来自腾讯的:《详解DeepSeek:模型训练、优化及数据处理的技术精髓》
大家好,我是吾鳴。
今天吾鳴要给大家分享的是一份来自腾讯出品的最新报告——《详解DeepSeek:模型训练、优化及数据处理的技术精髓》。这份报告主要特点是从大语言模型特点、技术突破与开源生态、核心技术架构、版本迭代与创新、关键技术优化、强化学习应用、应用场景、技术趋势与行业比较以及使用指南与最佳实践这几大部分展开,如果你希望了解DeepSeek的技术原理和精髓,那么这份报告建议你好好看看。报告一共23页,文末有完整版下载地址。

内容摘要
- DeepSeek简介
介绍了DeepSeek的背景,由杭州深度求索公司于2023年推出,专注于大语言模型开发,具备“低成本、聪明强大、本土化”特点,核心目标是降低训练成本并提升模型性能。 - 大语言模型特点
分析了DeepSeek的技术特性,包括内容Token化、训练数据截止时间限制、无自我意识、上下文长度限制(约3-4万字)、输出长度限制(约2000-4000字),并提出分块输入、联网补充等解决方案。 - 发展历程与行业背景
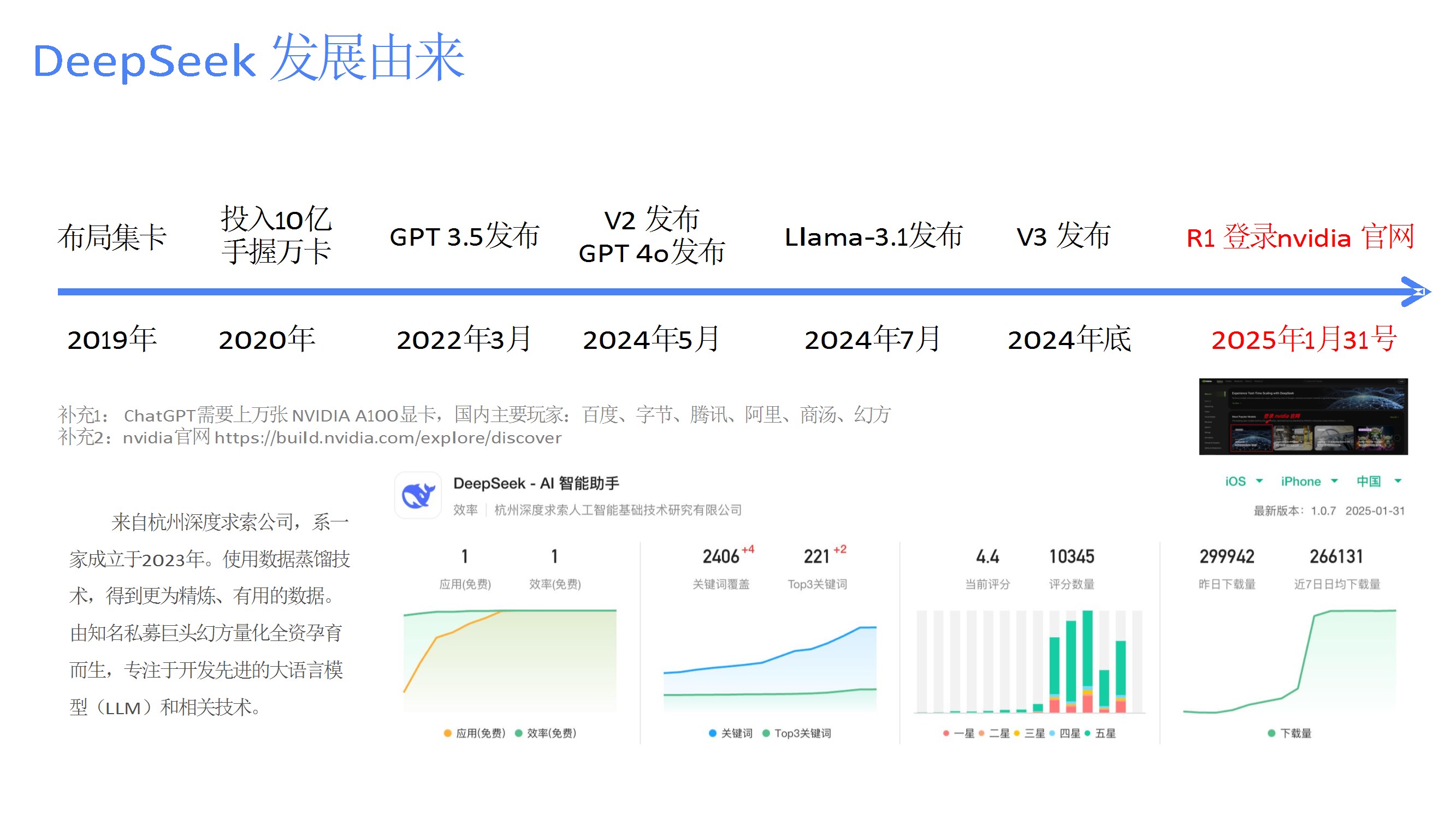
梳理了DeepSeek的发展时间线,强调其依托幻方量化的算力资源,采用数据蒸馏技术优化数据质量,并与国产硬件厂商合作推动生态建设。 - 技术突破与开源生态
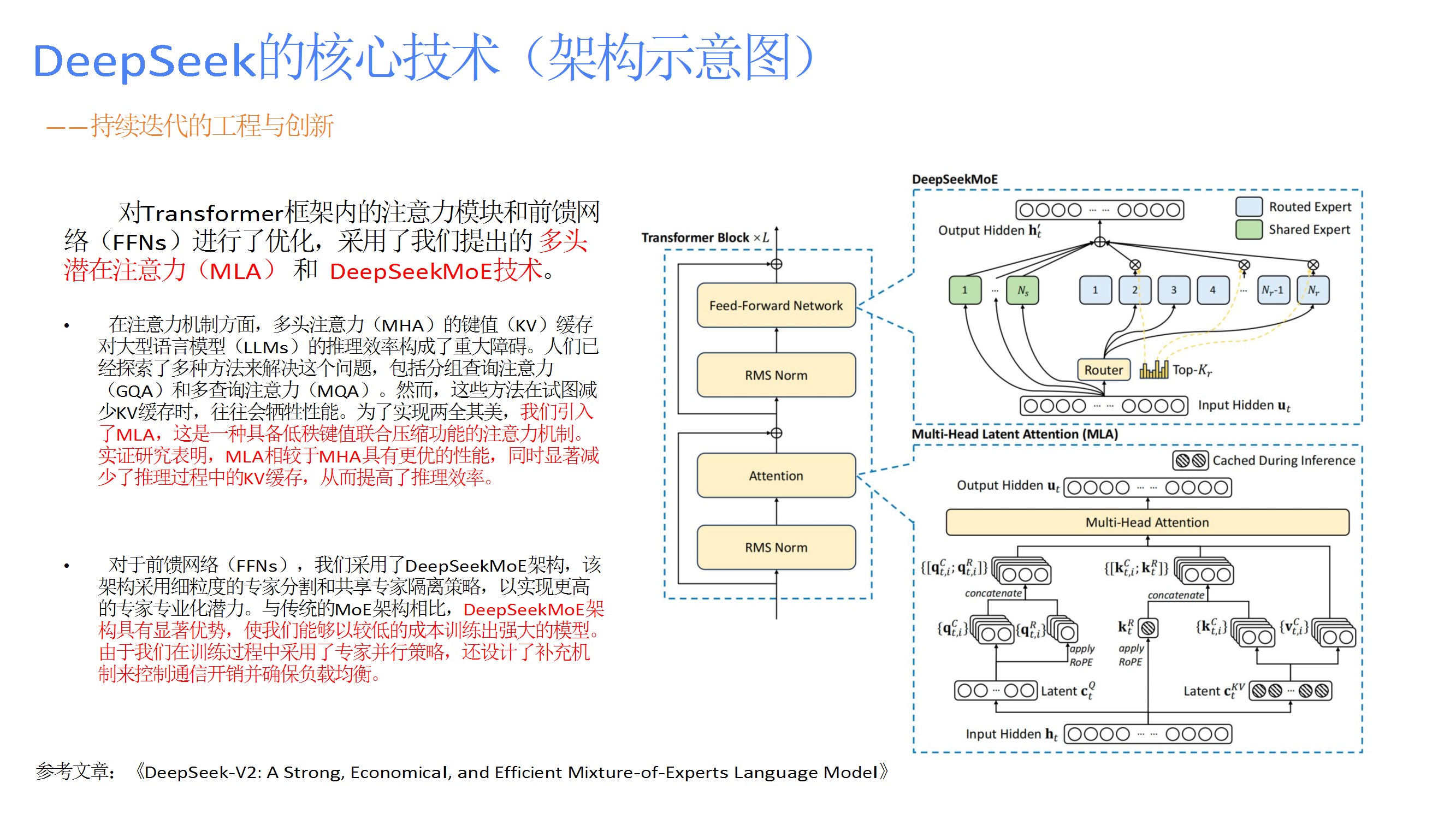
重点包括模型架构优化(如ITILA注意力机制、MoE混合专家架构)、训