Linux应用:PCB、fork
什么是进程
进程是程序的一次执行过程,是操作系统进行资源分配和调度的基本单位。它包含了程序执行的上下文环境,如代码、数据、打开的文件描述符、信号处理函数等。每个进程在操作系统中都有唯一的标识符(PID,Process ID),操作系统通过 PID 来管理和控制进程。
进程控制块PCB(Process Control Block)
PCB 是进程存在的唯一标志,当操作系统创建一个新进程时,会为其分配一个 PCB;当进程终止时,操作系统会回收其 PCB。每个进程都有一个与之对应的 PCB,操作系统通过对 PCB 的操作来实现对进程的控制和管理。
作用
进程标识:每个 PCB 都有一个唯一的标识符,即进程 ID(PID),用于区分不同的进程。
进程控制:操作系统通过 PCB 来控制进程的执行,如进程的创建、暂停、继续、终止等操作。
进程调度:调度程序根据 PCB 中的信息(如优先级、状态等)来决定哪个进程可以获得 CPU 资源,以及何时获得 CPU 资源。
资源管理:PCB 记录了进程所占用的各种资源,如内存、文件、设备等,操作系统可以根据这些信息进行资源的分配和回收。
上下文切换:当进程被暂停执行时,其当前的执行上下文(如寄存器值、程序计数器等)会被保存到 PCB 中;当进程再次获得 CPU 资源时,操作系统会从 PCB 中恢复其执行上下文,使进程能够继续执行。
包含信息
不同操作系统的 PCB 所包含的信息可能会有所不同,但一般都包含以下几类信息:
进程标识符
内部标识符:操作系统为每个进程分配的唯一数字标识符,用于在操作系统内部对进程进行管理和识别。
外部标识符:由用户或应用程序使用的标识符,通常是一个字符串,用于方便用户或应用程序对进程进行操作和管理。
处理机状态
通用寄存器:用于保存进程在执行过程中的中间结果和临时数据。
程序计数器(PC):指示下一条要执行的指令的地址。
状态寄存器:保存进程的运行状态信息,如进位标志、溢出标志等。
栈指针:指向进程栈的栈顶地址,用于管理进程的函数调用和局部变量。
进程调度信息
进程状态:如就绪、运行、阻塞、终止等,用于描述进程当前的执行状态。
优先级:用于确定进程在调度时的优先顺序,优先级高的进程通常会优先获得 CPU 资源。
调度相关信息:如进程的等待时间、执行时间等,用于调度算法的计算和决策。
进程控制信息
程序和数据的地址:指示进程的程序代码和数据在内存中的存储位置。
进程同步和通信机制:如信号量、消息队列等,用于实现进程之间的同步和通信。
资源清单:记录进程所占用的各种资源,如内存、文件、设备等。
链接指针:用于将多个 PCB 组织成某种数据结构,如链表、队列等。
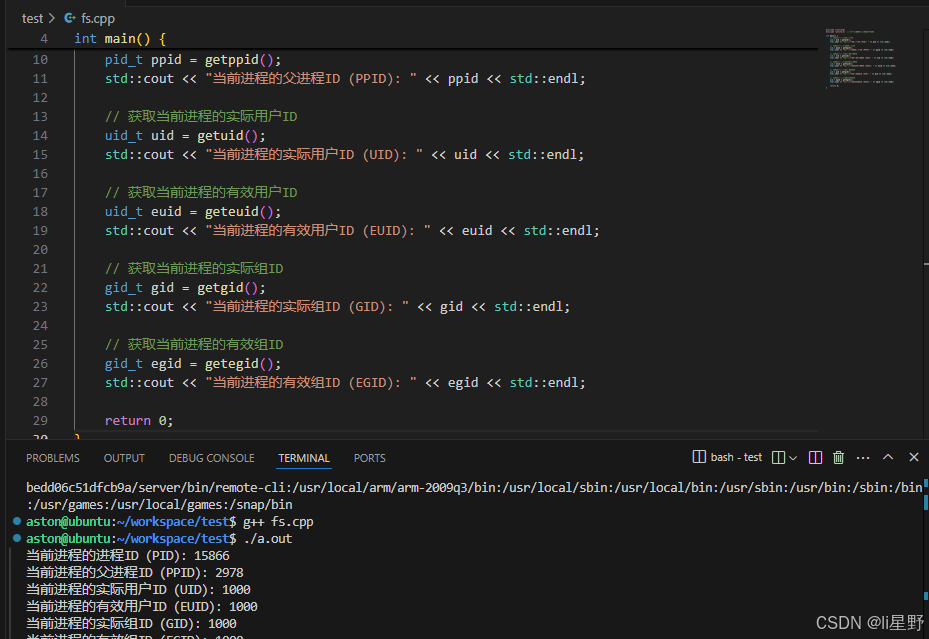
进程ID
getpid():返回当前进程的进程 ID(PID)。
getppid():返回当前进程的父进程 ID(PPID)。
getuid():返回当前进程的实际用户 ID(UID)。
geteuid():返回当前进程的有效用户 ID(EUID)。
getgid():返回当前进程的实际组 ID(GID)。
getegid():返回当前进程的有效组 ID(EGID)
#include <iostream>
#include <unistd.h> // 包含系统调用函数的头文件
int main() {
// 获取当前进程的进程ID
pid_t pid = getpid();
std::cout << "当前进程的进程ID (PID): " << pid << std::endl;
// 获取当前进程的父进程ID
pid_t ppid = getppid();
std::cout << "当前进程的父进程ID (PPID): " << ppid << std::endl;
// 获取当前进程的实际用户ID
