Nerf较真系列
一.解决的核心问题
1.什么是Nerf
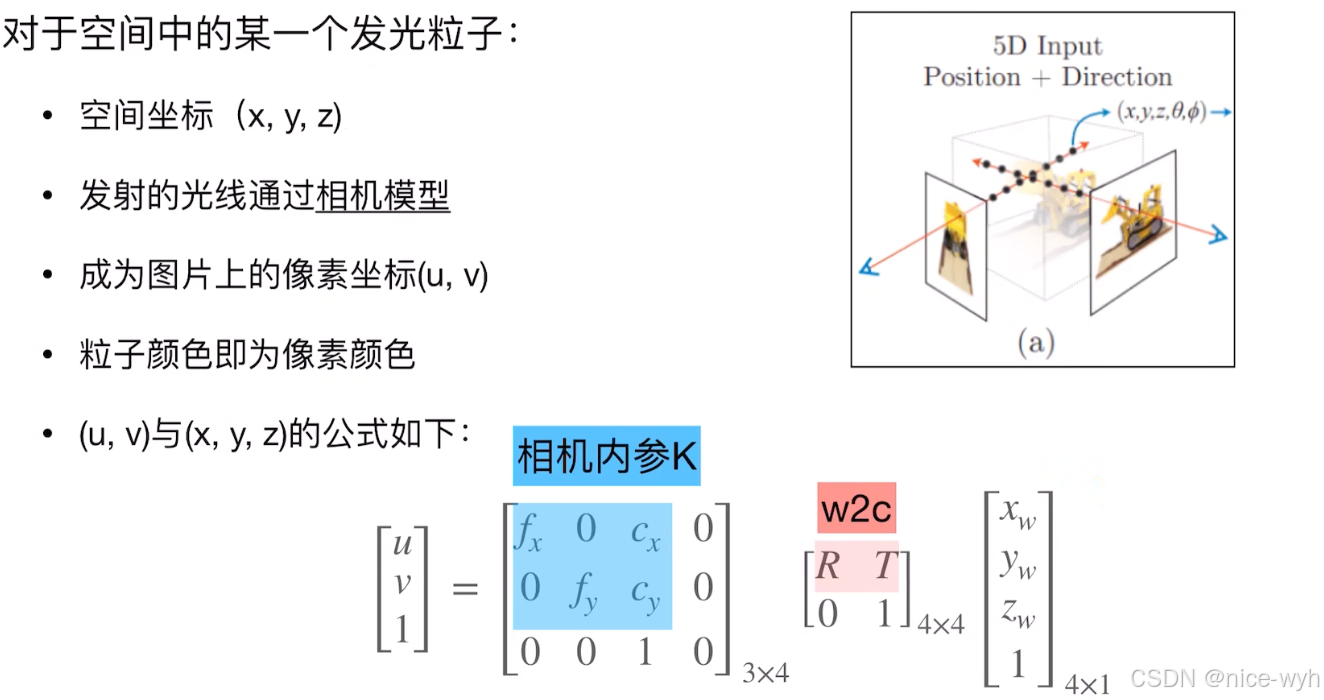
2.Nerf的输入是什么
3.Nerf的输出是什么
4.怎么把Nerf的输出转化为一张图片
5.Loss是怎么计算的
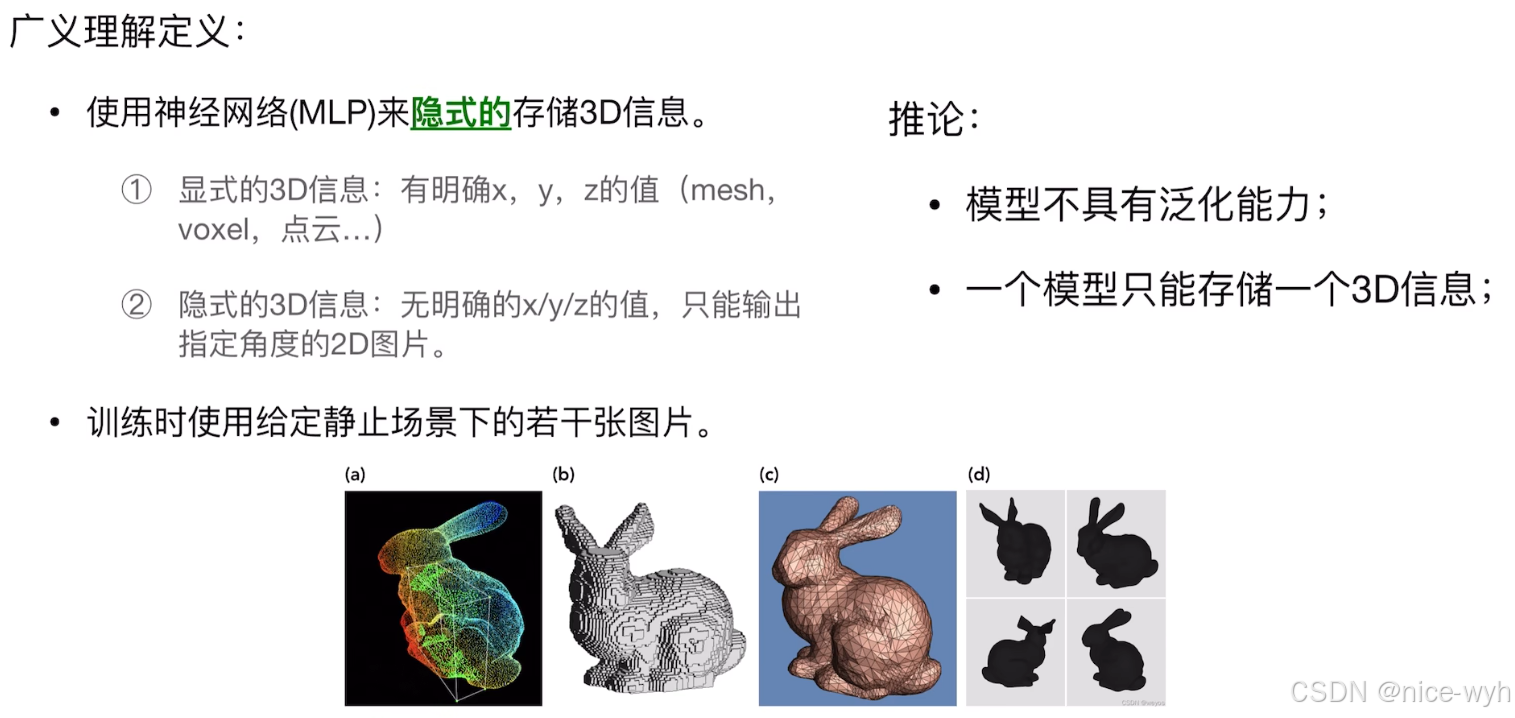
模型输入是5D向量(x,y,z,theta, phi),输出是4D向量(密度,颜色),模型结构是八层MLP,此