【漫话机器学习系列】134.基于半径的最近邻分类器(Radius-Based Nearest Neighbor Classifier)
在机器学习中,最近邻(Nearest Neighbor)算法是一种基本的分类方法,它主要依赖于计算点之间的距离来进行分类。最常见的最近邻算法是 k-最近邻(k-Nearest Neighbors, k-NN),它通过选取距离目标点最近的 k 个样本,并根据它们的类别来进行预测。然而,基于半径的最近邻分类器(Radius-Based Nearest Neighbor Classifier, RBNN) 是 k-NN 的一种变体,它采用的是固定半径(Radius) 来确定最近邻,而不是选取固定数量的邻居。
1. 基于半径的最近邻分类器概述
基于半径的最近邻分类器(RBNN) 通过设定一个固定的超参数 超球半径(Radius),然后在这个半径范围内寻找所有的样本点。如果存在一个或多个样本点落入这个半径内,则采用多数投票的方式决定类别;如果在这个半径范围内没有任何样本点,则分类可能会失败或者采用默认策略(例如:最近邻策略)。
相比于 k-NN,RBNN 具有以下特点:
- 避免了 k-NN 可能导致的全局 K 值不适配问题:k-NN 需要手动指定 k 值,在不同密度的数据集中 k 值的选择会影响分类结果。而 RBNN 通过设定半径,能够更好地适应数据的局部密度变化。
- 适用于数据密度不均匀的情况:在密度较大的区域,RBNN 可以使用较少的样本点进行分类,而在密度较低的区域,它可以扩大搜索范围,提高分类的鲁棒性。
- 计算量依赖于半径大小:如果半径设置过大,可能会包含过多样本点,导致计算量增加;如果半径设置过小,则可能会导致无法分类的问题。
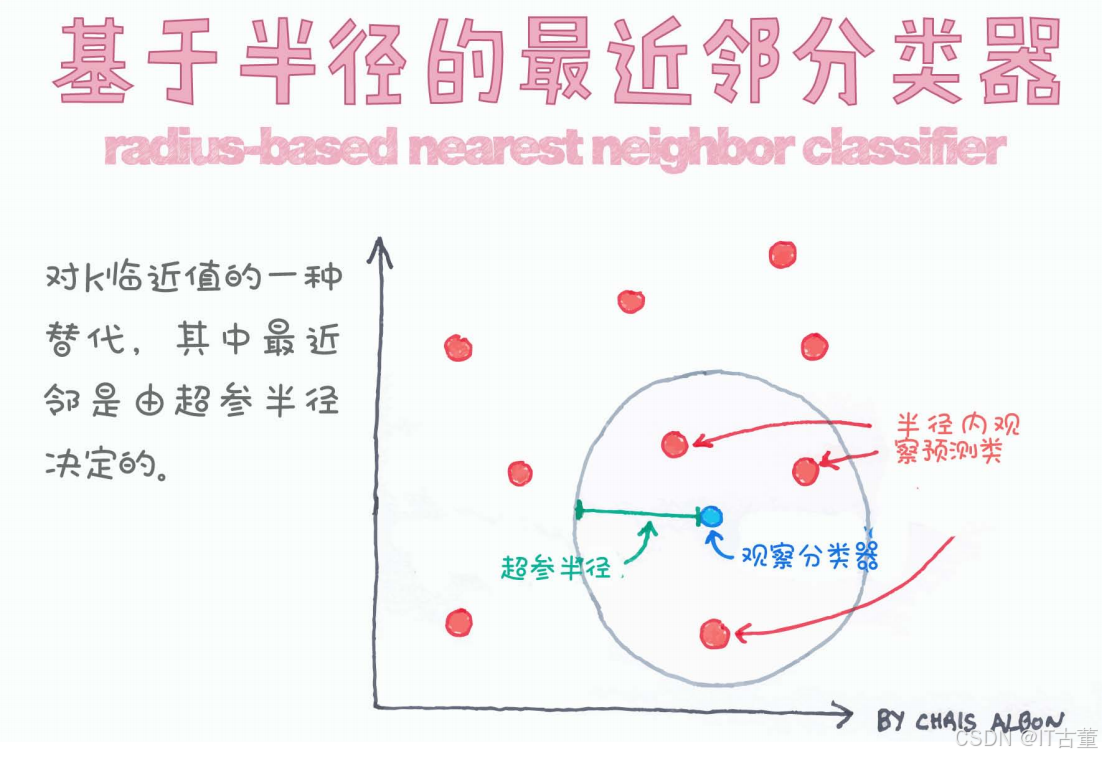
2. 图片解析
在上图中,展示了 RBNN 分类器的基本工作原理:
- 红色点 代表数据集中已有的样本点。
- 蓝色点 代表待分类的新样本点(观察分类器)。
- 黑色圆圈 代表以蓝色点为中心的超球体(超球半径)。
- 圆圈内的红色点 表示在该半径范围内的邻居点,这些点将被用于决定蓝色点的类别。
- 圆圈外的红色点 表示距离蓝色点过远,无法用于分类的样本。
通过这种方式,RBNN 仅利用在半径范围内的样本点进行分类,而不会考虑更远的点。
3. RBNN 分类器的数学定义
假设有一个数据集:
其中, 是特征向量,
是类别标签。
对于一个新的观测点 x′,基于半径的最近邻分类器的决策规则如下:
- 计算所有样本点与 x′ 之间的距离:
- 选取所有满足
的样本点(即在半径 r 内的样本)。
- 如果选出的点不为空,则采用多数投票法,将 x′ 归为出现最多类别的类别:
其中,表示半径 r 内的点集,
为指示函数:
如果半径内没有样本点,则可以:
- 采用最近邻(1-NN)进行分类
- 设定默认类别
- 认为分类失败
4. RBNN 分类器的应用
(1) 异常检测
如果一个数据点在 RBNN 分类器的半径范围内找不到任何邻居,则它可能是一个异常点(Outlier)。因此,RBNN 可以用于异常检测(Anomaly Detection),例如在网络安全、信用卡欺诈检测等领域。
(2) 文本分类
在 NLP(自然语言处理)领域,RBNN 可用于基于词向量的文本分类。如果某个文本的词向量在半径内找不到足够的邻居,则可能需要重新标注或归入新的类别。
(3) 医疗诊断
在医疗数据分析中,RBNN 可以用于基于患者历史数据的疾病预测。例如,在给定患者的症状向量时,可以检查其在过去患者数据中的邻居情况,并进行分类。
5. RBNN 的优缺点
优点
- 适应局部数据分布:相比 k-NN 需要固定 k 值,RBNN 通过半径选择可以更适应不同密度的数据。
- 可用于异常检测:如果某个点在半径范围内没有邻居,它可以被认为是异常点。
- 计算效率较高(对于稀疏数据):在数据较为稀疏的情况下,RBNN 只需计算部分样本点的距离,而 k-NN 可能需要计算所有点的距离。
缺点
- 半径选择敏感:如果半径设定过小,可能会导致许多数据点无法分类;如果半径过大,可能会引入过多的噪声。
- 计算复杂度受半径影响:半径较大会增加计算复杂度,因为需要计算更多的样本点距离。
- 受数据分布影响较大:如果数据密度变化较大,不同区域的半径可能需要不同的值,而固定半径可能不适用。
6. 总结
基于半径的最近邻分类器(RBNN)是一种基于邻近原则的分类方法,核心思想是使用超球半径来决定最近邻,而不是固定的 k 值。它可以更灵活地适应不同数据密度的情况,适用于分类、异常检测、文本处理和医疗预测等多个领域。
在实际应用中,RBNN 需要合理选择超球半径,通常可以通过交叉验证(Cross Validation) 或网格搜索(Grid Search) 来优化半径的选择。同时,可以结合其他方法(如加权投票、距离度量优化等)来提高分类的准确性。
总体而言,RBNN 是一种简单但有效的分类方法,尤其在密度变化较大的数据集中,比传统的 k-NN 更具优势。