2.1 transformer模型原理及代码(python)
本文参考了其他一些博客,在这里作了一个汇总,参考最多的是博客Transformer原理详解(图解完整版附代码) - 知乎、博客https://zhuanlan.zhihu.com/p/631398525和博客Transformer模型详解(图解最完整版) - 知乎,也看了其他博客,在这里不详细的说了,作为笔记用。
1.transformer模型结构
模型的结构如下图所示:
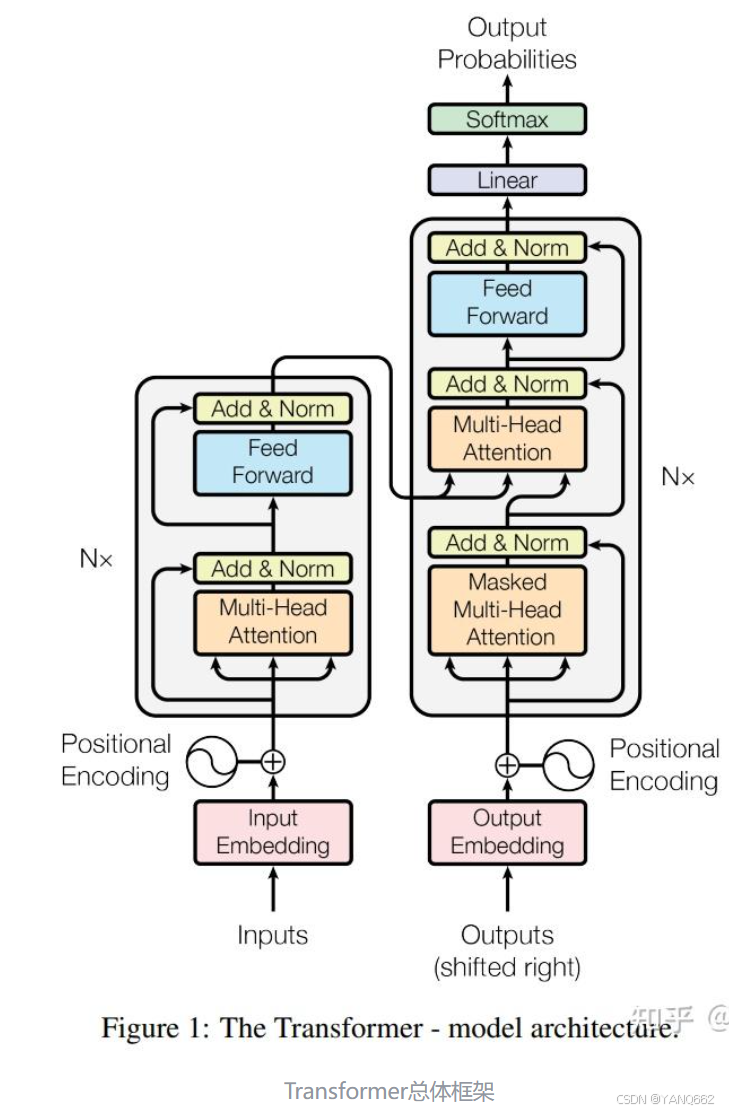
Transformer 模型多用于自然语言处理、大模型、计算机视觉等。该模型核心特征是自注意力机制,这使得模型能够有效地处理序列数据中的长距离依赖问题。由于其出色的并行处理能力和优异的性能,Transformer 已成为当今自然语言处理领域的基石技术。
其实模型由上图中的Inputs一列的和outputs一列两大部分组成,可以用下图理解:
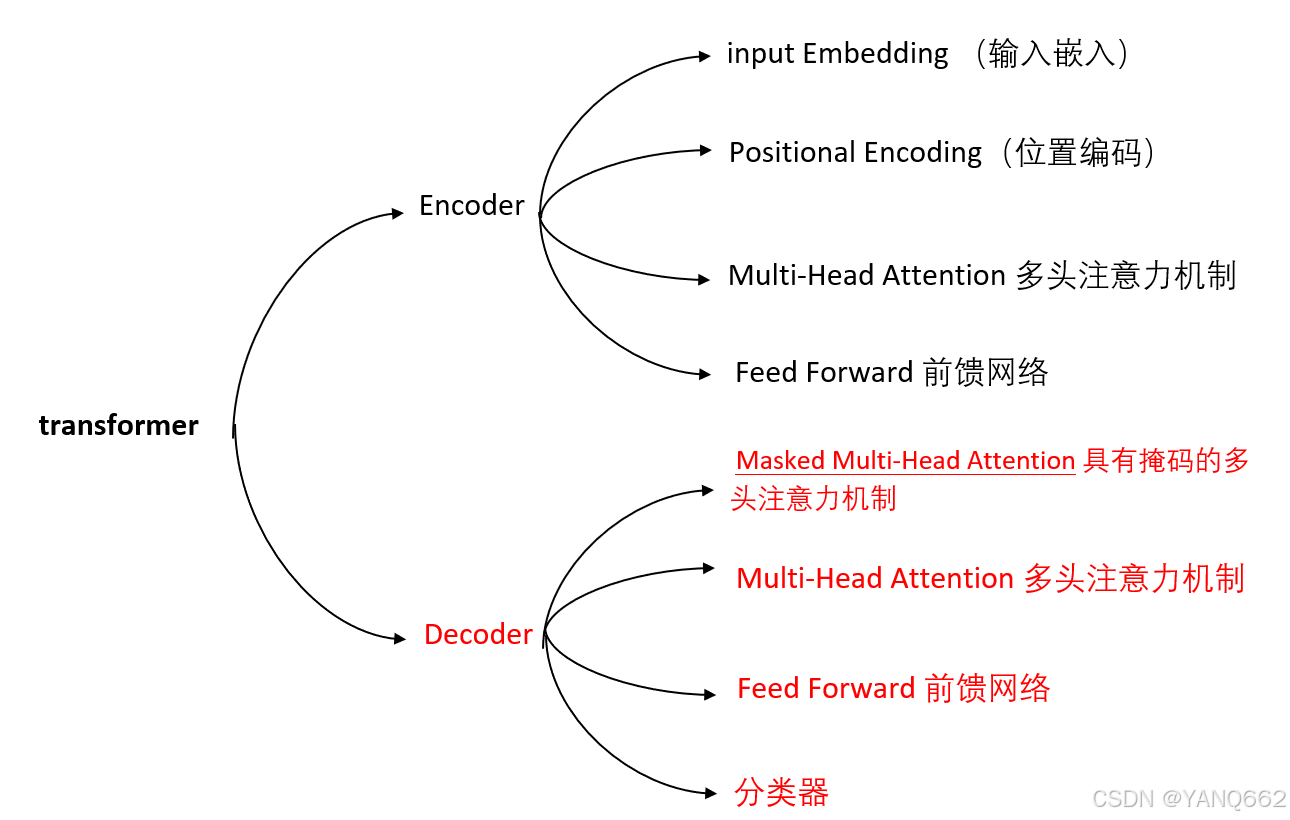
通过上图可以看出,transformer由encoder和decoder两大部分构成,encoder又由input Embedding (输入嵌入) 、Positional Encoding(位置编码) 、Multi-Head Attention 多头注意力机制和 Feed Forward 前馈网络四部分构成,decoder由Masked Multi-Head Attention 具有掩码的多头注意力机制 、 Multi-Head Attention 多头注意力机制 、 Feed Forward 前馈网络 和分类器四部分构成。下图由另一篇博客在内容的角度对encoder和decoder两个框架的解释,大家可以参考理解。
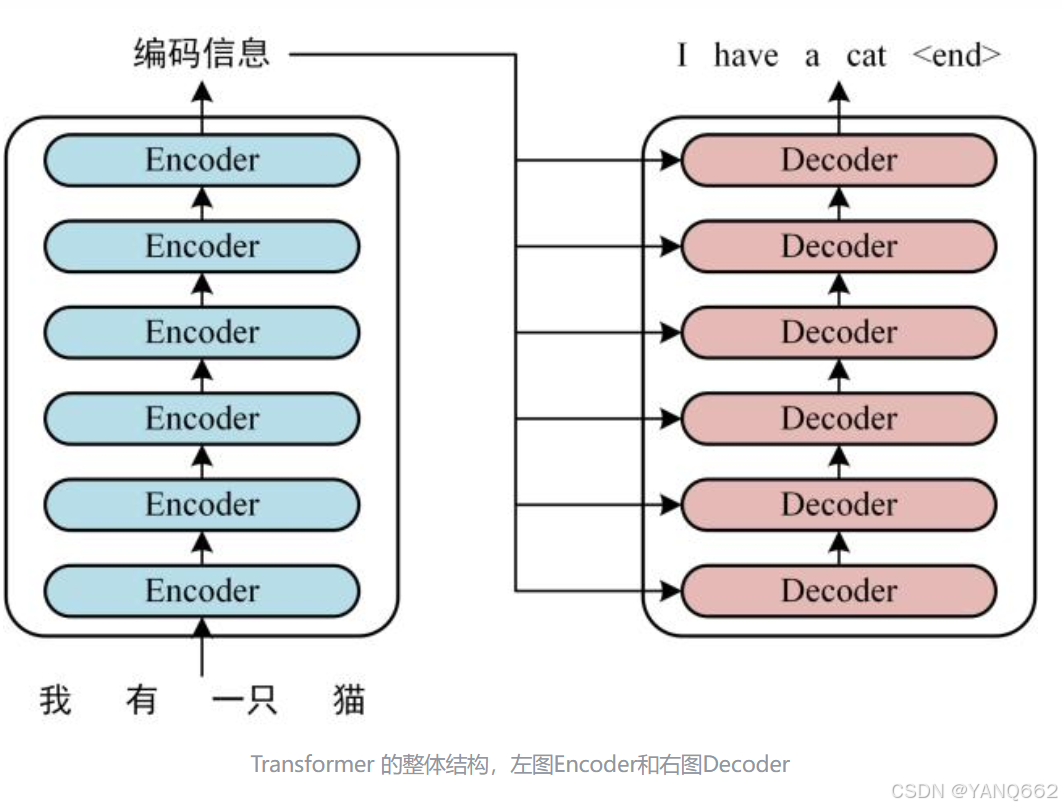
下面从各模块分别介绍各自的功能和原理。
2.encoder模块
在第一部分已经说过,encoder模块由 input Embedding (输入嵌入) 、Positional Encoding(位置编码) 、Multi-Head Attention 多头注意力机制和 Feed Forward 前馈网络四部分构成,下面我们分开介绍各部分。
2.1 input Embedding (输入嵌入)
Transformer 中单词的输入表示 x由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到。
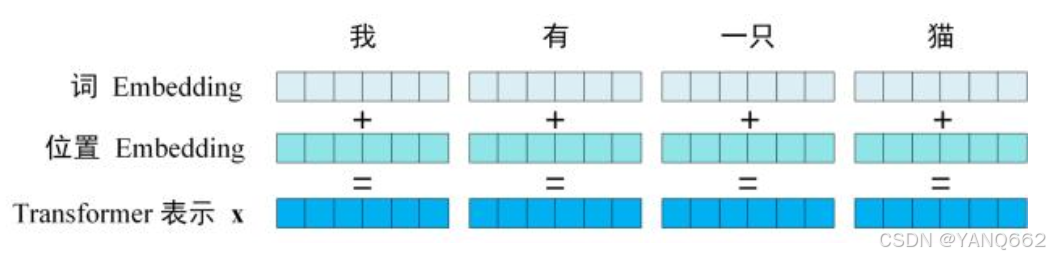
输入层的代码如下:
# 数据构建
import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
# device = 'cpu'
device = 'cuda'
# transformer epochs
epochs = 100
# 这里我没有用什么大型的数据集,而是手动输入了两对中文→英语的句子
# 还有每个字的索引也是我手动硬编码上去的,主要是为了降低代码阅读难度
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps
# 训练集
sentences = [
# 中文和英语的单词个数不要求相同
# enc_input dec_input dec_output
['我 有 一 个 好 朋 友 P', 'S I have a good friend .', 'I have a good friend . E'],
['我 有 零 个 女 朋 友 P', 'S I have zero girl friend .', 'I have zero girl friend . E'],
['我 有 一 个 男 朋 友 P', 'S I have a boy friend .', 'I have a boy friend . E']
]
# 测试集(希望transformer能达到的效果)
# 输入:"我 有 一 个 女 朋 友"
# 输出:"i have a girlfriend"
# 中文和英语的单词要分开建立词库
# Padding Should be Zero
src_vocab = {'P': 0, '我': 1, '有': 2, '一': 3,
'个': 4, '好': 5, '朋': 6, '友': 7, '零': 8, '女': 9, '男': 10}
src_idx2word = {i: w for i, w in enumerate(src_vocab)}
src_vocab_size = len(src_vocab)
tgt_vocab = {'P': 0, 'I': 1, 'have': 2, 'a': 3, 'good': 4,
'friend': 5, 'zero': 6, 'girl': 7, 'boy': 8, 'S': 9, 'E': 10, '.': 11}
idx2word = {i: w for i, w in enumerate(tgt_vocab)}
tgt_vocab_size = len(tgt_vocab)
src_len = 8 # (源句子的长度)enc_input max sequence length
tgt_len = 7 # dec_input(=dec_output) max sequence length