时可能会有疑问,输入不是一张张图片吗,怎么变成5D向量了,那么就应该有一个前处理过程,把图片处理成需要的5D向量,而输出不应该也是图片吗,到这里变成了4D向量,那么就应该有一个后处理过程,把4D向量处理成需要的图片。

而这里的位姿是哪里来的,图片不是只有xyz位置信息吗,这里的粒子又是从哪来的;正常在人的感官世界里,人眼通过模拟相机模型来连接3D世界与2D图片,所以说对于空间中的一个物体,是通过太阳光照在上面,在经过反射与折射,将光射会人眼的过程,而物体本身就是我们要观察的物体本身的表面是支持反射与折射的,将物体细分,将可以当成是一堆粒子的集合,其中光照射到每一个粒子上都会反射与折射,也就是上面的过程,因此这里九江自然界的物体抽象成细化成一个一个粒子的结合了;因此模型的输入和输出就是

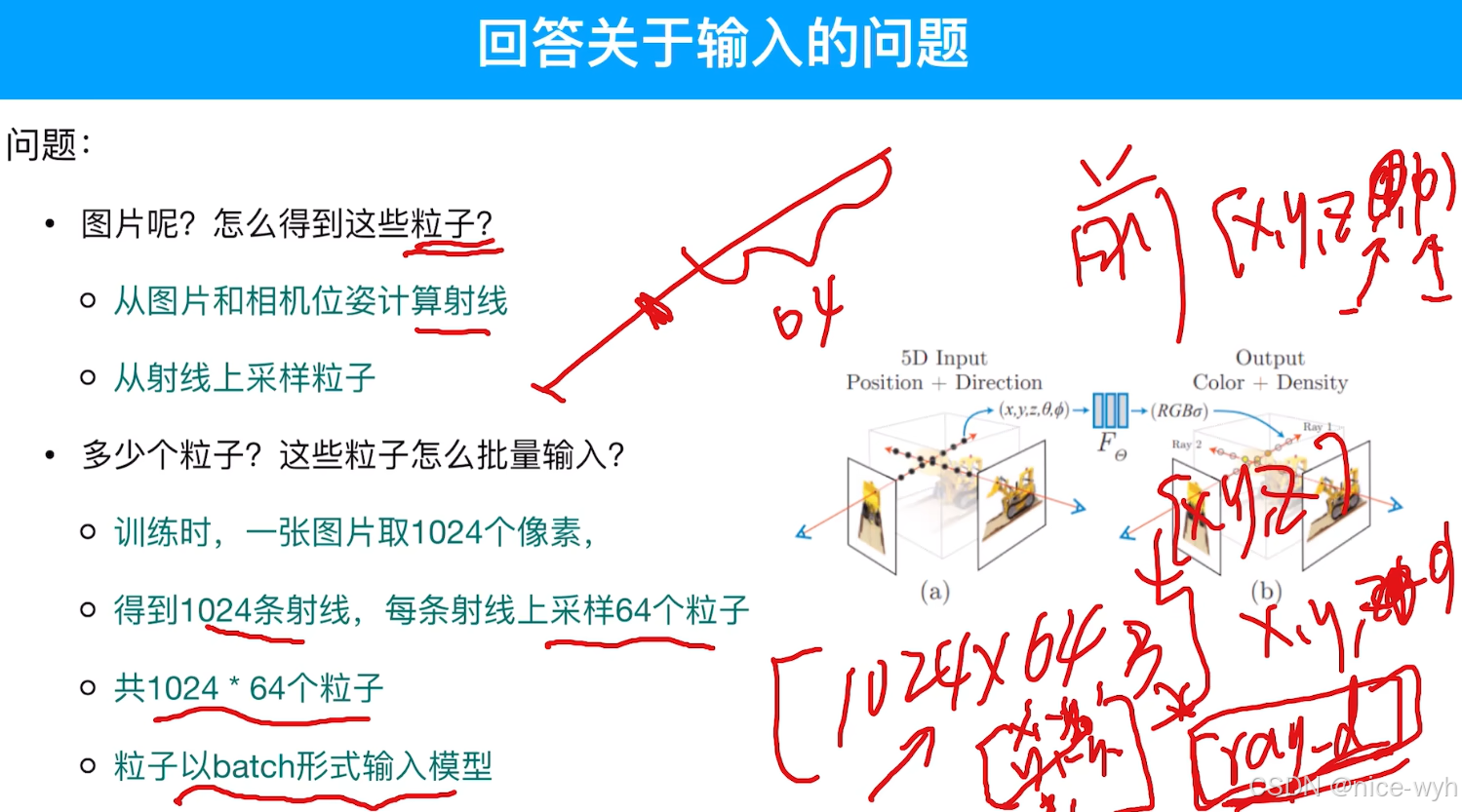
而现在还有一个问题,输入的各个图片是怎么变成粒子的,需要多少个粒子才能达到渲染的目的,这些粒子又是怎么渲染成图片的?
