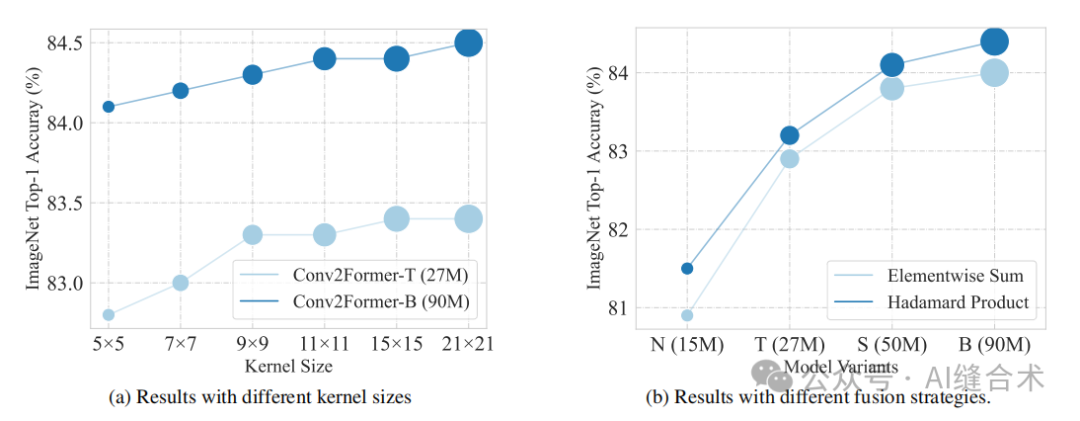
图4. 消融实验。对于Conv2Former-T和Conv2Former-B,当核大小从5×5增加到21×21时,我们可以观察到一致的性能提升。当将哈达玛乘积替换为逐元素求和操作时,我们Conv2Former的四种变体的性能均有所下降。
1. 研究背景:
-
研究问题:如何更高效地利用卷积操作来编码空间特征,以提升视觉识别模型的性能。
-
研究难点:在设计视觉识别模型时,如何平衡模型的性能与计算成本,尤其是在处理高分辨率图像时,自注意力机制的计算成本较高。
-
文献综述:文章回顾了从早期的卷积神经网络(如AlexNet、VGGNet、GoogLeNet)到现代的视觉Transformer(如ViT、DeiT)的发展历程。特别提到了一些工作通过引入大卷积核、高阶空间交互或稀疏卷积核等方法来改进ConvNets的设计。此外,还提到了Vision Transformer在视觉识别任务中的成功应用,以及一些研究通过引入局部依赖性或探索Transformer的扩展能力来提升模型性能。
2. 本文贡献:
-
提出Conv2Former网络架构:Conv2Former是一种新的卷积网络架构,用于视觉识别任务。该网络的核心是卷积调制操作,它通过仅使用卷积和Hadamard乘积来简化自注意力机制。通过比较卷积神经网络(ConvNets)和视觉变换器(Vision Transformers)的设计原则,提出利用卷积调制操作来简化自注意力。
-
卷积调制操作:与自注意力通过矩阵乘法生成注意力矩阵不同,卷积调制操作直接使用k×k深度可分离卷积来产生权重,并通过Hadamard乘积重新加权值表示。这种操作允许每个空间位置与中心点周围k×k区域内的所有像素相关联。
-
网络设计与调整:Conv2Former采用金字塔结构,包含四个阶段,每个阶段具有不同的特征图分辨率。在连续阶段之间使用补丁嵌入块来降低分辨率。研究者们构建了五个Conv2Former变体,分别命名为Conv2Former-N、Conv2Former-T、Conv2Former-S、Conv2Former-B和Conv2Former-L,并提供了它们的简要配置。
-