uid_t uid = getuid();
std::cout << "当前进程的实际用户ID (UID): " << uid << std::endl;
// 获取当前进程的有效用户ID
uid_t euid = geteuid();
std::cout << "当前进程的有效用户ID (EUID): " << euid << std::endl;
// 获取当前进程的实际组ID
gid_t gid = getgid();
std::cout << "当前进程的实际组ID (GID): " << gid << std::endl;
// 获取当前进程的有效组ID
gid_t egid = getegid();
std::cout << "当前进程的有效组ID (EGID): " << egid << std::endl;
return 0;
}
多进程调度原理
操作系统采用多种调度算法来决定在多个进程之间如何分配 CPU 时间。常见的调度算法有先来先服务(FCFS)、短作业优先(SJF)、优先级调度、时间片轮转调度等。这些算法根据进程的特性(如预计执行时间、优先级等)和系统资源的使用情况,合理地安排进程的执行顺序,以提高系统的整体性能和资源利用率。
先来先服务(FCFS)调度算法
原理:按照进程进入就绪队列的先后顺序来分配 CPU。先进入队列的进程先获得 CPU 资源,一直执行到完成或因某种原因阻塞才释放 CPU。
优点:实现简单,公平性好,每个进程都按照其到达的先后顺序获得服务,不会出现进程被饿死的情况。
缺点:如果有一个长作业先进入队列,那么后面的短作业即使已经就绪,也必须等待长作业执行完成才能得到处理,导致短作业的平均等待时间可能很长,系统的整体效率不高。
短作业优先(SJF)调度算法
原理:从就绪队列中选择预计执行时间最短的进程来分配 CPU。这种算法假设每个进程的执行时间是已知的,它总是优先选择执行时间短的作业,以减少平均周转时间。
优点:可以有效地降低作业的平均等待时间,提高系统的吞吐量。因为短作业能够更快地完成,释放资源,让其他作业有更多机会使用 CPU。
缺点:需要事先知道每个作业的执行时间,这在实际中往往是难以准确预测的。而且该算法可能导致长作业长时间等待,甚至出现饥饿现象,即长作业可能一直得不到执行的机会。
优先级调度算法
原理:为每个进程分配一个优先级,根据优先级的高低来决定进程的执行顺序。优先级高的进程优先获得 CPU 资源,当有更高优先级的进程进入就绪队列时,当前正在执行的低优先级进程可能会被抢占,除非系统采用非抢占式优先级调度,即只有当高优先级进程主动放弃 CPU 或阻塞时,低优先级进程才有机会执行。
优点:可以根据进程的重要性或紧急程度来分配 CPU 资源,确保关键任务能够优先得到处理。
缺点:如果不采取适当的措施,低优先级的进程可能会长期处于等待状态,出现饥饿现象。此外,如何合理地确定进程的优先级也是一个复杂的问题,需要综合考虑多种因素。
时间片轮转调度算法
原理:将 CPU 的时间划分成一个个固定长度的时间片,每个进程轮流在一个时间片内执行。当时间片用完后,无论进程是否执行完成,都将被暂停,然后将 CPU 分配给下一个就绪进程。如此循环,直到所有进程都执行完毕或满足某种结束条件。
优点:可以保证每个进程都能在一定时间内获得 CPU 资源,实现了进程之间的公平调度,用户会感觉系统在同时处理多个任务,提高了系统的响应速度和交互性。
缺点:由于进程的切换需要保存和恢复现场等操作,会带来一定的系统开销。如果时间片设置得太短,会导致进程切换过于频繁,系统开销增大;如果时间片设置得太长,又会退化为类似 FCFS 算法,无法及时响应其他进程的请求。
fork创建子进程
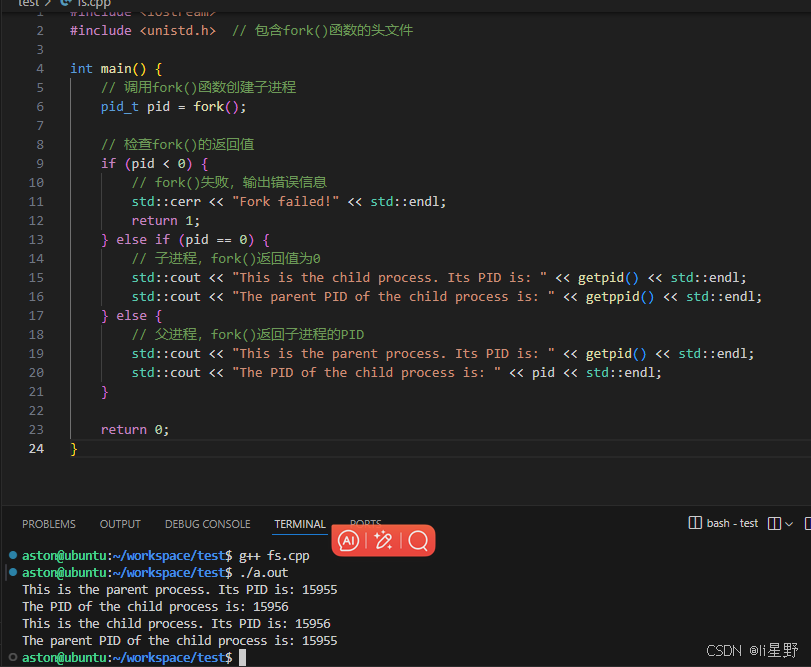
