tongweb信创项目线上业务添堵问题排查
介绍
老项目迁移到TongWeb服务内,另外还需要接入其他的新服务与功能。
TongWeb 是一款国产的应用服务器软件,TongWeb 由东方通科技股份有限公司研发,旨在为企业级应用提供可靠、高效且安全的运行环境,能够承载和支撑各类 Java EE 等相关应用的部署、运行与管理。
生产上状况
TongWeb: 专用机版本
jvm堆:16G;卡顿时大概使用10G多
国产CPU:64核使用率大概74%
线程池:最少50,最高1500/400/200都试过,都可以复现;
http通道:io模式:nio2/nio都可以复现;
用户数:高峰时间,大概300多人:
监控信息看:线程池线程已使用完,使用率100%,感觉是线程不释放。
重启tongweb可以解决卡顿;每天大概8点多可以均可以复现,偶尔不复现
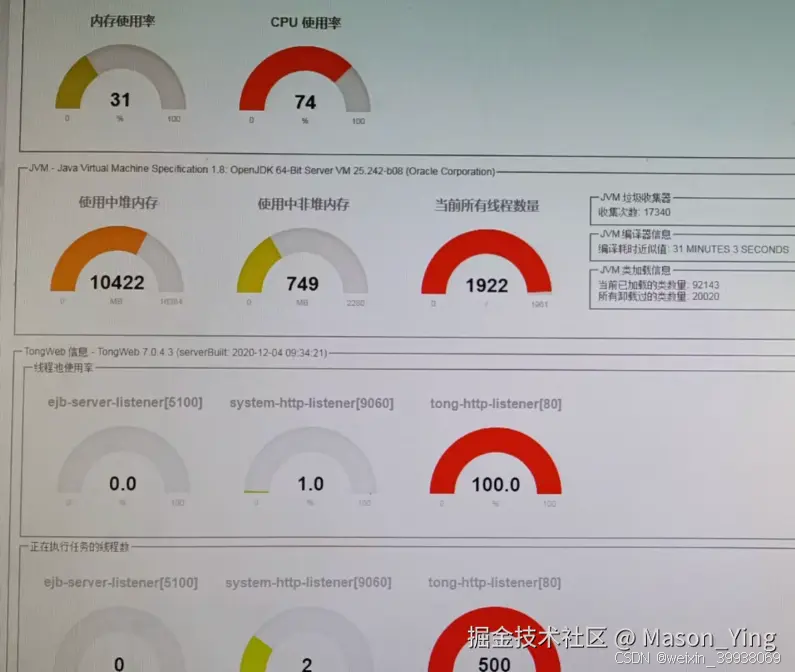
猜想
业务堵塞,导致tongWeb的线程资源耗尽 ,说白了执行业务任务耗时,高峰时期尤为明显
CPU偏高:CPU冲高问题,由于某些代码不考性能,并发一高特别容易出现CPU资源不够,又进一步拖累业务。
排查思路
请注意以下操作一定要在业务堵塞高峰时期执行,请提前写好shell
第一步 排除系统上其他进程,系统资源,磁盘IO等干扰