实验结果:CAS-ViT模型在多个视觉任务上取得了优异的性能,包括图像分类、对象检测、实例分割和语义分割。在ImageNet-1K数据集上,CAS-ViT模型的M和T模型分别以12M和21M参数取得了83.0%/84.1%的top-1准确率。
三、方法
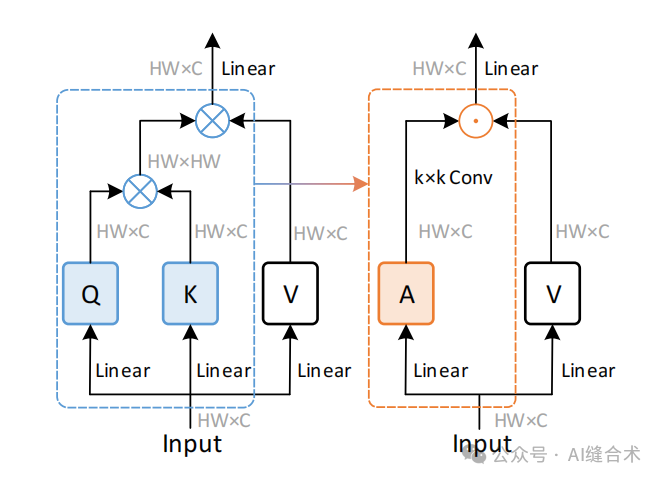
图1. 自注意力机制与提出的卷积调制操作的比较。不是通过查询和键之间的矩阵乘法生成注意力矩阵,而是直接使用k × k深度可分离卷积来产生权重,通过Hadamard乘积(⊙:Hadamard乘积;⊗:矩阵乘法)重新加权值。
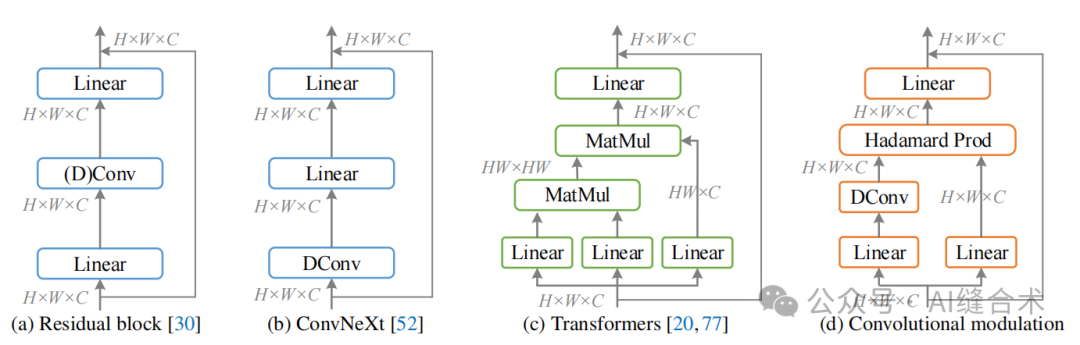
图3. 自注意力和典型卷积块的空间编码过程比较。我们的方法使用深度卷积的卷积特征作为权重来调节值表示,如(d)中右侧线性层所示。
正如论文题目写的那样,卷积调制空间自注意力的实现原理非常简洁,它不是通过Q和K之间的矩阵乘法生成注意力矩阵,而是直接使用k × k深度可分离卷积来产生权重,通过Hadamard乘积(哈达玛积,也叫基本积,即:两个矩阵同阶,对应元素相乘的结果矩阵)生成特征优化结果。网络定义如下面代码所示:
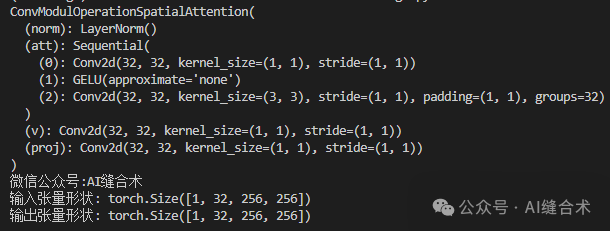
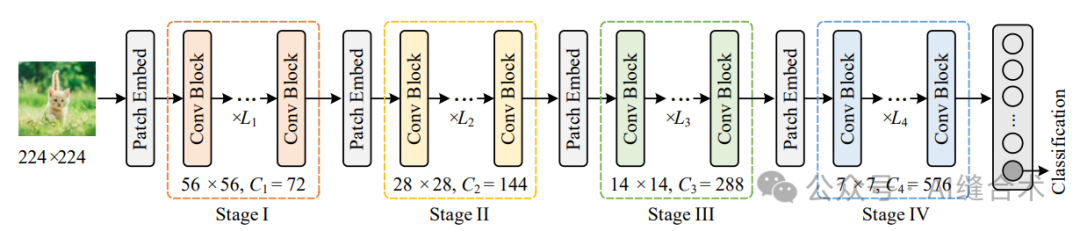
图2. Conv2Former的整体架构。像大多数之前的ConvNets和Swin Transformer一样,我们采用了一个包含四个阶段的金字塔结构。在每个阶段,使用了不同数量的卷积块。这个图展示了所提出的Conv2Former-T的设置,其中{L1, L2, L3, L4} = {3, 3, 12, 3}。
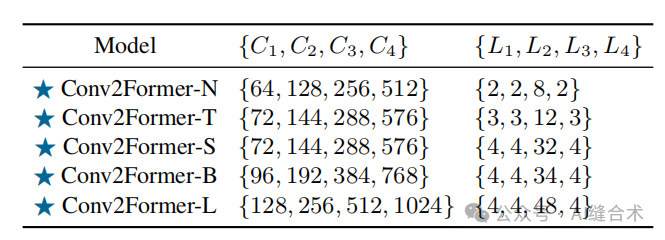
表1. 所提出的Conv2Former的简要配置。实现了5种变体,其参数数量分别为15M、27M、50M、90M和199M。
四、实验分析
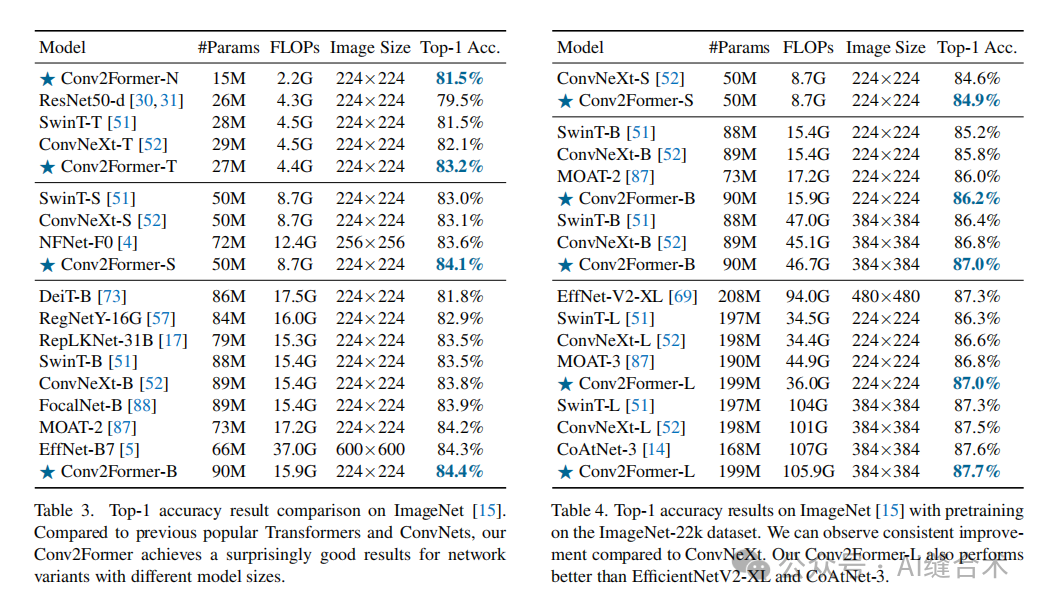
