RAG的Rerank:从期待到现实的转变

在人工智能快速发展的时代,检索增强生成(RAG)给我们带来了全新的思维与期待。结合大规模语言模型(LLM),许多人信心满满,以为可以轻松解决复杂的问答任务。现实则告诉我们,尽管RAG的使用相对简单,但要真正掌握其精髓,却并非易事。
一、RAG流程中的困惑
RAG并非仅仅是将文档存入向量数据库,随后由LLM进行处理。从技术层面看,RAG涉及多个步骤与复杂的算法。许多人在开发完RAG流程后,面临的首要问题是:为何效果与预期差距如此悬殊?实际上,RAG的成功与否,在很大程度上取决于检索和生成两个阶段的有效性。
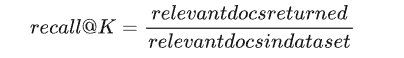
二、检索问题的深层解读
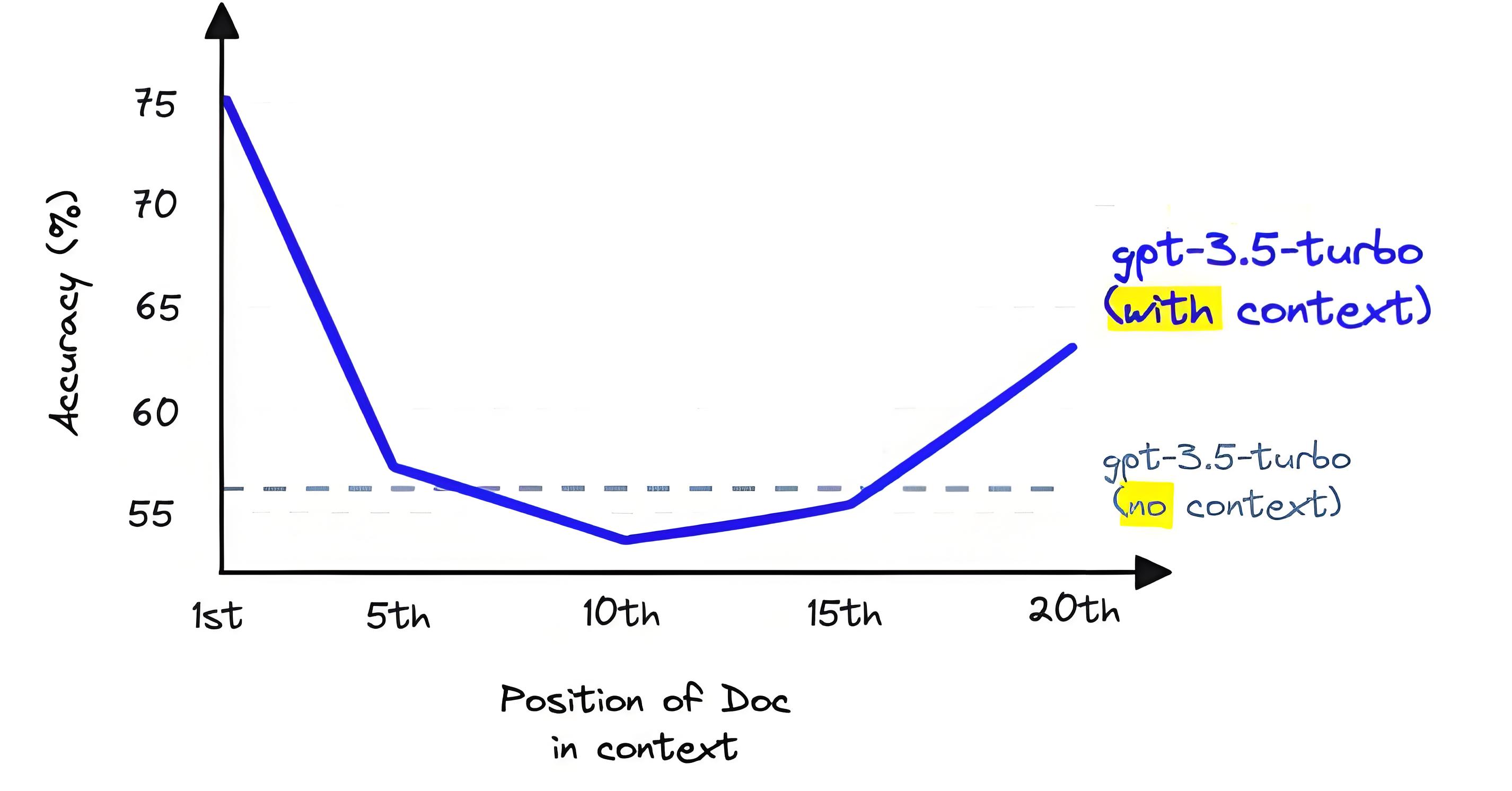
使用RAG时,我们需要对大量的文本文档进行语义搜索。文档的数量从数万到数亿不等,确保在此过程中速度的关键是向量搜索。