练效率提升(分布式并行、FP8混合精度)、数据质量策略,以及开源模型与工具链对开发者社区的赋能。 - 核心技术架构
详细阐述模型架构(动态稀疏激活、长上下文建模)、训练框架(分布式优化、强化学习对齐)、核心优势(高效推理、多任务兼容、持续进化),并对比传统稠密模型与MoE架构的差异。 - 版本迭代与创新
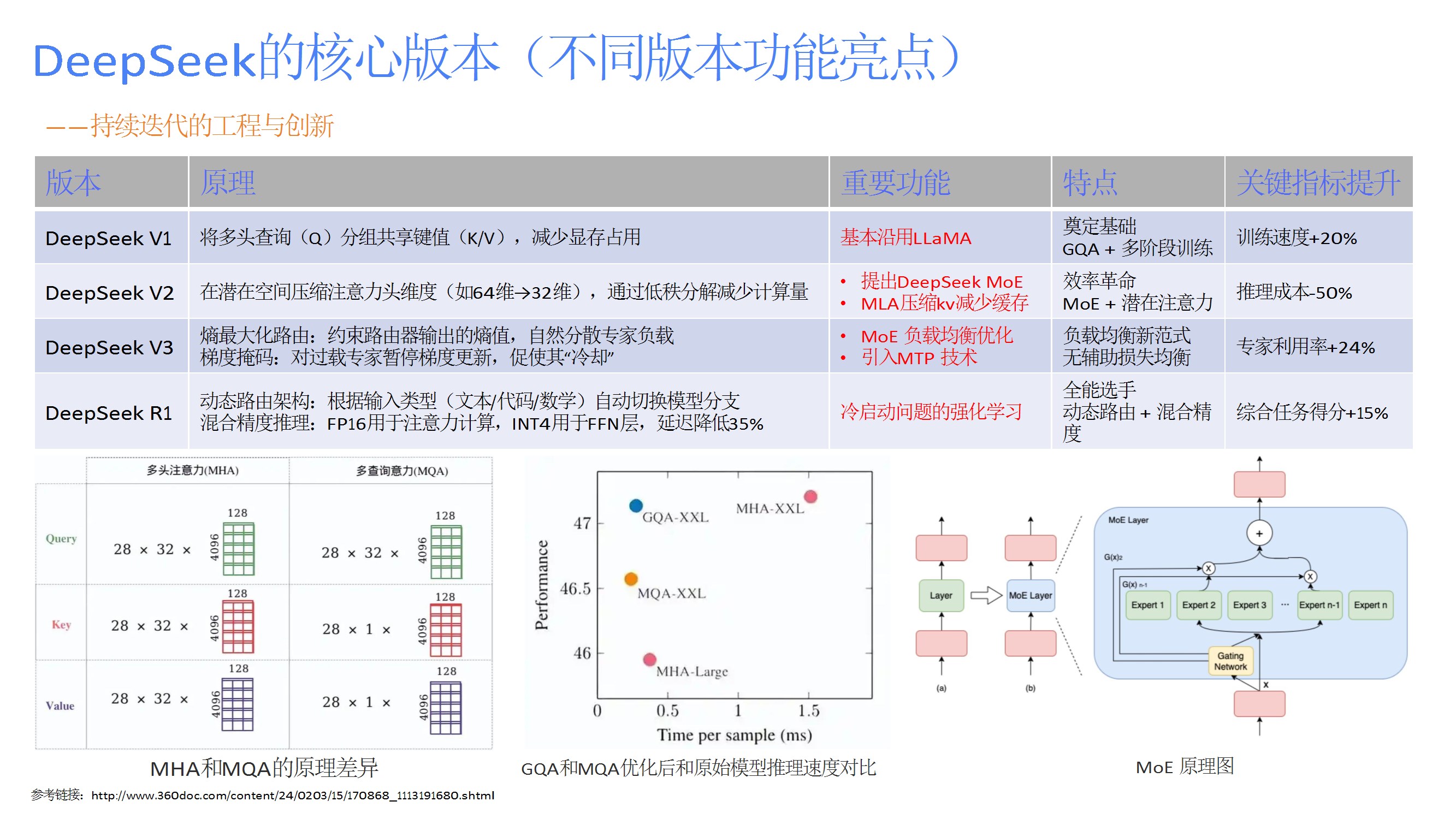
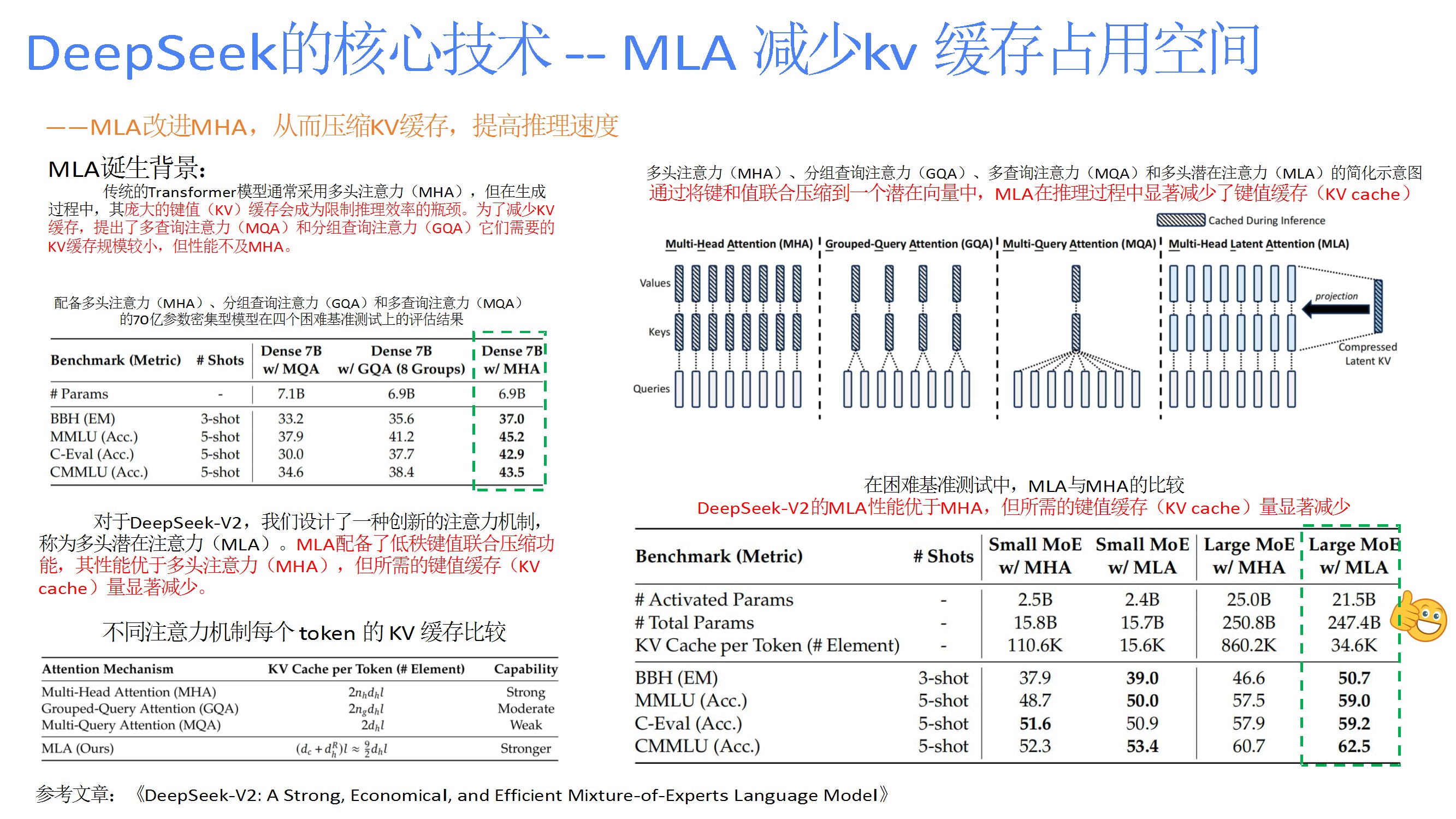