查看其他进程的CPU,内存,磁盘IO(特别是交换分区),网络IO,命令:top ,free,iostat 等
第二步 网络抓包使用tcpdump抓取pcap包tcpdump -i any tcp port 端口
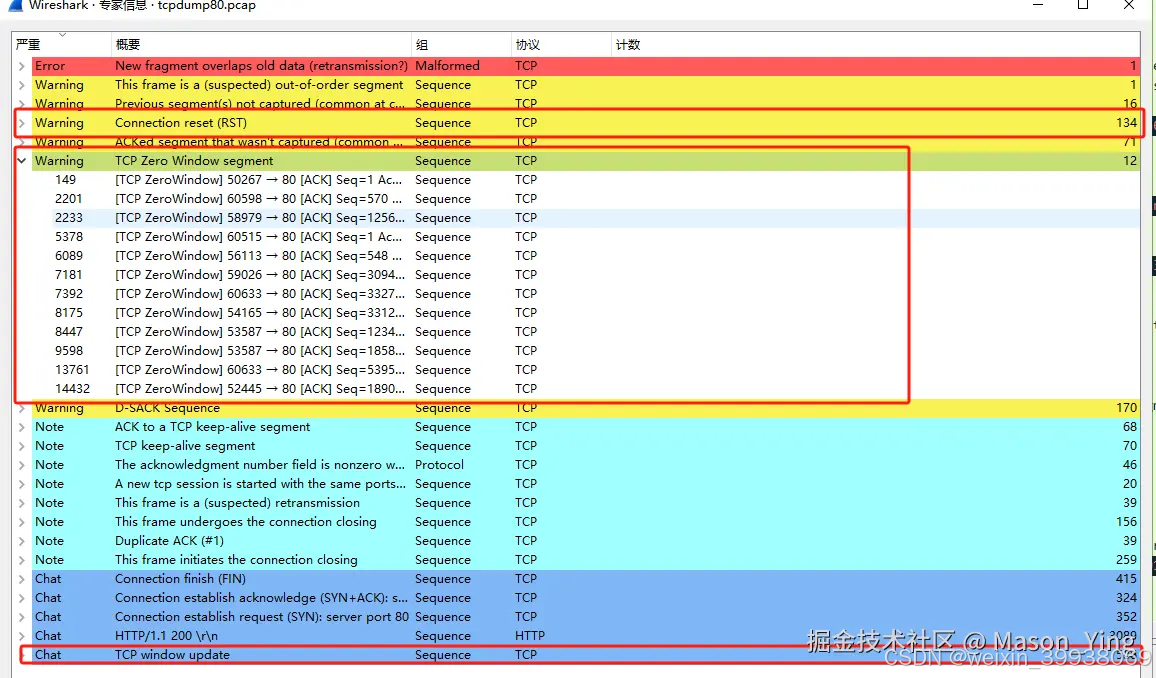
可以明显看到TCP的零窗口堵塞非常之多,是否服务器返回数据字节数偏多,是前端、还是后端,如下图所示,明显该服务不是前后端分离。
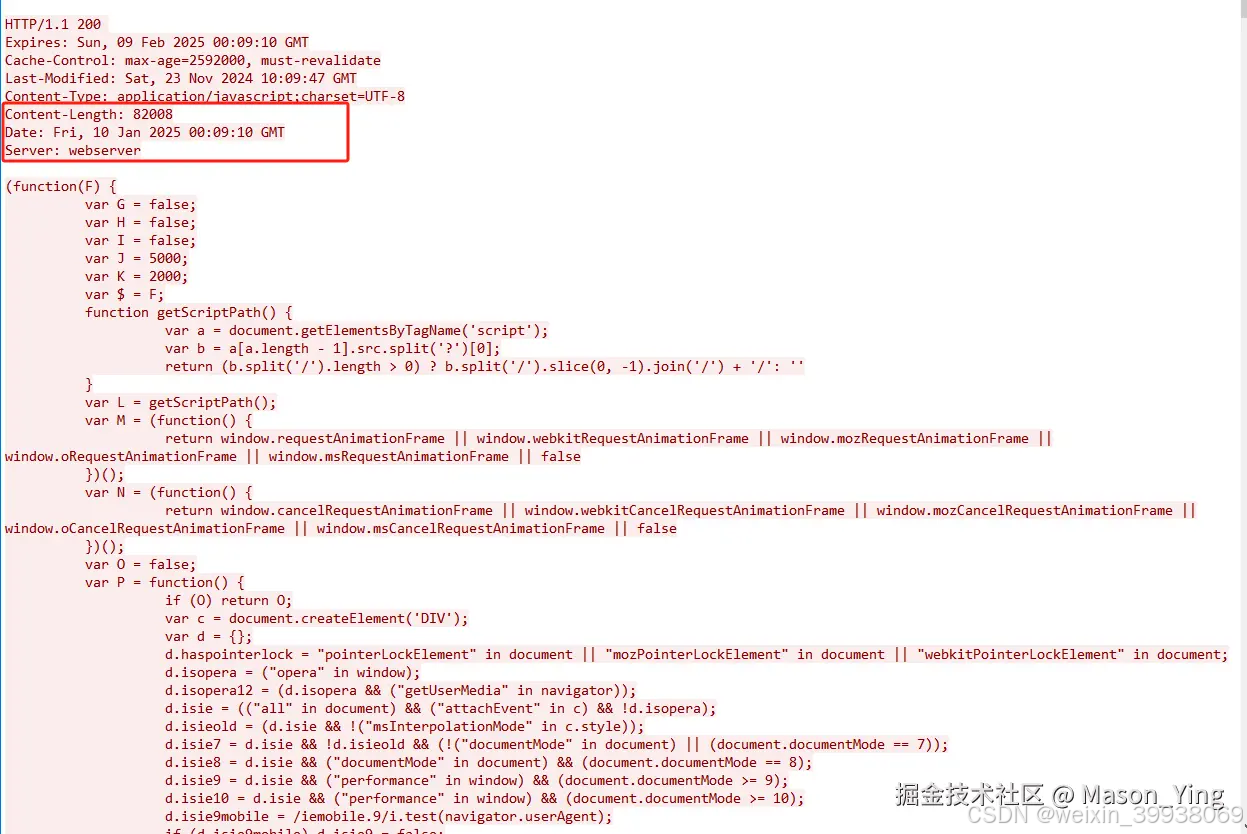
注意,请求到服务返回将近3秒。请一定结合网卡的吞吐量来排查确定问题。如果要求高并发,优化点之一
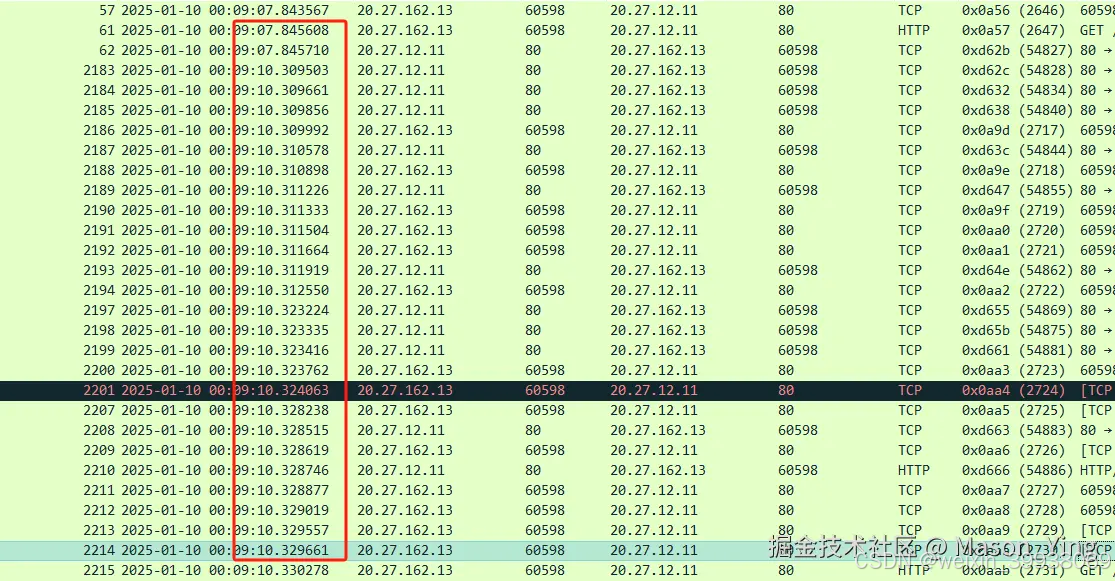
重置连接数也如此之多,更加说明业务被堵塞了
第三步 使用命令netstat抓取tcp链接的详情netstat -nat | grep -i “tcp” | grep -i “:端口” > tcp.txt
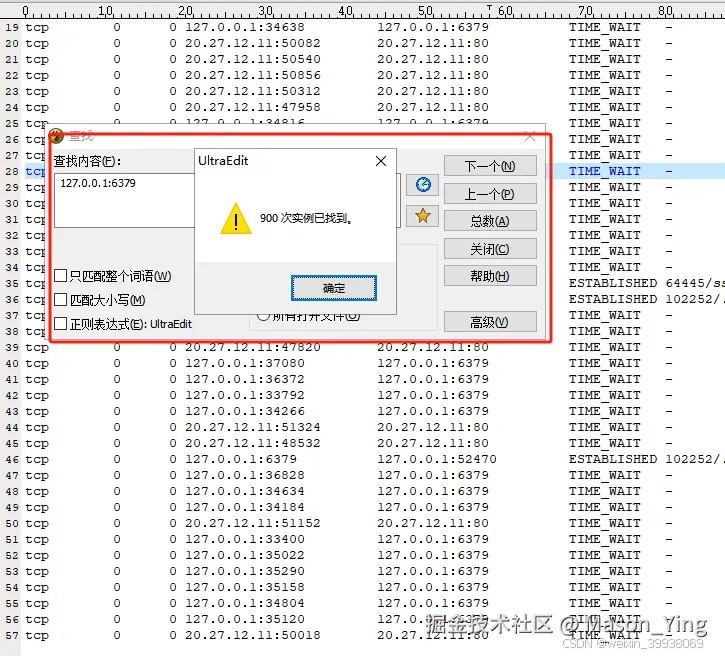
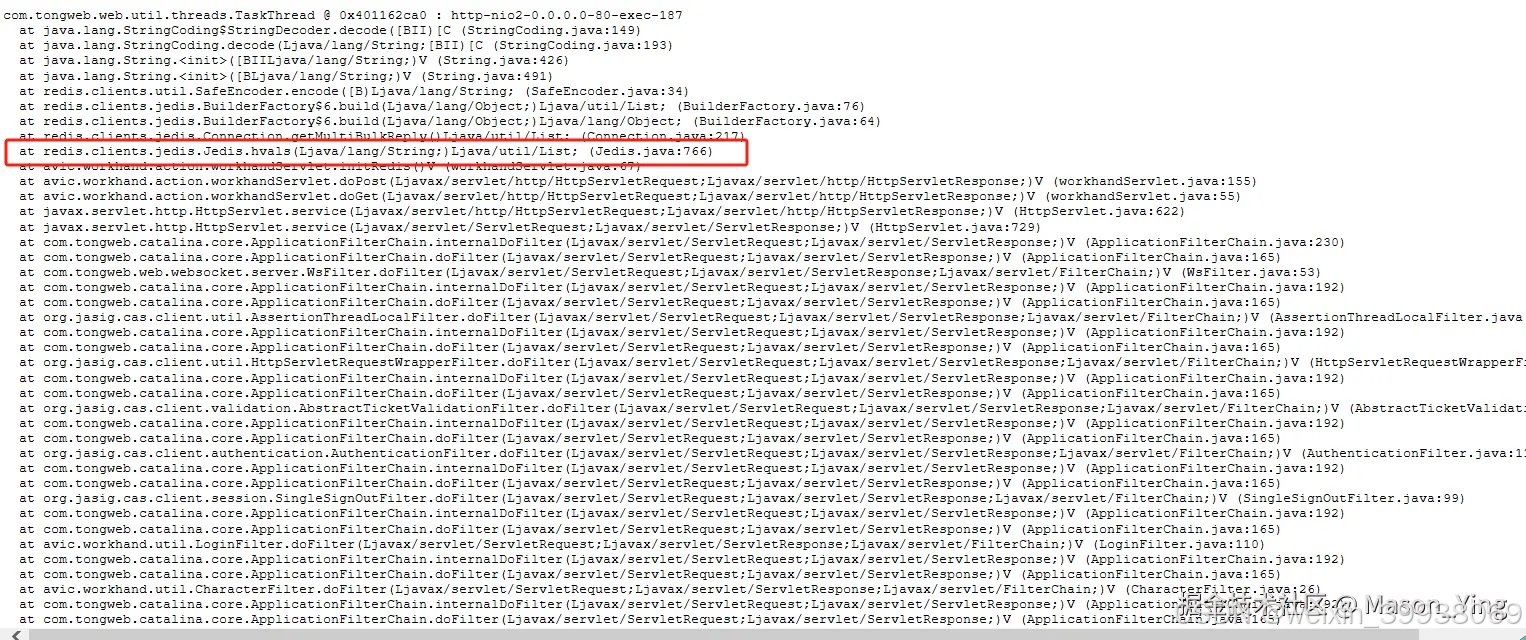
可以看到redis连接数惊人,可想而知写代码的人, redis相关业务代码一定存在什么问题。
业务服务请求的连接数大概470 正常。
第四步 打印GC日志