二.处理过程
1.前处理
已知有粒子的情况下是怎么得到图片的呢?对于空间中的一个发光粒子,知道他的空间坐标,他发出的光线或者是反射太阳的光线通过相机模型,就可以变为相机坐标系的坐标,再经过左乘相机内参就可以得到粒子在像素坐标系下的坐标,同时粒子本身是有颜色和密度的,所以得到的像素也是具有颜色的。这也就是粒子到图片的正向过程。
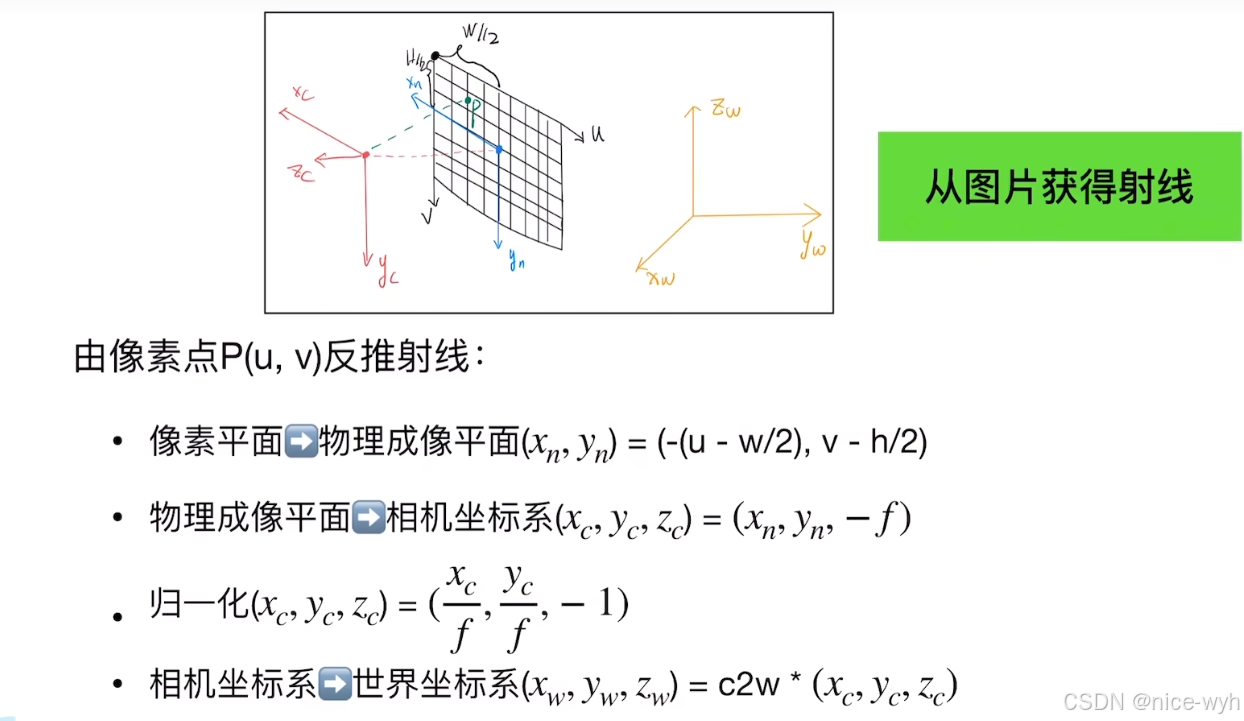
那么怎么通过图片得到例子呢?对于图片中的某个像素,他是有特定颜色的,我们认为该像素投影射线上所有点的集合的颜色平均就是该像素的颜色

由公式去推得