从V1到R1的版本演进,改进点包括显存优化(GQA)、计算量压缩(潜在注意力)、负载均衡(熵最大化路由)、动态路由与混合精度推理,显著提升性能并降低成本。 - 关键技术优化
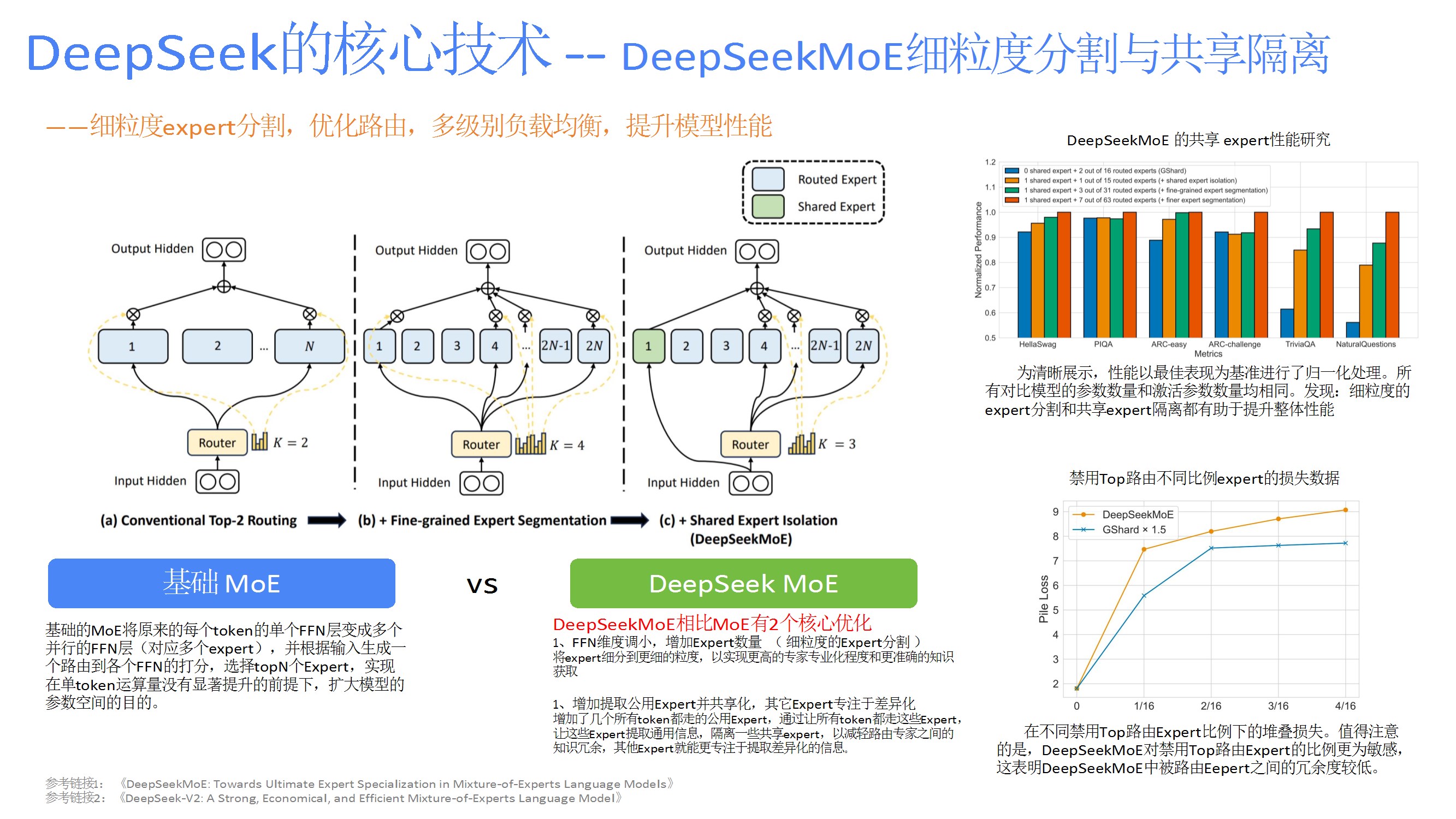
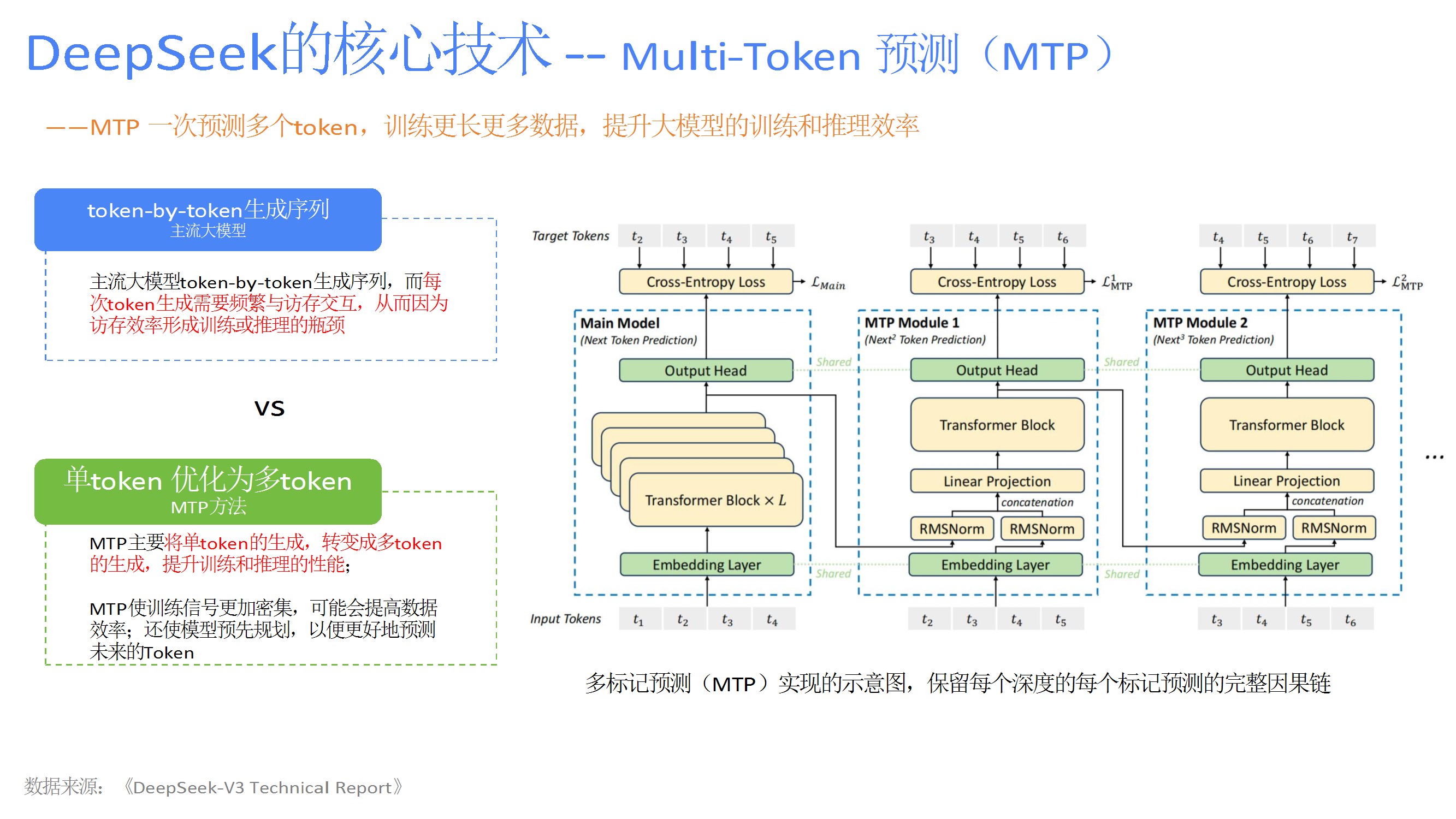
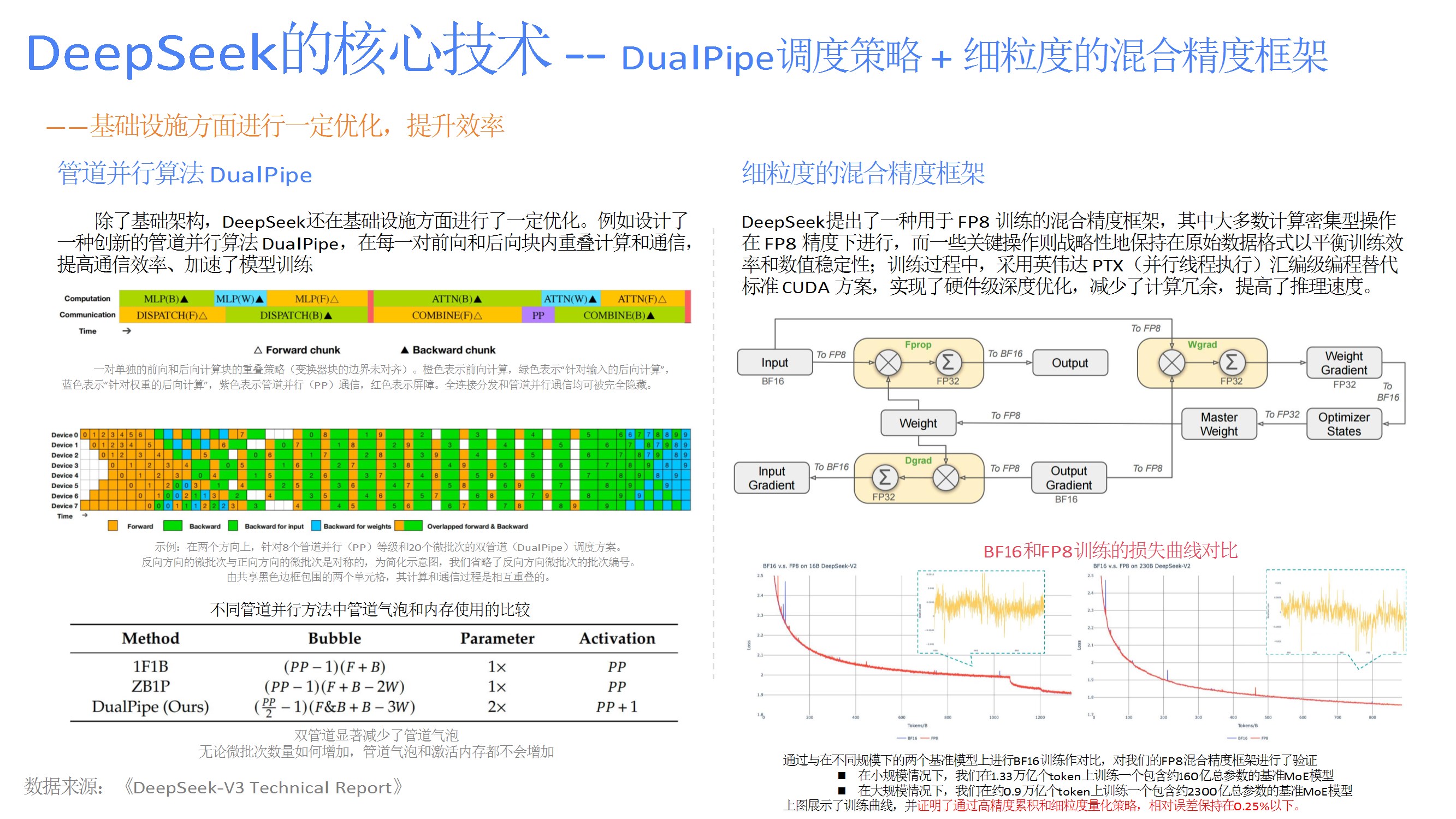