# Transformer Parameters
d_model = 512 # Embedding Size(token embedding和position编码的维度)
# FeedForward dimension (两次线性层中的隐藏层 512->2048->512,线性层是用来做特征提取的),当然最后会再接一个projection层
d_ff = 2048
d_k = d_v = 64 # dimension of K(=Q), V(Q和K的维度需要相同,这里为了方便让K=V)
n_layers = 6 # number of Encoder of Decoder Layer(Block的个数)
n_heads = 8 # number of heads in Multi-Head Attention(有几套头)
# ==============================================================================================
# 数据构建
def make_data(sentences):
"""把单词序列转换为数字序列"""
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]]
# [[1, 2, 3, 4, 5, 6, 7, 0], [1, 2, 8, 4, 9, 6, 7, 0], [1, 2, 3, 4, 10, 6, 7, 0]]
enc_inputs.extend(enc_input)
# [[9, 1, 2, 3, 4, 5, 11], [9, 1, 2, 6, 7, 5, 11], [9, 1, 2, 3, 8, 5, 11]]
dec_inputs.extend(dec_input)
# [[1, 2, 3, 4, 5, 11, 10], [1, 2, 6, 7, 5, 11, 10], [1, 2, 3, 8, 5, 11, 10]]
dec_outputs.extend(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
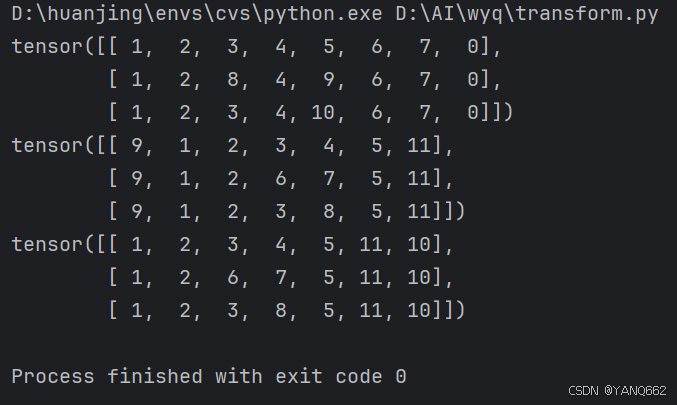
print(enc_inputs)
print(dec_inputs)
print(dec_outputs)
class MyDataSet(Data.Dataset):
"""自定义DataLoader"""
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
loader = Data.DataLoader(