猜测使用G1算法 整体看下正常。但是GC线程数过大浪费资源。设计GC参数设置不合理这里不过多展开。
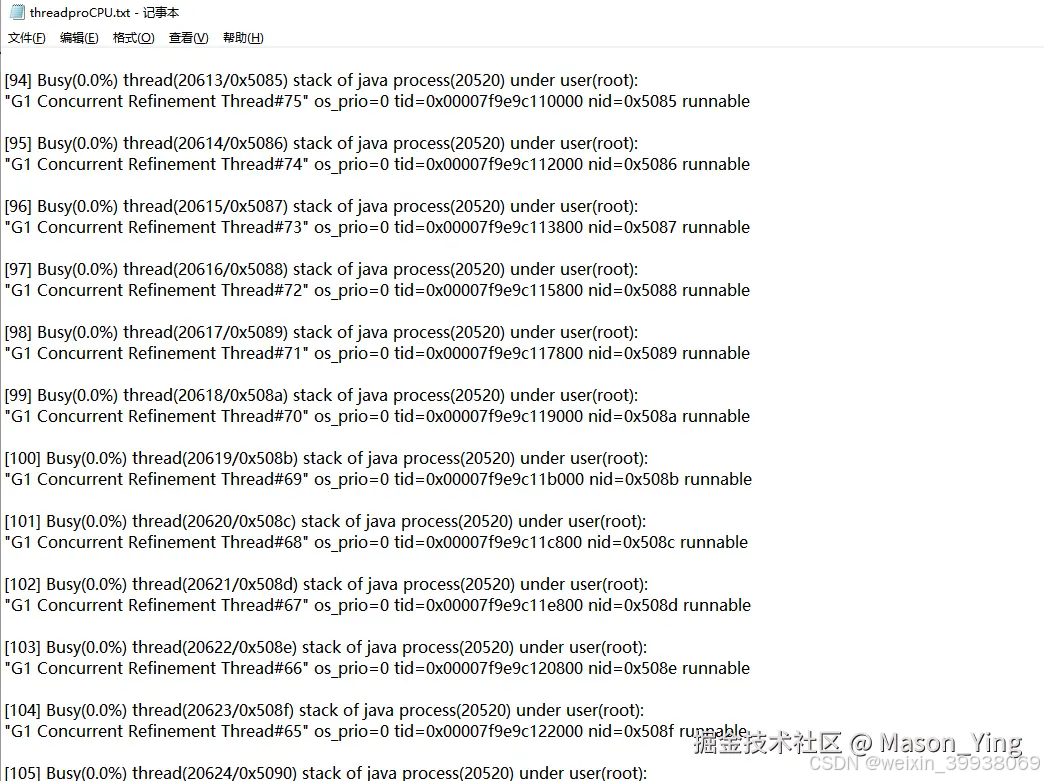
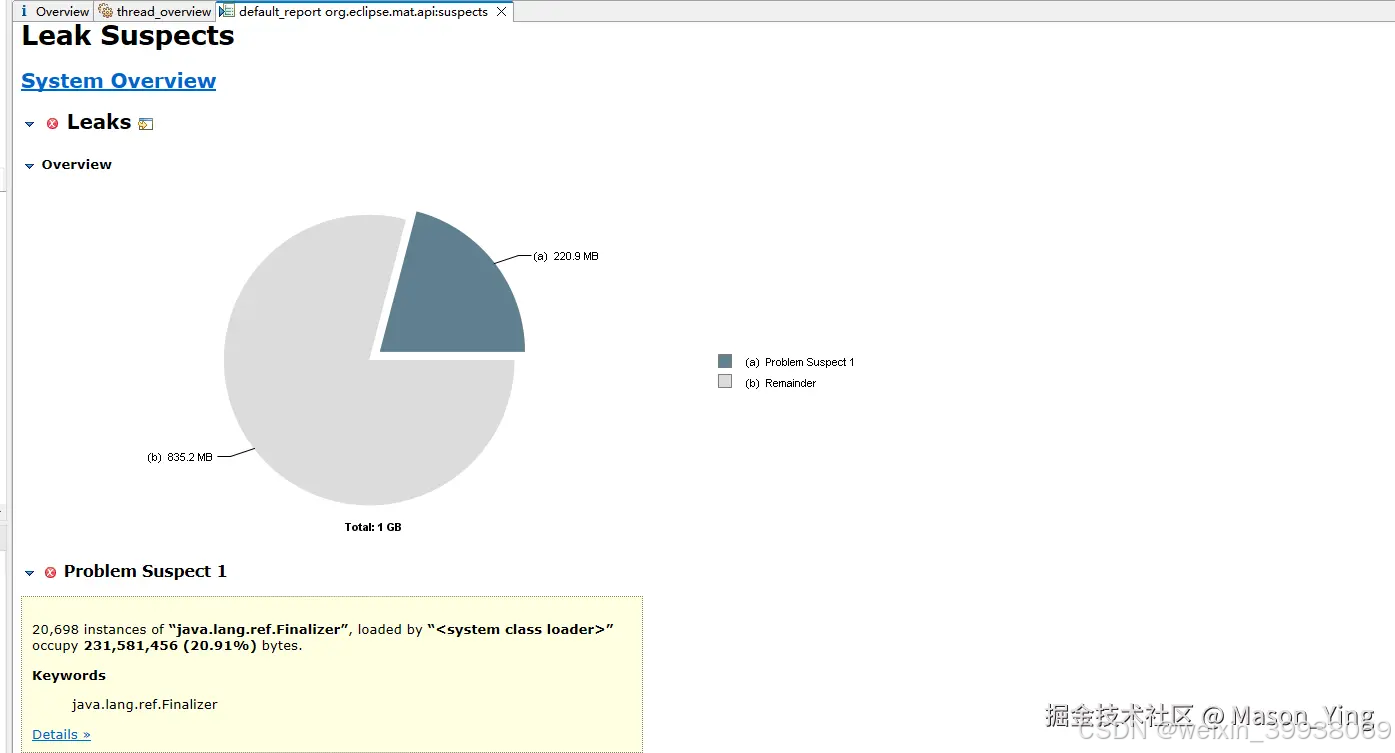
第五步 dump文件,以及jstack打印线程堆栈分析
内存使用没有多大问题,存在内存泄漏风险几乎可以排除
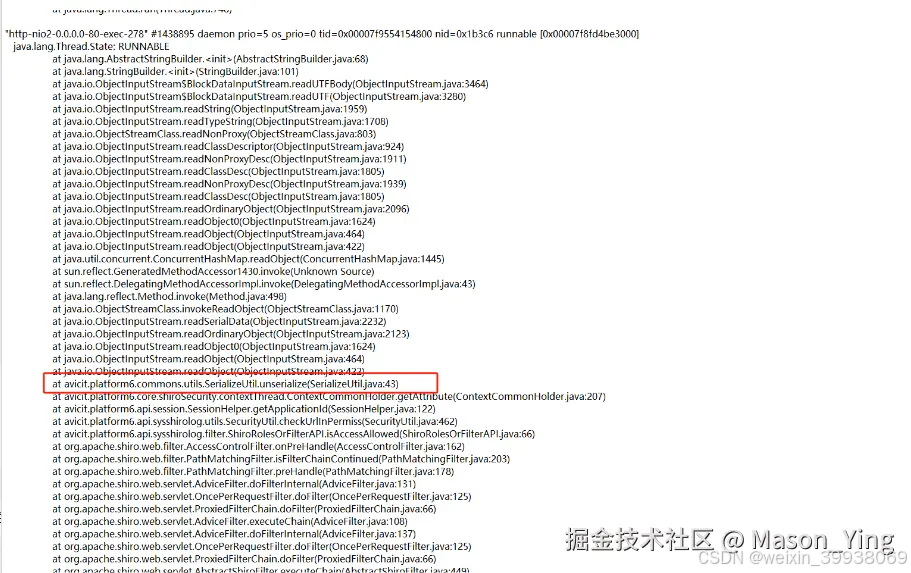
首先分析TongWeb线程
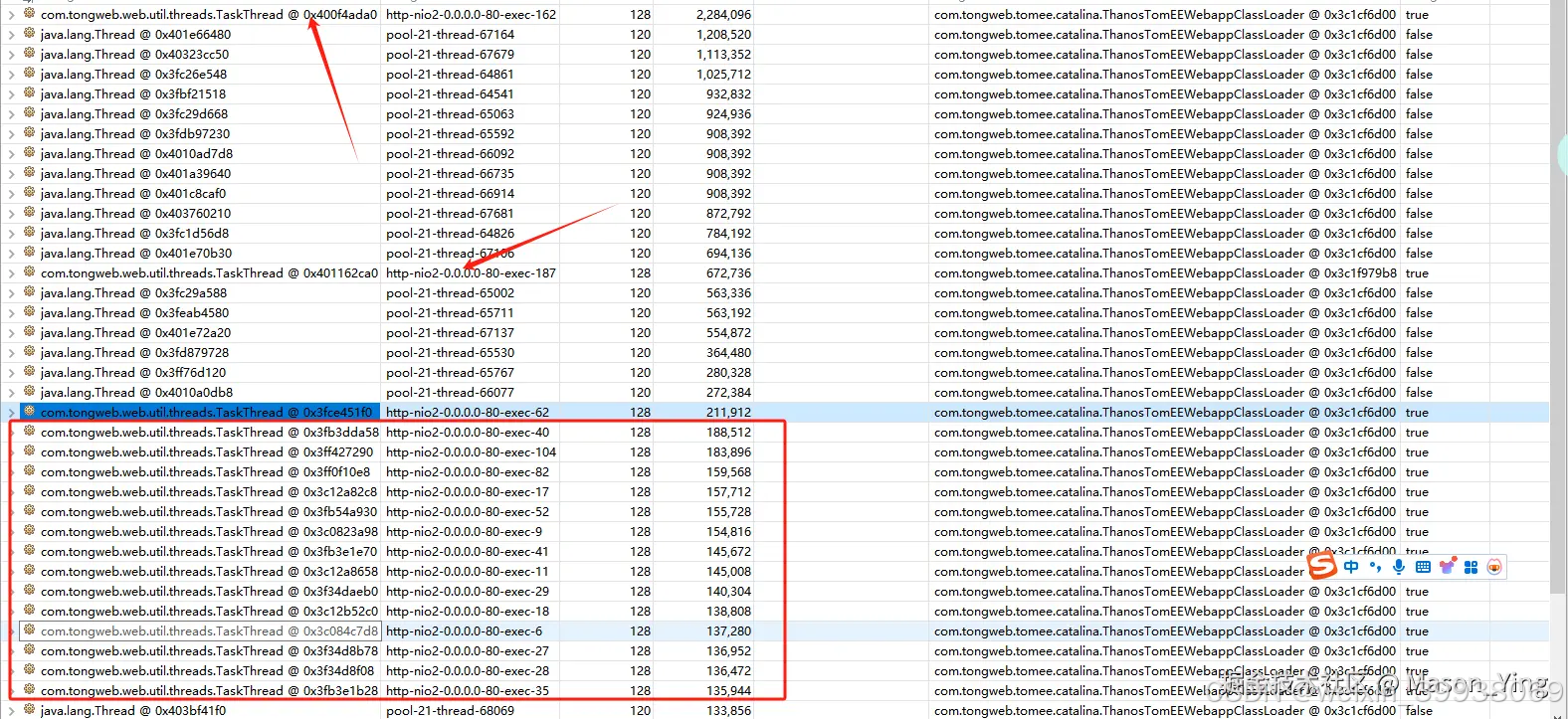
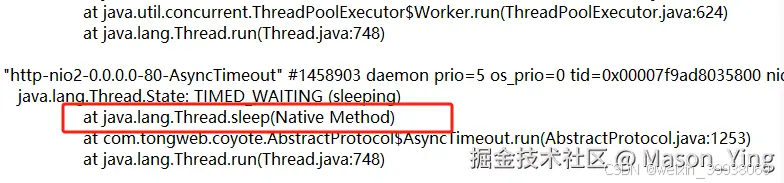
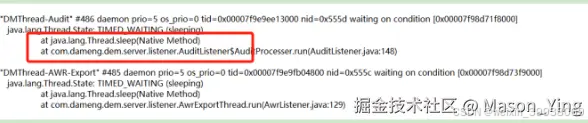
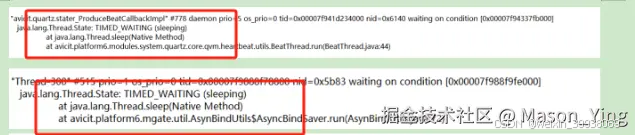
查看大多数线程堆栈线程日志都调用这几个方法,结合业务代码发现在这里,堵塞主要原因,(由于安全没法截取源码代码演示大家看)
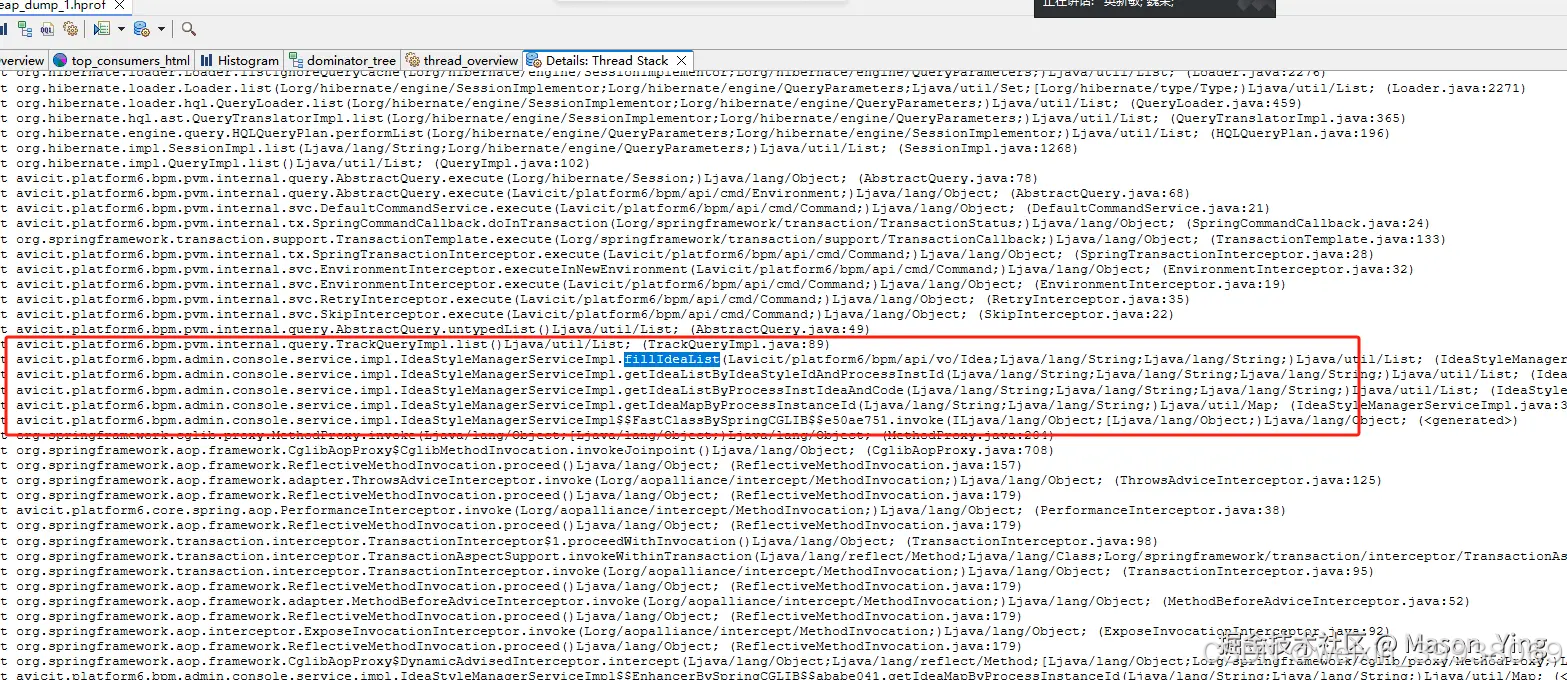
业务逻辑代码逻辑bug漏洞
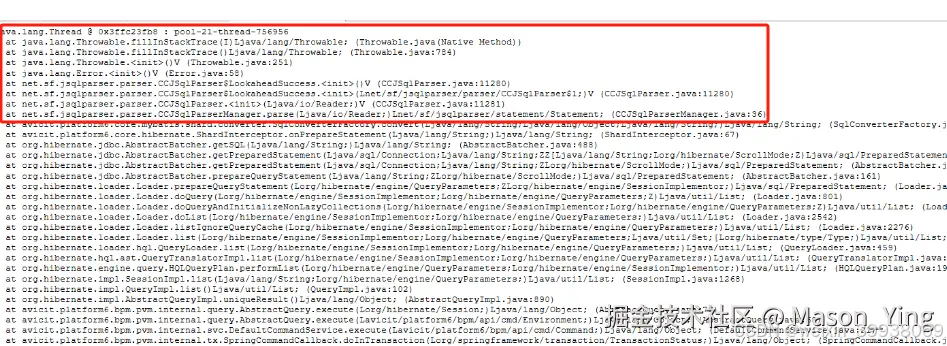
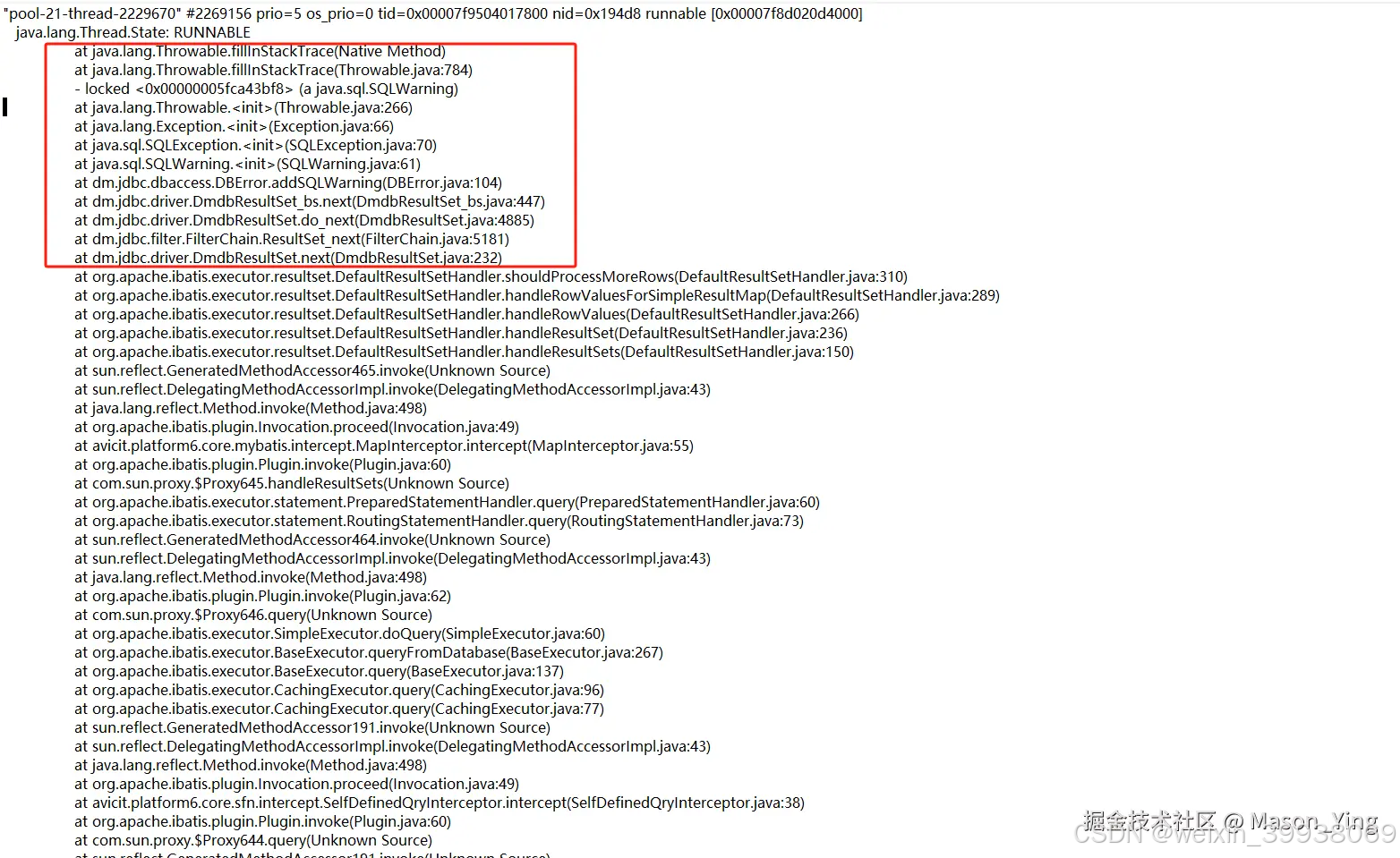