如MLA减少KV缓存、DeepSeekMoE的细粒度专家分割与共享隔离、多标记预测(MTP)提升训练效率、DualPipe调度策略隐藏通信延迟、FP8量化框架降低计算开销。 - 强化学习应用
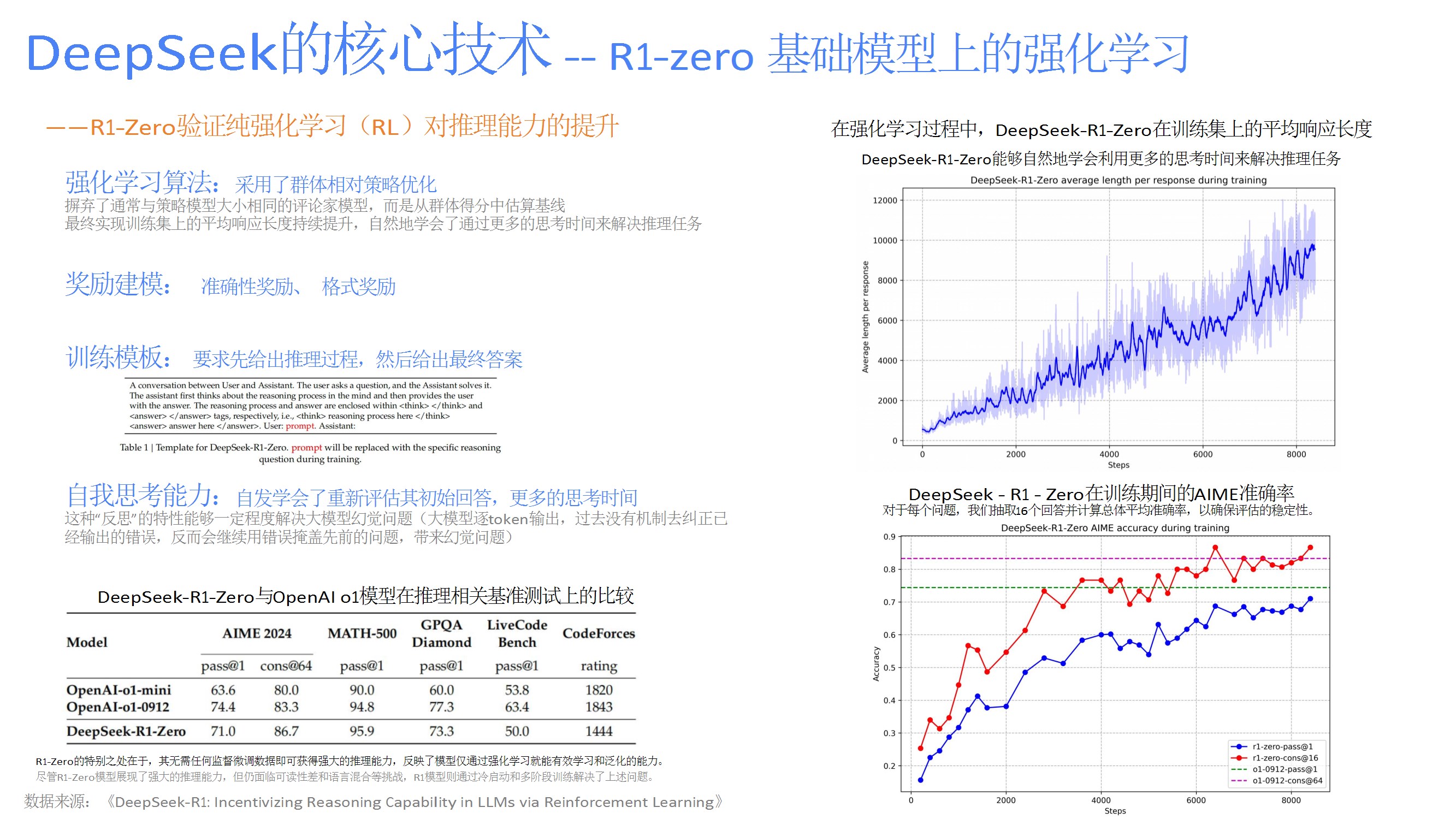
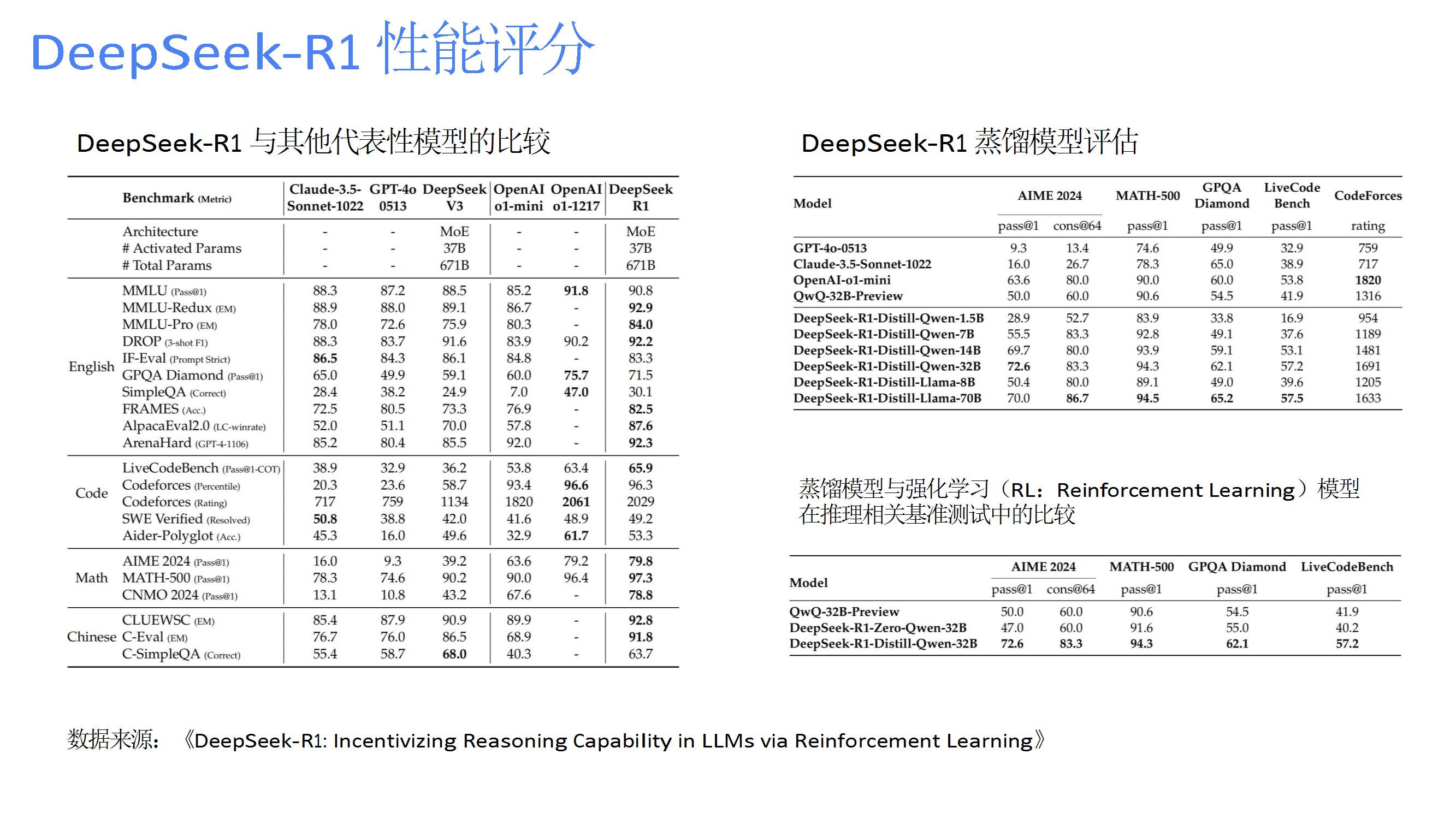
通过纯强化学习(R1-Zero)和冷启动优化(R1)提升推理能力,结合奖励建模与拒绝采样,在数学、代码等任务中表现优于部分主流模型,并通过蒸馏技术迁移至小模型。 - 应用场景
覆盖零售(需求预测)、金融(智能风控)、教育(自适应学习)、医疗(影像诊断)等领域,强调多模态交互、实时决策与闭环系统对行业的赋能价值。 - 技术趋势与行业比较
展望通用AI与垂直场景的双向发展,预测参数规模扩展、因果推理升级、边缘部署等趋势;对比DeepSeek与GPT、Claude等模型的性能、成本、场景优势,突出其中文任务和开源生态竞争力。 - 使用指南与最佳实践
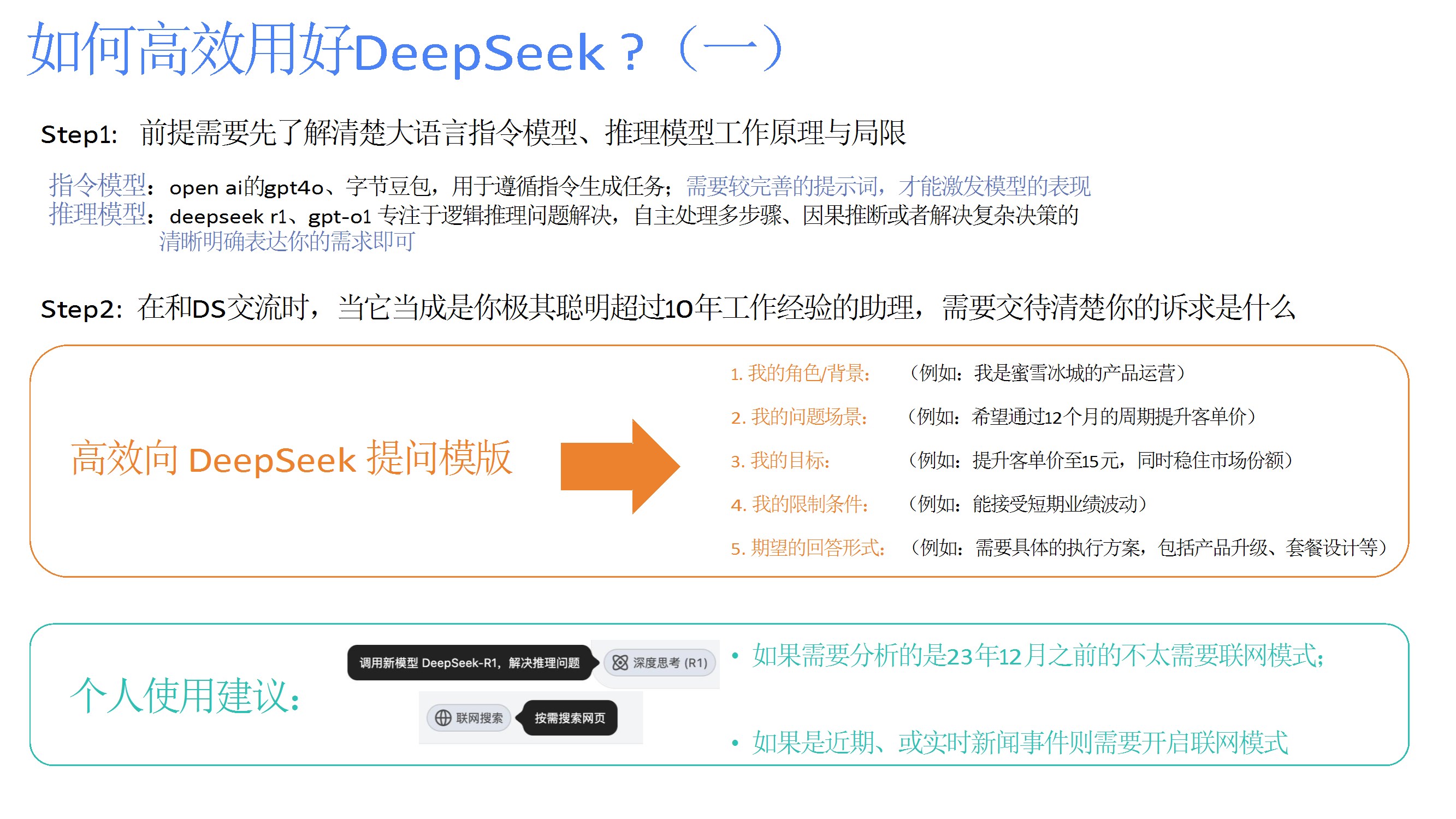
提供高效提问模板,强调明确背景、结构化描述、拆分复杂问题、避免模糊指令等策略,并建议根据需求选择联网模式或本地知识库。 - 总结与展望
肯定DeepSeek在降低训练成本、推动AI民主化方面的贡献,展望其在AI历史中的长期价值,呼吁持续学习与技术跟进。
精彩内容











报告无套路自取:https://kdocs.cn/l/ci1DfElGCPoS