向量将文本背后的“含义”压缩成一组固定维度的数字表示,但信息的压缩不可避免地会导致一些重要信息的丢失。例如,我们可能发现,从向量搜索中返回的前三篇文档,可能并不包含最相关的信息。解决方案是提高返回文档的数量,但这并不完美。很大一部分LLM的处理能力受限于其上下文窗口。
三、上下文窗口的限制
上下文窗口限制了LLM能够接受的信息量。虽然一些模型如Anthropic的Claude,能够处理更多的Token(达到100K),但仍然不能超出这个范围。当我们试图在上下文中填充过多文档时,LLM的性能往往会受到影响。这一现象显示,简单增加文档数量并不能提高性能,相反地,可能会对处理结果产生负面影响。
四、Rerank的崛起
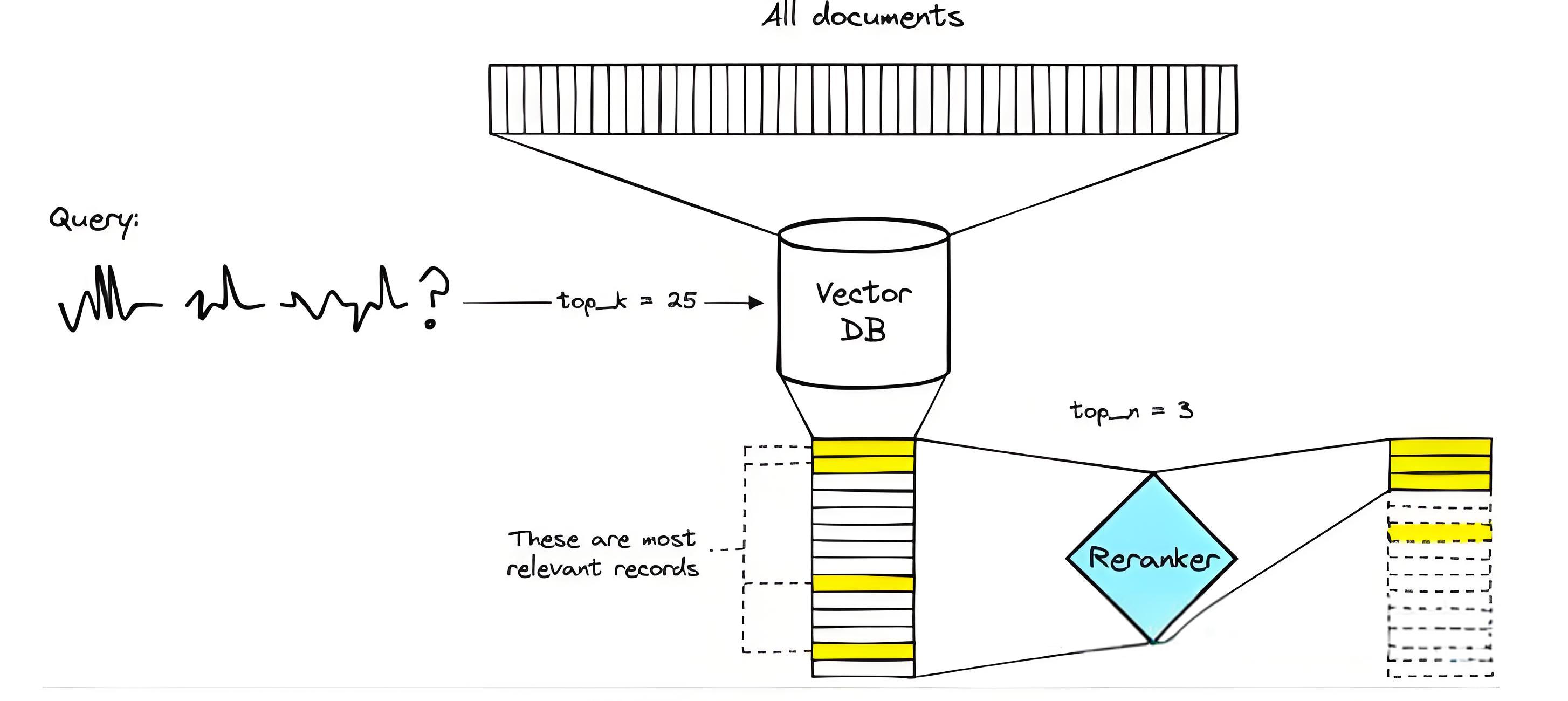
如何在保证检索率的同时提升生成效果?这需要引入重排序技术——Rerank。重排序模型,通常被称为交叉编码器,能够针对给定的查询和文档对,生成一个相似度分数。根据这一分数,我们能够对检索到的文档进行有效排序。
