徒手打造个人AI Agent:基于DeepSeek-R1+websearch从零构建类Manus深度探索智能体AI-Research
从零构建深度探索Agent
原创不易,转发请备注【评论S源码】
我们将从零开始构建这样一个基于DeepSeek R1的深度研究Agent。
什么是深度研究代理(深度探索Agent)?
该系统能够在预定义的主题上进行深入研究。通常,这包括以下步骤:
-
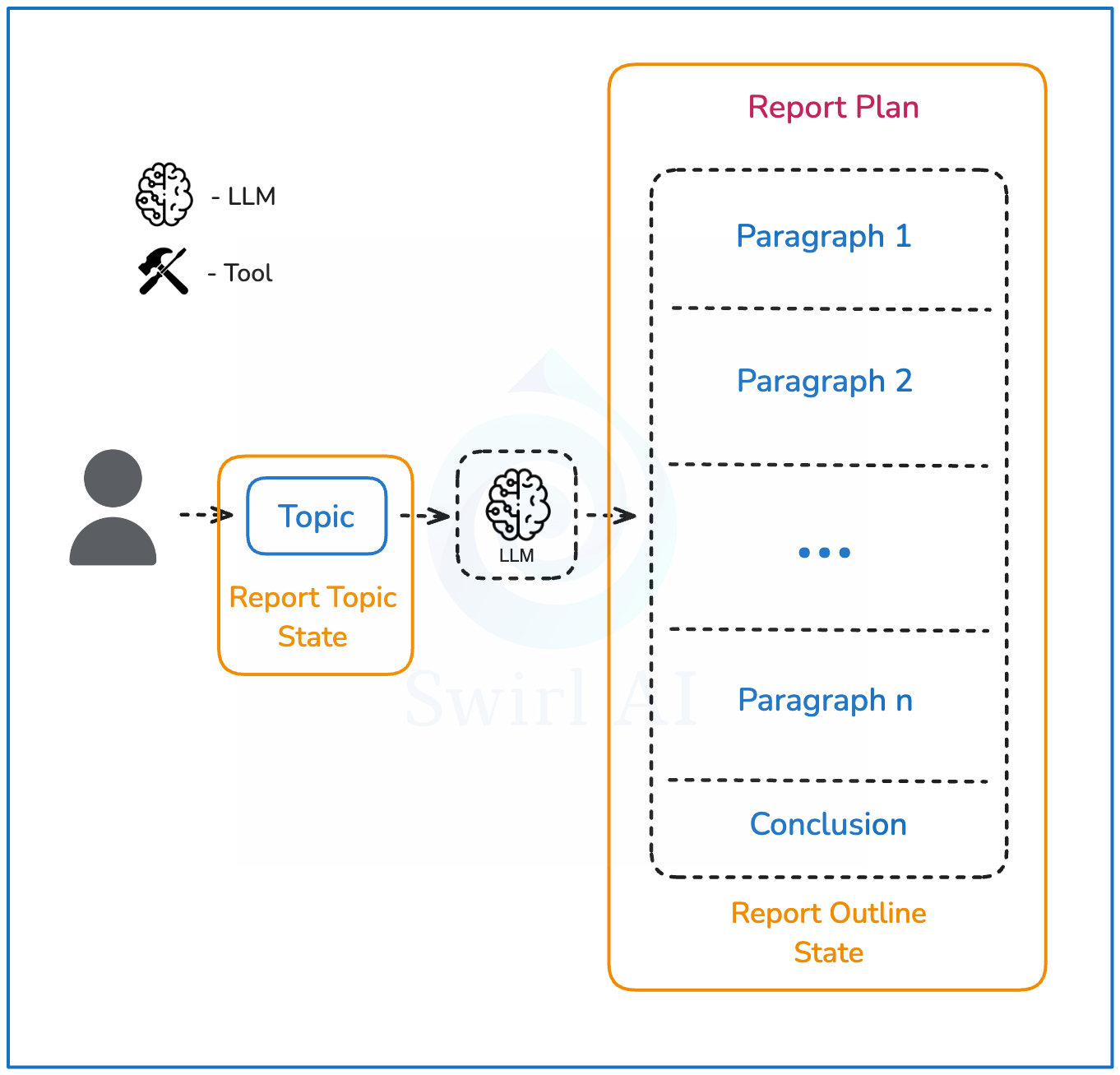
研究计划:这意味着创建一个研究报告大纲,这将成为系统的最终输出。
-
将上述内容拆分为可管理的步骤。
-
对报告的各个部分进行深入研究。针对推理所需的数据,进行全面的分析,并利用网络搜索工具支持分析。
-
反思研究过程中不同步骤生成的数据,并改进结果。
-
总结检索到的数据,并生成最终的研究报告。
今天,我们将实现上述所有步骤,而不使用任何LLM编排框架。
系统拓扑结构
以下是我们将要构建的系统结构图,系统将执行以下步骤:
-
用户提供一个查询或研究主题。
-
LLM将创建最终报告的大纲,目标是不超过一定数量的段落。
-
每个段落描述将分别输入到研究过程中,以生成用于报告构建的全面信息。研究过程的详细描述将在下一节中介绍。
-
所有信息将输入到总结步骤中,构建最终报告,包括结论。
-
报告将以Markdown形式提供给用户。
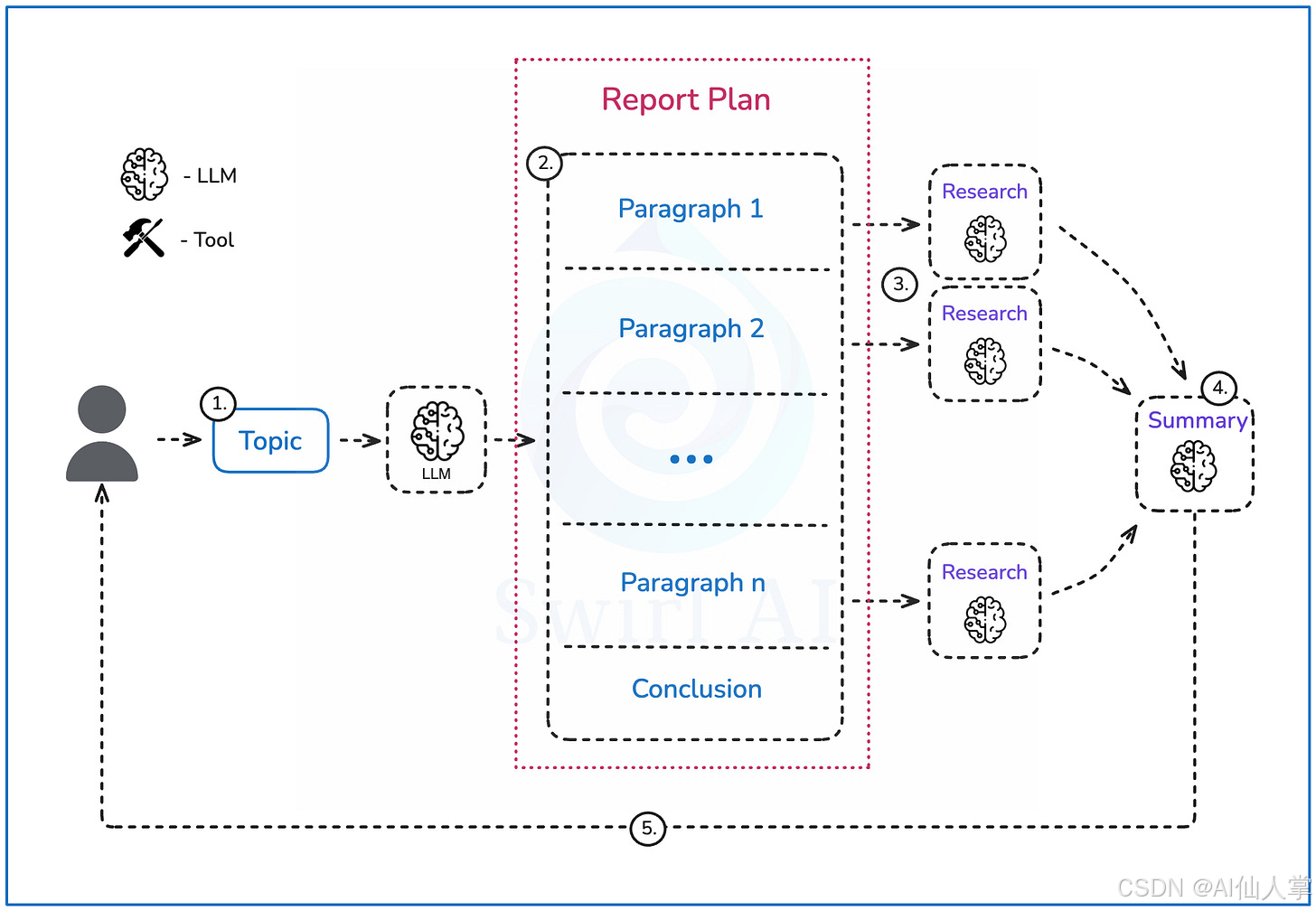
深度研究代理拓扑结构
研究步骤
让我们深入研究上一段中定义的研究步骤:
-
一旦我们有了每个段落的大纲,它将被传递给LLM,以构建网络搜索查询,以尽可能丰富所需的信息。
-
LLM将输出搜索查询及其推理过程。
-
我们将执行网络搜索,并检索最相关的顶部结果。
-
结果将传递到反思步骤,LLM将推理任何遗漏的细节,并尝试提出一个能够丰富初始结果的搜索查询。
-
这个过程将重复n次,以尝试获得最佳的信息集。
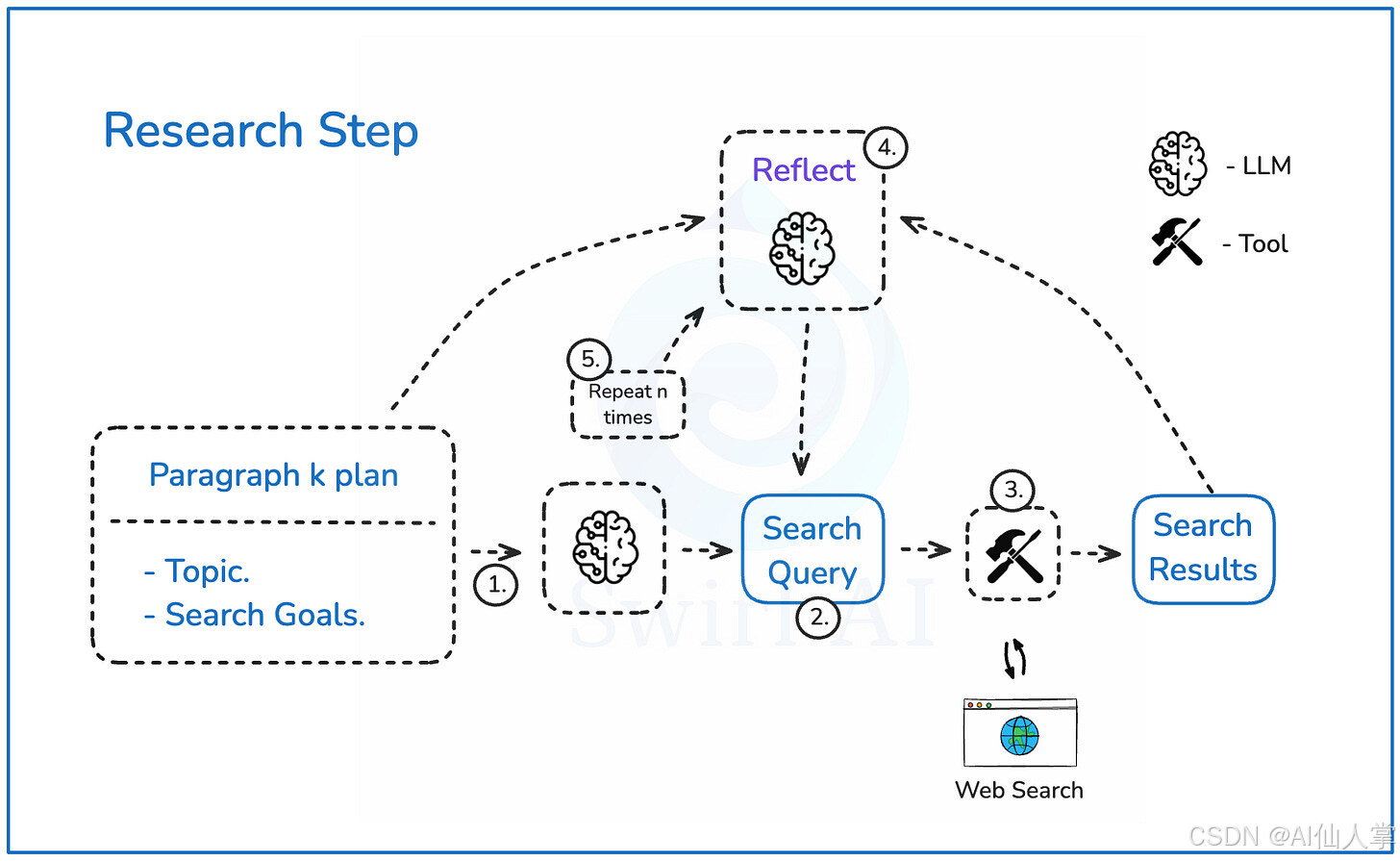
实现代理
到deepseek官方、阿里、腾讯登平台注册并获取你DeepSeek R1模型家族的API密钥。
安装工具包:
pip install openai
对于该项目,我们将使用6710亿参数的非精简版DeepSeek-R1版本。
确保你的DS_API_KEY已作为环境变量导出,并在控制台或Notebook中运行以下代码:
import os
import openai