那CPU问题呢?继续查看堆栈线程日志
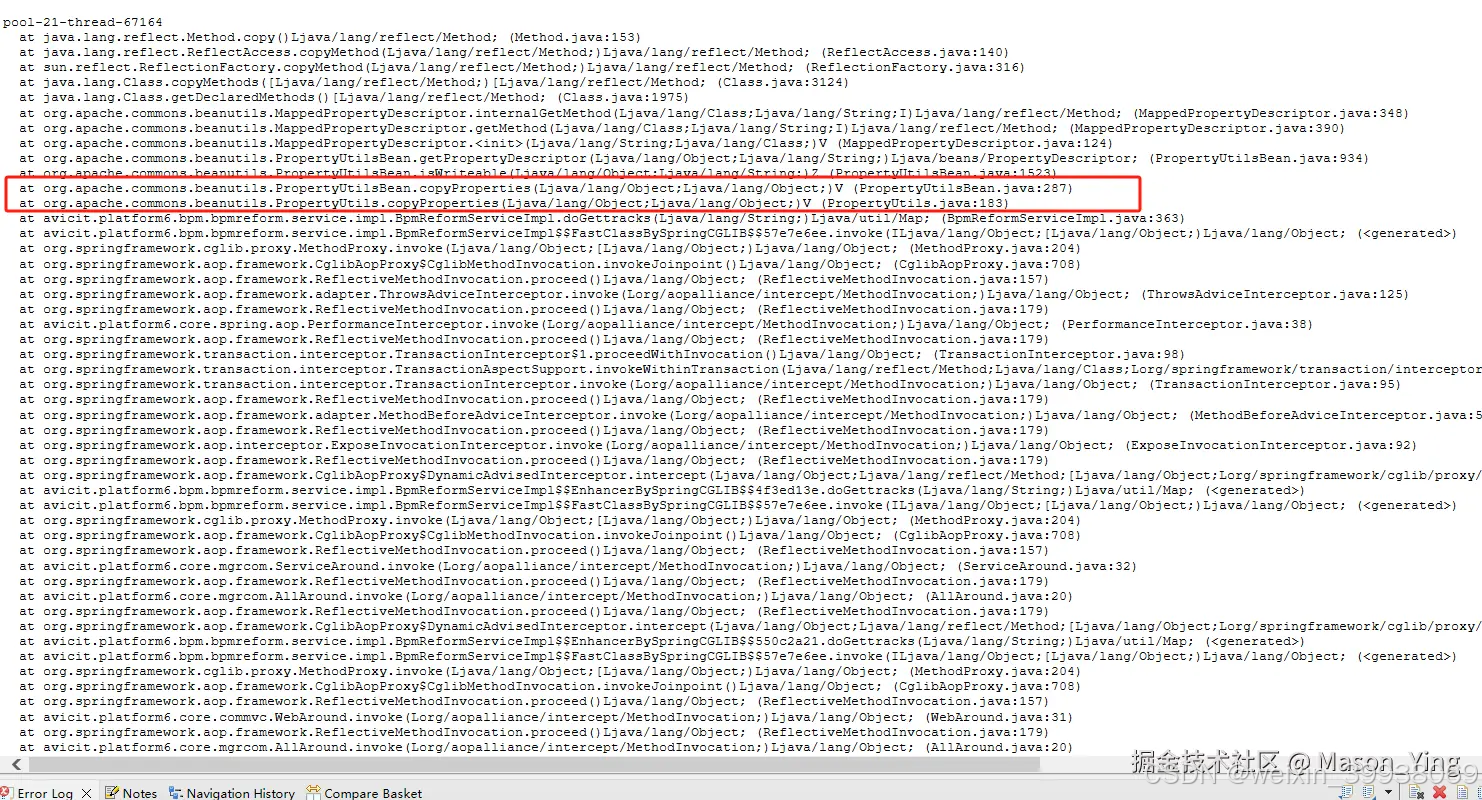
经典的Apache BeanUtils 拷贝对象性能问题
BeanUtils.copyProperties 方法虽然方便,但在性能上并不理想。它使用反射来获取和设置属性,而反射操作是比较慢的。
当需要大量复制对象时,性能影响会变得更加显著
BeanUtils 默认允许对所有属性进行读写,这可能导致意外地修改不应该被修改的字段
如果你的对象中有敏感数据,直接使用 BeanUtils 复制可能会导致数据泄露。
使用 BeanUtils 时,异常处理通常较为粗糙
sleep持有cpu的资源不释放。
redis可能得大key问题,至于内存碎片化要去服务器排查
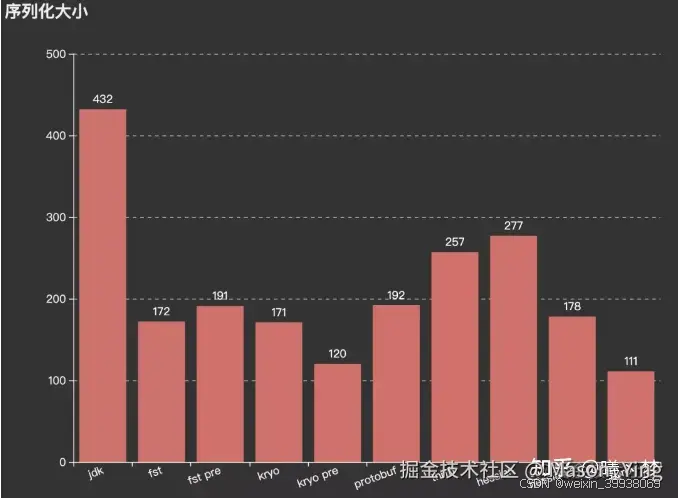
JDK原生序列化问题
1、无法跨语言
这一缺点几乎是致命伤害,对于跨进程的服务调用,通常都需要考虑到不同语言的相互调用时候的兼容性,而这一点对于jdk序列化操作来说却无法做到。这是因为jdk序列化操作时是使用了java语言内部的私有协议,在对其他语言进行反序列化的时候会有严重的阻碍。
2、序列化之后的码流过大
jdk进行序列化编码之后产生的字节数组过大,占用的存储内存空间也较高,这就导致了相应的流在网络传输的时候带宽占用较高,性能相比较为低下的情况