在实际应用中,许多搜索工程师已在使用包含Rerank的两阶段检索系统。通过第一阶段的快速检索,获取相关文档,并在第二阶段利用Rerank对信息进行重新排序。这种方法结合了快速与准确的优势。
五、Rerank的优势与代价
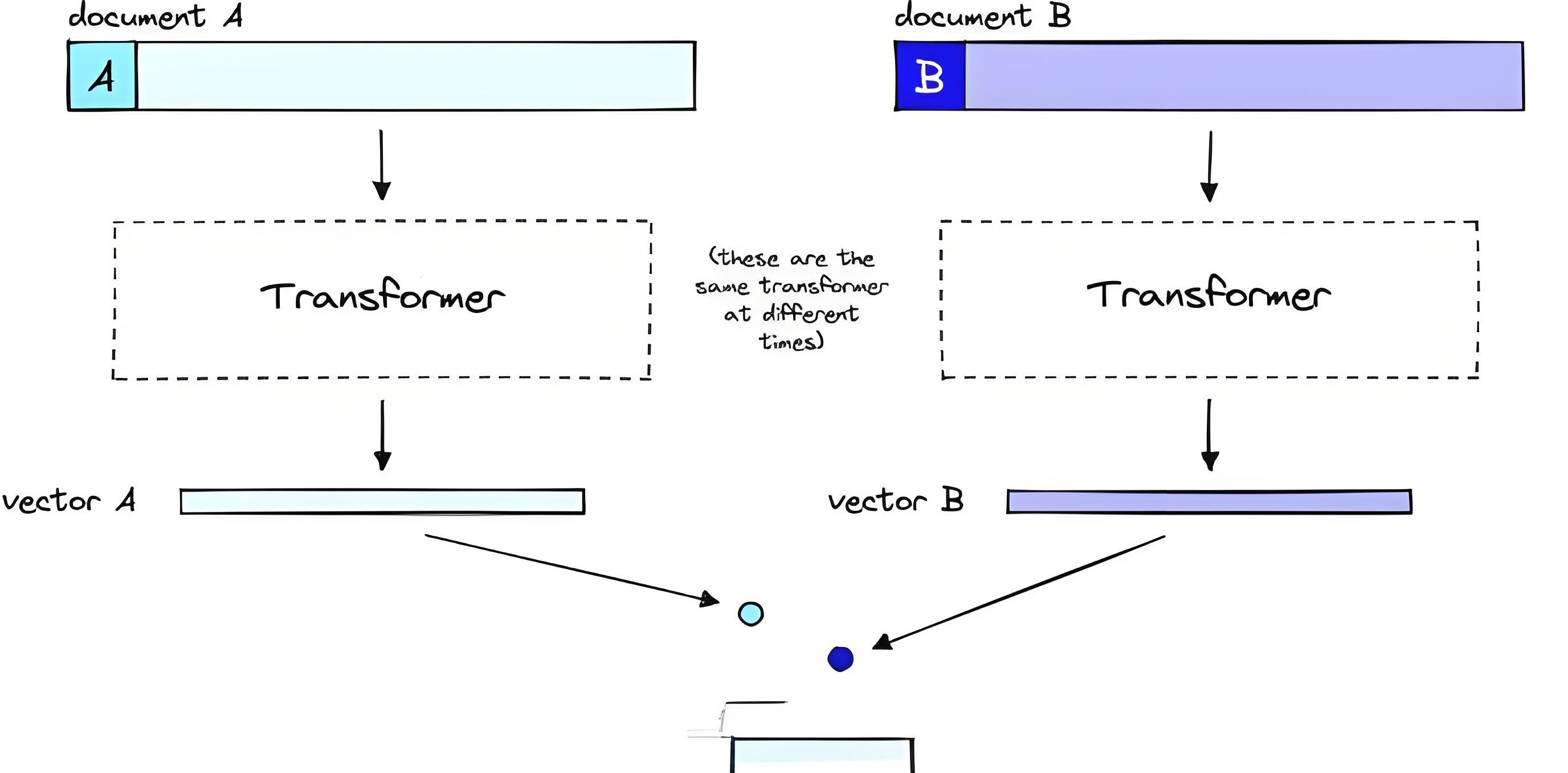
即使Rerank的计算速度较慢,它带来的准确性却是其他模型所无法比拟的。重排序模型接收到的输入信息更为全面,因此减少了信息的丢失。此外,由于Rerank是在用户查询后执行的,它能够根据查询的具体含义进行分析,进一步提高相关性。
然而,准确性与速度之间的权衡始终是不容忽视的。对于大规模文档,例如4千万条记录,使用小型重排序模型可能需要消耗数十小时。针对这种情况,结合文档切片技术和混合召回策略是必不可少的途径。
六、总结与展望
精通RAG的重要一环在于实现有效的Rerank。在信息技术飞速更新迭代的背景下,理解和运用这些技术将使我们在解决问答任务时,更具优势与成功的可能性。展望未来,随着更多技术的融入,RAG将带给我们更加广阔的应用前景。