client = openai.OpenAI(
api_key=os.environ.get("DS_API_KEY"),
base_url="https://preview.snova.ai/v1",
)
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content":"You are a helpful assistant"},
{"role":"user","content":"Tell me something interesting about human species"}],
temperature=1
)
print(response.choices[0].message.content)
你应该会看到类似以下内容:
<think>
Okay, so I'm trying to ... <REDACTED>
</think>
人类物种以其大脑的卓越认知能力而脱颖而出,这些能力支撑了一系列独特的特征。我们大脑的先进结构和功能使复杂的思维、语言和社会组织成为可能。这些能力推动了创新、艺术和复杂社会的形成,使人类在适应、创新和创造方面超越了其他任何物种。这种认知能力是人类成就的基石,也是我们对世界产生深远影响的根本。
推理标记将始终包含在答案中。虽然看到思考过程很有趣,但我们的系统只需要答案。这就是我们可以创建一个清理函数来移除<think>标签之间的内容。
def remove_reasoning_from_output(output):
return output.split("</think>")[-1].strip()
简单但很有用。
太好了!我们现在已经设置了SambaNova账户,并了解了DeepSeek R1模型家族的输出结构。接下来,让我们开始实现深度研究代理。
第一部分:定义状态
首先,我们需要定义整个系统的状态,该状态将在代理运行过程中不断演变,并被系统的不同部分选择性地使用。
让我们将状态与代理系统的阶段联系起来:
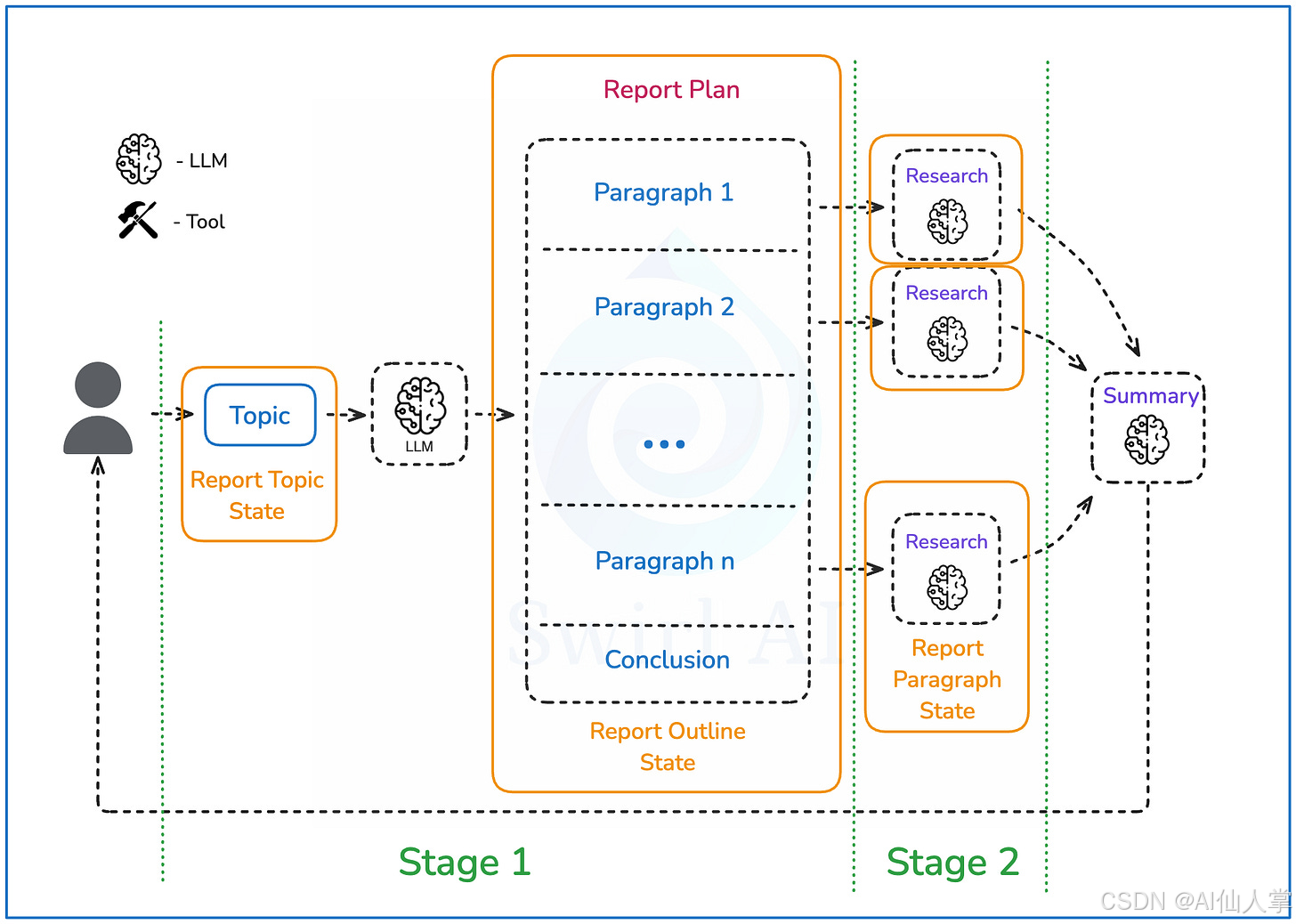
拓扑状态
-
阶段1 是创建报告大纲的阶段,报告结构将在此阶段规划,其状态也会随之演变。我们从一个空状态开始,但最终会演变为类似以下结构(推理过程在阶段2中描述):
{ "report_title": "报告标题", "paragraphs": [ { "title": "段落标题", "content": "段落内容", "research": <...> }, { "title": "段落标题", "content": "段落内容", "research": <...> } ] }使用Python的