各种序列化技术性能对比
第五步 打印threaID的cpu高于阈值并打印堆栈线程日志
由于安全问题,朋友告诉甲方不允许执行该脚本。(请注意top -Hp 方式排查cpu高的问题,有时候线程一闪而过导致手动铺抓比较难,故使用脚本比较好),具体详情请参考添加链接描述
推荐脚本编写
#!/bin/bash
# 由crontab触发每分钟执行一次,判断CPU使用率大于阈值时触发dump
# 使用方式:
# 把当前文件放到项目中与start.sh相同的目录
# 修改start.sh 在脚本最后加一行,一般是这一行后边 echo "$APP_NAME is up runnig :)"
# echo "* * * * * sh /export/App/bin/cpu-peak-dump.sh" | crontab -
# 可配置项:
# 触发dump的cpu阈值。default 70
# STACK_DUMP_CPU_THRESHOLD=xxx
# 触发dump时列举的线程数(按使用率由高到低排列) default 10
# STACK_DUMP_THREAD_COUNT=xxx
# 配置方式,使用行云分组的环境变量配置即可
# stack log 存放目录 /export/Logs/
# stack log 文件名: jstack_snapshot_$(date +%Y%m%d%H%M%S).log
# 最后,记得配置相应的日志清理策略
# 设置CPU阈值,当CPU使用率达到该阈值时触发线程快照
CPU_THRESHOLD="${STACK_DUMP_CPU_THRESHOLD:-100}"
THREAD_COUNT="${STACK_DUMP_THREAD_COUNT:-30}"
echo "Current CPU_THRESHOLD is $CPU_THRESHOLD"
JAVA_PID=$(pgrep -d, -x java)
echo "Current JAVA_PID is $JAVA_PID"
# 使用top命令获取当前CPU使用率,并提取其中的CPU利用率百分比
CPU_USAGE=$(top -b -n 1 | grep -A10 "PID USER" | grep java | grep "$JAVA_PID" | awk '{print $9}' | cut -d'.' -f1)
echo "Current Java($JAVA_PID) CPU_USAGE :$CPU_USAGE"%
if [ -z "$JAVA_PID" ]; then
echo "No Java process found."
exit 1
fi
# 检查CPU使用率是否超过阈值
if [[ $CPU_USAGE -gt $CPU_THRESHOLD ]]; then