fork函数是 UNIX/Linux 系统中用于创建子进程的系统调用。调用fork函数后,操作系统会为新的子进程分配资源,包括内存空间、文件描述符等,并复制父进程的上下文环境。子进程几乎是父进程的一个副本,它们从fork函数调用点开始并发执行不同的代码分支,通过fork函数的返回值来区分父子进程,父进程返回子进程的 PID,子进程返回 0。
#include <iostream>
#include <unistd.h> // 包含fork()函数的头文件
int main() {
// 调用fork()函数创建子进程
pid_t pid = fork();
// 检查fork()的返回值
if (pid < 0) {
// fork()失败,输出错误信息
std::cerr << "Fork failed!" << std::endl;
return 1;
} else if (pid == 0) {
// 子进程,fork()返回值为0
std::cout << "This is the child process. Its PID is: " << getpid() << std::endl;
std::cout << "The parent PID of the child process is: " << getppid() << std::endl;
} else {
// 父进程,fork()返回子进程的PID
std::cout << "This is the parent process. Its PID is: " << getpid() << std::endl;
std::cout << "The PID of the child process is: " << pid << std::endl;
}
return 0;
}
包含头文件:
#include :用于输入输出操作。
#include <unistd.h>:包含了fork()函数以及getpid()和getppid()函数的声明。getpid()用于获取当前进程的 PID,getppid()用于获取当前进程的父进程的 PID。
调用fork()函数:
pid_t pid = fork();:调用fork()函数创建子进程。fork()函数会返回两次,在父进程中返回子进程的 PID,在子进程中返回 0,如果创建失败则返回 - 1。
检查fork()的返回值:
if (pid < 0):表示fork()调用失败,输出错误信息并返回 1。
else if (pid == 0):表示当前代码在子进程中执行,输出子进程的 PID 和父进程的 PID。
else:表示当前代码在父进程中执行,输出父进程的 PID 和子进程的 PID。
什么是子进程
子进程是由另一个进程(父进程)通过fork或其他类似机制创建的新进程。子进程继承了父进程的许多属性,如用户 ID、组 ID、环境变量、文件描述符等,但它有自己独立的 PID 和内存空间,与父进程并发执行,在一定程度上可以看作是一个独立的程序在运行。
子进程和父进程的关系
父子关系:父进程创建子进程,它们之间存在明确的父子层次结构。
资源继承:子进程继承父进程的部分资源,如打开的文件描述符,这意味着父进程打开的文件在子进程中仍然保持打开状态。
并发执行:父子进程并发运行,它们的执行顺序由操作系统的调度算法决定。
生命周期关联:一般情况下,父进程可以通过wait系列函数等待子进程结束,并获取子进程的退出状态,子进程的结束也可能会影响父进程的后续行为。
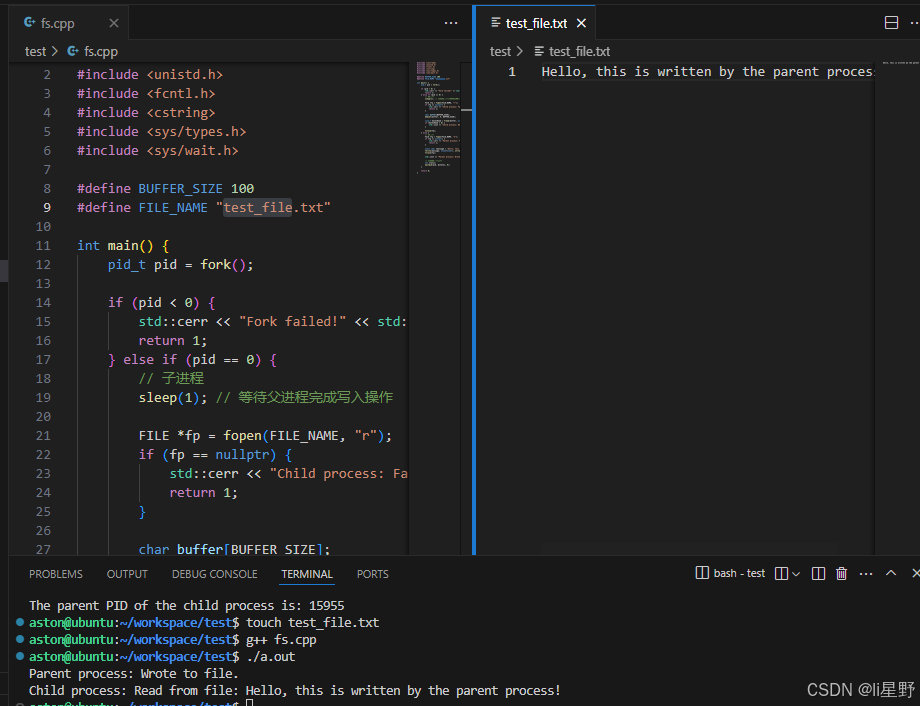
父子进程对文件的操作
由于子进程继承了父进程的文件描述符,父子进程对同一文件描述符所指向的文件进行操作时,具有一些特殊的行为。例如,父子进程共享文件的偏移量,一个进程对文件的写入操作会影响另一个进程对文件的读取位置。但如果在fork之后,某个进程又单独打开了同一个文件,那么它会得到一个新的文件描述符,与父进程的文件描述符相互独立,对文件的操作也相互独立。