dataclass可以优雅地实现上述结构。代码如下:@dataclass class Paragraph: title: str = "" content: str = "" research: Research = field(default_factory=Research) @dataclass class State: report_title: str = "" paragraphs: List[Paragraph] = field(default_factory=list) -
阶段2 是我们迭代每个段落状态的阶段。我们将更改每个段落的
“research”字段。每个段落的研究状态结构如下:{ "search_history": [{"url": "某个网址", "content": "网页内容"}], "latest_summary": "基于搜索历史的最新总结", "reflection_iteration": 1 }
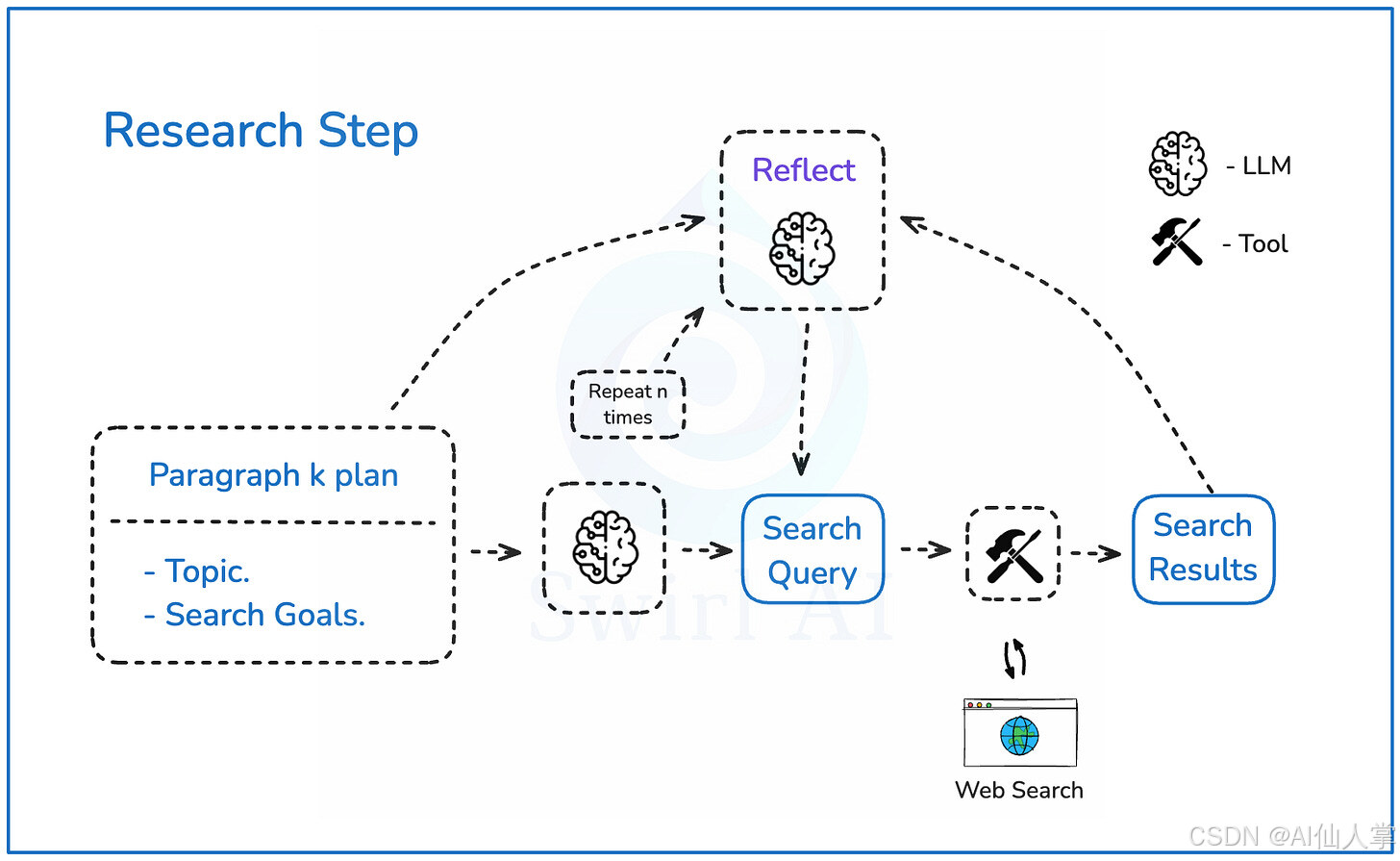
研究步骤
- `search_history`:我们将存储所有执行的搜索结果,包括网址和内容,以便后续去重和在最终报告中引用链接。
- `latest_summary`:基于所有搜索结果的段落总结版本。它将用于反思步骤,以判断是否需要进一步搜索,并在后续的总结和报告生成步骤中使用。
- `reflection_iteration`:用于跟踪当前的反思迭代次数,并在达到限制时强制停止。
同样,我们可以使用`dataclass`实现研究状态:
```python
@dataclass
class Search:
url: str = ""
content: str = ""
@dataclass
class Research:
search_history: List[Search] = field(default_factory=list)
latest_summary: str = ""
reflection_iteration: int = 0
```
第二部分:创建报告大纲
不同版本的模型在输出一致性方面会有所不同。我尝试了多次DeepSeek-R1,以下提示似乎能够生成格式良好的输出:
output_schema_report_structure = {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"}
}
}
}
SYSTEM_PROMPT_REPORT_STRUCTURE = f"""
你是一个深度研究助手。给定一个查询,规划一个报告的结构以及要包含的段落。
确保段落的顺序合理。
一旦大纲创建完成,你将分别针对每个部分进行网络搜索和反思。
按照以下JSON模式定义格式化输出:
<OUTPUT JSON SCHEMA>
{json.dumps(output_schema_report_structure, indent=2)}
</OUTPUT JSON SCHEMA>
标题和内容属性将用于进一步研究。
确保输出是一个符合上述JSON模式定义的JSON对象。
只返回JSON对象,不要附加任何解释或额外文本。
"""
[
段落结构状态
让我们用上述系统提示运行一个示例查询:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content":SYSTEM_PROMPT_REPORT_STRUCTURE},
{"role":"user","content":"Tell me something interesting about human species"}],
temperature=1
)
print(response.choices[0].message.content)
你将得到类似以下内容:
[
{
"title": "人类适应性的引言",
"content": "人类拥有独特的适应能力,这在其生存和在各种环境中的主导地位中至关重要。这一引言为探索人类适应性的不同方面奠定了基础。"
},
...
<REDACTED>
...
{
"title": "结论:适应性在人类生存中的作用",
"content": "适应性一直是人类生存和进化的基石,使我们能够面对挑战并探索新的领域,为未来的发展提供了洞见。"
}
]
这些JSON标签对我们来说并不友好,因为我们需要将输出转换为Python字典。以下是一个简单的函数,用于移除输出的首行和尾行:
```python
def clean_json_tags(text):
return text.replace("```json\n", "").replace("\n```", "")
以下是清理后的输出:
json.loads(clean_json_tags(remove_reasoning_from_output(response.choices[0].message.content)))