# 使用top命令查找占用CPU最高的前十个线程,并获取它们的信息
TOP_THREADS=$(top -H -b -n 1 -p "$JAVA_PID" | grep -A$THREAD_COUNT 'PID USER' | head -n $THREAD_COUNT | grep -v 'PID')
# 使用jstack捕捉JVM线程快照
# 请将下面的Java进程ID替换为你要监视的Java进程的实际进程ID
JSTACK_OUTPUT=$(/export/servers/jdk1.8.0_191/bin/jstack "$JAVA_PID")
JSTACK_OUTPUT_FILE="/export/Logs/jstack_snapshot_$(date +%Y%m%d%H%M%S).log"
echo "当前JAVA进程ID($JAVA_PID)CPU使用率:$CPU_USAGE"% >>$JSTACK_OUTPUT_FILE
# 获取占用CPU最高的前十个线程的信息,包括线程的PID和堆栈信息,并将它们合并到同一行输出
echo "Top ${THREAD_COUNT} CPU占用线程信息:" >>$JSTACK_OUTPUT_FILE
while read -r THREAD_INFO; do
THREAD_TID=$(echo "$THREAD_INFO" | awk '{print $1}')
THREAD_NID=$(printf "%x\n" $THREAD_TID)
THREAD_STACK=$(echo "$JSTACK_OUTPUT" | sed -n "/nid=0x$THREAD_NID /,/^$/p")
THREAD_CPU_USAGE=$(echo "$THREAD_INFO" | awk '{print $9}')
echo "=======================================================" >>$JSTACK_OUTPUT_FILE
echo "线程TID: $THREAD_TID, THREAD_NID:$THREAD_NID, CPU使用率: $THREAD_CPU_USAGE%" >>$JSTACK_OUTPUT_FILE
echo "$THREAD_STACK" >>$JSTACK_OUTPUT_FILE
done <<<"$TOP_THREADS"
# echo "====all stack as below:====" >>$JSTACK_OUTPUT_FILE
# echo "$JSTACK_OUTPUT" >>$JSTACK_OUTPUT_FILE
echo "捕捉了JVM线程快照并保存到 $JSTACK_OUTPUT_FILE"
fi