嵌入式人工智能应用- 第九章 物体识别
嵌入式人工智能应用
1 物体识别概述
1.1 物体识别原理
物体识别在我们的生活中经常看到,比如某些科幻电影里机器可以识别人、狗、猫、汽车等等,在人工智能发展的今天,我们能不能实现物体识别呢?答案是可以的。本次实验名称是物体识别,其实不太准确,它本质上是分类问题,就好比我们常说的人脸识别,这里目的是更接近实际生活所听到的概念。物体识别实际是采集了一系列的场景,然后对场景中的物体(包括生物和非生物)进行标注,也就是告诉机器当前这张照片里有些什么。然后基于深度学习的方法,对样本图片进行多维空间映射,根据标注信息对样本图片在多维空间进行分割,提取特征信息,最后将特征信息保存、模型保存,以备下次使用。
接下来开发一些 APP,加载这些模型、特征信息,对采集到的场景进行处理,提取特征信息,然后对现在的场景进行分类比对,最后将标签标注到当前场景的特定位置。对于我们肉眼可以看到的就是识别了当前场景的物体,例如照片里有一个人、一条狗、一辆车,分别标注 person、dog、car,这样我们直观的感受到机器可以识别当前场景。
同样的原理,我们还可以做更多的应用,例如场景识别,提供一些医院的照片、地铁的照片、公园的照片,通过深度学习就可以对这些场景进行识别。
1.2 squeezenet 网络介绍
从 LeNet5 到 DenseNet,反应卷积网络的一个发展方向:提高精度。图像的空间特征、颜色特征等,对于物体识别在某些方面的精度要求不是那么高,那么有没有一种网络可以在精度一定要求下提高运算速度呢?提高运算速度的调整大概有两个方向:减少可学习参数的数量;减少整个网络的计算量。
SqueezeNet 的模型压缩
1.将 3x3 卷积替换成 1x1 卷积:通过这一步,一个卷积操作的参数数量减少了 9 倍。
2.减少 3x3 卷积的通道数:一个 3x3 卷积的计算量是 3x3xMxN(其中 M、N 分别是输入 Feature Map和输出 Feature Map 的通道数),Squeezenet 的作者认为这样的计算量过于庞大,因此将 M、N 减小来减少参数数量。
3.将降采样后置:作者认为较大的 Feature Map 含有更多的信息,因此将降采样往分类层移动。注意这样的操作虽然会提升网络的精度,但是它有一个非常严重的缺点:即会增加网络的计算量。
Fire 模块
SqueezeNet 是由若干个 Fire 模块结合卷积网络中卷积层,降采样层,全连接等层组成的。一个 Fire 模块由 Squeeze 部分和 Expand 部分组成。Squeezenet 部分是由一组连续的 1x1 卷积组成,Expand 部分则是由一组连续的 1x1 卷积核一组连续的 3x3 卷积 cancatnate 组成,3x3 卷积需要使用 same 卷积,Fire 模块的结构。
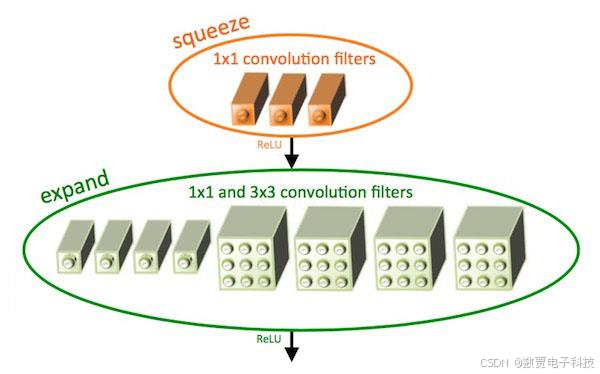
具体的计算这里不多说,python 中,sklearn、keras 帮我们实现了大量的算法,例如这里的 Fire 模块在keras 中是这样实现的
def fire_model(x, s_1x1, e_1x1, e_3x3, fire_name):
# squeeze part
squeeze_x =Conv2D(kernel_size=(1,1),filters=s_1x1