c++stl之unordered-map以及set
1.概述
在 C++ 的世界里,unordered_set(哈希集合)和unordered_map(哈希映射)作为基于哈希表实现的关联容器,是高效数据处理的得力工具。它们凭借独特的哈希技术,突破了传统有序容器的限制,在诸多场景下展现出卓越性能。这二者在底层实现上有着相似的脉络,皆依赖哈希表来组织数据,以实现快速的数据访问;但在应用方向上,又因存储内容的差异 ——unordered_set专注于存储唯一元素,而unordered_map擅长维护键值对映射,呈现出各自的特点。接下来,就让我们深入探究unordered_set与unordered_map在功能特性、操作细节、性能表现以及适用场景等方面的异同,为你在实际编程中精准选用它们提供有力支持
2数据结构
哈希表
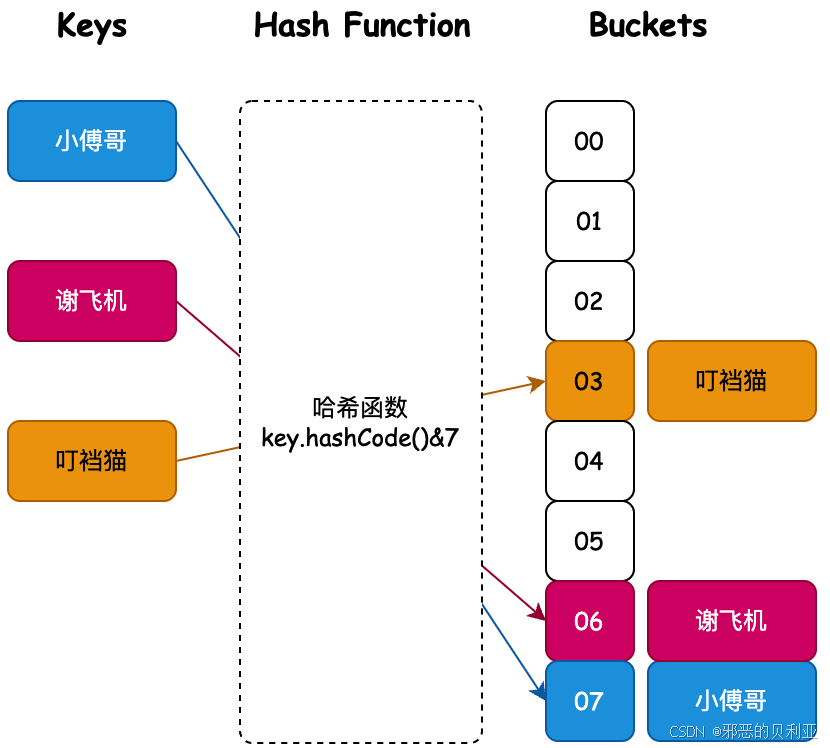
借鉴了一种函数思想 将输入->通过一个变化->映射到一个储存空间
现代实现中,为了避免链表过长导致的性能下降(链表查找、插入和删除操作的时间复杂度为O(N,当链表长度超过一定阈值时,会将链表转换为树结构(如红黑树),树结构在处理大量元素时,查找、插入和删除操作的时间复杂度为0(log(N))
std::unordered_map 在处理元素时,会使用键(key)作为输入传递给哈希函数
std::unordered_set就用val进入
3 操作方法
创建
using namespace std;
unordered_map<type ,type> um();
unordered_map um(InputIterator first, InputIterator last)
std::unordered_map<Key, T> um1(um2)
std::unordered_map<Key, T> um(std::move(um2));
set 同理有一个关键是pair组件,使用第二个,你的迭代对象得是pair
访问
size_type size() const; // 返回 unordered_set 中元素的数量
bool empty() const; // 判断 unordered_set 是否为空
iterator find(const Key& k);
// 在 unordered_set 中查找键为 k 的元素,如果找到返回指向该元素的迭代器,否则返回 end()
//map都不用变的 直接用 key是键的数据类型元素:
只有map有
T& operator[](const Key& k);
// 返回键为 k 的值的引用,如果键不存在,则插入一个默认构造的值
T& at(const Key& k);
// 返回键为 k 的值的引用,如果键不存在,抛出 std::out_of_range 异常两者都有
map
for (const auto& [key, value] : myMap) {
std::cout << "Key: " << key << ", Value: " << value << std::endl;
}
set
for (const auto &t : set) {
std::cout << key << endl;
}增加
// 插入单个元素
std::pair<iterator, bool> insert(const value_type& val);
// 插入范围
template <class InputIterator>
void insert(InputIterator first, InputIterator last);
template <class... Args>
std::pair<iterator, bool> emplace(Args&&... args);
// 直接在 unordered_set 中构造元素删除
// 删除指定位置的元素
iterator erase(iterator position);
// 删除指定键的元素
size_type erase(const Key& k);
// 删除指定范围的元素
iterator erase(iterator first, iterator last); 你可以结合STL之关联容器(map ,set)-CSDN博客这个来看 成员函数解析
4.应用场景
性能要求
-
对性能要求极高且哈希冲突可控:如果应用程序对插入、查找和删除操作的性能要求非常高,且能合理控制哈希冲突(例如选择合适的哈希函数和负载因子),那么
unordered_map和unordered_set是更好的选择。例如,在实时数据处理系统中,需要快速处理大量的数据插入和查找操作。 -
对有序性有要求且性能可接受:当需要元素有序,并且对插入、删除和查找操作的性能要求不是极端高时,
map和set更合适。例如,在一个需要按顺序输出统计结果的报表生成系统中。
数据结构复杂度
-
简单数据处理:对于简单的数据存储和查找,且不需要额外的排序操作,
unordered_map和unordered_set由于其实现相对简单,在代码编写和维护上可能更方便。 -
复杂数据处理:如果需要进行范围查找、获取最大 / 最小元素等操作,
map和set基于红黑树的特性可以更好地支持这些操作。例如,在一个需要找出某个区间内所有元素的应用中,map可以方便地通过迭代器进行范围查找。