现在,我们可以直接将上述内容作为输入更新到全局状态中。
STATE = State()
report_structure = json.loads(clean_json_tags(remove_reasoning_from_output(response.choices[0].message.content)))
for paragraph in report_structure:
STATE.paragraphs.append(Paragraph(title=paragraph["title"], content=paragraph["content"]))
第三部分:网络搜索工具
我们将使用Tavily进行网络搜索。你可以在这里获取你的API密钥:Tavily注册。
工具的实现非常简单:
def tavily_search(query, include_raw_content=True, max_results=5):
tavily_client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
return tavily_client.search(query,
include_raw_content=include_raw_content,
max_results=max_results)
每次函数调用将返回最多max_results个网络搜索结果,每个搜索结果将返回:
- 搜索结果的标题。
- 搜索结果的网址。
- 内容摘要。
- 如果可能的话,返回网页的完整内容。我们希望获取完整内容以获得最佳结果。
第四部分:规划首次搜索
为了规划首次搜索,我找到了以下提示,它能够产生非常一致的结果:
input_schema_first_search = {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"}
}
}
output_schema_first_search = {
"type": "object",
"properties": {
"search_query": {"type": "string"},
"reasoning": {"type": "string"}
}
}
SYSTEM_PROMPT_FIRST_SEARCH = f"""
你是一个深度研究助手。你将获得一个报告段落的标题和预期内容,格式如下所示的JSON模式定义:
<INPUT JSON SCHEMA>
{json.dumps(input_schema_first_search, indent=2)}
</INPUT JSON SCHEMA>
你可以使用一个网络搜索工具,该工具以“search_query”作为参数。
你的任务是思考该主题,并提供最优化的网络搜索查询,以丰富你当前的知识。
按照以下JSON模式定义格式化输出:
<OUTPUT JSON SCHEMA>
{json.dumps(output_schema_first_search, indent=2)}
</OUTPUT JSON SCHEMA>
确保输出是一个符合上述JSON模式定义的JSON对象。
只返回JSON对象,不要附加任何解释或额外文本。
"""
我们在输出模式中要求提供推理内容,只是为了促使模型在查询上进行更多思考。虽然对于推理模型来说这可能有些多余,但对于普通LLM来说可能是个好主意。尽管我们在这里使用的是DeepSeek R1,但其实并不一定需要推理模型。在深度研究代理的第一步中,推理模型主要用于规划报告结构。
鉴于我们已经规划了一个包含标题和内容描述的段落列表,我们可以直接将第三部分的输出传递给这个提示,代码如下:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content":SYSTEM_PROMPT_FIRST_SEARCH},
{"role":"user","content":json.dumps(STATE.paragraphs[0])}],
temperature=1
)
print(response.choices[0].message.content)
STATE.paragraphs[0] 指向第一个段落的状态,其中 research 字段仍然是空的。
我为第一次搜索计划得到了以下结果:
{
"search_query": "Homo sapiens characteristics basic biological traits cognitive abilities behavioral traits",
"reasoning": "To understand the basic characteristics of Homo sapiens, including their biological traits, cognitive abilities, and behavioral patterns."