所以关于输入输出的问题,其实在代码里为了表示,输入是一个6D向量,姿态也有了三个维度进行表示
2.模型结构
模型就是一个简单八层MLP,输入是一个60D的向量,中间还会和这个60D的向量进行concat,最后再加上一个24D的向量。
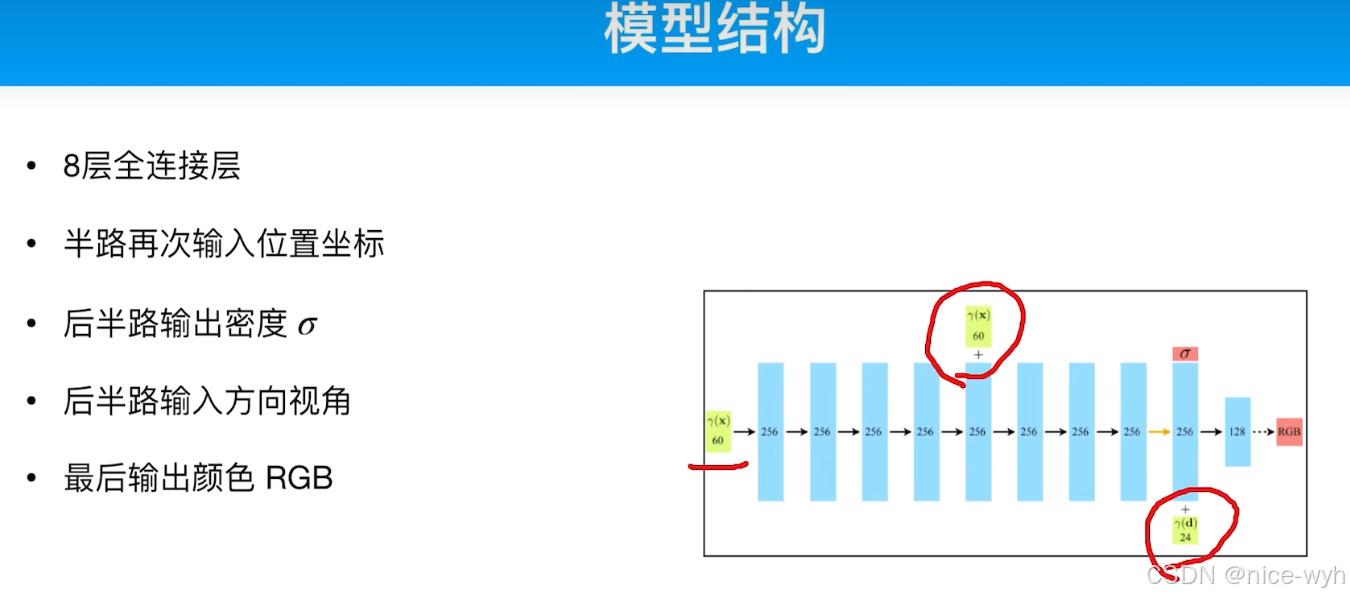
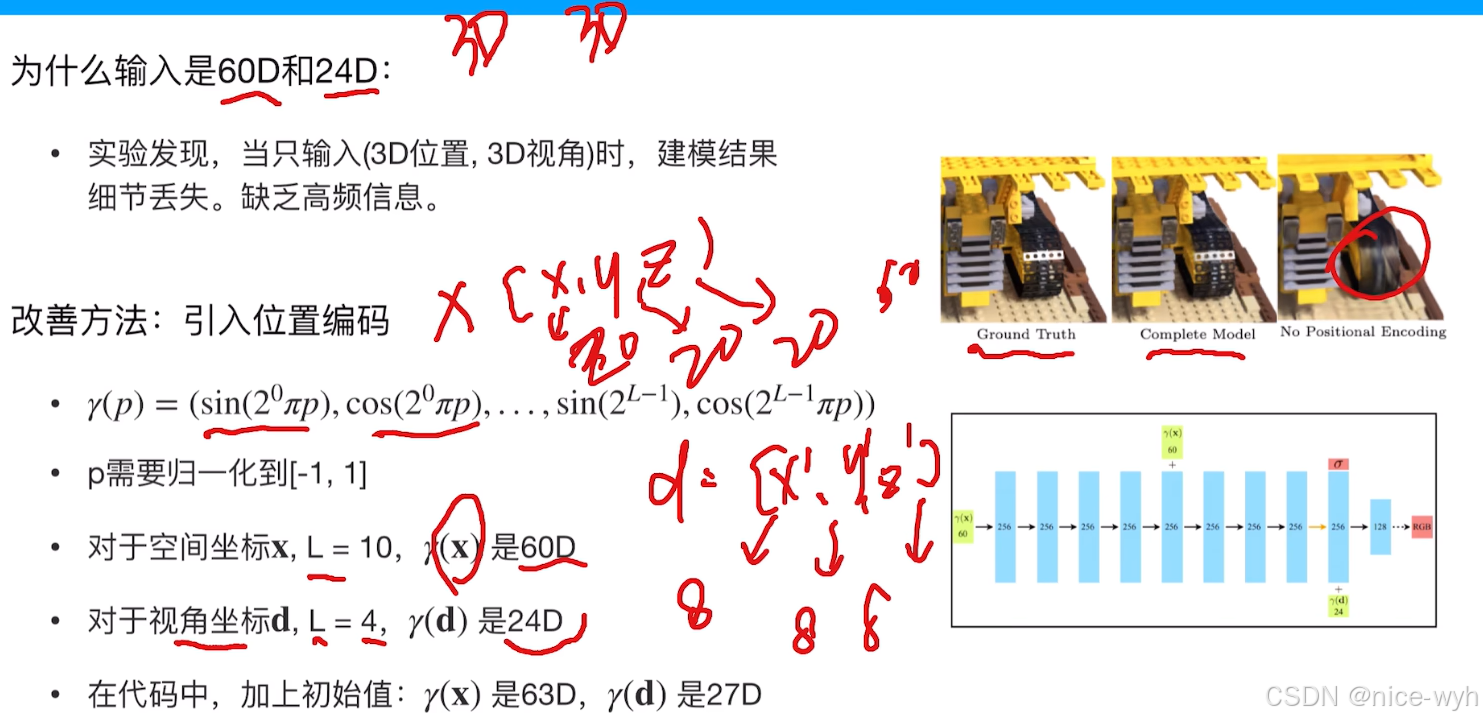
那么刚才所说的明明输入是6D,现在怎么变成60D里,这是又因为通过实验发现只输入6D的3D位置信息和3D视角信息时,建模结果的细节会丢失,因此猜测是缺乏高频信息导致的,因此为了丰富输入信息,引入了位置编码,也就是引入了sin和cos