MyDataSet(enc_inputs, dec_inputs, dec_outputs), 2, True)运行代码效果如下:
2.2 Positional Encoding(位置编码)
由于Transformer模型本身不具备处理序列顺序的能力,但因为在文本信息的处理时,当前单词是跟前后单词有关联系的,因此需要在输入嵌入层( input Embedding)后加入位置编码(position encoding),以提供位置信息,使用位置 Embedding 保存单词在序列中的相对或绝对位置。方便后面的模型训练能够获取文本的位置信息,从而更精准地来进行模型训练。
位置 Embedding 用 PE表示,PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了后者,计算公式如下:

其中,pos 表示单词在句子中的位置,d 表示 PE的维度 (与词 Embedding 一样),2i 表示偶数的维度,2i+1 表示奇数维度 (即 2i≤d, 2i+1≤d)。使用这种公式计算 PE 有以下的好处:
- 使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
- 可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。
将单词的词 Embedding 和位置 Embedding 相加,就可以得到单词的表示向量 x,x 就是 Transformer 的输入。
代码如下(该代码需要和上面的代码结合运行),其中PositionalEncoding(nn.Module)类就是我们的位置公式的函数。
:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(
0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: [seq_len, batch_size, d_model]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model) # token Embedding
self.pos_emb = PositionalEncoding(d_model) # Transformer中位置编码时固定的,不需要学习
def forward(self, enc_inputs):
"""
enc_inputs: [batch_size, src_len]
"""
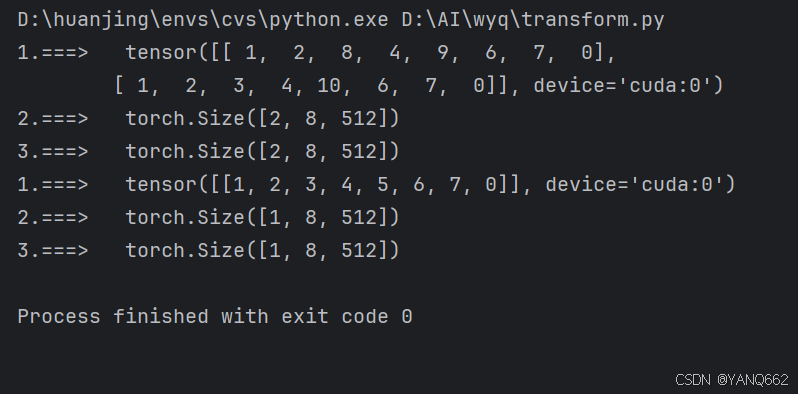
print("1.===> ",enc_inputs)
enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
print("2.===> ", enc_outputs.shape)
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, d_model]
print("3.===> ", enc_outputs.shape)
return enc_outputs
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder().to(device)
def forward(self, enc_inputs, dec_inputs):
enc_outputs= self.encoder(enc_inputs)
return enc_outputs
if __name__ == "__main__":
model = Transformer().to(device)
# 这里的损失函数里面设置了一个参数 ignore_index=0,因为 "pad" 这个单词的索引为 0,这样设置以后,就不会计算 "pad" 的损失(因为本来 "pad" 也没有意义,不需要计算)
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.SGD(model.parameters(), lr=1e-3,momentum=0.99) # 用adam的话效果不好
# ====================================================================================================
epochs = 1
for epoch in range(epochs):
for enc_inputs, dec_inputs, dec_outputs in loader:
"""
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
dec_outputs: [batch_size, tgt_len]
"""
enc_inputs, dec_inputs, dec_outputs = enc_inputs.to(device), dec_inputs.to(device), dec_outputs.to(device)
# outputs: [batch_size * tgt_len, tgt_vocab_size]
enc_outputs = model(enc_inputs, dec_inputs)运行结果如下:
2.3 Multi-Head Attention (多头注意力机制)
后续会继续补充。。。