}
我们可以直接将这个查询输入到我们的搜索工具中:
tavily_search("Homo sapiens characteristics basic biological traits cognitive abilities behavioral traits")
第五部分:首次总结
首次总结与后续的反思步骤不同,因为还没有任何内容可供反思。这一步将生成可供后续反思的内容。以下提示效果不错:
input_schema_first_summary = {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"},
"search_query": {"type": "string"},
"search_results": {
"type": "array",
"items": {"type": "string"}
}
}
}
output_schema_first_summary = {
"type": "object",
"properties": {
"paragraph_latest_state": {"type": "string"}
}
}
SYSTEM_PROMPT_FIRST_SUMMARY = f"""
你是一个深度研究助手。你将获得一个搜索查询、搜索结果以及你正在研究的报告段落,格式如下所示的JSON模式定义:
<INPUT JSON SCHEMA>
{json.dumps(input_schema_first_summary, indent=2)}
</INPUT JSON SCHEMA>
你的任务是使用搜索结果撰写段落,使其符合段落主题,并合理地组织结构,以便包含在报告中。
按照以下JSON模式定义格式化输出:
<OUTPUT JSON SCHEMA>
{json.dumps(output_schema_first_summary, indent=2)}
</OUTPUT JSON SCHEMA>
确保输出是一个符合上述JSON模式定义的JSON对象。
只返回JSON对象,不要附加任何解释或额外文本。
"""
我们需要为LLM提供以下格式的数据:
{
"title": "标题",
"content": "内容",
"search_query": "搜索查询",
"search_results": []
}
我们已经拥有了所需的数据,可以从中构造JSON。假设以下代码运行结果为:
search_results = tavily_search("Homo sapiens characteristics basic biological traits cognitive abilities behavioral traits")
那么输入的JSON将如下所示:
input = {
"title": "人类适应性的引言",
"content": "人类拥有独特的适应能力,这在其生存和在各种环境中的主导地位中至关重要。这一引言为探索人类适应性的不同方面奠定了基础。",
"search_query": "Homo sapiens characteristics basic biological traits cognitive abilities behavioral traits",
"search_results": [result["raw_content"][0:20000] for result in search_results["results"] if result["raw_content"]]
}
然后运行以下代码:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content": SYSTEM_PROMPT_FIRST_SUMMARY},
{"role":"user","content":json.dumps(input)}],
temperature=1
)
print(remove_reasoning_from_output(response.choices[0].message.content))
你将得到类似以下内容:
{
"paragraph_latest_state": "Homo sapiens(现代人类所属的物种)是地球上生命进化史中独特而引人入胜的一页。作为Homo属中唯一现存的物种,Homo sapiens以其独特的生物、认知和行为特征与其他灵长类动物和已灭绝的人类近亲区分开来。从生物学上看,人类拥有一个结构复杂且高度发达的大脑,其新皮质相较于我们的祖先有了显著的扩展。这种解剖学上的发展使得人类具备了卓越的认知能力,例如复杂的解决问题能力、抽象思维以及语言和符号交流的能力。从行为学上看,人类展现出复杂的社会结构、文化习俗以及技术创新能力,这些能力对于人类适应多样化环境并繁衍至今至关重要。这些特征共同体现了生物学与行为学之间的复杂相互作用,定义了人类的本质。"
}
我们将使用这个结果更新 STATE.paragraphs[0].research.latest_summary 字段。在后续的 第六部分 中,我们将基于这个段落的最新状态进行反思。
第六部分:反思
现在我们已经拥有了报告段落内容的最新状态,接下来我们将利用它来改进内容。我们将提示LLM对文本进行反思,并寻找在撰写过程中可能遗漏的任何角度。
以下是一个效果很好的提示:
input_schema_reflection = {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"},
"paragraph_latest_state": {"type": "string"}
}
}
output_schema_reflection = {
"type": "object",
"properties": {
"search_query": {"type": "string"},
"reasoning": {"type": "string"}
}
}
SYSTEM_PROMPT_REFLECTION = f"""
你是一个深度研究助手。你的任务是为研究报告构建全面的段落内容。你将获得段落标题、计划内容摘要以及你已经创建的段落的最新状态,格式如下所示的JSON模式定义:
<INPUT JSON SCHEMA>
{json.dumps(input_schema_reflection, indent=2)}
</INPUT JSON SCHEMA>
你可以使用一个网络搜索工具,该工具以“search_query”作为参数。
你的任务是反思当前段落文本的状态,思考是否遗漏了该主题的某些关键方面,并提供最优化的网络搜索查询,以丰富最新的段落状态。
按照以下JSON模式定义格式化输出:
<OUTPUT JSON SCHEMA>
{json.dumps(output_schema_reflection, indent=2)}