三角函数对其进行位置编码,对于3D位置信息,引入一个超参数L,让L=10,那么原先的3D就变成了60D(20D+20D+20D,其中20是因为sin和cos各占10);而对于3D视角信息,让L=4,那么原先的3D就变成了24D(8D+8D+8D,其中8D是因为sin和cos各占4)。
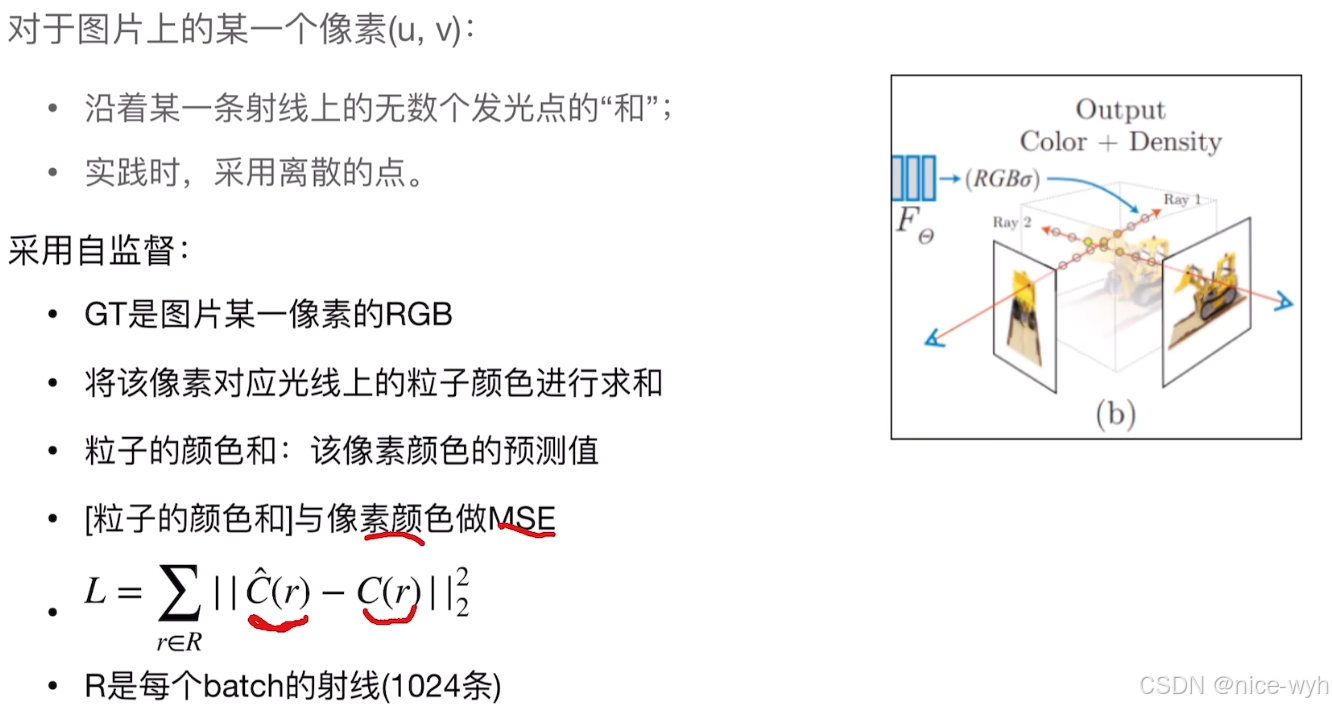
3.Loss计算
loss是怎么算的呢,首先GT就是图片中某一像素的RGB值,将该像素对应的射线上的采样的粒子颜色进行求和,将采样粒子的颜色和视为对该像素颜色的预测值,二者做MSE就得到了loss。
那么如何对粒子求和呢?