#include <iostream>
#include <unistd.h>
#include <fcntl.h>
#include <cstring>
#include <sys/types.h>
#include <sys/wait.h>
#define BUFFER_SIZE 100
#define FILE_NAME "test_file.txt"
int main() {
pid_t pid = fork();
if (pid < 0) {
std::cerr << "Fork failed!" << std::endl;
return 1;
} else if (pid == 0) {
// 子进程
sleep(1); // 等待父进程完成写入操作
FILE *fp = fopen(FILE_NAME, "r");
if (fp == nullptr) {
std::cerr << "Child process: Failed to open file!" << std::endl;
return 1;
}
char buffer[BUFFER_SIZE];
memset(buffer, 0, BUFFER_SIZE);
size_t bytesRead = fread(buffer, sizeof(char), BUFFER_SIZE - 1, fp);
if (bytesRead > 0) {
std::cout << "Child process: Read from file: " << buffer << std::endl;
}
fclose(fp);
} else {
// 父进程
FILE *fp = fopen(FILE_NAME, "w");
if (fp == nullptr) {
std::cerr << "Parent process: Failed to open file!" << std::endl;
return 1;
}
const char *message = "Hello, this is written by the parent process!";
fwrite(message, sizeof(char), strlen(message), fp);
fclose(fp);
std::cout << "Parent process: Wrote to file." << std::endl;
// 等待子进程结束
int status;
waitpid(pid, &status, 0);
}
return 0;
}
头文件包含:
:用于标准输入输出操作。
<unistd.h>:包含 fork() 和 sleep() 等函数。
<fcntl.h>:提供文件控制相关的函数和常量。
:用于字符串操作,如 strlen 和 memset。
<sys/types.h> 和 <sys/wait.h>:提供进程相关的类型和 waitpid 函数。
常量定义:
BUFFER_SIZE:定义读取文件时使用的缓冲区大小。
FILE_NAME:指定要操作的文件名称。
fork() 函数调用:
通过 fork() 创建子进程,依据返回值判断当前是父进程还是子进程。
子进程操作:
调用 sleep(1) 让子进程等待 1 秒,确保父进程完成文件写入操作。
以只读模式打开文件,若打开失败则输出错误信息。
使用 fread 函数从文件读取数据到缓冲区,并输出读取到的内容。
关闭文件。
父进程操作:
以写入模式打开文件,若打开失败则输出错误信息。
使用 fwrite 函数将字符串写入文件。
关闭文件并输出写入成功的信息。
调用 waitpid 等待子进程结束。