1. 图像分类——ImageNet-1K: Conv2Former在ImageNet-1k数据集上进行了训练,并在ImageNet-1k验证集上报告了结果。对于不同大小的模型,Conv2Former均表现出比现有CNN和Transformer模型更好的性能。例如,Conv2Former-T在参数为27M、FLOPs为4.4G的情况下,达到了83.2%的Top-1准确率,而ConvNeXt-T在相似参数下为82.1%。此外,Conv2Former还在ImageNet-22k数据集上进行了预训练,并在ImageNet-1k数据集上进行了微调,结果显示Conv2Former在模型大小相似的情况下,性能优于ConvNeXt和MOAT等模型。Conv2Former-B在ImageNet-1k数据集上达到了84.4%的Top-1准确率,而EfficientNet-B7在计算量是其两倍的情况下,准确率为84.3%。
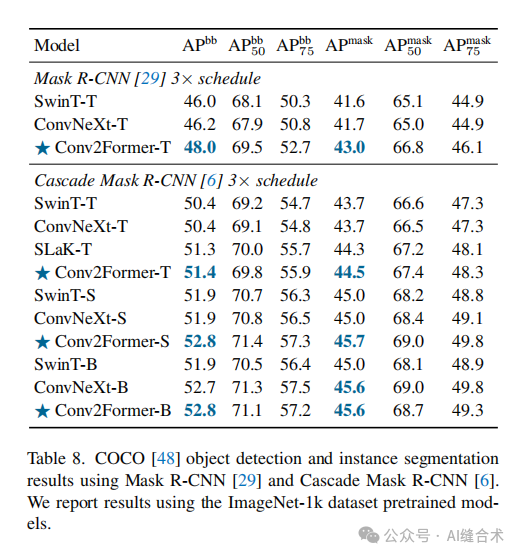
2. 目标检测和实例分割——COCO 2017: 在COCO数据集上,使用Mask R-CNN和Cascade Mask R-CNN作为目标检测器,Conv2Former在对象检测和实例分割任务上也取得了较好的结果。例如,Conv2Former-T在使用Mask R-CNN时,AP(平均精度)为48.0%,而SwinT-T为46.0%。
3. 语义分割——ADE 20K: 在ADE 20k数据集上,Conv 2Former同样在语义分割任务上表现优异。Conv 2Former-T在使用UperNet作为解码器时,mIoU(平均交并比)为48.0%,而SwinT-T为45.8%。

五、代码
https://github.com/AIFengheshu/Plug-play-modules
2025年全网最全即插即用模块,免费分享!包含人工智能全领域(机器学习、深度学习等),适用于图像分类、目标检测、实例分割、语义分割、全景分割、姿态识别、医学图像分割、视频目标分割、图像抠图、图像编辑、单目标跟踪、多目标跟踪、行人重识别、RGBT、图像去噪、去雨、去雾、去阴影、去模糊、超分辨率、去反光、去摩尔纹、图像恢复、图像修复、高光谱图像恢复、图像融合、图像上色、高动态范围成像、视频与图像压缩、3D点云、3D目标检测、3D语义分割、3D姿态识别等各类计算机视觉和图像处理任务,以及自然语言处理、大语言模型、多模态等其他各类人工智能相关任务。持续更新中.....