采用积分对粒子颜色就行求和,认为(s)是在s点的密度,C(s)是在s点模型得出来的颜色,T(s)是在这个s点前面,光线没有被阻碍的概率,可以这样去想,如果在s点前面有一个比s点异常明亮的另一个点,那么由s点射出来的光就会被前面的这个点阻碍,此时认为s点发出的光线被阻碍,T(s)接近于0,整个也就是0。
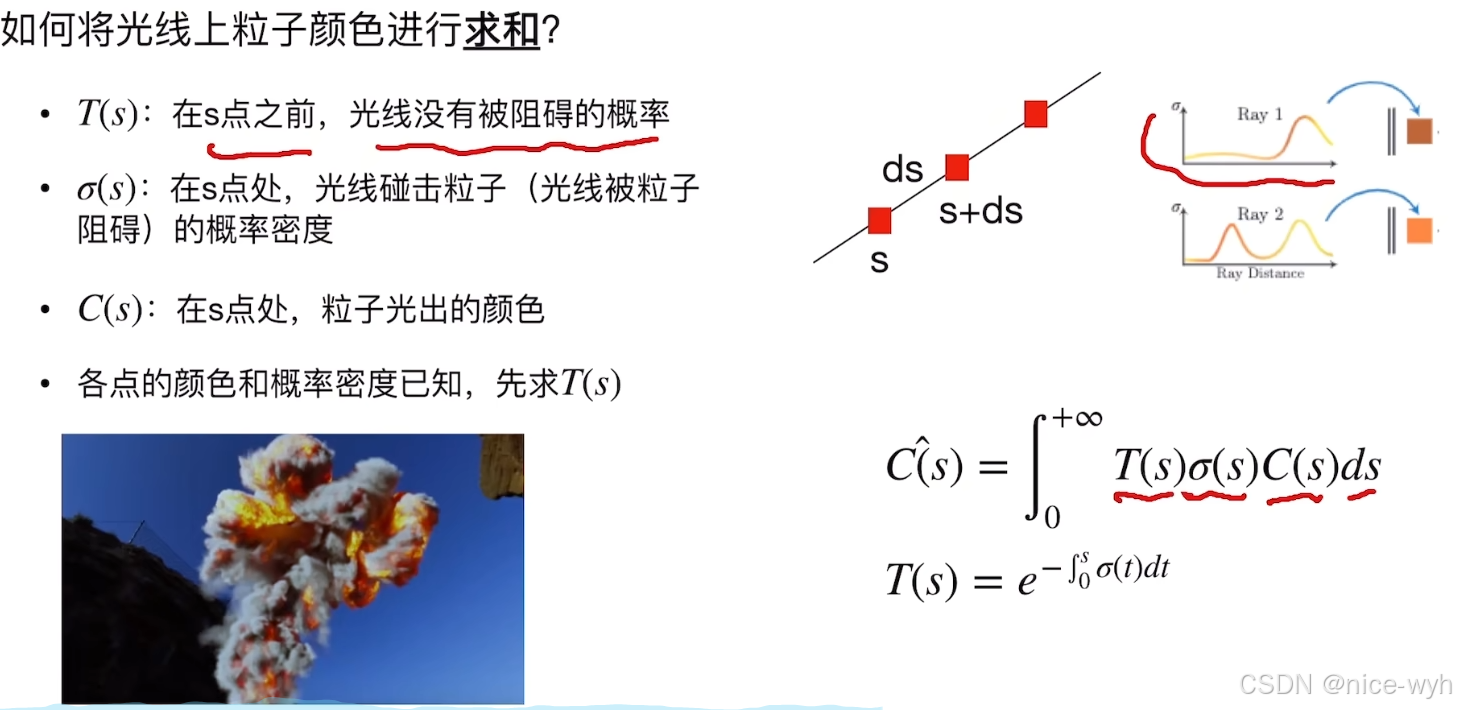
那么想要对图像上某一像素求他的颜色就是对从他发射出来的射线上所有粒子去做一个连续的积分,然后,每一个粒子的密度(s)和颜色C(s)都是已知