</OUTPUT JSON SCHEMA>
确保输出是一个符合上述JSON模式定义的JSON对象。
只返回JSON对象,不要附加任何解释或额外文本。
"""
对于当前正在实现的运行,输入将如下所示:
input = {
"paragraph_latest_state": "Homo sapiens(现代人类所属的物种)是地球上生命进化史中独特而引人入胜的一页。作为Homo属中唯一现存的物种,Homo sapiens以其独特的生物、认知和行为特征与其他灵长类动物和已灭绝的人类近亲区分开来。从生物学上看,人类拥有一个结构复杂且高度发达的大脑,其新皮质相较于我们的祖先有了显著的扩展。这种解剖学上的发展使得人类具备了卓越的认知能力,例如复杂的解决问题能力、抽象思维以及语言和符号交流的能力。从行为学上看,人类展现出复杂的社会结构、文化习俗以及技术创新能力,这些能力对于人类适应多样化环境并繁衍至今至关重要。这些特征共同体现了生物学与行为学之间的复杂相互作用,定义了人类的本质。",
"title": "引言",
"content": "人类物种(Homo sapiens)是地球上最独特且引人入胜的物种之一。本节将介绍人类的基本特征,并为探索该物种的有趣方面奠定基础。"
}
接下来运行以下代码:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content": SYSTEM_PROMPT_REFLECTION},
{"role":"user","content":json.dumps(input)}],
temperature=1
)
print(remove_reasoning_from_output(response.choices[0].message.content))
输出结果如下:
{
"search_query": "Recent research on Homo sapiens evolution, interaction with other human species, and factors contributing to their success",
"reasoning": "当前段落对Homo sapiens的特征进行了很好的概述,但缺乏对其进化历史以及与其他人类物种相互作用的深入探讨。加入这些主题的最新研究成果,将使段落更加全面,并提供最新的信息。"
}
现在,我们运行反思步骤中的搜索查询:
search_results = tavily_search("Recent research on Homo sapiens evolution, interaction with other human species, and factors contributing to their success")
然后,使用以下代码更新段落的搜索状态:
update_state_with_search_results(search_results, idx_paragraph, state)
接下来,我们将反思步骤(第6部分)和更新段落状态的步骤(第7部分)放入循环中,按照指定的反思次数重复执行。
第七部分:结合反思搜索结果丰富段落的最新状态
在运行反思步骤的搜索查询后:
search_results = tavily_search("Recent research on Homo sapiens evolution, interaction with other human species, and factors contributing to their success")
我们可以通过以下代码更新段落的搜索历史:
update_state_with_search_results(search_results, idx_paragraph, state)
然后,我们将反思步骤的搜索结果与段落的最新状态结合起来,进一步丰富段落内容。
第八部分:总结并生成报告
我们对每个段落重复执行第4到第7部分的步骤。当所有段落的最终状态都准备好后,我们可以将它们拼接在一起,生成完整的报告。我们将通过LLM完成这一步,并生成一个格式良好的Markdown文档。以下是提示:
input_schema_report_formatting = {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},
"paragraph_latest_state": {"type": "string"}
}
}
}
SYSTEM_PROMPT_REPORT_FORMATTING = f"""
你是一个深度研究助手。你已经完成了研究,并构建了报告中所有段落的最终版本。
你将获得以下格式的数据:
<INPUT JSON SCHEMA>
{json.dumps(input_schema_report_formatting, indent=2)}
</INPUT JSON SCHEMA>
你的任务是将报告格式化为Markdown格式。如果报告中缺少结论段落,请从其他段落的最新状态中生成一个结论段落并添加到报告末尾。
"""
运行以下代码:
report_data = [{"title": paragraph.title, "paragraph_latest_state": paragraph.research.latest_summary} for paragraph in STATE.paragraphs]
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content": SYSTEM_PROMPT_REPORT_FORMATTING},
{"role":"user","content":json.dumps(report_data)}],
temperature=1
)
print(remove_reasoning_from_output(response.choices[0].message.content))
至此,你已经成功生成了一个关于指定主题的深度研究报告。
结论
恭喜!你已经从零开始成功实现了一个深度研究代理。
如果你希望查看更完整的代码实现,可以访问我的GitHub仓库:
GitHub仓库
原创不易,转发请备注
此外,还有许多可以改进的地方,以使系统更加稳定:
- 让系统始终生成格式良好的JSON输出并非易事,因为推理模型在结构化输出方面表现并不理想。
- 鉴于此,我们可以考虑在系统拓扑的不同任务中使用不同的模型,推理模型主要用于第一步。
- 我们还可以改进网络搜索的方式以及对检索结果的排序方法。
- 反思步骤的次数可以设置为动态的,让LLM根据需要决定是否需要更多步骤。
- 我们可以在报告中返回用于搜索的链接,并为每个段落提供参考来源。
- ……
原创不易,转发请备注