的,去算一个他没有被阻碍的概率T(s),然后进行积分就可以推导出像素的颜色。
而刚才所说的连续积分对于计算机是做不到,因为计算机都是离散的数据,因此需要做离散化,方法上就是对一条射线,去均匀地取样,认为采样间隔内的颜色和密度是固定的,这样去做一个离散化的求和。
4.二次采样
希望对有效区域多采样,无效区域少采样。
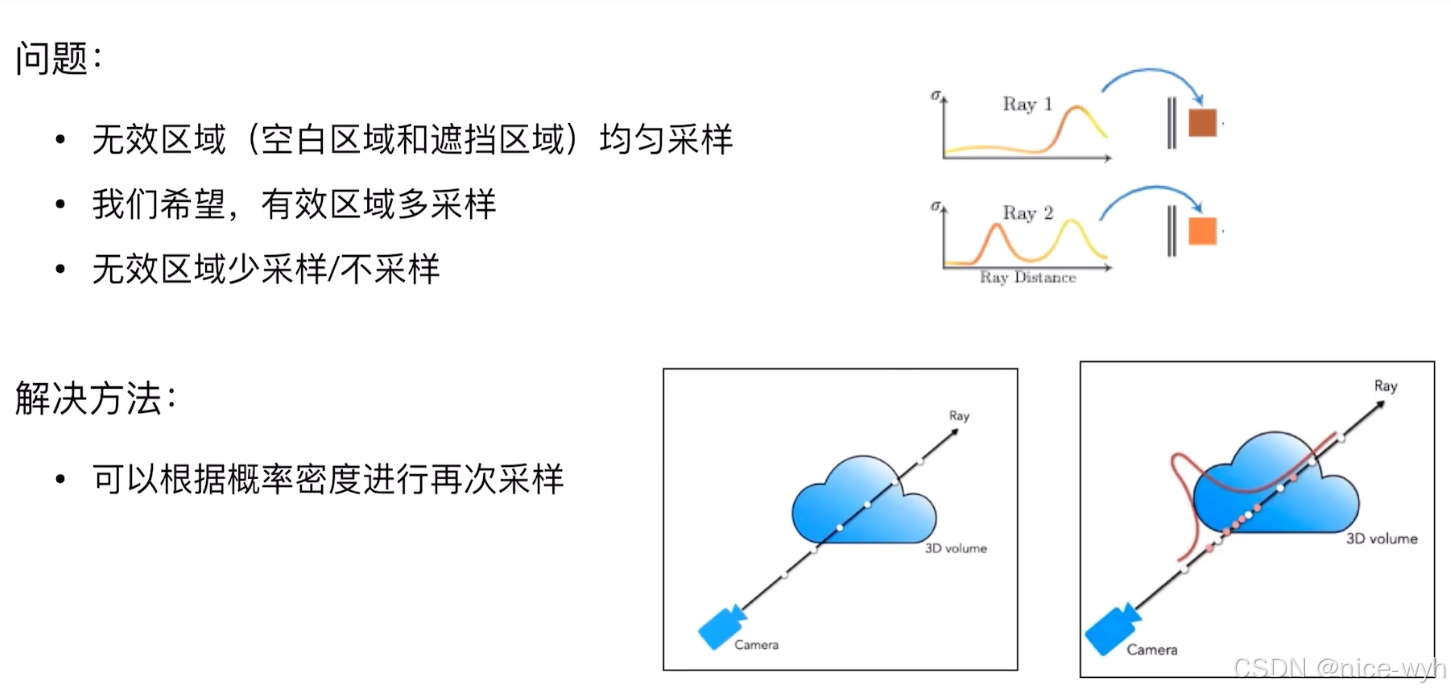
可以根据密度进行二次采样,定义均匀采样得到的模型为粗模型,二次采样得到的模型为细模型,二次采样的做法是什么呢?

三.总结
